Fast and accurate object detector for autonomous driving based on improved YOLOv5
發表時間:2023年;期刊:scientific reports
論文地址
摘要
自動駕駛是人工智能的一個重要分支,實時準確的目標檢測是保證自動駕駛車輛安全穩定運行的關鍵。為此,本文提出了一種基于改進的YOLOv5的快速準確的自動駕駛目標檢測器。首先,對YOLOv5算法進行了改進,引入結構重參數(REP),通過訓練-推理解耦提高了模型的精度和速度。此外,在訓練階段引入了神經架構搜索法對多分支再參數化模塊中的冗余分支進行裁剪,提高了訓練的效率和精度。最后,在網絡中加入小目標檢測層,并在各檢測層加入協調注意機制,以提高模型對小型車輛和行人的識別率。實驗結果表明,該方法在Kitti數據集上的檢測準確率達到96.1%,FPS達到202,優于當前的許多主流算法,有效地提高了無人駕駛目標檢測的準確性和實時性。
引言
近年來,機動車保有量大幅增加,極大地方便了人們的出行。然而,這一增長導致了日益擁擠的交通狀況和交通事故頻率的上升,這對安全出行構成了重大挑戰。面對日益復雜的交通環境,往往需要個人憑自身經驗選擇合適的出行路線,應對路上可能出現的各種突發事件。即使是經驗豐富的司機也不能幸免于遇到不可預測的危險。
