一.整數在內存中的存儲
? ? ? ? 在計算機內存中,所有的數字都是以二進制來存儲的。整數也不例外,在計算機內存中,整數往往以補碼的形式來存儲數據。這是為什么呢?
? ? ? ? 在早期計算機表示整數時,最高位為符號位。但是0卻有兩種表示形式:00000000和10000000分別表示正零和負零。這樣兩種零的表示形式,無疑是極其不方便的。但是出現了整數補碼的表示形式。這種形式完美解決了此類問題,因為在計算機內存中,整數以補碼的形式存儲,所以正負零的補碼均為00000000。
? ? ? ? 在計算機內存中表示整數,無非就是為了下來的加、減計算。但是計算機硬件的核心運算單位是加法器,直接實現減法運算會增加電路的復雜度。這時候出現的補碼表示形式,讓讓兩數減法變成了正數和負數的加法,此時的負數用補碼的形式表示,進行兩數相加就可以將二進制的減法運算轉換成加法運算,降低了電路的復雜度。(負數補碼形式加上正數的值正好等于兩正數相減,因為補碼就是這樣巧妙設計的。)
? ? ? ? 補碼的運算規則簡單,就是原碼進行取反后+1,容易實現。并且補碼的符號位無需單獨處理,兩數可以用二進制的補碼形式直接相加,得到的結果符號位自然正確。
? ? ? ? 補碼和原碼表示的范圍相同,因為二進制的位數相同,并且最高位均為符號位,所以范圍相同,這樣就可以更好的參與運算和管理。
? ? ? ? 整數的二進制表示形式有3種,分別是:原碼、反碼、補碼。有符號的整數,三種表示方法均有符號位和數值位兩部分,符號位都是用0表示“正”,用1表示“負”,最高位的一位是被當做符號位,剩余的都是數值位;無符號的整數,最高位不是符號位,而是表示數值。正整數的原碼、反碼、補碼均相同。負整數的反碼=原碼符號位不變,其余數值位取反;補碼=反碼+1。
????????原碼:直接將數值按照正負數的形式翻譯成二進制得到的就是原碼。 反碼:將原碼的符號位不變,其他位依次按位取反就可以得到反碼。 補碼:反碼+1就得到補碼。
