原創 董藝荃 Higress 2025年08月21日 16:32 陜西
本文整理自攜程旅游研發總監董藝荃在2025中國可信云大會上的分享,董藝荃 GitHub ID CH3CHO,同時也是 Higress 的 Maintainer。分享內容分為以下4部分。
01 大規模應用 AI 技術過程中遇到了哪些問題
02 網關選型上有哪些考慮
03 落地 AI 網關時,有哪些難點和如何應對的
04 應用成效和未來規劃
1、大規模應用 AI 技術過程中遇到了哪些問題
為了進一步提升服務水平和服務質量,攜程很早就開始在人工智能大模型領域進行探索。而隨著工作的深入,大模型服務的應用領域不斷擴大,公司內部需要訪問大模型服務的應用也越來越多,不可避免的就遇到了下面這幾個問題。
- 第一,我們不僅接入了外部的商業大模型,還有很多我們內部的自研模型,不同的模型對網絡訪問能力要求不同,在認證機制也存在差異。
- 第二,各個業務應用點對點接入大模型,費用管理各自為政,沒有集中的用量統計。
- 第三,在流量高峰,乃至大模型服務出現故障的時候,沒有統一的限流、熔斷、流量切換等機制,全靠業務線自己。
在這種場景下,我們自然就會想到使用網關來對這些服務接入進行統一管理,并增加各種切面上的流量治理功能。
2、網關選型上有哪些考慮
在對比多個開源項目之后,我們選擇了 Higress 作為搭建 AI 網關的基礎。
- 第一,Higress 在阿里內部有著長時間的實踐和技術沉淀,在傳統 API 網關的基礎上迭代了 AI 網關的功能,對各種大模型接入場景提供了豐富的功能支持,而且穩定性良好。
- 第二,Higress 使用了在云原生服務網格領域廣泛應用的 Istio和 Envoy 作為內核,并且支持使用 C++、Go 和 Rust 等語言編寫 Wasm插件,具有極強的擴展性,便于我們后續根據自身需求添加功能。
- 第三,Higress 社區非常活躍,對于需求的跟進速度很快,一般兩到三周就會發布一個新版本。
在內部落地 Higress 作為 AI 網關基礎設施之后,我們整個 AI 服務接入架構就如下圖所示。網關的所有組件都部署在內部的 Kubernetes 集群內,由它來負責服務器資源和配置信息的管理。
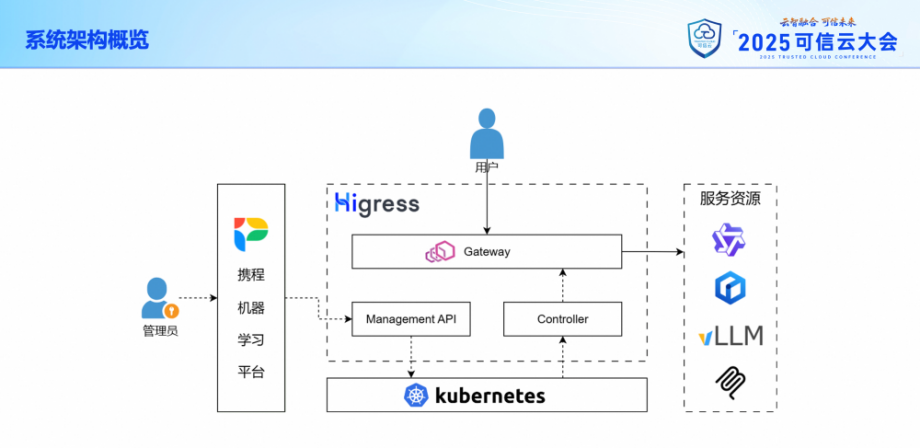
其中,網關本身由 3 個組件組成:
- Gateway,也就是數據面,直接承接用戶流量并轉發給后端的大模型服務。
- Controller,也就是控制面,負責從 Kubernetes 中讀取配置信息并推送給 Gateway。
- Management API,負責對接我們內部的大模型運營平臺,也就是圖中的攜程機器學習平臺。管理員會在平臺上面配置可供訪問的各種大模型服務,最近還接入了 MCP 服務,以及接入方的相關信息。API 會把這些配置信息寫入 Kubernetes 進行持久化保存,供 Controller 讀取。
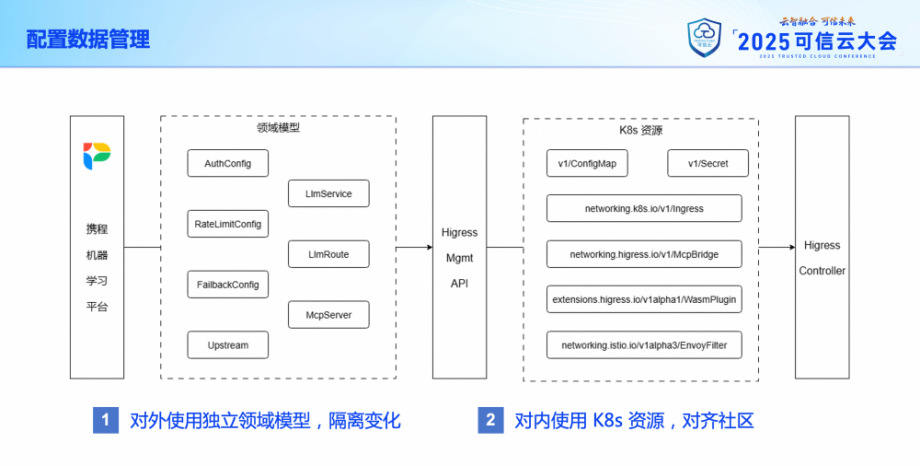
在配置數據方面,Higress 本身使用的是 K8s 原生的一些資源類型,還有一些自定義的資源。這部分我們沒有做什么改動。但在對接機器學習平臺時,我們根據實際的業務需求,針對大模型接入和 MCP Server 接入兩種場景設計了獨立的領域模型,并對 Higress的 Management API 進行了二次開發,增加了模型轉換的功能,并且支持對所有的配置進行增量和全量兩種同步操作。
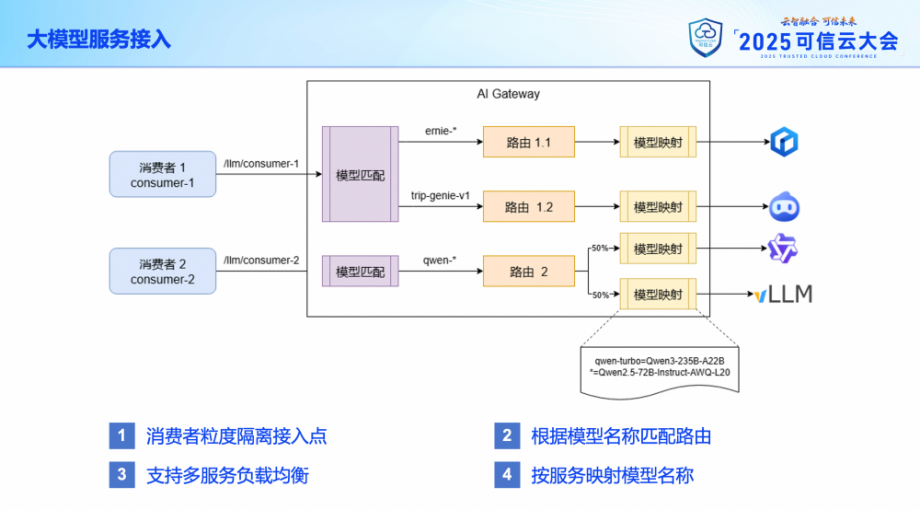
在大模型服務接入方面,考慮到風險隔離的需求,我們為不同的接入方(這里我們稱之為消費者),設置了不同的接入點路徑。每個接入點路徑可以關聯多個模型路由,使用模型名稱進行匹配。每一個模型路由也可以關聯多個后端的大模型服務,實現服務間的負載均衡。
在實際轉發請求給大模型服務時,網關還支持對模型名稱進行映射,也就是說用戶可以使用統一的模型別名發起調用,在轉發到不同的大模型服務時,根據服務的實際情況來更換為具體的模型名稱。
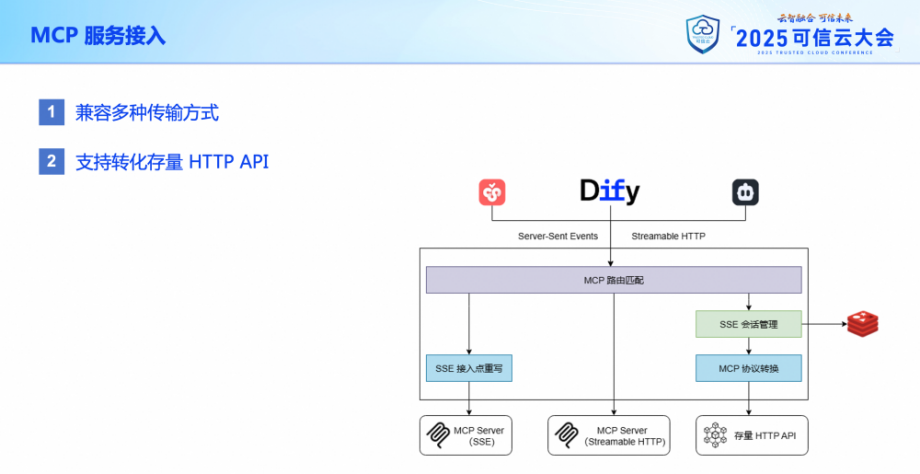
最近,我們又在網關上增加了 MCP 服務接入的能力。這部分更類似于傳統的 API 網關,將一個服務暴露到網關上以便外部進行訪問。
但除了支持現有的 MCP 服務之外,網關還支持將存量的 HTTP API 轉化為 MCP 服務。用戶可以使用 SSE 或者 Streamable HTTP 方式來訪問這類 MCP 服務。針對存量轉化這一部分,我們后面也會進一步展開介紹。
對于所有經過 AI 網關處理的請求,訪問方都需要提供訪問憑證來進行認證和鑒權操作。目前針對訪問方,我們主要使用的是 Bearer Token 的認證機制。每個 Token 會關聯一個消費者。一個消費者可以訪問哪些服務則是需要經過申請和審批的。
