1. cpu 計算 fp16 四則運算
? ? ? ? 由于會用到cpu 的gemm 與 gpu gemm 的對比驗證,所以,這里稍微解釋一下 cpu 計算fp16 gemm 的過程。這里為了簡化理解,cpu 中不使用 avx 相關的 fp16 運算器,而是直接使用 cpu 原先的 ALU 功能。這里使用一個示例來做這件事情。
1.1. 源碼編譯運行
hello_fp16.cu
#include <stdio.h>
#include "cuda_fp16.h"int main()
{half x = half(3.333);half y = half(7.777);half z = half(0.0);z = x*y;printf("sizeof(half) = %ld x = %f \n", sizeof(x), float(z));return 0;
}
編譯運行:
nvcc -g --gpu-architecture=sm_120 hello_fp16.cu -o hello_fp16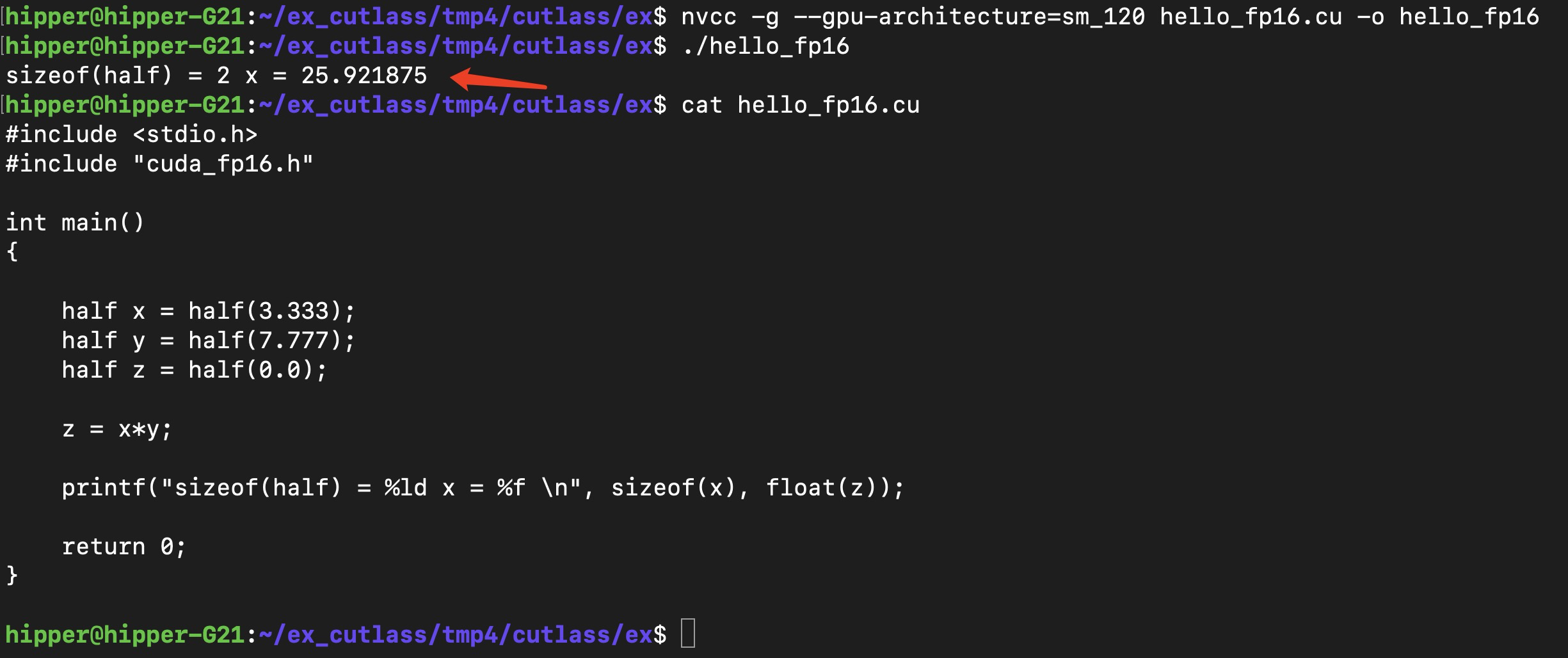
1.2. 調試追蹤 fp16 的相關功能
? ? ? ? 這里有兩個目標:
? ? ? ? 一個是類型轉換,怎么樣得到一個 fp16 的變量值;
? ? ? ? 一個是 fp16 類型變量之間的乘法(四則運算)。
? ? ? ? 現在看一下其中的 half(3.333) 的執行,通過使用 step,經歷如下幾個斷點:
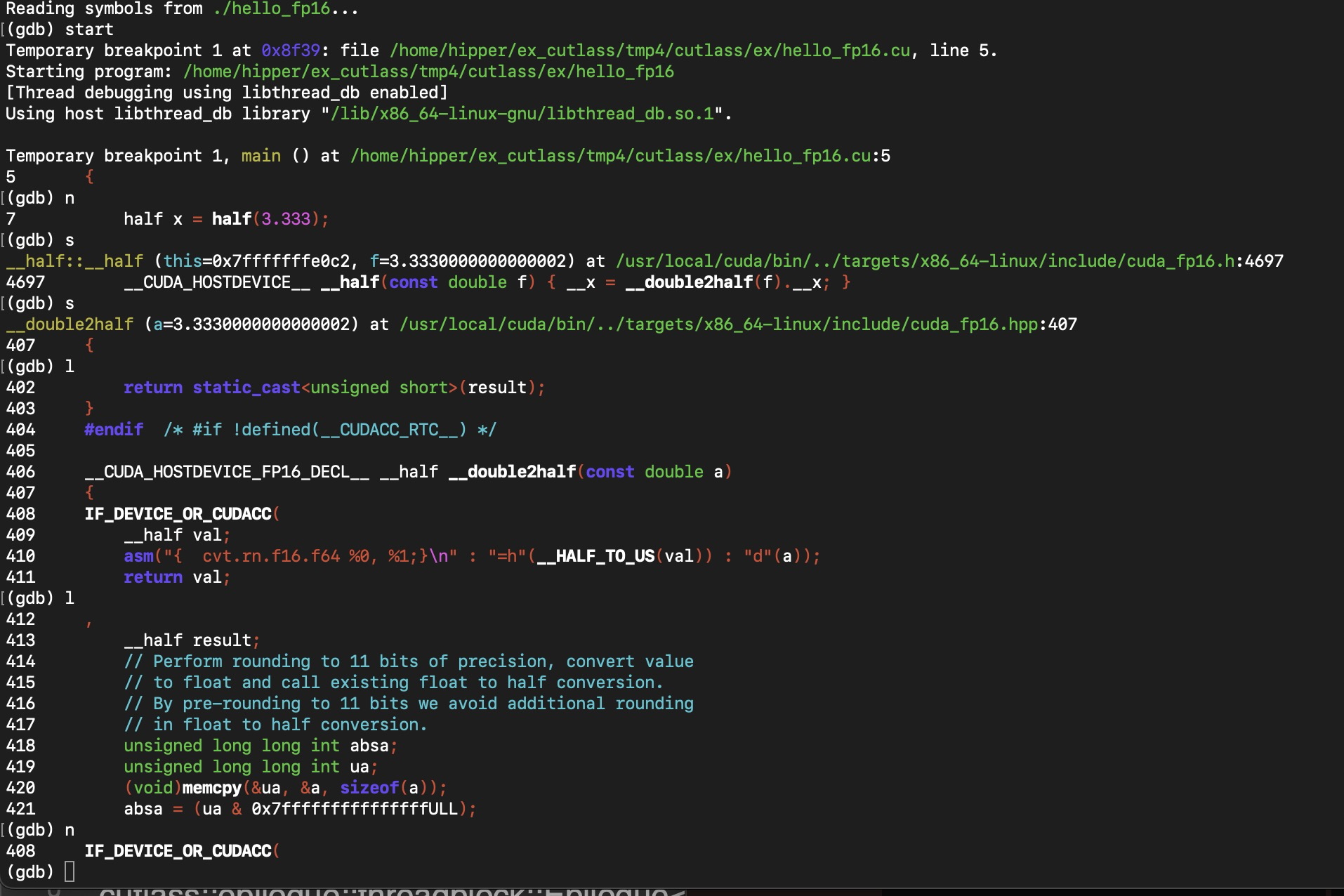
在 408 行 時,使用gdb )s 會跳到下圖代碼 549 行處:
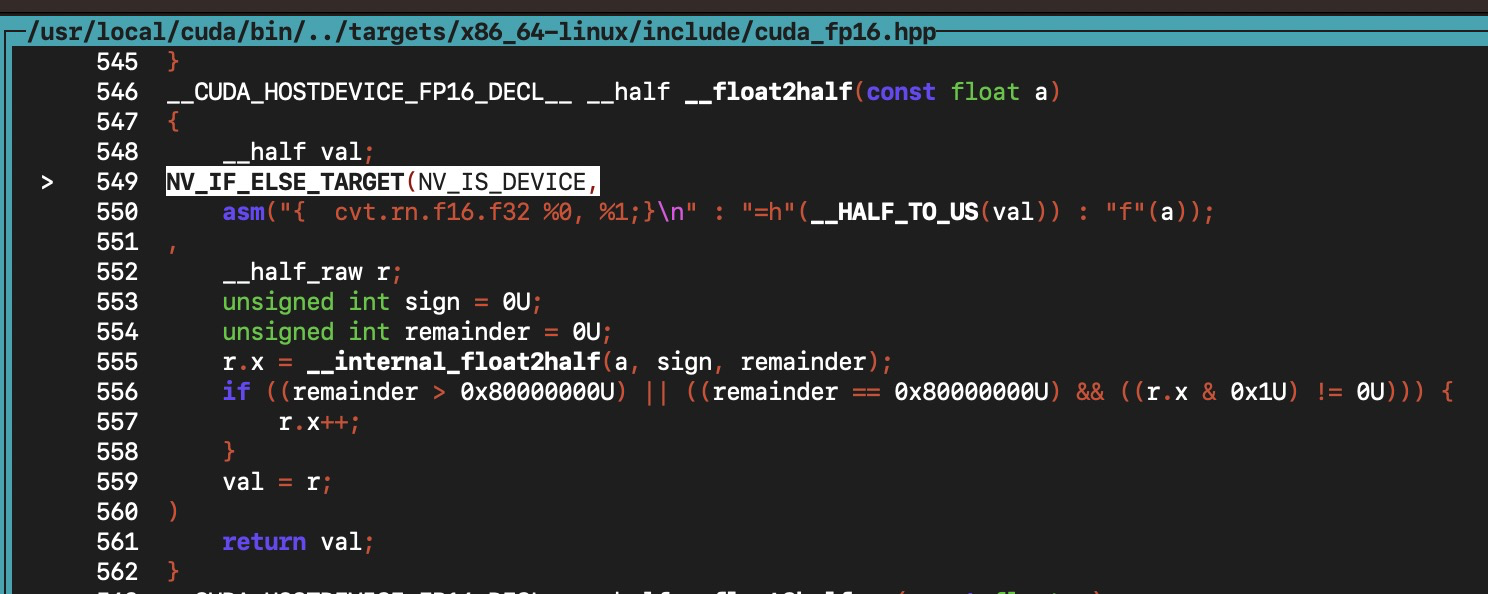
繼續使用 (cuda-gdb) s 會跳到下圖:
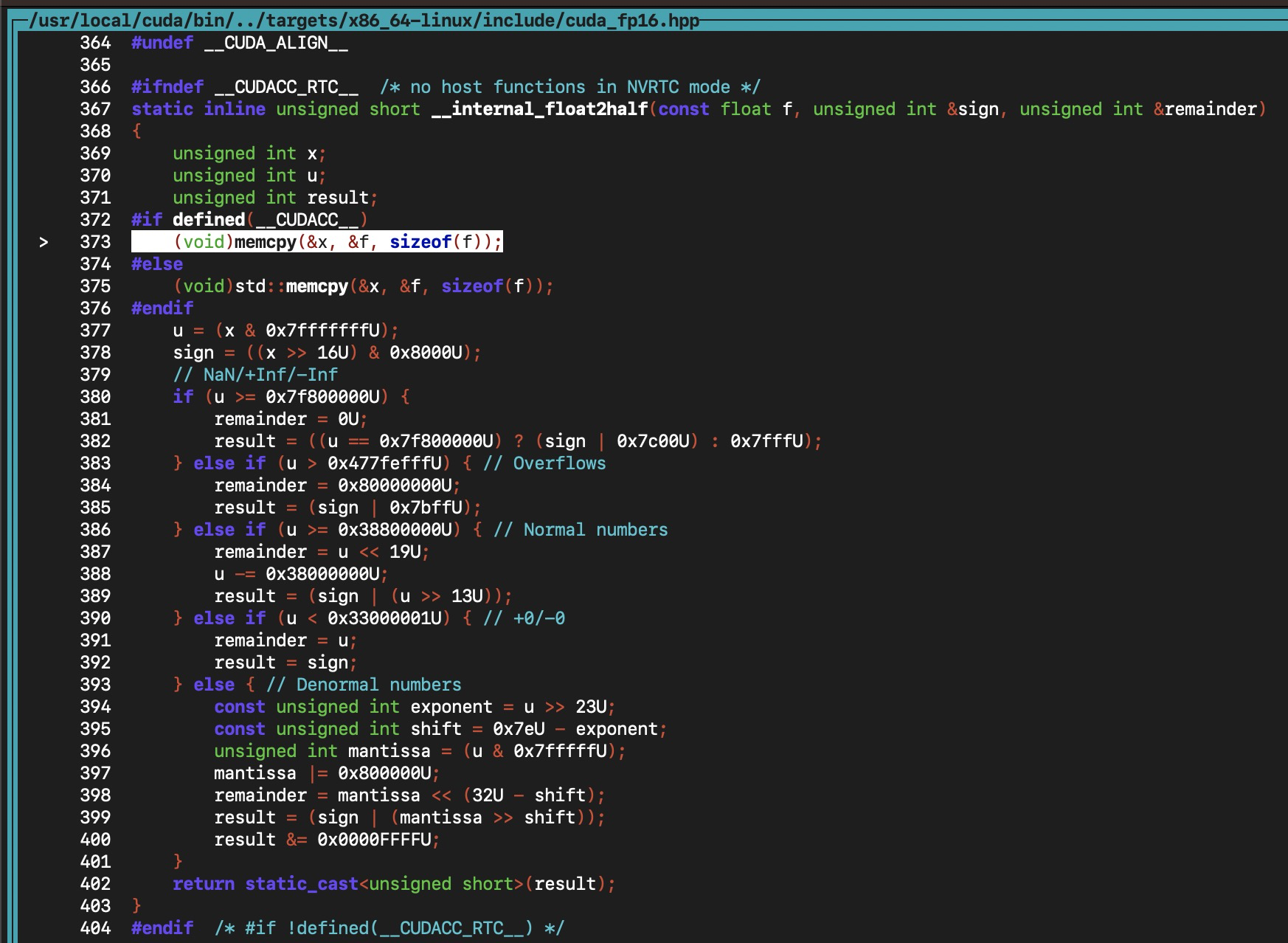
? ? 然后 使用 (cuda-gdb) next ,會經歷上圖代碼的主體邏輯,也就是一些位運算的那些邏輯。
? ? 結論便是,cuda 程序對 cpu 的 half(3.333) 使用了 cpu 軟件算法模擬了這個轉換過程,將 double 類型轉換成 fp16,即 half 類型?。
