目錄
一、NeRAF
1、概述
2、方法
3、訓練過程
4、實驗
二、ImVid
1、概述
2、Imvid數據集
3、STG++方法
一、NeRAF
1、概述
? ? ? ? NeRF類方法僅支持視覺合成功能,缺乏聲學建模能力。對于以往的聲學建模(如NAR/INRAS)會忽略三維場景幾何對聲波傳播的本質影響。
? ? ? ? NeRAF可以在現有圖像和音頻數據中學習輻射場和聲學場信息,并且能夠在未知區域合成視聽信息,無需依賴同位置的視聽傳感器進行訓練。
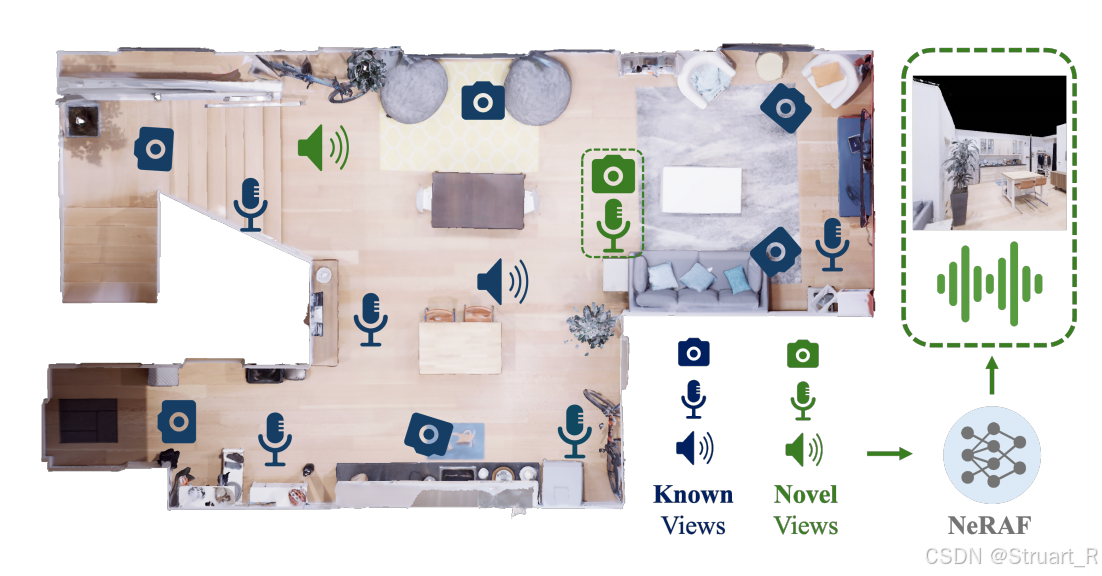
2、方法
? ? ? ? NeRAF模型包含三個部分NeRF神經輻射場,網格采樣器,神經聲學場(NAcF)。
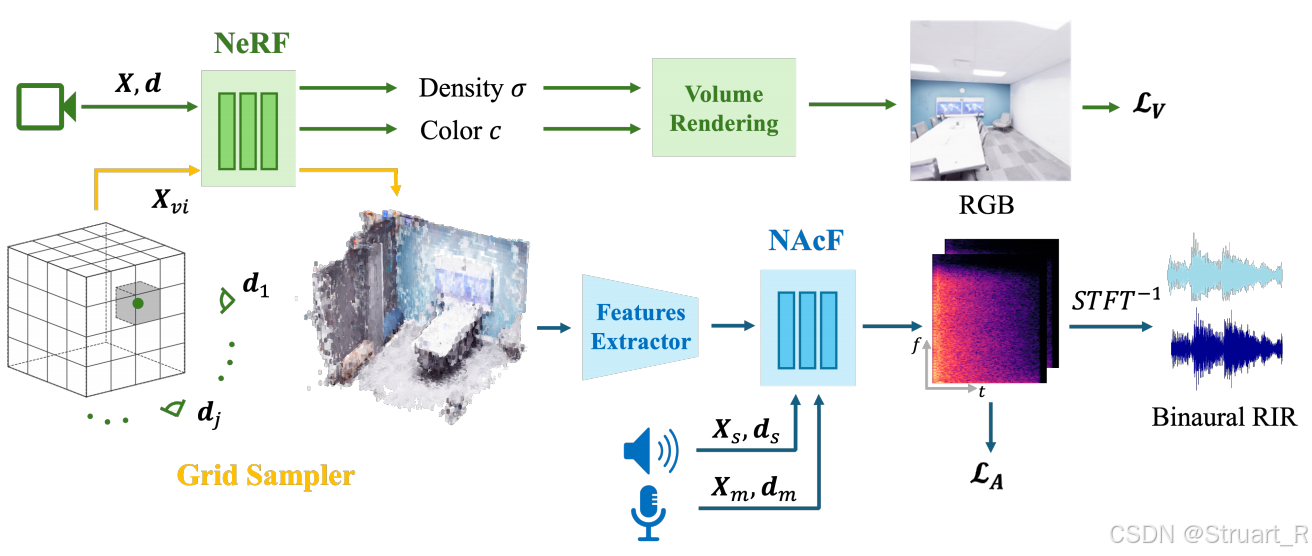
? ? ? ? 神經輻射場首先依賴于Nerfacto進行搭建,該框架整合了哈希編碼,場景收縮,相機位姿優化等技術,并且NeRAF模型也不對NeRF進行改進。NeRF通過給定xyz坐標和位姿->輸出密度和顏色信息。
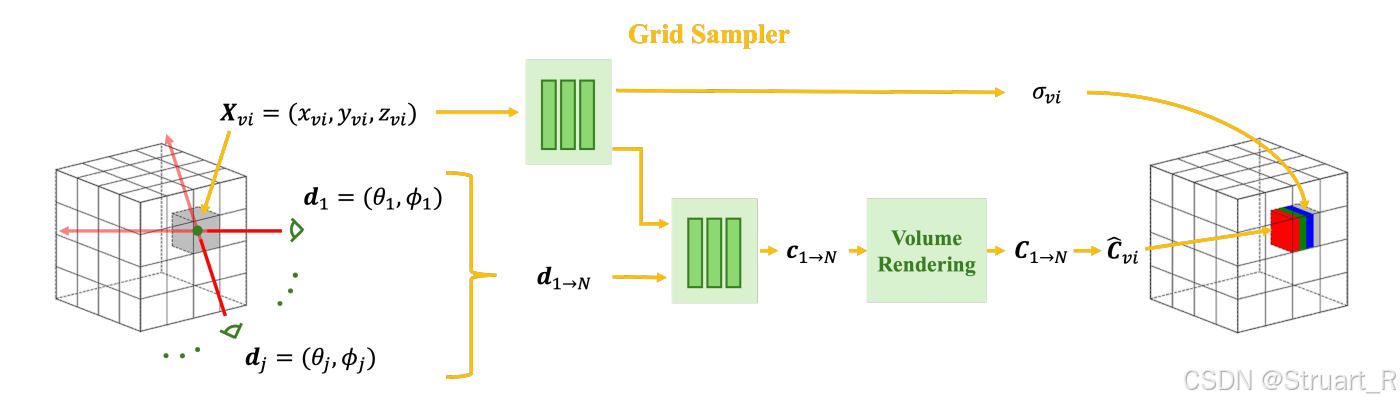
? ? ? ? 網格采樣器,目的是將NeRF模型切換到一個可以提取特征的網格特征結構。對整個3D場景構建一個128x128x128的體素網格空間,并對每一個體素中心點查詢NeRF,不透明度為