針對后端服務這一側,大部分大模型服務都是需要在訪問時進行鑒權操作的。這些訪問憑證統一存儲在了網關內,消費者一側無需關注。而在 MCP 服務這一邊,情況就要復雜一些。有的 MCP 服務并不需要認證,有的則是要求提供認證信息。網關層是支持服務提供方根據實際情況進行選擇的。如果需要認證,既可以把認證憑證統一放在網關內,也可以要求由調用方提供。網關也會根據配置來調整憑證信息的傳遞方式,以滿足端到端的認證需求。

當然這些都是正常的情況,下面我們要說的就是一些針對異常流量的處理機制。
首先是限流。
每一個消費者在申請大模型訪問的時候,都需要填入響應的限流閾值,這個閾值一種有三種,分別 Token per Minute (TPM)、Query per Minute (QPM) 和并發請求數。這不僅可以保護我們的網關和后端服務免收突發流量的干擾,也便于網關和服務的運維團隊進行容量規劃,同時也可以幫助用戶管控成本。
這些限流機制利用的都是 Higress 所提供的 Wasm 插件擴展點,內部使用 Redis 作為中央計數器,實現全局性的限流統計功能,并通過 LUA 腳本來實現計數器更新的原子化。

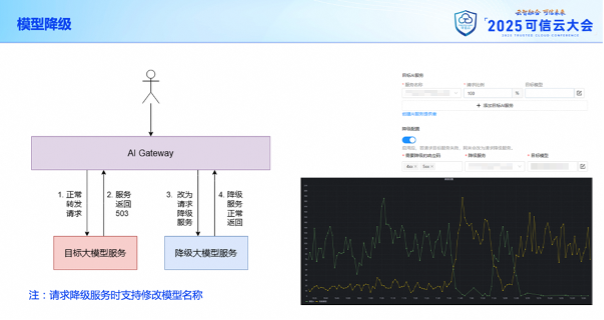
其次是降級。
但如果意外情況下,后端大模型服務出現故障,我們還可以預先配置相應的模型降級規則。當路由原本指向的大模型服務返回 4xx、5xx 等異常響應碼時,網關并不會直接把響應返回給調用方,而是會再次把請求轉發給降級用的大模型服務,并返回降級服務的響應數據。這個降級操作只會進行一次,而且考慮到降級服務支持的模型列表可能與原服務有所差異,我們可以針對降級服務配置獨立的模型名稱映射規則。
在下方的這張圖里的黑色的調用次數的對比圖中,我們就可以看到,當綠色線所對應的服務出現故障時,請求被自動切換到了黃色線所對應的服務上。之所以有這張圖,是因為網關本身也提供了強大的可觀測能力。
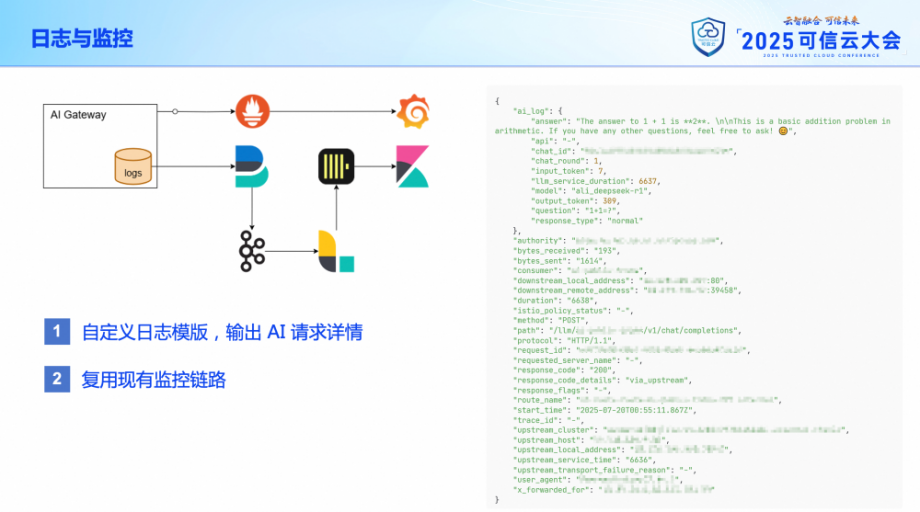
第三是日志和監控。