? ? 同時接下來會發現,兩個 half 類型的變量做乘法運算,會先將兩個 half 轉成 float,也是通過類似的軟件模擬的轉換方式,然后使用 cpu 的 float 乘法指令計算乘積,最后將 float 類型的乘積再轉回 half 類型,存入 half 類型的變量內存中。
接下來調試 half 的乘法運算符 * :
在 執行到 z = x*y; 時,使用(cuda-gdb) step,會跳進half 類型的乘法運算符 * 的實現代碼中,這里使用了 cpp 的重載功能(Operator Overloading) ,對運算符 * 做了重新實現?:

可以看到,operator * 重載時,函數體中調用了 __hmul(...) 來實現具體功能。
接下來繼續使用 (cuda-gdb) step,看看 __hmul(...) 的實現:
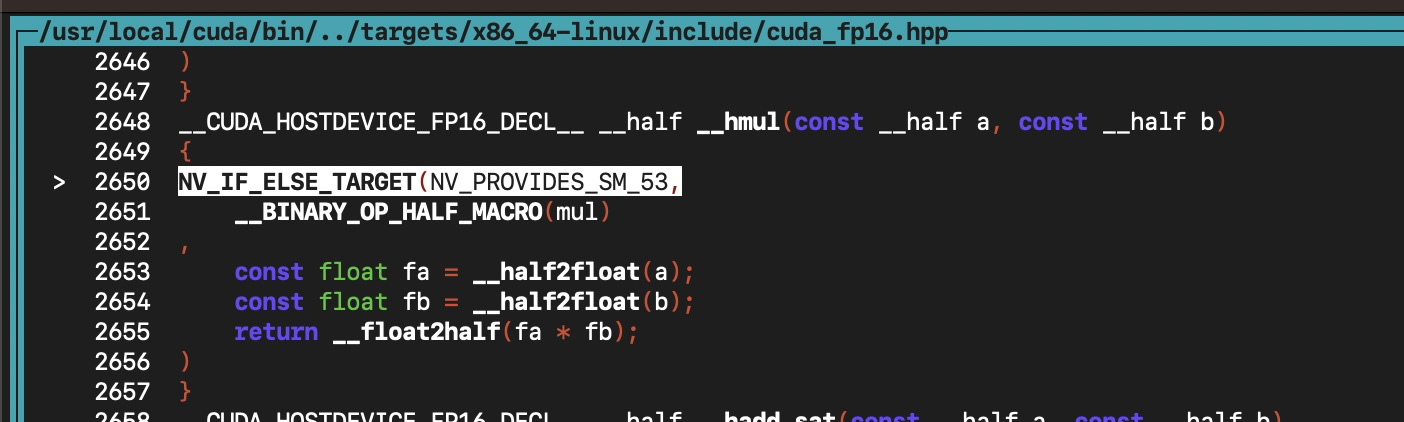
? ? ? ? 這里的 NV_IF_ELSE_TARGET(cond, , ) 表示可能存在兩種可能的實現方式,根絕第一個表達式的真假來選擇后邊的第二個或者第三個表達式。因為我們使用了 sm_120, 不等于 sm_53,可以初步猜測是調用了后邊的第三個表達式的內容來實現乘法。接下來通過 cuda-gdb 來單步調試驗證一下。
? ? ? ? 我們已經猜測會執行后邊三行代碼:2653,2654,2655等,但是為了驗證,這里做了個新函數 hhhaddd(),插入到第三個表達式的中間 float xfa = hhhaddd(fa); :
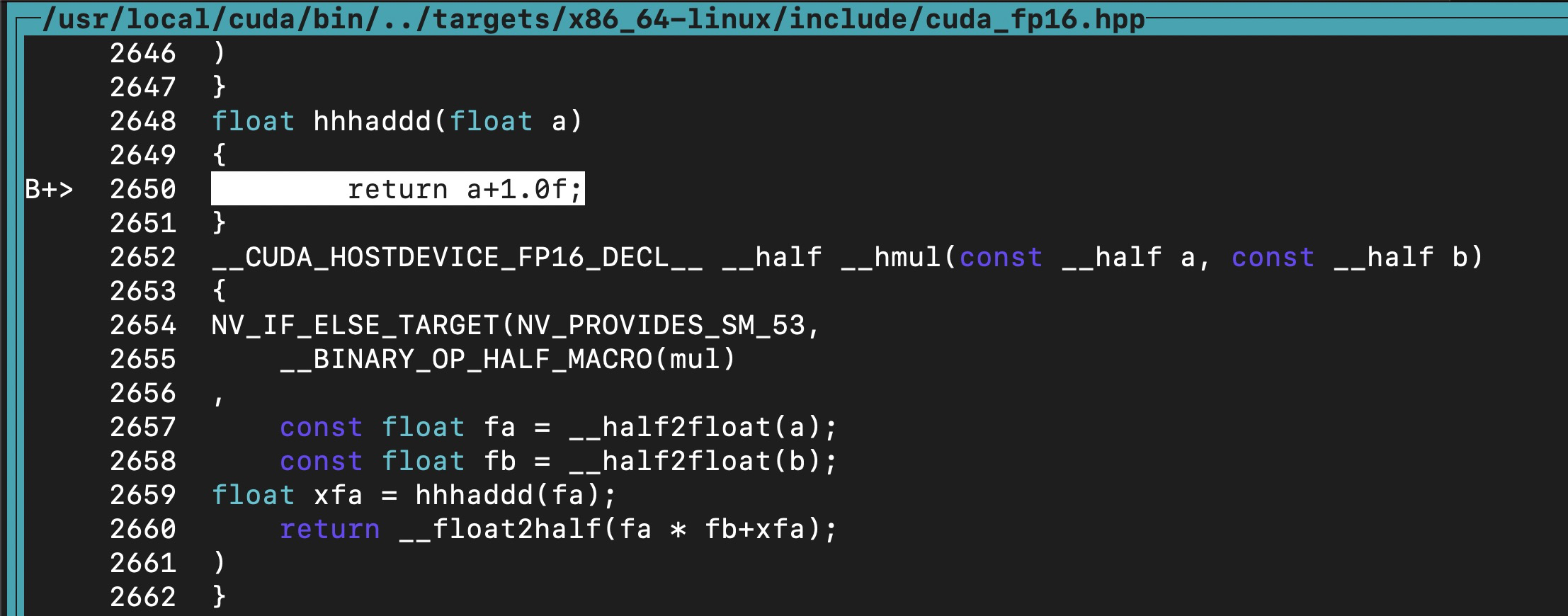
? ? ? ? 這會導致計算結果必然是錯誤的,但是可以給這個 hhhaddd 打斷點,然后直接 continue,果然停在了這個函數上。
? ? ? ? 說明執行了這三行代碼,即,half 的乘法,是使用 float32 的乘法指令來實現的:
const float fa = __half2float(a);const float fb = __half2float(b);return __float2half(fa * fb);2. 寫個 cpu gemm_fp16