,并且對每一個坐標投射18個視角,并對每一個視角渲染一個顏色信息,計算均值
,這樣就成功的將NeRF模型轉換成了一個顯式的體素網格結構,輸出7通道體素
。
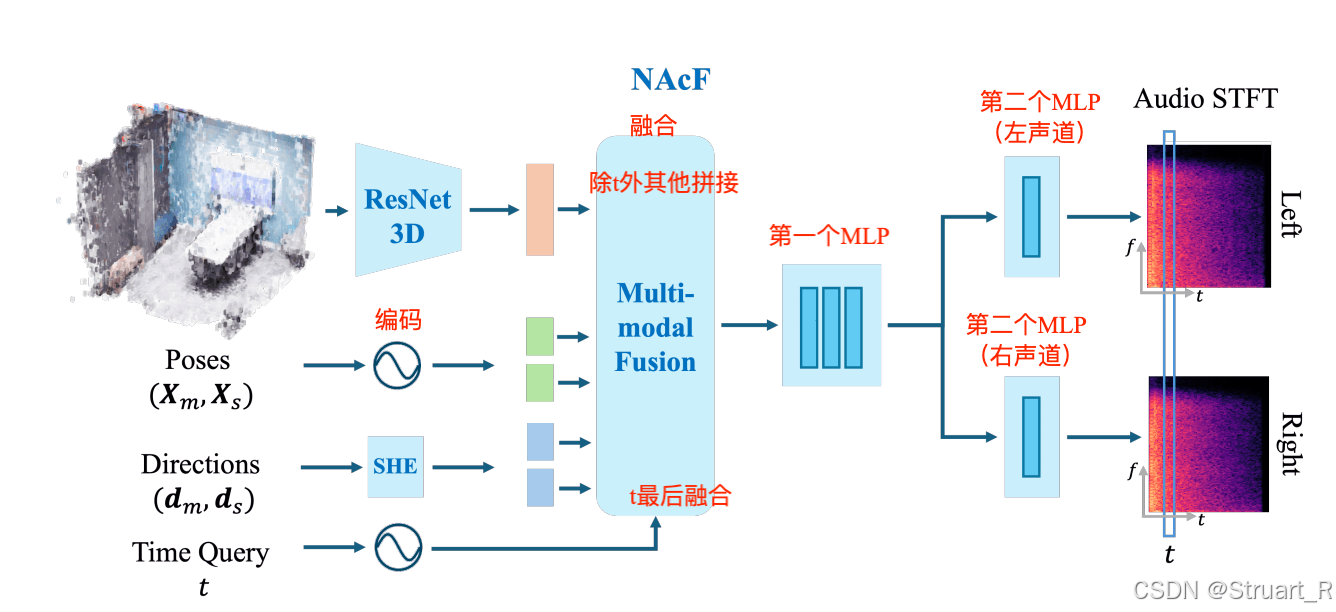
? ? ? ?神經聲學場部分:
? ? ? ?RIR:房間脈沖響應,描述聲波從聲源到麥克風的傳播特性,比如正常一個聲音從聲源傳到聽者,他需要經過早期反射和晚期混響兩個階段,早期反射反應聲源周圍的表面到聲源的距離信息,晚期混響則是多次散射形成的能量衰減,受場景規模,材質等影響。
????????神經聲學場(NAcF)旨在學習場景中的聲學特性的連續神經表征,也就是計算任意位置上的RIR合成,最后輸出到雙耳聲道。輸入任意位置的麥克風坐標以及方向角
,以及聲源位置的坐標
和聲源方向角
,時間查詢t。上述這些信息均用作編碼。
????????NAcF函數表示:,這個RIR實際上就是STFT的時頻表示,可以理解為利用上述五個信息,得到一個某一個位置的房間脈沖響應,這個響應用STFT來表示。
????????ResNet3D作為三維場景特征提取器,輸入一個體素網格,輸出1024或2048維的特征向量,他的目的是學習體素網格中的幾何特征和材質特征。
? ? ? ? Multi-modal Fusion包含兩個MLP,第一個用來輸入所有融合向量,輸出一個512維的聲學latent vector,用于學習聲波在場景中的傳播物理規律,第二個MLP分為左右兩個聲道獨立MLP,最終輸出STFT頻域系數。