隨著大數據、人工智能等計算機技術的發展,智慧城市、自動駕駛等技術手段為緩解交通壓力和交通安全問題提供了新的解決方案。無論是智能城市還是自動駕駛,都需要對交通場景進行分析,以獲取有用的信息,即感知外部環境。計算機視覺技術是現階段感知外部環境最方便、最快捷的技術手段,而目標檢測是計算機視覺中最基本、最關鍵的任務。目標檢測識別圖像中目標的類別和位置,為計算機視覺中的場景分析提供詳細的基本環境信息。因此,交通場景中的目標檢測就成為一個不可或缺的研究方向。當目標檢測算法應用于交通場景時,對算法有很高的要求。該算法不僅要求具有較高的識別精度,而且要求滿足真實場景的要求。以往對目標檢測的研究大多集中在如何通過增加網絡層數來提高算法的檢測精度,進一步優化現有網絡。雖然模型的檢測精度可以得到一定程度的提高,但由于模型較大,使得算法很難在計算能力較低的設備上運行,檢測速度低得令人不快。在大多數交通場景中,設備都在戶外使用,特別是在自動駕駛領域,用于運行算法的硬件設備不能具有強大的計算能力。(研究背景)
因此,如何在不影響算法精度性能的情況下,使目標檢測算法盡可能快地實現,從而將目標檢測算法移植到車輛上的終端應用中,實現實時的自主駕駛目標檢測是一個棘手的挑戰。高精度使得目標檢測算法能夠更準確地定位和識別前方的車輛或行人,而快速的速度使模型更快地獲取外部對象的變化,從而輔助控制系統更合理地運行,確保車內乘員的安全。因此,設計一種精度高、速度快的目標檢測算法是實現無人駕駛目標檢測的關鍵。
對于普通的自動駕駛目標檢測深度學習方法來說,準確率和速度是兩個很難平衡的指標。提出了一種基于改進的YOLOv5算法的快速準確的目標檢測算法,實現了檢測精度和速度的雙重提高。主要貢獻概括如下:
1、采用YOLOv5算法作為基線算法,引入結構重參數化(Rep)模塊進行改進,通過訓練推理解耦提高了模型的精度和速度。
2、將神經結構搜索(NAS)方法應用于結構重參數化模塊,并自動去除多分支模塊中的冗余分支,提高了模型訓練的效率和精度。
3、針對車輛和行人小目標檢測精度低的問題,增加了一個小目標檢測層,并在各檢測層中加入協調注意(CA),提高了模型對小目標和不可辨認目標的識別精度。
方法
YOLOv5