二.大小端字節序和字節序判斷
? ? ? ?1.大小端內容的引入
????????上面我們了解了整數在內存中以補碼的形式存儲,下面我們調試內存塊查看一下細節:
#include <stdio.h>
int main()
{int a = 0x11223344; //創建整型變量,用于調試觀察內存return 0;
}
? ? ? ? 上述代碼,我們創建了一個整型變量a,用于存放11223344這個16進制的數字。因為該數字為正數,所以該數的原碼、反碼、補碼相同。計算機數據的存儲是以二進制的形式存儲的,但是為了方便查看調試數據,編譯器會以16進制形式顯示。
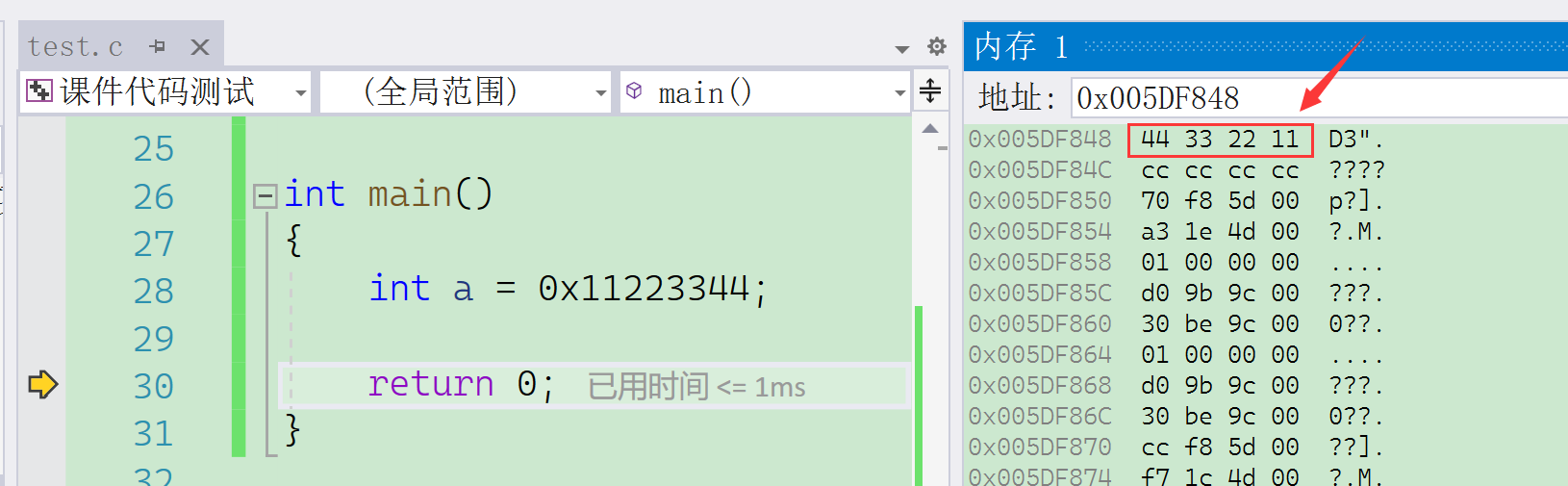
? ? ? ? 根據上面調試的圖片,可以得出:創建的變量a存儲數據時,竟然是倒著存儲的。這是為什么呢?
2.大小端是什么呢?
? ? ? ? 首先在上述的例子中,要把數據存在內存中無非就是下面幾種方法:
???????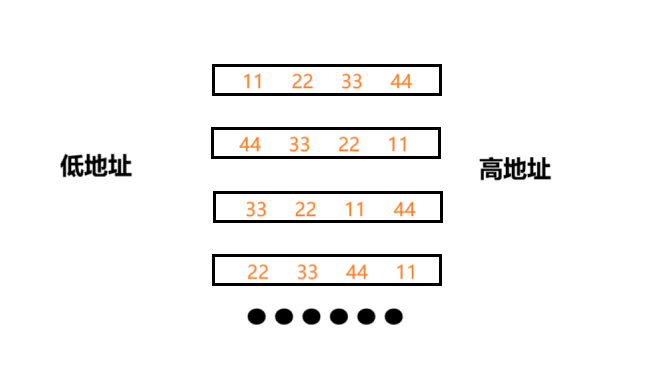
? ? ? ? 上述圖片中,第一個和第二個存儲順序分別是正序、逆序。這樣存儲數據方便數據接下來的訪問,而剩余的存儲數據都是亂序,不方便后續數據的讀取。這就是大小端字節序的由來。
????????超過一個字節的數據在內存中存儲的時候,就有存儲順序的問題,按照不同的存儲順序,我們分為大端字節序存儲和小端字節序存儲,下面是具體的概念:大端存儲模式: 是指數據的低位字節內容保存在內存的高地址處,而數據的高位字節內容,保存在內存的低地址處。(圖片第一種存儲順序)小端存儲模式: 是指數據的低位字節內容保存在內存的低地址處,而數據的高位字節內容,保存在內存的高地址處(圖片第二種存儲順序)。
3.為什么有大小端?