? ? ? ? MLP Block1:5層全連接,LeakyReLU作激活函數
? ? ? ? MLP Block2:學習非對稱HRTF,證明空間定位能力,兩耳存在一定的聲壓差,Tanh作為激活函數。
? ? ? ? 還原RIR波形,通過Griffin-Lim算法來實現還原(參考NAcF)
3、訓練過程
損失函數
? ? ? ? NeRF損失包括重建MSE誤差和互補損失(相機位姿修正損失和多分辨率哈希損失),不修改原損失。
? ? ? ? 聲學損失計算光譜對數損失L_SL和光譜收斂損失L_SC

訓練策略
? ? ? ? 先訓練NeRF,并且分批更新體素網格。
? ? ? ? 之后聯合訓練NAcF和NeRF。
數據集
? ? ? ? SoundSpaces:仿真數據由Habitat Sim構建,包含6個室內場景信息,聲學數據提供雙耳RIR并且每隔0.5m網格進行空間采樣,視覺數據則初始128x128 的RGB-D數據,NeRAF重新渲染了512x512的。
? ? ? ? RAF:RAF之前的SoundSpaces和MeshRIR都是合成數據或者稀疏采樣,RAF是首個真實世界密集采樣視聽數據集,每平方米372個樣本,只有兩個真實房間:空房間和帶家具房間。視覺采集來自于VR-NeRF相機環,22個相機多視角共11418張圖像,帶有深度圖。聲學采集利用全向麥克風,共86K條,每個4秒鐘,48kHz采樣,RIR數據。