YOLOv5是目前最主流的單級目標檢測算法之一。YOLOv5算法由三個模塊組成:CSP-DarkNet主干網絡、FPN+PAN Neck和預測頭。如圖所示,將尺寸為3×640×640的圖片輸入到網絡中。在骨干網部分,CBS層用于下采樣,CSP模塊用于特征提取。經過5次下采樣后,特征圖的大小達到512×20×20。最后,連接SPPF模塊,實現不同感受野特征圖的融合。在頸部網絡部分,特征映射首先經過降維路徑,然后再經過降維路徑。大小分別為512×20×20、256×40×40、128×80×80的特征地圖通過兩條路徑完全融合。在頭網絡部分,三種大小的特征映射進入探測頭,然后通過1×1卷積層。大小保持不變,通道數變為3×(NC+5),其中3表示三種不同縱橫比的錨框,NC表示類別數,5表示用于指示錨幀位置的4個參數加上1個錨幀前景概率。
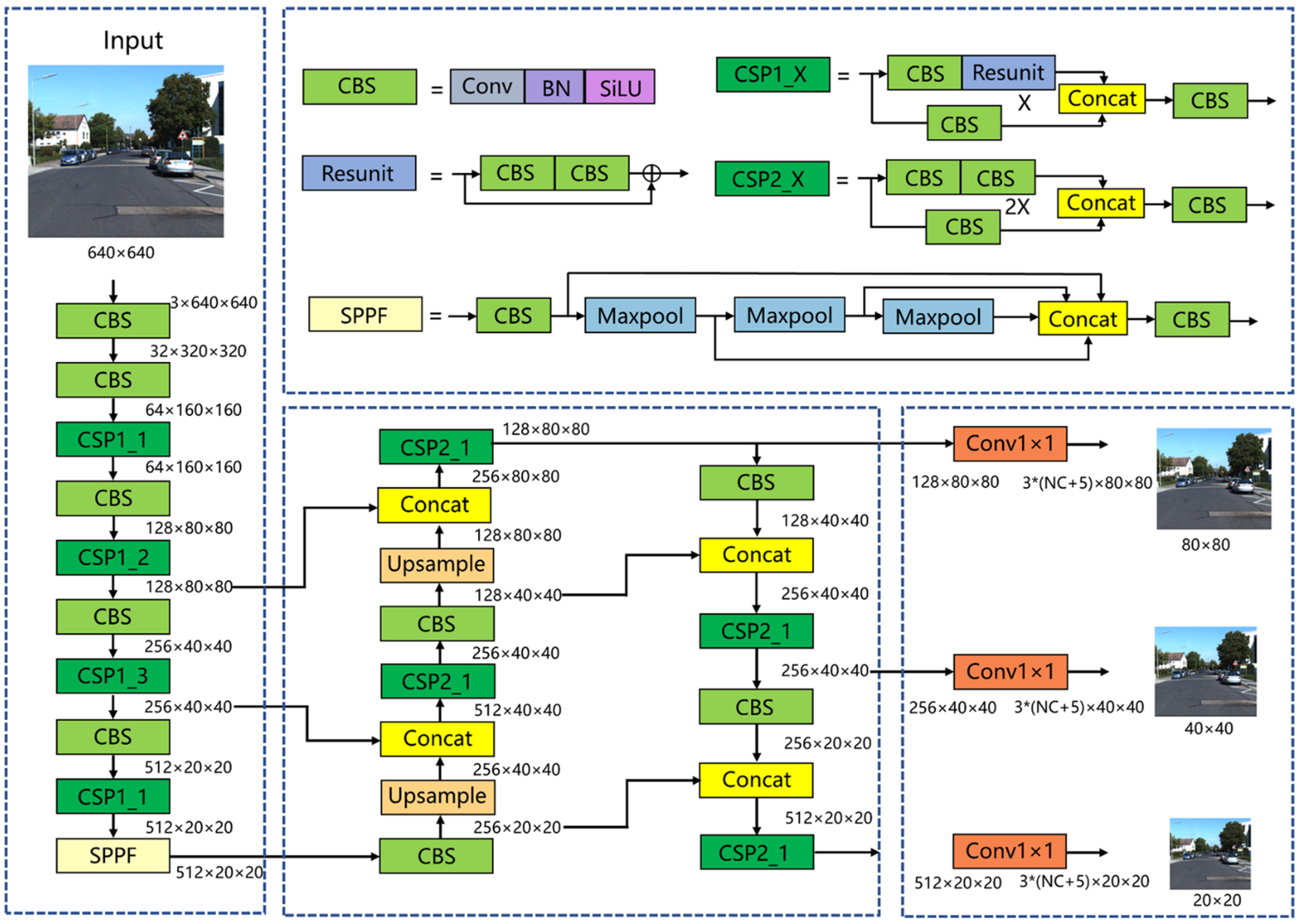
改進YOLOv5總體結構
首先將骨干網中的模塊全部改為RepNAS模塊,下采樣的RepNAS模塊數量為1個,未下采樣的RepNAS模塊數量分別為1、3、3、13個。在訓練階段,非下采樣RepNAS模塊包含7個分支,而下采樣RepNAS模塊包含6個分支,這是因為下采樣RepNAS模塊的輸入和輸出特征圖大小不同,并且不存在標識分支。NAS在訓練階段判斷每個模塊不同分支的重要性,不斷剔除不重要的分支,減少模型冗余,提高模型訓練精度和訓練效率。