????????這是因為在計算機系統中,我們是以字節為單位的,每個地址單元都對應著一個字節,一個字節為8 bit 位,但是在C語言中除了8?bit 的 char 之外,還有16 bit 的 short 型,32 bit 的 long 型,另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如何將多個字節安排的問題。
????????因此就導致了大端存儲模式和小端存儲模式。 例如:一個 16bit 的short型x ,在內存中的地址為0x0010 , x的值為0x1122 ,那么0x11為高字節, 0x22為低字節。對于大端模式,就將0x11 放在低地址中,即0x0010中, 0x22放在高地址中,即0x0011中。小端模式剛好相反。我們常用的X86 結構是小端模式,而KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
4.練習
(1)練習一
題目表述:設計一個程序來判斷當前機器的字節序。
//代碼1
#include <stdio.h>
int check_sys()
{int i = 1; //創建變量,用于得到首字節地址的內容return (*(char *)&i); //返回首字節地址的內容
}int main()
{int ret = check_sys(); if(ret == 1) //當返回值為1,說明為小端字節存儲printf("?端\n");else //當返回值為0,說明為大端字節存儲printf("?端\n");return 0;
}
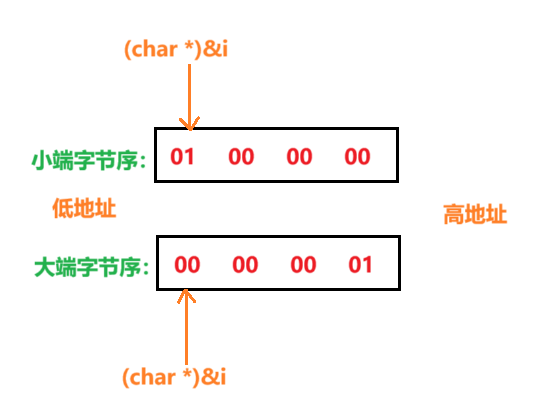
? ? ? ? 上述代碼的具體解釋:首先創建一個整型變量,通過在內存中第一個字節內容的判斷,從而得出該機器的字節序。函數直接返回強制類型轉化為1字節的變量地址的解引用值。利用該變量首字節的內容靈活寫出的長須函數返回值。
//代碼2
int check_sys()
{union //聯合體類型的關鍵字{int i;char c;} un; //創建聯合體變量unun.i = 1; return un.c;
}
? ? ? ? 上述代碼的具體解釋:創建了自定義類型的聯合體,聯合體的特點是:所有的成員共享同一塊內存空間,大小為最大成員的大小。這里創建的聯合體成員變量i=1。并且返回該內存的首字節的地址。所以該代碼2和上述代碼1的效果相同。
(2)練習二
#include <stdio.h>
int main()
{char a= -1;signed char b=-1;unsigned char c=-1;printf("a=%d,b=%d,c=%d",a,b,c);return 0;
}