? ? ? ? RWAVS:來自于AV-NeRF論文,首個真實世界視聽同步數據集,包括辦公室,公寓,房屋,戶外(戶外那個視頻帶一段空房間),并且故意保留了一些設備噪聲,環境噪聲,腳步聲這種,覆蓋日常全場景聲學特性。數據量232分鐘,樣本數12319個(8:2訓練和驗證分開)。數據模態構成為相機位姿+視頻幀+雙耳音頻+單聲道源音頻。
4、實驗
性能指標
? ? ? ? 對于重建仍然用LPIPS,PSNR,SSIM
? ? ? ? 聲學指標上用有T60,C50,EDT,都是計算預測值與真實值之間的誤差百分比。STFT error計算頻域相似度。你可以理解為前三個是重建環境對音質的影響,最后一個是能重建音色,音調一致。
? ? ? ? T60:混響時間,在一個封閉空間內,當聲源突然停止發聲后,??聲能衰減60分貝(dB)所需的時間。??T60越長,空間回聲感越強,聽起來越“空曠”;T60越短,聲音消失得越快,聽起來越“干”或“死寂”??。T60的物理屬性,受空間大小和界面材質影響,空間越大聲音傳播路徑越長,衰減到同樣水平所需時間也就更長。界面材質來說,硬質光滑表面??(如混凝土墻、玻璃窗):吸聲能力差,大部分聲能被反射,導致??T60較長??。???軟質多孔表面??(如地毯、窗簾、沙發、吸音棉):吸聲能力強,將聲能轉化為熱能,導致??T60較短??。