? ? ? ? 矩陣小一點,方便驗證,其中的輸出格式,是為了能夠簡單地放進matlab 做對比驗證:
#include <stdio.h>
#include <stdlib.h>
#include "cuda_fp16.h"void init_matrix(half *A, int lda, int m, int n, bool colMajor)
{if(colMajor){for(int j=0; j<n; j++){for(int i=0; i<m; i++){half x = half(rand()*1.0f/RAND_MAX);A[i + j*lda] = x;printf(" %f", float(x));}}printf("\n\n");}else{for(int i=0; i<m; i++){for(int j=0; j<n; j++){half x = half(rand()*1.0f/RAND_MAX);A[i*lda + j] = x;printf(" %f", float(x));}}}
}void print_matrix(half *A, int lda, int m, int n, bool colMajor)
{printf("[ ...\n");for(int i=0; i<m; i++){for(int j=0; j<n; j++){if(colMajor)printf(" %5.4f, ", float(A[i + j*lda]));elseprintf(" %5.4f, ", float(A[i*lda + j]));}printf(" ; ...\n");}printf("]\n");
}void gemm_fp16_cpu(int M, int N, int K,half* A, int lda,half* B, int ldb,half* C, int ldc,half alpha, half beta)
{for(int i=0; i<M; i++){for(int j=0; j<N; j++){half sigma = half(0.0);for(int k=0; k<K; k++){sigma += A[i + k*lda]*B[k + j*lda];}C[i + j*ldc] = alpha*sigma + beta*C[i + j*ldc];}}
}int main()
{int m = 4;int n = 4;int k = 4;int lda = m;int ldb = k;int ldc = m;half *A_h;half *B_h;half *C_h;half alpha = half(1.0);half beta = half(1.0);A_h = (half*)malloc(lda * k * sizeof(half));B_h = (half*)malloc(ldb * n * sizeof(half));C_h = (half*)malloc(ldc * n * sizeof(half));init_matrix(A_h, lda, m, k, true);init_matrix(B_h, ldb, k, n, true);init_matrix(C_h, ldc, m, n, true);printf("A_h =");print_matrix(A_h, lda, m, k, true);printf("B_h =");print_matrix(B_h, ldb, k, n, true);printf("C_h =");print_matrix(C_h, ldc, m, n, true);gemm_fp16_cpu(m, n, k, A_h, lda, B_h, ldb, C_h, ldc, alpha, beta);printf("C_h =");print_matrix(C_h, ldc, m, n, true);return 0;
}Makefile:
EXE := hello_gemm.fp16all: $(EXE)%: %.cunvcc --gpu-architecture=sm_120 -g $< -o $@ -I /usr/local/cuda/include.PHONY: clean
clean:-rm -rf $(EXE)編譯運行:
$ make
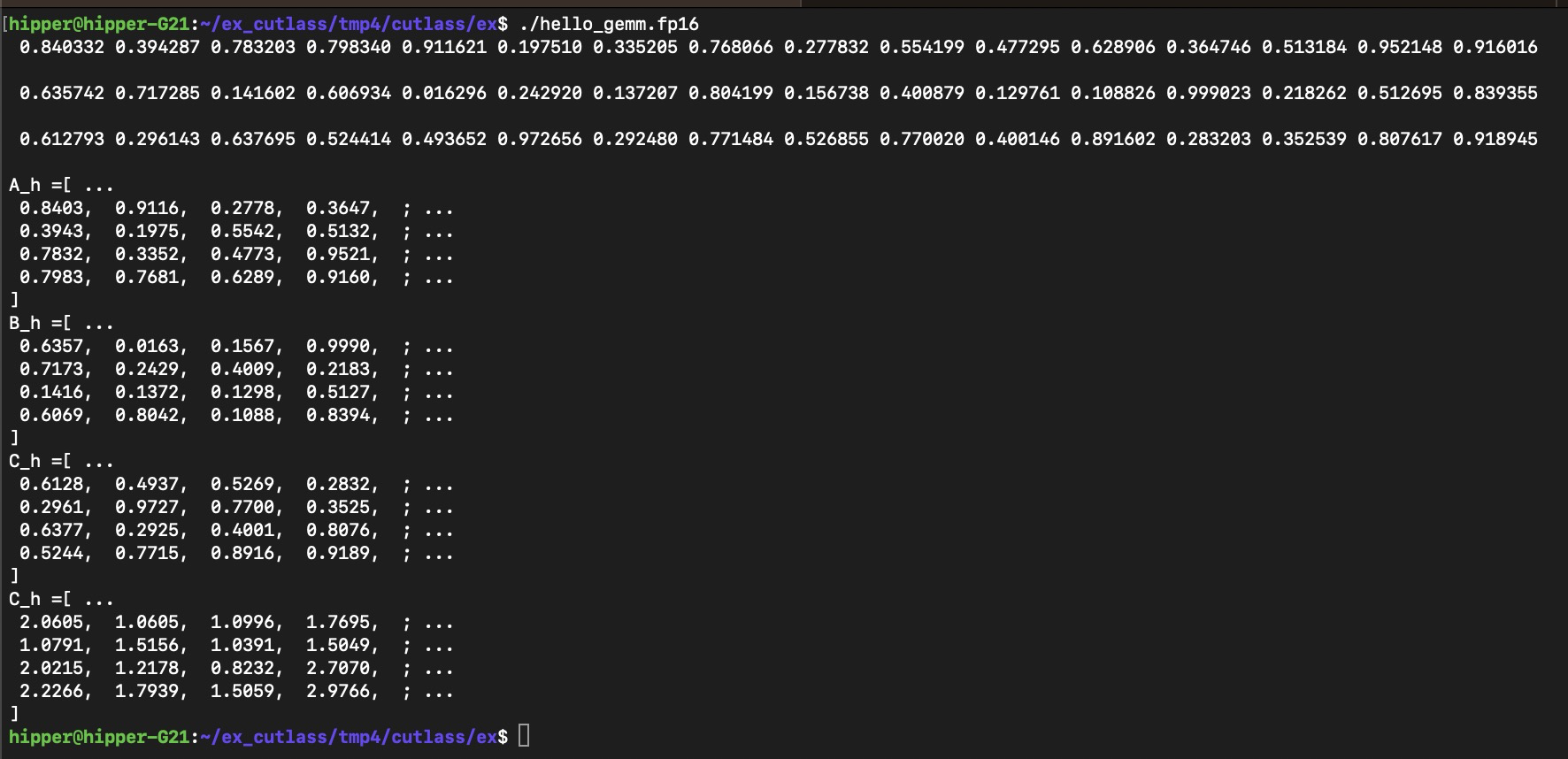
octave 驗證:
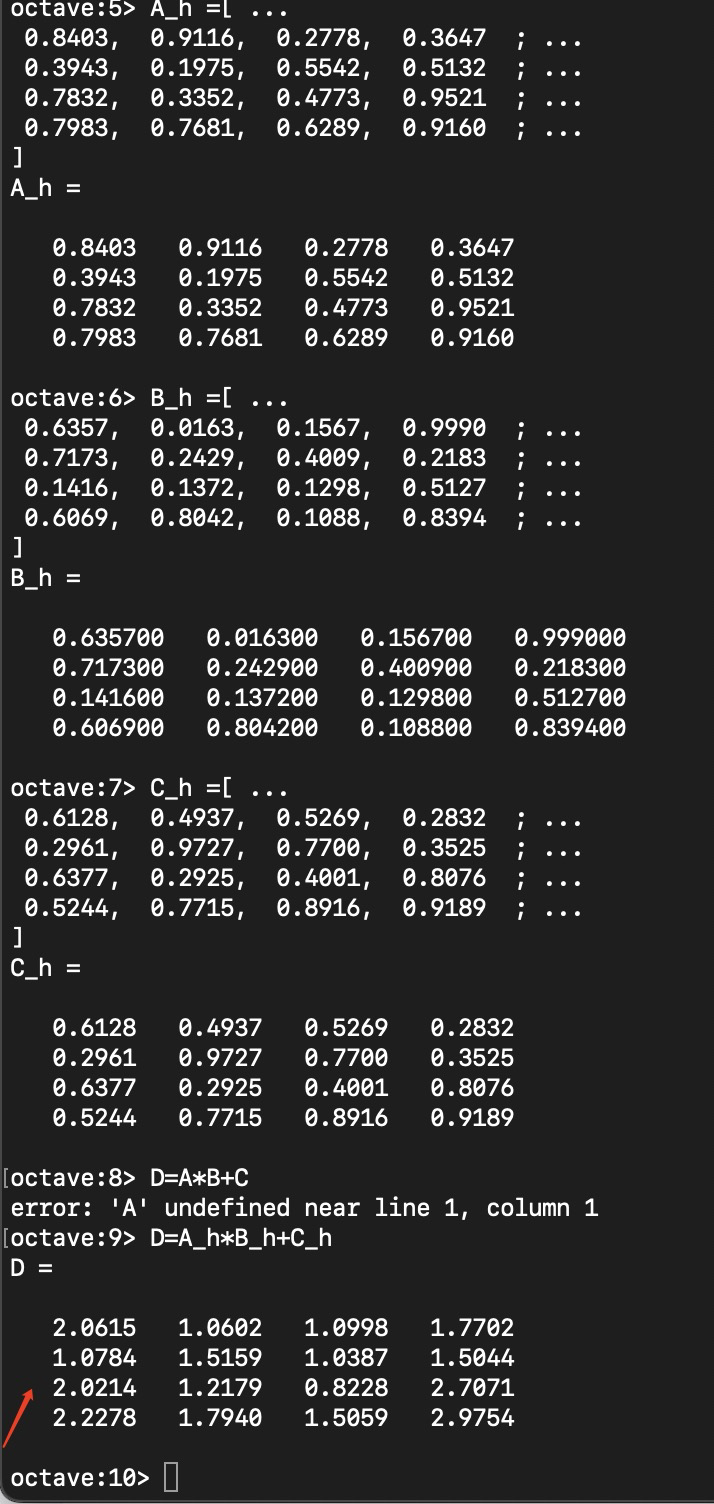
誤差范圍內,結果是相等的。
3. GPU 的最簡單版本 gemm_v01
? ? ? ? 簡單主要是指沒有任何優化考慮。單個warp 工作,也不考慮數據復用、異步加載,不考慮 tensor core 加速,流水線等都不考慮。
我們可以先稍微看看 RTX 5080 的硬件信息:
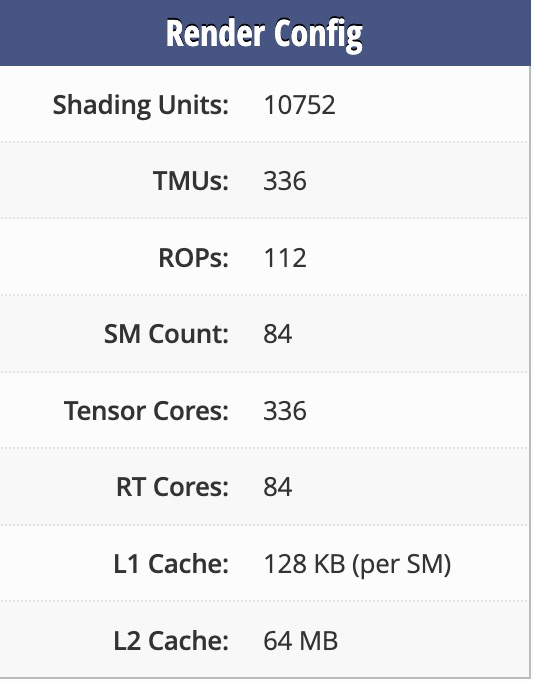
10752 個cuda core,每個warp 占 32 個 cuda core【注,從 Ampere 開始,每個warp 同時占用 32 個 cuda core;之前架構是 16 個 cuda core 迭代兩次完成 32 個 thread? 的任務;】,
總共含 84 個sm,
所以,每個sm 存在 128個 cuda core,也就是 128/32 = 4 個 同時運行的 warp,也即 4 個 tensor core/sm;也就是每個 block 最多可以同時占用 4 個tensor core。
這個 v01 版本不考慮使用 tensor core,僅啟動單個warp 工作。
ex/hello_gemm.fp16.cu
#include <stdio.h>
#include <stdlib.h>
#include "cuda_fp16.h"void init_matrix(half *A, int lda, int m, int n, bool colMajor)
{if(colMajor){for(int j=0; j<n; j++){for(int i=0; i<m; i++){half x = half(rand()*1.0f/RAND_MAX);A[i + j*lda] = x;printf(" %f", float(x));}}printf("\n\n");}else{for(int i=0; i<m; i++){for(int j=0; j<n; j++){half x = half(rand()*1.0f/RAND_MAX);A[i*lda + j] = x;printf(" %f", float(x));}}}