REP通過對訓練后的參數進行等價變換,實現了RepNAS模塊結構的簡化。也就是說,將主干網絡中的所有RepNAS模塊轉換為3×3卷積層,使主干網絡在推理階段成為VGG式的體系結構,使得推理速度顯著加快,并保持了模型訓練的高精度。其次,增加了×160×160的小目標特征檢測層。如圖所示,在頸部網絡中,160×160特征映射利用骨干網絡中的淺層信息進行特征融合。淺層網絡特征圖分辨率較高,包含的小目標信息較多,因此增加一個大小為160×160的檢測層可以更好地實現對小目標的定位和識別。最后,在每個檢測層之前都有CA注意機制。之所以在檢測層之前添加CA,是因為檢測層之前的特征映射已經被充分提取和融合,并且語義信息是完整的。因此,在這里加入注意機制可以使模型更多地關注語義豐富的通道。
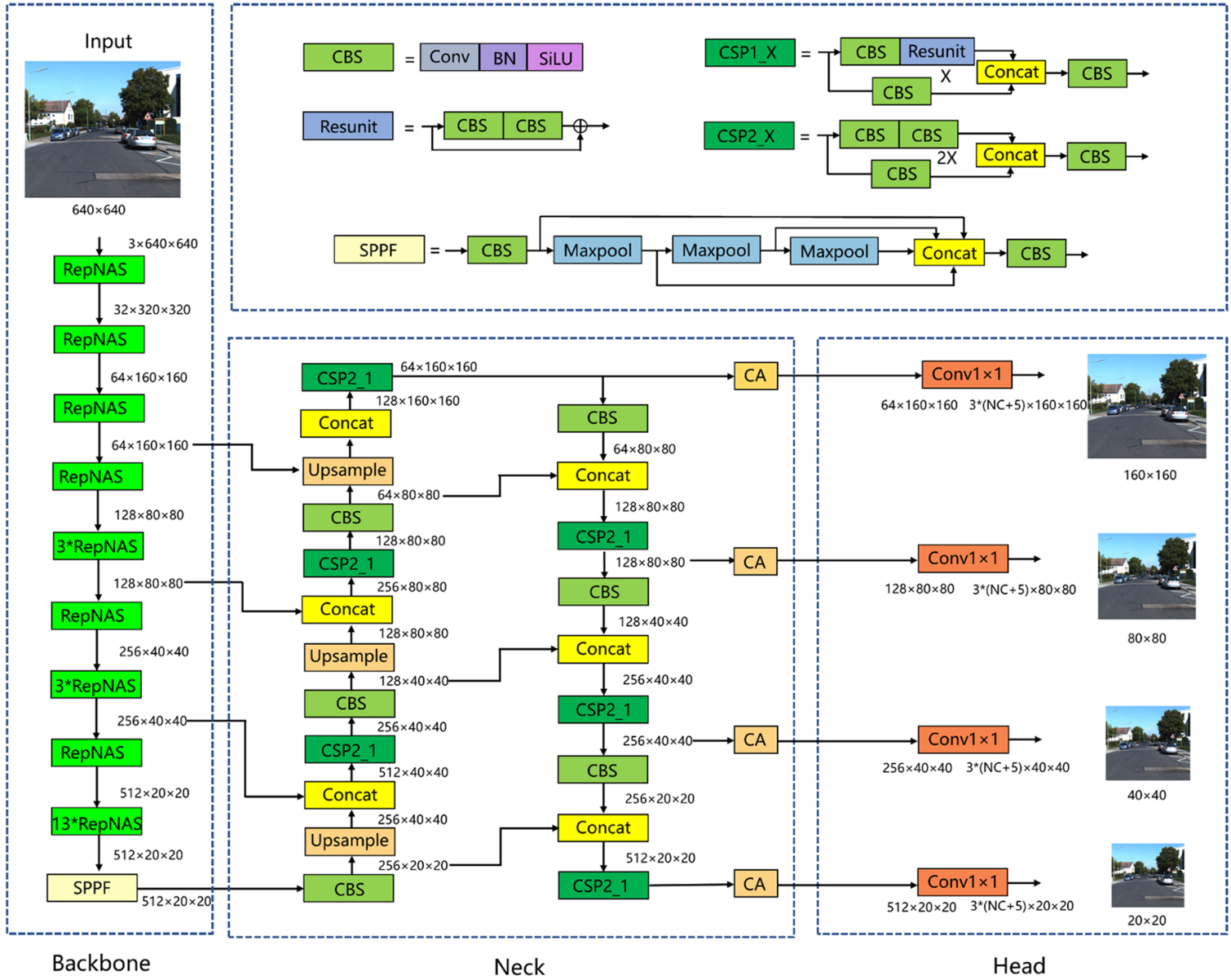
結構重參數化
結構重參數化是一種利用訓練-推理解耦的方法,使模型在訓練階段具有較高的精度,在推理階段具有較高的速度。具體地說,在訓練階段首先構建多分支結構,訓練后將多分支結構融合成單向結構進行模型推理和部署。在當今實際的自動駕駛場景中,推理模型往往部署在邊緣AI芯片上,并在邊緣設備上實時檢測捕獲的畫面。