網關的請求日志是落在本地磁盤的,通過 logrotate 來進行滾轉,避免占用過多存儲空間。日志的內容是可以自行修改定制的,通過 Wasm 插件配合自定義的日志模版,我們將大模型請求的很多詳細信息都記錄到了日志里,比如說模型名稱、消耗的 Token 數、輸入和輸出的消息內容等等。這些都有助于我們后續對用戶的使用情況進行分析,并且幫助用戶優化自己的使用方式。
日志的采集就比較直接了,這部分也是復用的公司現有的監控鏈路,通過 FileBeat 將日志內容送到 Kafka,通過類似 LogStash 的組件消費 Kafka 獲取日志信息,解析重組之后寫入 ClickHouse,然后在 Kibana 上提供給大家查看。
監控這邊就更加直接了。網關本身就暴露了一個供 Prometheus 抓取的接口。抓取到的監控信息可以在內部的 Grafana 上進行查看。
網關整體的情況大概就是這樣。接下來是一些關鍵難點分享。當然在 Higress 的幫助之下,原本的難點也并沒有那么難。
3、落地 AI 網關的難點和應對方案
首先是適配各種大模型供應商的接口契約。目前請求大模型時最通用的就是 OpenAI 的接口協議,網關本身對外提供的服務也基于的是這套協議。但有一些大模型服務并不完全兼容這個協議,比如說有的是接口路徑不一樣,有的是認證方式不一樣。
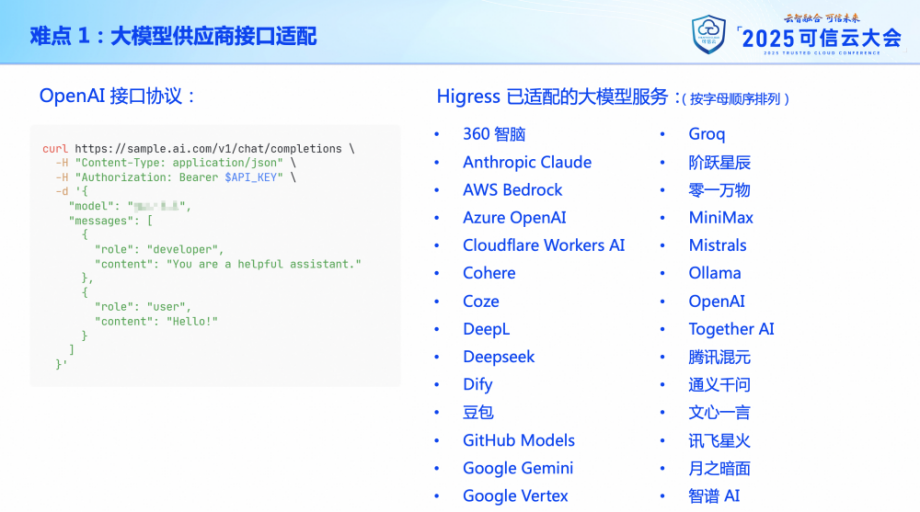
這樣就需要網關在轉發數據時,對請求和響應的數據進行修改,對齊對端所支持的接口協議。好在 Higress 目前已經適配了市面上很多種大模型服務類型,我們基本上不需要做什么改動,就可以對接各種大模型服務,但在推廣 MCP 服務接入方面就沒有這么簡單了。
攜程內部現在有大量的 HTTP 服務,覆蓋了業務場景的方方面面。如果能夠直接利用起來,把它們變成 MCP 服務提供給 AI 使用,對于業務方接入整個 AI 體系是很有幫助的。
但眾所周知,如果要把一個接口作為工具放到 MCP Server 上,它是需要一個工具描述信息的,包括接口的名稱、參數列表等等。
而我們的 REST API 最多也就是這種使用 Swagger 生成的 OpenAPI 接口契約,所以這里的核心就是要把左面這種接口契約轉化為右側這種工具描述。
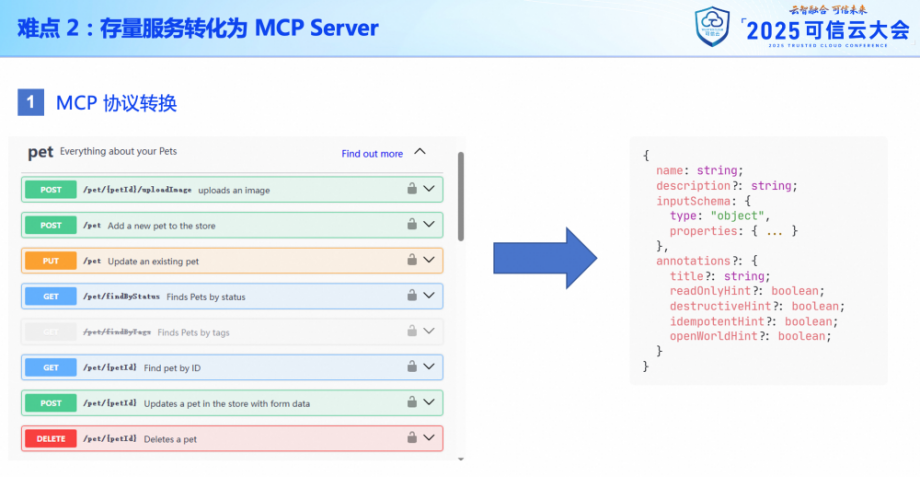
除了請求參數部分之外,我們還需要對后端接口的響應數據進行格式化,作為 MCP Server 的響應數據,便于大模型的理解。