? ? ? ? ?在計算機中,整數在C語言中默認為32位,所以-1的原碼、反碼、補碼均為32位的二進制的數字;賦值操作將32位的整數賦值給char類型的數字,這時的操作將存在隱式轉換,將獲取32位的后8位進行變量的賦值;在打印時,因為printf函數的占位符為%d,所以打印的是有符號的整數,但是各個變量為不同的char類型,所以在打印之前存在整型提升。當變量為有符號類型時,整型提升的前24位補的是符號位上的數字。如果是無符號的類型,整型提升時前24位補的是0。整型提升后就是需要打印的數據,將其轉換為原碼,最后變為10進制數字,該十進制數字就是最后打印的結果。
(3)練習三
#include <stdio.h>
int main()
{char a = -128;printf("%u\n",a);return 0;
}
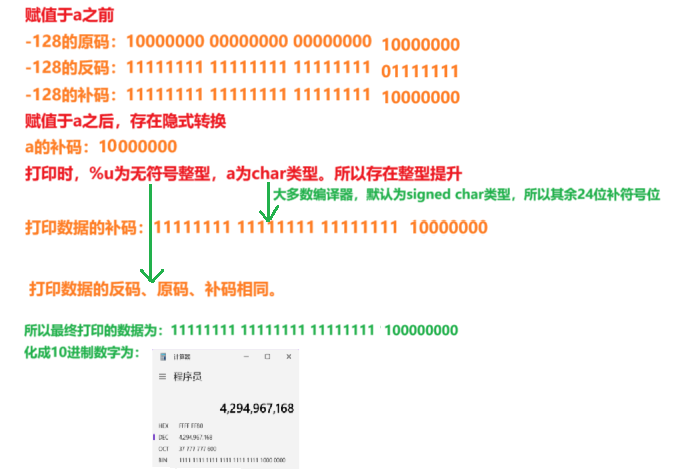
? ? ? ? 因為整數在C語言中默認為32位,所以賦值之前就可以得出-128的原碼、反碼和補碼。賦值操作時,因為-128是32位整數,而變量是只能存儲8位的char類型,所以這里存在隱式轉換。轉換之后,因為占位符是無符號整型,而數字卻是8位數字,所以這里存在整型提升(整型提升的規則由變量的數據類型決定,占位符僅僅決定如何解釋內存中的數據)。當整型提升之后,根據占位符可知,該數是一個無符號整型,所以原碼、反碼、補碼相同,化成10進制的數字為:4294967168。
(4)練習四
#include <stdio.h>
int main()
{char a = 128;printf("%u\n",a);return 0;
}
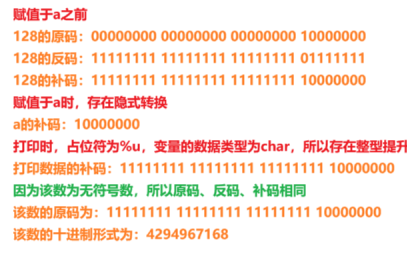
? ? ? ? 在C語言中,整數128賦值前默認為32位,其反碼、補碼、原碼均為32位。賦值時,需要將32位的整數賦值給只能存儲8位的char類型的變量,所以這里存在隱式轉換,只取32位的后8位賦值給變量a。隱式轉換之后,因為打印時,占位符和變量數據類型不匹配,所以這里存在整型提升。將變量的數據類型進行整型提升,得到的數值。根據占位符可知為無符號整型,所以最高位為數值位,不存在符號位,將其轉化為10進制就是打印出來的數據:4294967168。
(5)練習五
#include <stdio.h>
int main()
{char a[1000];int i;for(i=0; i<1000; i++){a[i] = -1-i;}printf("%d",strlen(a));return 0;
}
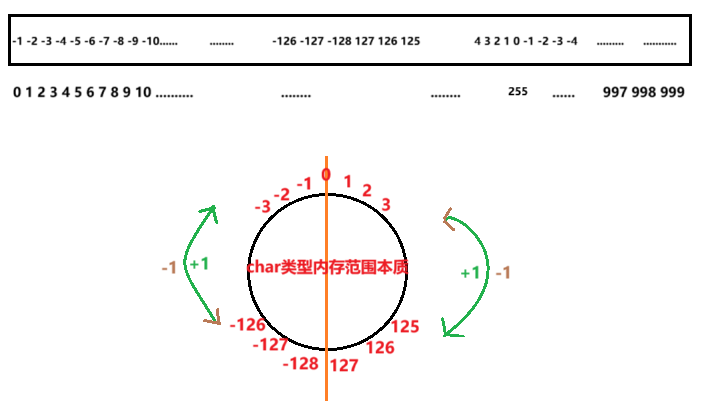
? ? ? ? strlen函數會從給的地址開始向后尋找 \0,找到后返回字符的個數。a位數組名,也就是數組首元素的地址,所以strlen函數會從數組的首元素開始,向后查找,直至找到內存中 \0的數字,后返回字符的個數。這里需要注意的是數組是char[1000]類型的,所以數組元素類型均為char類型,char類型的存儲范圍是:-128~127。當i=255時,char類型的值補碼為:00000000。所以打印的結果為256(因為i是從0開始的)。