}void print_matrix(half *A, int lda, int m, int n, bool colMajor)
{printf("[ ...\n");for(int i=0; i<m; i++){for(int j=0; j<n; j++){if(colMajor)printf(" %5.4f, ", float(A[i + j*lda]));elseprintf(" %5.4f, ", float(A[i*lda + j]));}printf(" ; ...\n");}printf("]\n");
}void gemm_fp16_cpu(int M, int N, int K,half* A, int lda,half* B, int ldb,half* C, int ldc,half alpha, half beta)
{for(int i=0; i<M; i++){for(int j=0; j<N; j++){half sigma = half(0.0);for(int k=0; k<K; k++){sigma += A[i + k*lda]*B[k + j*lda];}C[i + j*ldc] = alpha*sigma + beta*C[i + j*ldc];}}
}__global__ void gemm_v01_fp16_all(int M, int N, int K,half* A, int lda,half* B, int ldb,half* C, int ldc,half alpha, half beta)
{unsigned int i = threadIdx.x;unsigned int j = threadIdx.y;if(i==16) printf("%d ", j);
printf("threadIdx.x=%d ", threadIdx.x);half sigma = half(0.0);for(unsigned int k = 0; k<K; k++){sigma += A[i + k*lda]*B[k + j*ldb];}C[i + j*ldc] = alpha*sigma + beta*C[i + j*ldc];
