前言
大模型是指具有大規模參數和復雜計算結構的深度學習模型,這些模型通常由眾多神經網絡構建而成,擁有數十億甚至數千億個參數。本章將圍繞大模型概念及特點展開,介紹模型算法的分類、典型大模型及應用、大模型訓練流程和大模型業務流程。
目標
學完本課程后,您將能夠:
了解大模型應用發展。
了解大模型特點和主流大模型應用。
了解大模型業務流程。
目錄
1.AI應用發展現狀
2.大模型分類和特點
3.主流大模型介紹
4.大模型應用
5.大模型訓練及推理流程介紹
6.大模型業務流程
1.AI應用發展現狀
AI應用發展
當前AI應用進入大模型時代,智能化水平有了質的飛躍。從自然語言處理到圖像識別,從自動駕駛到醫療健康,大模型技術的應用正在不斷地提高我們對AI的認知和期待。
于此同時,各類算法和技術也在日新月異地發展。深度學習、強化學習等算法和開發框架、工具的不斷優化和完善,是的AI在處理復雜問題時更加高效和準確。
思考1
AI帶來了哪些改變?
AI可以適用于哪些行業?
大模型時代的AI應用有哪些變化?
大模型AI應用如何開發?
未來的AI應用會走向何方?
思考2
你是一位架構師,現在你將主導團隊AI應用的開發,你會如何進行開發,又會思考哪些問題?
模型那么多,選哪個?大模型還是小模型?
該為微調和推理準備多少算力?
應用上線時,模型應該怎么部署?
要是模型在回答時亂說話怎么辦?
如何保證模型上線后的安全問題?
。。。。。。
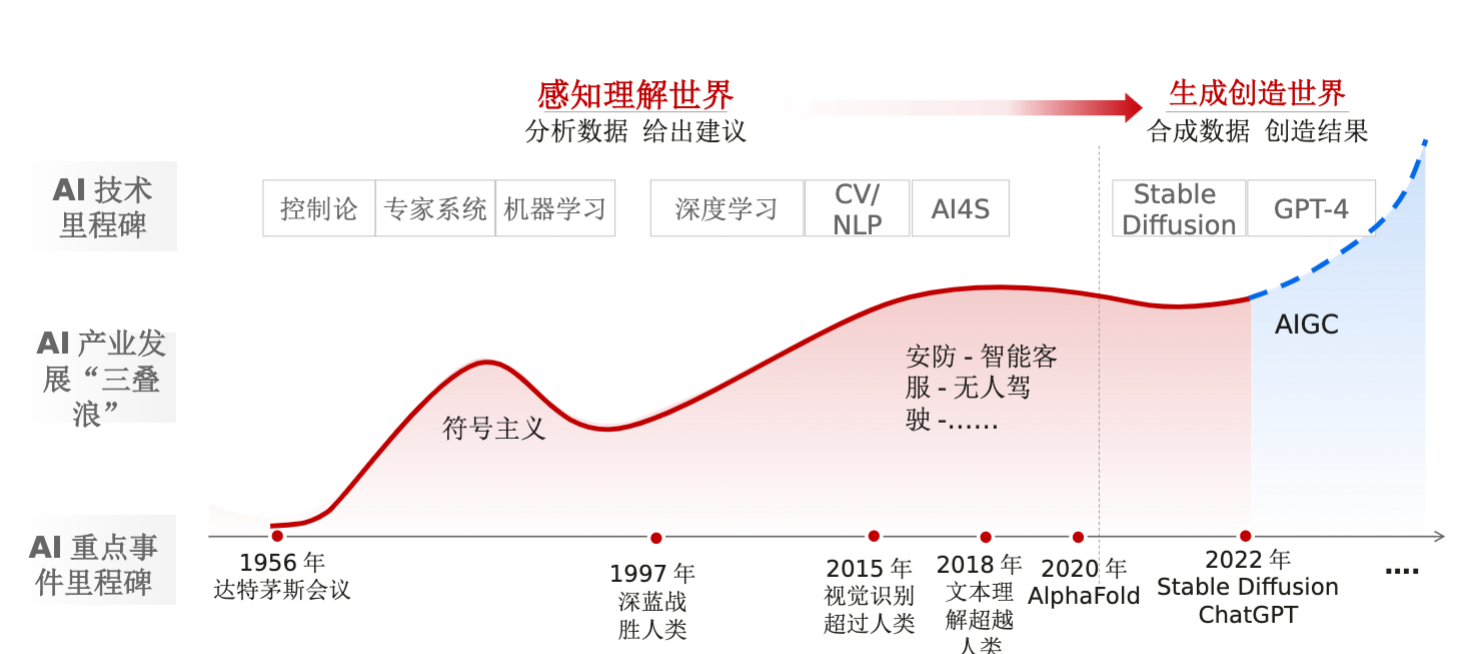
AI應用發展歷程
從 感知理解世界(分析數據,給出建議),到 生成創造世界(合成數據,創造結果)。
AI重點事件里程碑:
1956年達特茅斯會議
1997年深藍戰勝人類
2015年視覺識別超過人類
2018年文本理解超越人類
2020年AlphaFold
2022年Stable Diffusion ChatGPT
AI產業發展“三疊浪”:
符號主義
安防-智能客服-無人駕駛-。。。。。。
AIGC
AI技術里程碑:
控制論、專家系統、機器學習
深度學習、CV/NLP、AI4S
Stable Diffusion GPT-4
由小到大
算法:參數量膨脹,單位由Million到Billion
數據:訓練數據增加,單個模型訓練數據集可多達萬億token
算力:算力規模提升至EFLOPs
AlexNET-VGG-ResNet-ELMO-Transformer-ViT-GPT-LLaMA-GLM-...
