1.0: (adaptive clasisfier guidance,input 輸入一個沒cam的branch;提高triplane分辨率)
- 總結:
- 大規模再train zero123++,但角度設置不同;adaptive clasisfier guidance(front view和早期,使用更大的CFG)
- 對input img再加一個cam embeddings全0的branch來融入其特征
- 用了一種線性復雜度的方法來提高triplane的分辨率(avoid self attention on higher-resolution triplane tokens)
- (text就是先從text生成img,然后都走img to 3D)
- intro
- 還是multiview diffusion + LRM的路線。
- address的問題:
- multiview inconsistency,
- 依賴已知的pose或view
- Method:
- Multiview Diffusion:
- 基本情況:Zero123++ 擴大規模 & 更改角度設置
- 還是基于Zero123++再訓練
- 注意Zerro123++和InstantMesh的角度是(ele是absolute的)
[圖片] - 有側面,沒正面。
- 注意Zerro123++和InstantMesh的角度是(ele是absolute的)
- 擴大:larger parameters, larger dataset
- 角度:Ele: 0; azimuth: 0,60,120,180,240,300
- 有正面,沒側面。
- 說這個ele 0, 可以最大化view中的visible area。emm。放棄上下視角?
- 分辨率:lite還是320*320, standard進一步擴大到512了。
- 還是基于Zero123++再訓練
- Adaptive Classifier-free guidance (front view和早期,使用更大的CFG)
- 發現:CFG越大,幾何更好但texture不行;正面越高保真但背面越暗
- 因此:front view和早期,使用更大的CFG
- 基本情況:Zero123++ 擴大規模 & 更改角度設置
- Sparse-View Reconstruction (LRM part)
- Hybrid inputs: 同時使用input img和生成的multiview imgs(其實對于relative角度的方法并不存在此問題)
- 對input img,專門搞個 角度未知 的branch來融入其信息。(就是camera embedding全設為0)
- SR
- 用了一種線性復雜度的方法來提高triplane的分辨率(avoid self attention on higher-resolution triplane tokens)
- 起初是64641024,(用一個線性層把11 給上采樣為44),得到256256120
- 3D Rep:SDF + MC + UV unwrapping(是否稍顯原始了啊??Instantmesh
已經上flexicubes了啊)
- Hybrid inputs: 同時使用input img和生成的multiview imgs(其實對于relative角度的方法并不存在此問題)
- Multiview Diffusion:
2.0: 幾何Hunyuan3D-DiT + 紋理Hunyuan 3D-Paint (albedo)
- Hunyuan3D- DiT: 一個正常的image-conditioned DiT(Denoising Transformer),latent的。這個latent是用點云來訓練的。(用到Uniform和Importance sampled points)mesh表征是SDF + Marching Cubes.
- Hunyuan3D-Paint: 輸入的是img(delighting)和multiview normal 和 multiview position;然后對輸出進行SR
- Double-stream Image Conditioning Reference-Net:
- 第一個stream是 直接使用VAE的feature,設其time step為0
- 第二個stream是凍結SD的weights。
- Texture Baking (怎么把multiview imgs變為3Dmesh的texture?)
- Dense-view inference:聽上去好像是,train的時候每次從44個pre-set view中隨機選擇6個來輸出并train,這樣inference的時候,這44個view就都能生成
- 對輸出的multiview imgs逐個進行super resolution
- Texture inpainting: (鄰居擴散,weighted sum)沒有對應顏色的UV空間的像素點(texel),用他對應的有顏色的3D點的鄰居點的weighted sum來填色。
- Double-stream Image Conditioning Reference-Net:
- Preprocessing:
- Image Delighting: 大規模數據集下全監督學習train的。
- View Selection:
- 計算每個視角的信息增益,貪婪選擇(先固定前后左右,然后選盡可能涵蓋更多unseen regions的))
2.1 Paint時增加了material的支持(PBR(Physically-Based Rendering))
- 這個material似乎是metallic和roughness這兩項。(所以就是gen的時候不止gen albedo,還gen他倆)
2.5 new shape generator LATTICE
geometry 變精致多了:

- Detailed Shape Generation: LATTICE
- 一個diffusion model,輸入是single or 4 view images
- 核心點:
- scaling up
- 還用了guidance and step distillation 來減少inference時間
- Texture
-
extend 2.1
-
inherit 3D-aware RoPE to enhance cross-view consistency
-
multi(dual)- channel attention mechanism to ensure sptial alignment
- 無論albedo還是MR,都用albedo的attention mask
-
PolyGen:布線(重拓撲)工具
沒有開源,沒有technical report。
可以參考官方的這篇文章:
https://mp.weixin.qq.com/s/l12y2IPExhvz2fvUJPm-tw
和量子位的這篇文章:
https://baijiahao.baidu.com/s?id=1837134756242570771&wfr=spider&for=pc
跟想象的一樣,是MeshGPT這一脈的
Contributions:
- 自研高壓縮率表征BPT
- 一個面不再需要三個頂點xyz一共9個token了。平均2.3個token每個triangle,比EdgeRunner的四五個更少==(這樣可以支持更復雜(多面)的mesh了!)==
- 強化學習后訓練==(穩定生成和美術規范獎勵)==
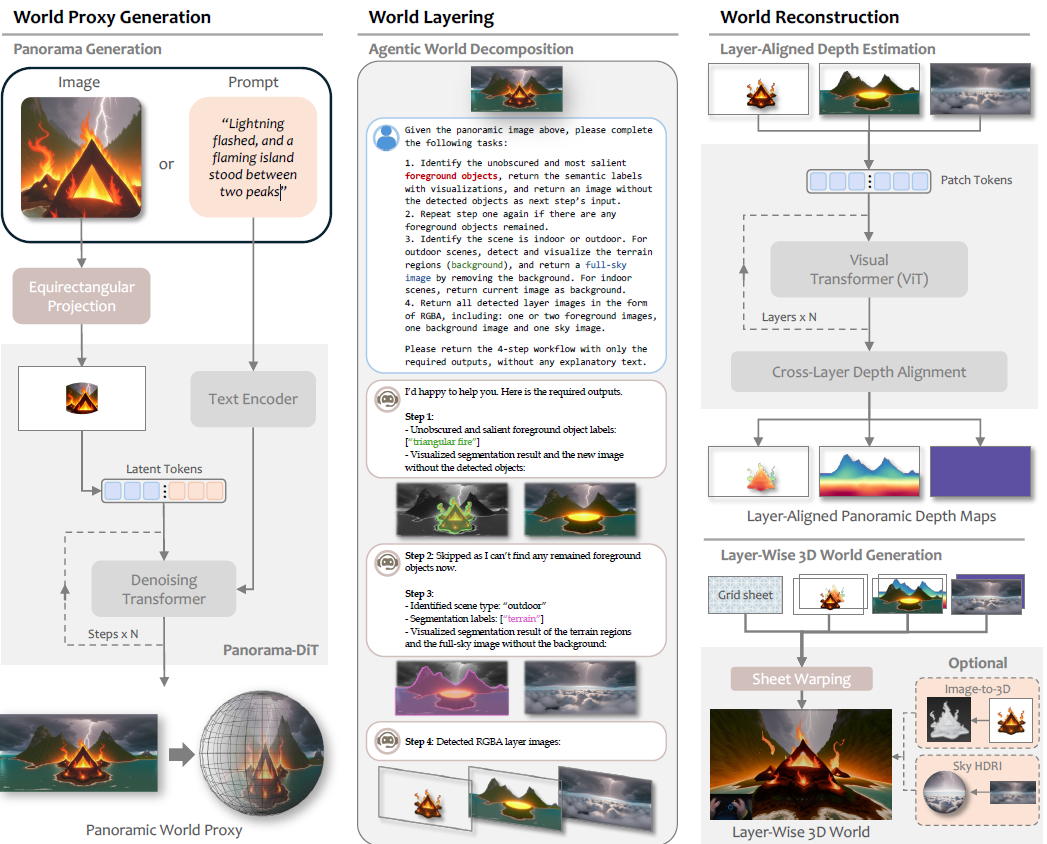
Hunyuan World 1.0
概述
- 輸入single image 或text prompt
- 輸出一個場景的mesh,是分層的(前景物體,地形,天空)
- 方法:三步走
- 先生成全景圖
- 用一個視覺LLM來把全景圖解耦成前景物體,地形,天空(得到這三者分別的圖像)
- 對他們三個進行深度估計并對其;再重建出mesh
:原理、實踐與應用場景)









)


)



Android窗口管理系統分析)