}void gemm_v01_test(int m, int n, int k,half* Ah, int lda,half* Bh, int ldb,half* Ch, int ldc,half alpha, half beta,half* Cd2h)
{//1. alloc ABC_dhalf * Ad = nullptr;half * Bd = nullptr;half * Cd = nullptr;cudaMalloc((void**)Ad, lda*k*sizeof(half));cudaMalloc((void**)Bd, ldb*n*sizeof(half));cudaMalloc((void**)Cd, ldc*n*sizeof(half));//2. cpy H2DcudaMemcpy(Ad, Ah, lda*k*sizeof(half), cudaMemcpyHostToDevice);cudaMemcpy(Bd, Bh, ldb*n*sizeof(half), cudaMemcpyHostToDevice);cudaMemcpy(Cd, Ch, ldc*n*sizeof(half), cudaMemcpyHostToDevice);//3. Gemm_v01, simple cuda core gemmdim3 block_;dim3 grid_;block_.x = 32;block_.y = 32;grid_.x = 1;grid_.y = 1;printf("__00________\n");gemm_v01_fp16_all<<<grid_,block_>>>(m, n, k, Ad, lda, Bd, ldb, Cd, ldc, alpha, beta);
printf("##11########\n");//4. cpy D2HcudaMemcpy(Cd2h, Cd, ldc*n*sizeof(half), cudaMemcpyDeviceToHost);//5. free ABC_dcudaFree(Ad);cudaFree(Bd);cudaFree(Cd);