大模型 VS 小模型
| 小模型 | 大模型 |
| 學習能力上限低 | 學習能力強 |
| 不同任務需要不同模型 | 一個模型解決多個任務 |
| 訓練數據上限低 | 訓練數據上限高 |
| 單一多模態數據 | 多模態能力強 |
| Few-shot能力差 | Few-shot能力強 |
使用AI模型獲取數據中的知識 -》“知識”學習的更好
服務器/云側AI應用
隨著AI模型的不斷膨脹(網絡深度、參數量),所需要的算力也是成倍的增加,當前大模型大多數為云側應用,如盤古、ChatGPT、文心一言等
優點:算力相對充足、擴展性強
缺點:數據安全問題、網絡延遲、計算中心維護復雜
AI端邊應用
AI邊緣側應用:攝像頭、開發板等。
AI移動端應用:平板、手機等。
ChatGPT等AIGC應用一直以來都伴隨著強烈的隱私安全爭議,但如果完全在短側運行,就能夠完全避免這一問題。
相比傳統的PC或者服務器,移動終端最大的挑戰就是如何平衡好體驗和能耗。
批注:
在部署深度學習模型時,推理效率是一個關鍵考慮因素。目前,AI技術運用在越來越多的邊緣設備中,例如,智能手機,智能手環,VR眼鏡,Atlas200等等,由于邊緣設備資源的限制,我們需要考慮到模型的大小、推理的速度,并且在很多情況下還需要考慮耗電量,因此模型大小和計算效率成為一個主要考慮因素。
華為終端BG AI與智能全場景業務部總裁賈永利解釋,一方面,大語言模型具備泛化能力,能夠幫助手機智能助手提升理解能力。另一方面,大模型Plug-in的插件能力,可以在手機內部打通各應用之間的壁壘,借助工具拓展能力。
算力挑戰
集群是必然選擇
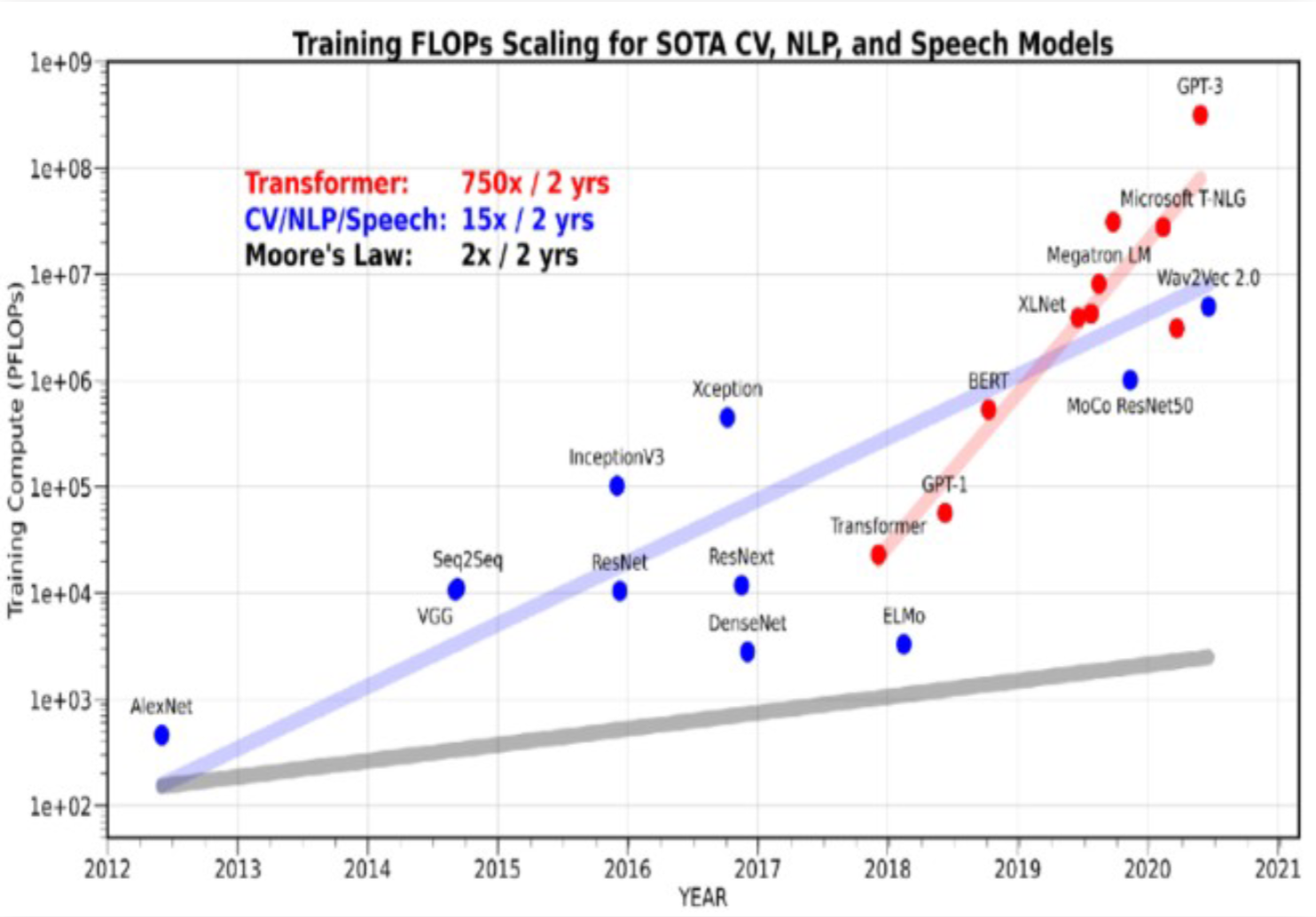
算力的“需”比“供”大200倍+
大模型算力需求指數級膨脹,750倍每2年
硬件算力供給僅線性增長,3倍每2年
萬級參數時代:2015~2018
典型模型:參數:ResNet-50 2500萬
計算需求:百TF級平臺 1張GPU卡
網絡需求:無互聯網
存儲需求:GB級存取-服務器硬盤
億級參數時代:2018~2022
典型模型:參數:GPT-1 1.7億
計算需求:PF級平臺單服務器,8卡(百TF*10倍)
網絡需求:節點內卡間互聯
存儲需求:TB級存取-服務器硬盤
萬億級參數時代:2023~
典型模型:參數:GPT-4 1-1.7萬億