? ? ? ? C50:語音清晰度指數,計算聲波到達后 ??前50毫秒?? 的聲能與?50毫秒后?? 的殘余聲能的對數比。正值??表示語音清晰(早期能量>混響能量),??負值??表示渾濁(如會議室回音干擾)。家具房間的C50值普遍高于空房間(圖7對比),證明物體對混響的抑制作用。
? ? ? ? EDT:聲源停止后,??前10毫秒內?? 聲能衰減曲線的斜率(通常外推至衰減60dB所需時間)。EDT短(如0.5秒)→ 空間感“緊致”;EDT長(如2秒)→ 空間感“開闊”(如教堂)
? ? ? ? STFT Error:短時傅里葉變換誤差是評估 ??生成脈沖響應(RIR)與真實RIR在頻域相似度?? 的核心指標,為什么用STFT error,是因為STFT的頻帶劃分(Bark/Mel尺度)匹配人耳非線性感知,單純計算RIR的相位信息對聽覺影響較小,頻譜幅度誤差更關鍵。一般沒有障礙的地方STFT error較低,邊緣,遮擋的地方誤差容易升高。
實驗分析
? ? ? ? 對比過去的聲光場方法中聲音的指標。
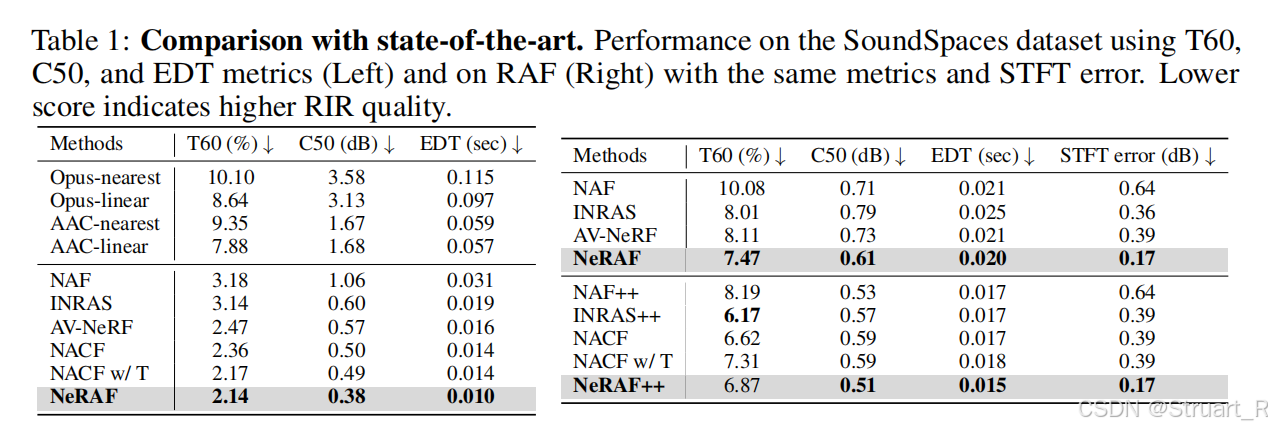
? ? ? ? 對比NeRF基礎模型的重建指標。
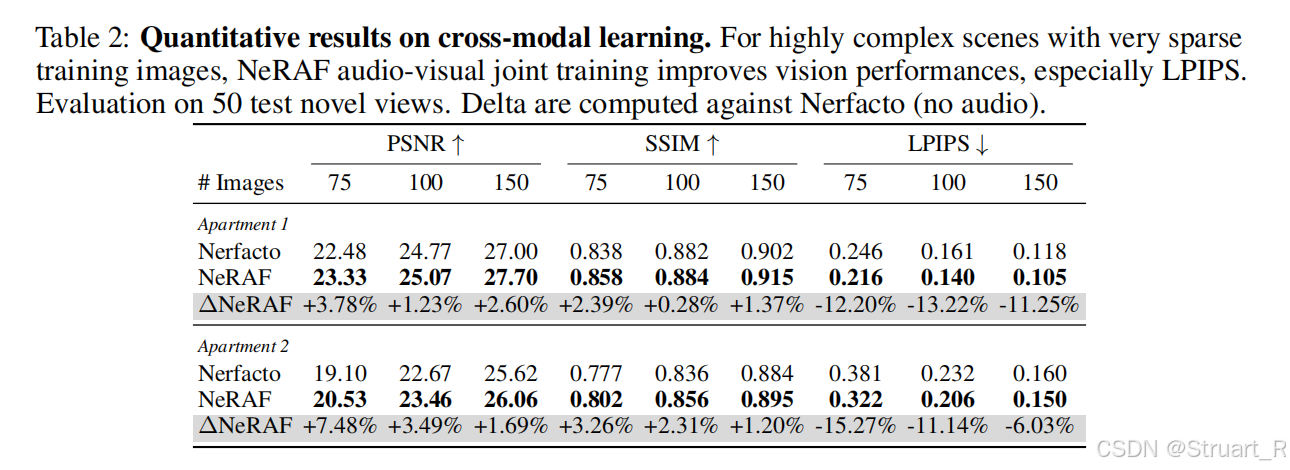
? ? ? ? 難道audio中也有vision信息?這兩者可以互補