}
int main()
{int m = 32;int n = 32;int k = 32;int lda = m;int ldb = k;int ldc = m;half *A_h;half *B_h;half *C_h;half *C_d2h;half alpha = half(1.0);half beta = half(1.0);A_h = (half*)malloc(lda * k * sizeof(half));B_h = (half*)malloc(ldb * n * sizeof(half));C_h = (half*)malloc(ldc * n * sizeof(half));C_d2h = (half*)malloc(ldc * n * sizeof(half));init_matrix(A_h, lda, m, k, true);init_matrix(B_h, ldb, k, n, true);init_matrix(C_h, ldc, m, n, true);printf("A_h =");print_matrix(A_h, lda, m, k, true);printf("B_h =");print_matrix(B_h, ldb, k, n, true);printf("C_h =");print_matrix(C_h, ldc, m, n, true);gemm_fp16_cpu(m, n, k, A_h, lda, B_h, ldb, C_h, ldc, alpha, beta);printf("C_h =");print_matrix(C_h, ldc, m, n, true);gemm_v01_test(m, n, k, A_h, lda, B_h, ldb, C_h, ldc, alpha, beta, C_d2h);printf("C_d2h =");print_matrix(C_d2h, ldc, m, n, true);return 0;
}未完待續
。。。。



)
)


的設計與實現)

)





)