因此,模型需要在保證精度的前提下具有較快的推理速度,而結構再參數化可以很好地滿足這一條件。結構重新參數化由以下基本融合模塊組成:
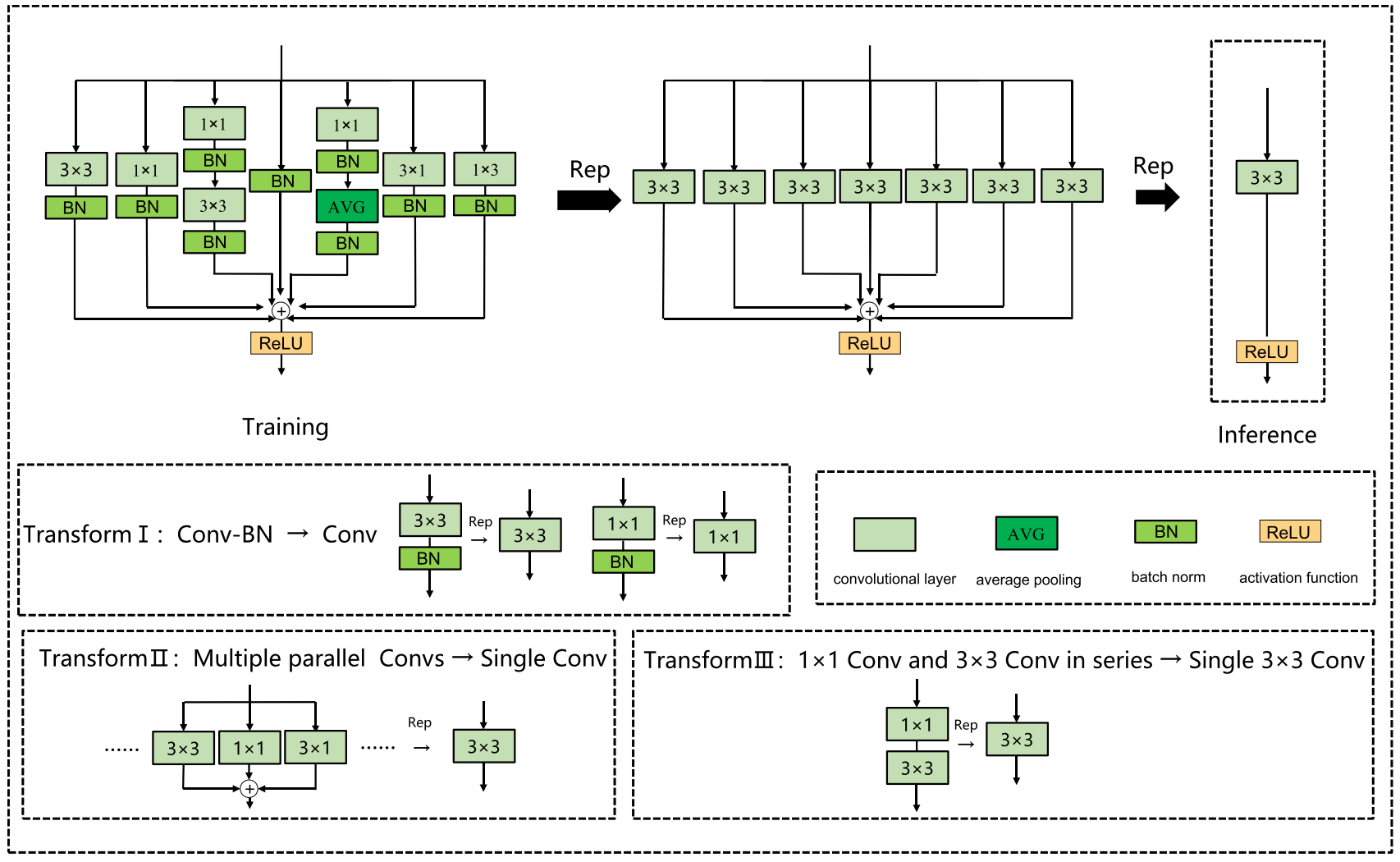
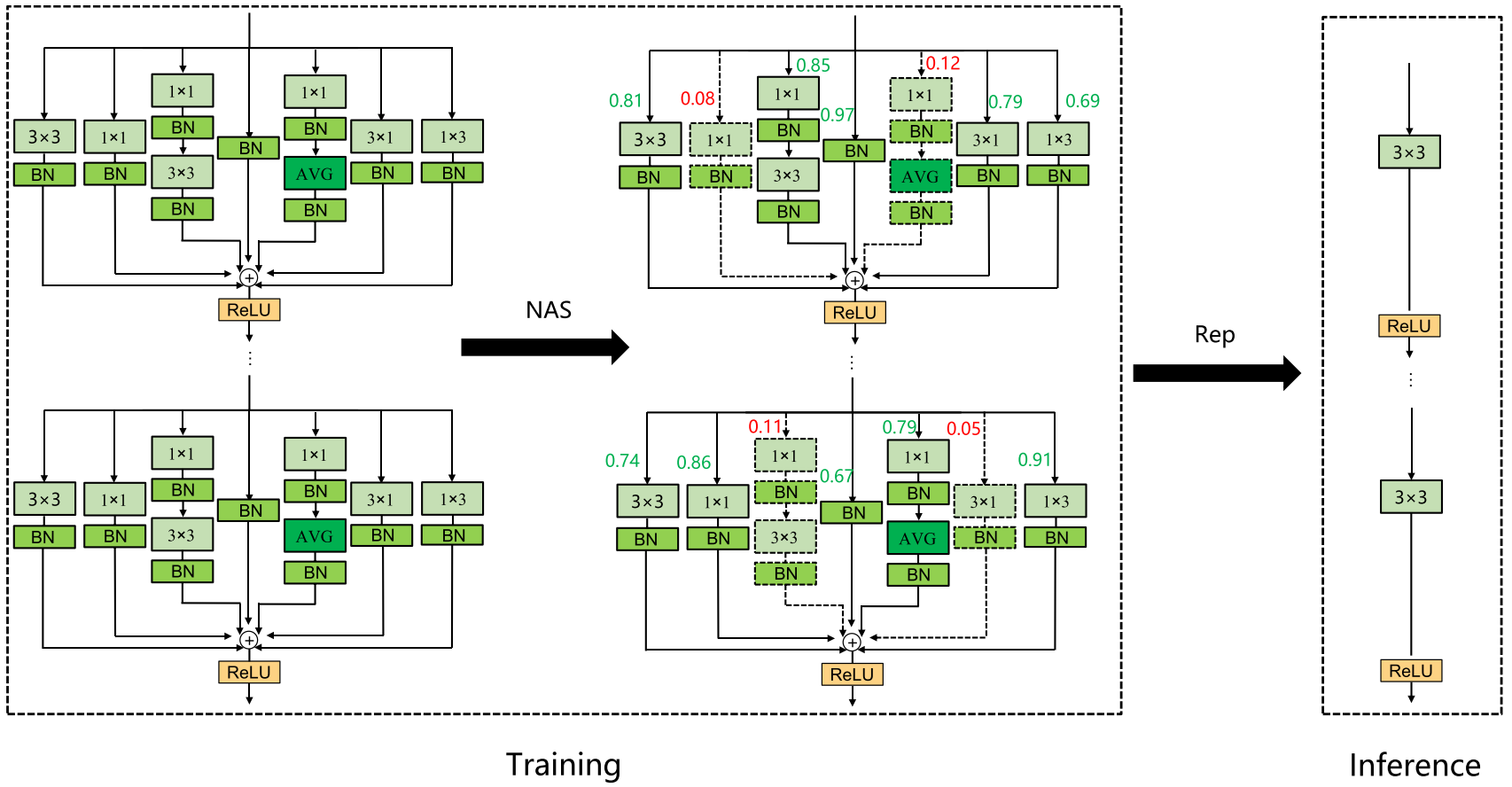
神經架構搜索(NAS)
神經結構搜索是當前計算機視覺領域的一個研究熱點,它利用強化學習、進化算法、梯度方法等策略自動搜索網絡的最優結構。受Zhang等人的啟發[25],本文將NAS技術與結構重參數化模塊相結合,設計了RepNAS模塊,如圖所示。RepNAS通過判斷多個分支中不同分支的重要性來自動裁剪一些冗余分支,從而達到減少模型訓練時間和內存,提高模型精度的效果。
小目標檢測層
YOLOv5網絡的探測頭共包含三個檢測層,規模分別為80×80、40×40、20×20。其中,80×80檢測層的每平方面積最小,位置信息更準確,更適合檢測小目標。同樣,40×40的檢測層適合檢測中等物體,而20×20的檢測層更適合檢測大型物體。在車輛檢測或行人檢測中,許多目標只占原始圖像的一小部分。為了提高小目標檢測算法的檢測精度,我們增加了一個160×160的檢測層,用于對較小的車輛或行人進行精確定位和識別。