二、ImVid
1、概述
? ? ? ? 動機:一方面受現有數據集稀少影響,當前數據集視角受限,固定相機陣列只能支持靜態拍攝,無法覆蓋360度背景,當前數據集缺乏同步的音頻,比如Diva-360,Replay數據集。當前數據集缺乏動態場景支持,多是單目,低分辨率,時長短的。另一方面工業上Vision Pro的推動,也需要更加全視角覆蓋的,兼顧視聽多模態的數據集。
? ? ? ? ImVid中主要貢獻:
(1)首次設計了移動式多模態采集系統
(2)高質量的動態場景視聽數據集ImViD
(3)動態光場重建STG++,無需訓練的聲場重建(不用神經網絡)

2、Imvid數據集
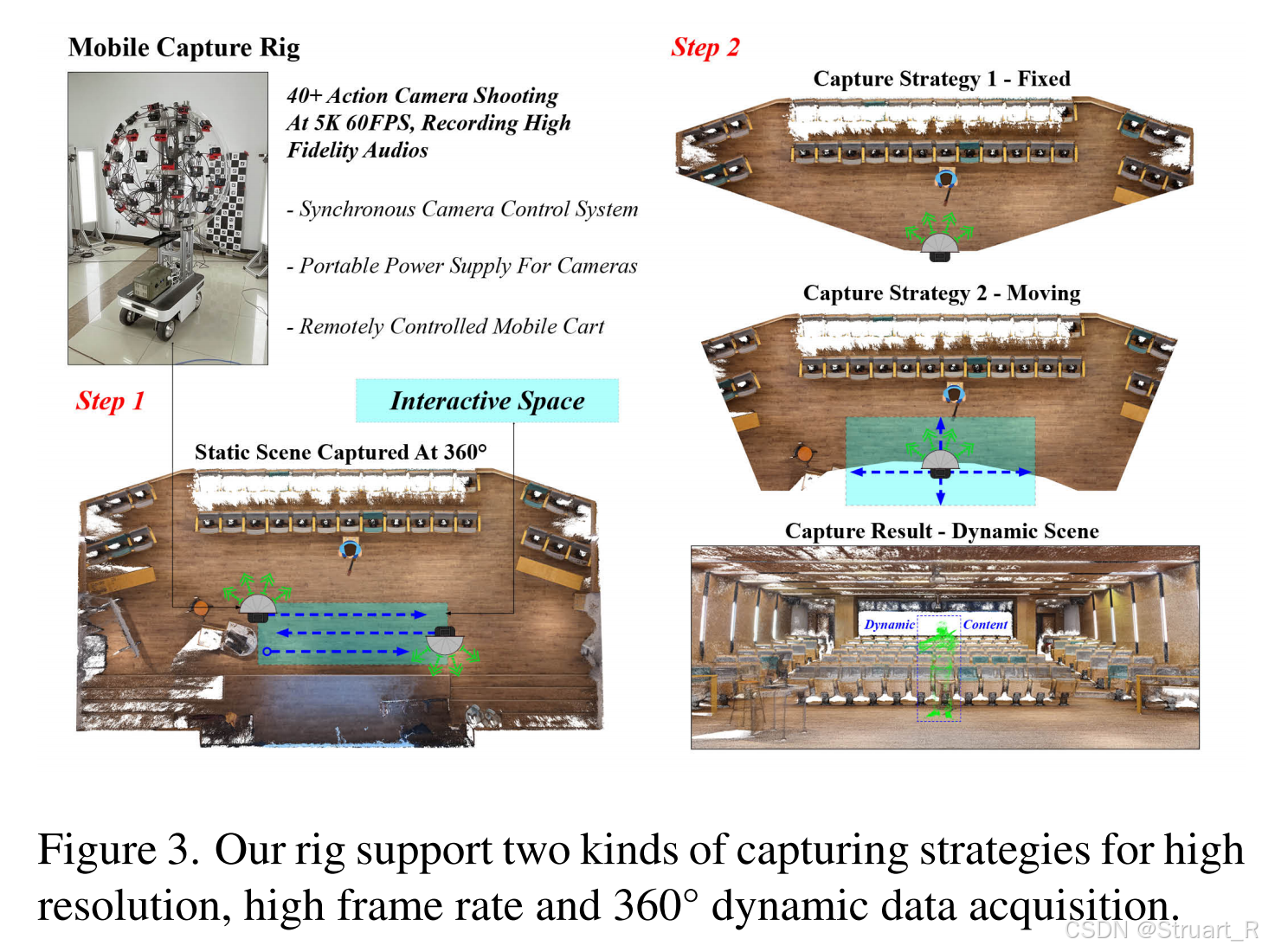
移動式多模態采集系統
? ? ? ? 采集系統:46臺GoPro相機安裝在可移動小車的半球形支架上,高度模擬人眼視角(1.7m)同時相機和麥克風集成,同步采集5K@60FPS視頻+48kHz音頻。遙控小車可在場景中緩慢移動(速度受限于地形安全),覆蓋??最小6m3空間??(2分鐘內采集1000+圖像)。GoPro相機可以實現誤差2ms內的同步,并且有降噪功能。
數據集
? ? ? ? 價值意義:
????????對比傳統方案,缺乏動態場景和移動視角,另外手持設備局限。該數據集是首個支持移動中的多模態采集的數據集。
? ? ? ? 數據采集:
????????靜態場景高密度采集。小車固定位置,多相機同步拍攝??高分辨率靜態照片??(5568×4176),覆蓋??360°背景??(如實驗室設備、窗外景物),為動態重建提供環境先驗。
? ? ? ? 動態場景雙模式采集。固定點拍攝模式,不移動小車,捕捉細微動態細節。移動拍攝模式,緩慢移動(每秒0.1立方米),擴展交互空間。
? ? ? ? 數據處理:
? ? ? ? 靜態問題上基于GoPro內參利用COLMAP進行稀疏重建,另外基于硬件同步聲音時間碼對齊。
? ? ? ? 動態數據上,對視頻切段,分別進行COLMAP重建,并用PnP拼接,但是沒有給出具體做法,近期的方法其實也可以預測了。
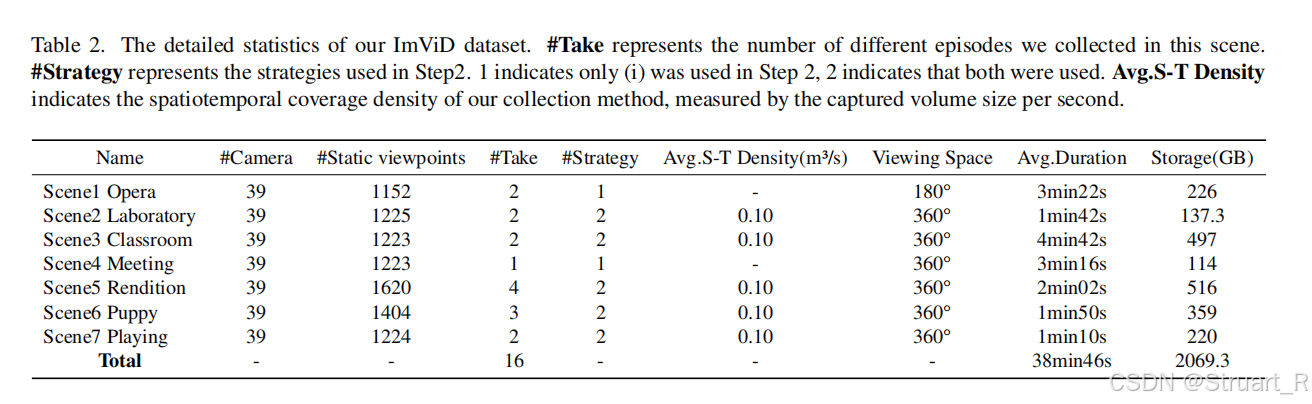
? ? ? ? 數據集:包含7種場景,39個攝像機,共38分46秒,包含人體動作,物體交互,反射表面,光影變化等問題。
3、STG++方法
? ? ? ? 首先這個方法對比的是4DGS的方法,不做聲光場重建,光場重建依賴從4DGS學來的,聲場重建只依賴聲源位姿和麥克風位姿,不考慮場景材質信息。
? ? ? ? STG++在STG模型基礎上,優化了多相機??顏色不一致??導致視圖切換時閃爍和分段訓練時??跨段連續性差?的問題,引入了顏色校正模塊和時變密度控制兩個策略。
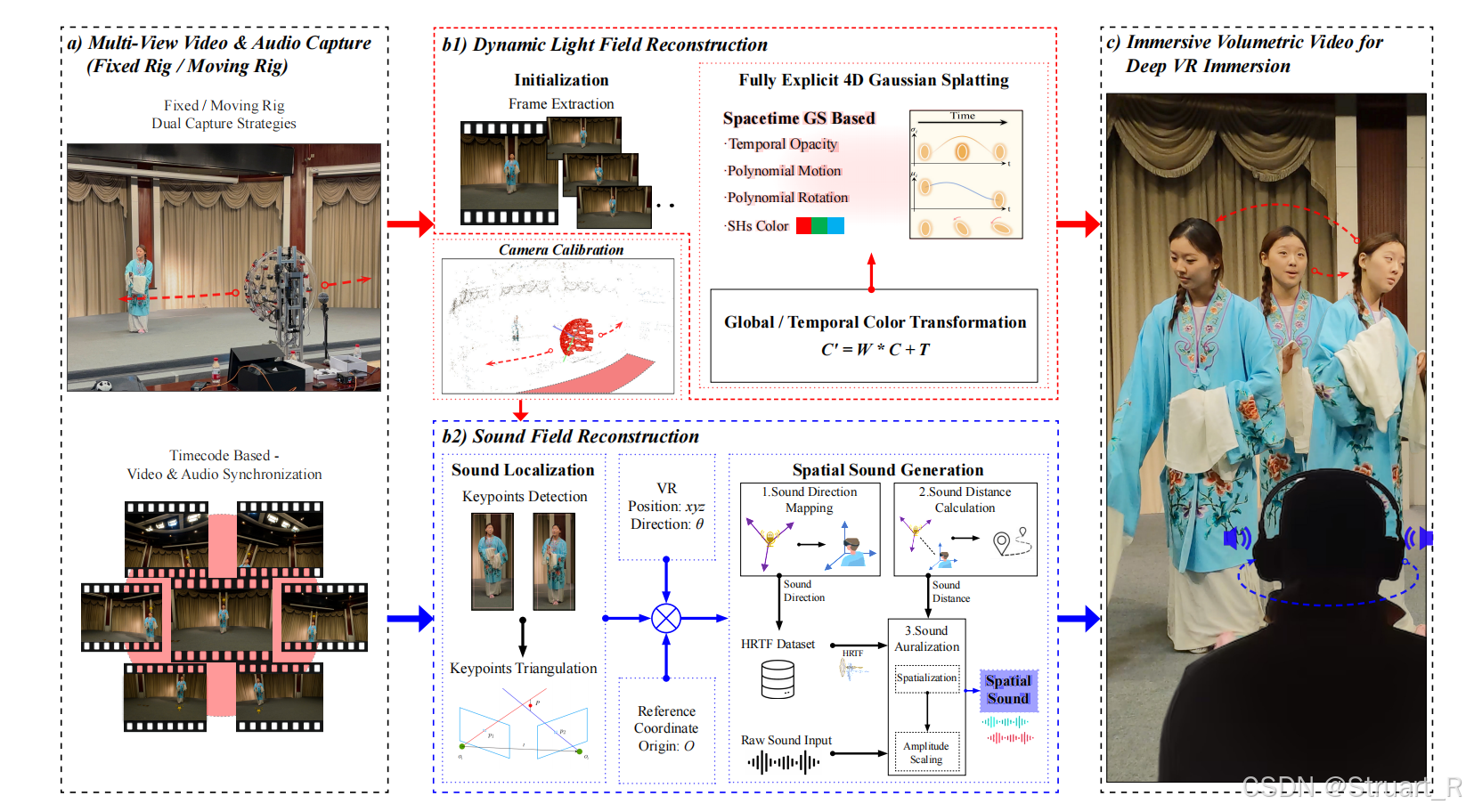