這顯然是個重復性很強的工作。既然是重復性很強的工作,那肯定就可以讓 AI 來幫我們完成。
我們利用右側這個提示詞,將接口契約一同提供給大模型,大模型就可以生成出基本可用的描述信息。只需要人工校對并做少量的調整就可以使用了。

完成了協議轉換,我們就來到了下一個問題點。
雖然 SSE 這個傳輸方式已經被 MCP 官方廢棄,但仍舊有很多調用方希望網關能夠支持 SSE,而這種傳輸方式采用了請求與響應分離的設計,這就要求在網關層面提供一個會話管理的功能。

大致流程是這樣的:MCP Client 請求服務的 /SSE 接口,啟動一個新的會話。然后網關生成一個新的 SessionID,并且在 Redis 里監聽一個與這個 SessionID 所關聯的 Channel,然后把這個 MCP Server 對應的 Endpoint 信息返回給客戶端。這樣客戶端就可以向這個 Endpoint 發起后續的請求,比如說初始化監聽、獲取工具列表、調用工具等等。而這請求的響應數據并不會被直接返回給客戶端,而是要發布到前面監聽的那個 Redis Channel 中。通過這個 Channel 把信息傳遞給 /SSE 那個請求的上下文,然后推送給客戶端。
4、應用成效和未來規劃
關于網關落地的技術細節就介紹到這兒。
目前 AI 網關在攜程內部已經接入了多款大模型,具備穩定支撐大規模模型調用的能力,為公司的人工智能技術探索奠定了扎實的基礎。現在我們也在不斷的接入各種 MCP Server,豐富整個產品的生態體系。
各位可以看到,我們整個 AI 網關很多功能都是開源的 Higress 原生提供的,我們要做的更多是將它適配到攜程的研發體系中去,并對接周邊的治理平臺。通過我們的驗證,也發現了一些社區尚不支持的場景。這些我們也通過 Pull Request 的方式提交給了社區,并已經合并進了代碼庫中。相信隨著有越來越多的人使用開源產品,貢獻開源代碼,我們的社區也會越來越好。
正如這句話所說:每一次代碼回饋,都是開源生命力的延續。
接下來,我們也會繼續對網關的能力進行迭代,在模型路由規則、模型輸出后處理、調用方優先級識別和內容安全防護等方面進行優化,并將 AI 能力融入到網關內部,而不僅僅停留在作為由網關所承載的業務這一層面,并進一步強化網關的安全性和合規性,讓網關在整個 AI 流量鏈路上發揮更大的作用。













)

-共享內存)
)