協調注意力機制(CA)
針對輸入圖像中某些車輛和行人所占比例較小,導致識別精度不高的問題,引入了協調注意機制。它可以將水平和垂直位置信息編碼到通道注意機制中,使網絡能夠更好地聚焦目標位置信息。經典的SE注意機制只考慮通道之間的信息,而忽略位置信息。CBAM改進了SE,在減少特征地圖通道的數量后使用卷積來提取位置注意信息。然而,卷積只能提取本地關系,很難關注遠程信息。CA能夠將水平和垂直位置信息編碼為通道注意力,并同時捕獲通道間信息和與方向相關的位置信息。它可以提高模型感知目標位置的能力,從而實現對汽車和行人的更準確的定位和識別。
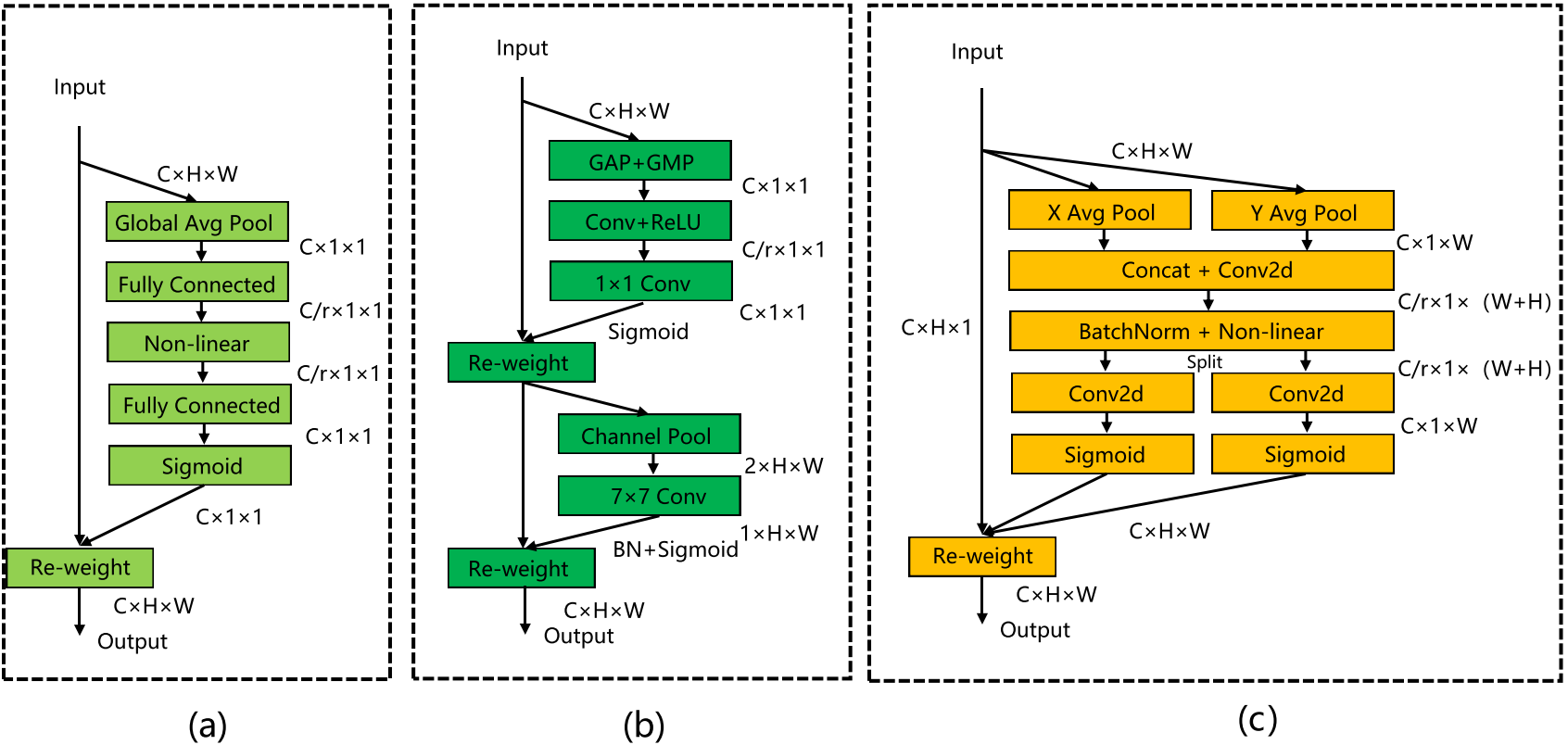
(a)SE;(b)CBAM;(c)CA
實驗及結果分析
實驗數據集
在自動駕駛領域應用最廣泛的KITTI數據集上進行了實驗。KITTI訓練集由7481張圖像標記,包括農村、城市和高速公路等道路場景。每幅圖像最多有15輛車,目標有不同程度的遮擋和截斷。數據集共包含8個類別:轎車、貨車、卡車、有軌電車、行人、人(坐)、騎自行車和其他。其中,將人合并為行人類別,另外選擇轎車、貨車、卡車和自行車手,取出五類對象進行訓練和測試。