? ? ? ? 聲學重建上,數據機遇39個攝像頭攜帶的多麥克風音頻,生成6-DoF的空間音頻,對預測位置的聲音則完全通過幾何計算,加聲學優化區分雙耳來實現。首先規定:

? ? ? ? 聲源方向計算相對方位角,表示聲源相對于聽者正前方的偏角(逆時針為正):
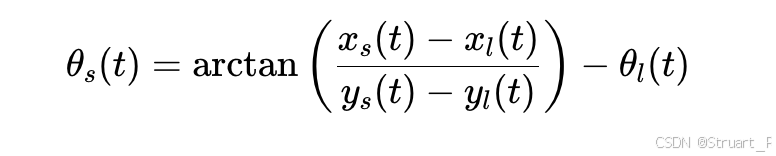
? ? ? ? 聲源距離映射:計算能量衰減系數,進而計算聲音能量下降(模擬聲音隨著距離的平方反比衰減)
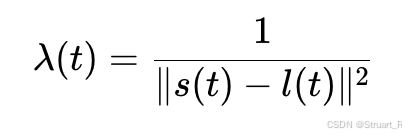
? ? ? ? 雙耳音頻合成:根據SADIE II數據集中的傳遞函數,利用STFT計算左右耳的頻域譜
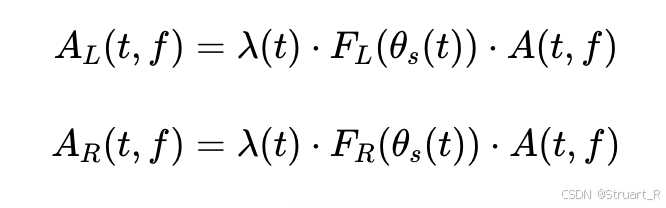
???????
參考論文:
[2405.18213] NeRAF: 3D Scene Infused Neural Radiance and Acoustic Fields
[2503.14359] ImViD: Immersive Volumetric Videos for Enhanced VR Engagement







)








-以太坊共識機制)
計算機網絡)

![ZYNQ [Petalinux的運行]](http://pic.xiahunao.cn/ZYNQ [Petalinux的運行])