計算需求:EF級平臺AI集群,~萬卡(PF*1000倍)
網絡需求:超節點+網絡互聯(節點內卡間互聯*100倍)
存儲需求:PB級存取-高并發多級存儲
集群系統創新,加速中國AI創新
批注:
大模型對于算力的需求是呈指數級膨脹式增長的,而硬件算力的供給能力是呈線性增長的,因此,目前對于算力的需求量要比硬件算力供給量高出200倍以上。
那么,同時伴隨著模型參數的不斷增長,在萬億參數時代下的模型訓練中,不僅需要大算力,同時對于網絡、存儲的協同訴求也與日劇增。
所以,單機的服務器已經不能夠滿足萬億參數時代下的大模型訓練,只有通過AI集群的方式,才能夠更好的滿足大規模分布式訓練場景訴求。
因此,集群是大規模時代下的必然選擇,集群系統的創新,也必然會加速中國AI的創新。
算力需求
根據業界論文理論推算,端到端訓練AI大模型的理論時間為E_t = 8 * T * p / (n * X)。其中E_t為端到端訓練理論時間,T為訓練數據的token數量,P為模型參數量,n為AI硬件卡數,X為每塊卡的有效算力。
| 參數量P(B) | 訓練階段 | 數據量T(B tokens) | 卡數n | 訓練時長(天) |
| 175(e.g. GPT3) | 預訓練 | 3500 | 8192 | 49 |
| 二次訓練 | 100 | 2048 | 5.5 | |
| 65(e.g. LLaMA) | 預訓練 | 1300 | 2048 | 27 |
| 二次訓練 | 100 | 512 | 8 | |
| 13(e.g. LLaMA) | 預訓練 | 1000 | 256 | 34 |
| 二次訓練 | 100 | 128 | 7 |
批注:
以GPT3為例,參數量175B(750億)規模下,在預訓練階段,數據量35000億,使用8192張卡,其訓練時長為49天。
華為AI算力底座支持國內外主流開源大模型,實測性能持平業界最佳
國內唯一已完成訓練千億參數大模型的技術路線,訓練效率10倍領先其他國產友商

2.大模型分類和特點
大模型分類
大語言模型發展史
2017,Transformer誕生
2018,Google推出Bert
2018,OpenAI推出GPT
2019,OpenAi推出GPT2
2020,OpenAI推出GPT3
2022,OpenAI推出ChatGPT
期



)
)