實驗環境
實驗環境是Ubuntu 21.04,Pytorch 1.8.0,第11代CPU英特爾?酷睿?i5-11,400@2.60 GHz,GPU型號NVIDIA GeForce RTX 3070,內存16G,CUDA 11.2,CUDNN 7.6,Python3.8。初始學習率為0.01,使用余弦退火法衰變,最終學習率為0.001,epoch設置為300時,批次大小設置為8。
評價指標
Precision、Recall、mAP、FPS
實驗結果
消融實驗
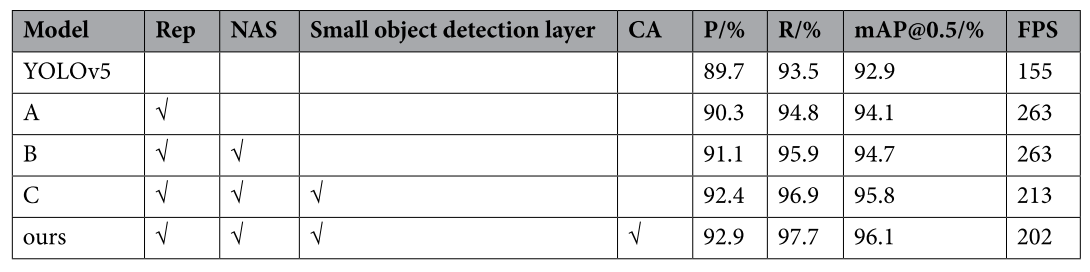
為了考察在重參數化模塊中增加不同分支對模型的影響,以及不同分支組合下NAS的效果,進行了相關實驗
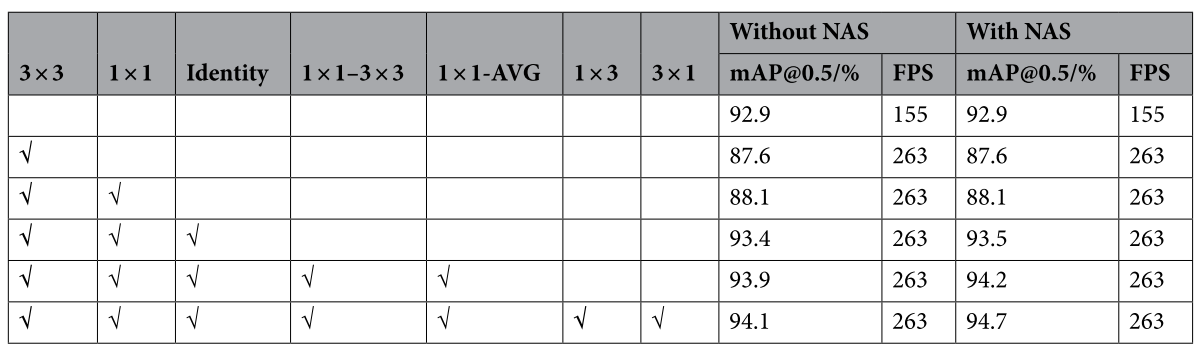
不同注意力機制
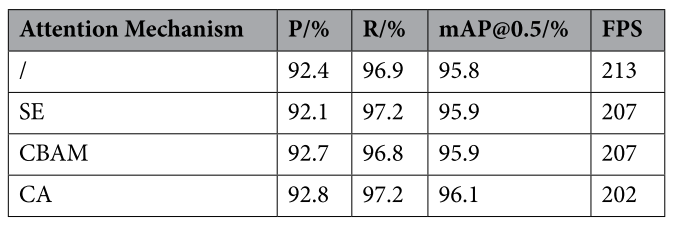
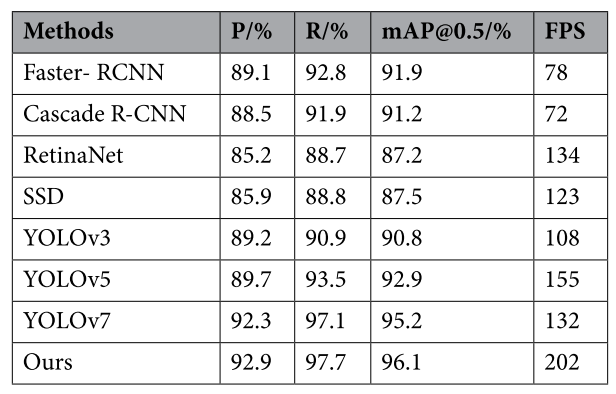
對比實驗
檢測結果(左邊:YOLOv5;右邊:改進的YOLOv5)




)











)
完全指南)