(6)練習六
#include <stdio.h>
unsigned char i = 0;
int main()
{for(i = 0;i<=255;i++){printf("hello world\n");}return 0;
}
? ? ? ? 由于char類型的內存范圍是-128~127,所以上述代碼的循環條件恒成立,故該循環會無線循環次數的打印hello world。
(7)練習七
#include <stdio.h>
int main()
{unsigned int i;for(i = 9; i >= 0; i--){printf("%u\n",i);}return 0;
}

? ? ? ? 該代碼首先創建了無符號整型變量變量i,那么變量i恒大于等于0。循環的終止條件永遠達不到,所以循環會無限次的打印數據。當i變為0時,下一次循環會變成非常大的數字:4294967295,然后繼續-1,無限循環。
(8)練習八
#include <stdio.h>
//X86環境 ?端字節序
int main()
{int a[4] = { 1, 2, 3, 4 };int *ptr1 = (int *)(&a + 1);int *ptr2 = (int *)((int)a + 1);printf("%x,%x", ptr1[-1], *ptr2);return 0;
}
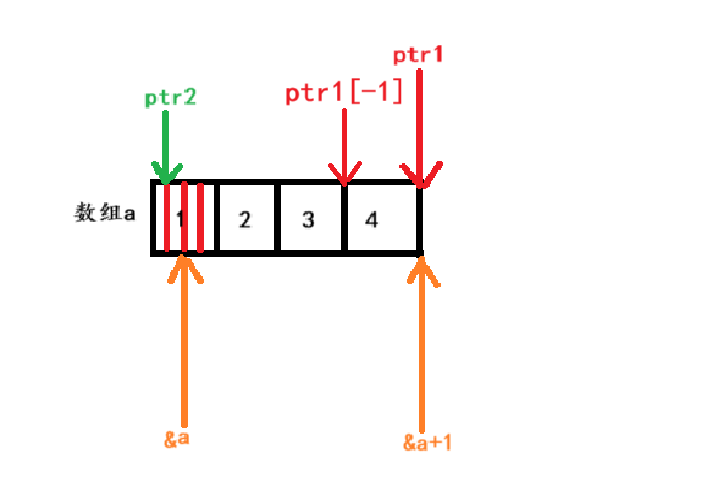
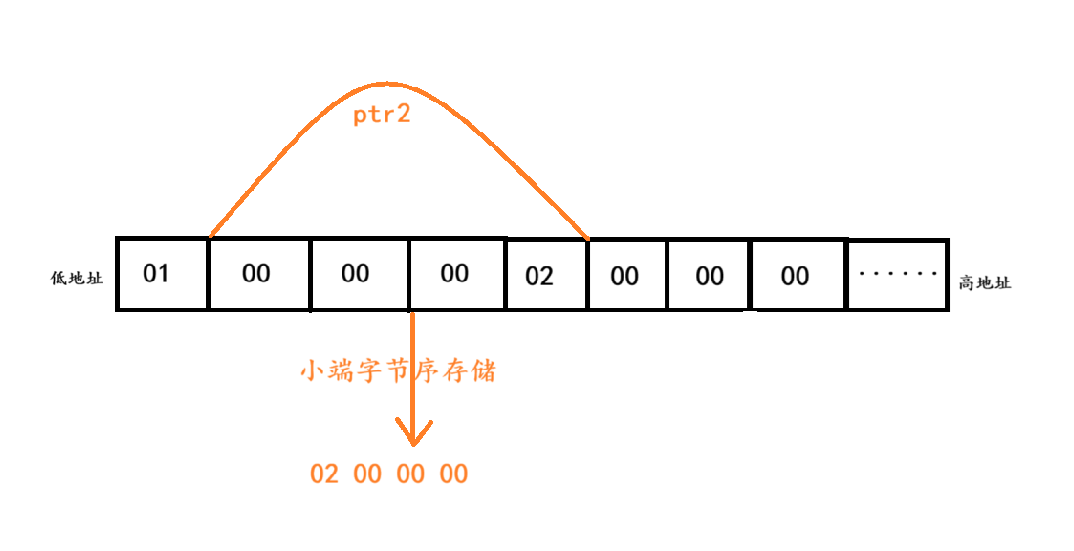
? ? ? ? 上述代碼的具體解釋:首先創建了一個整型數組,ptr1指針指向的位置是該數組末尾,ptr2將數組首元素的地址強制類型轉化為int類型后+1,指向的是數組首元素地址內部的第二部分(詳細見第二張圖片)。ptr2最后為int *類型,打印時就需要得到4個字節的地址。
? ? ? ? %x是16進制的數字打印時所需的占位符。因為該題目已知是小端字節序存儲,所以ptr2得到的數字就是:02 00 00 00。
三.浮點數在內存中的存儲
????????常見的浮點數有:3.14159、1E10等,浮點數的數據類型包括: float、double、long double 類型。?浮點數表示的范圍:在文件float.h中定義,下面是相關文件:
1.引例
#include <stdio.h>
int main()
{int n = 9;float *pFloat = (float *)&n;printf("n的值為:%d\n",n);printf("*pFloat的值為:%f\n",*pFloat);*pFloat = 9.0;printf("num的值為:%d\n",n);printf("*pFloat的值為:%f\n",*pFloat);return 0;
}
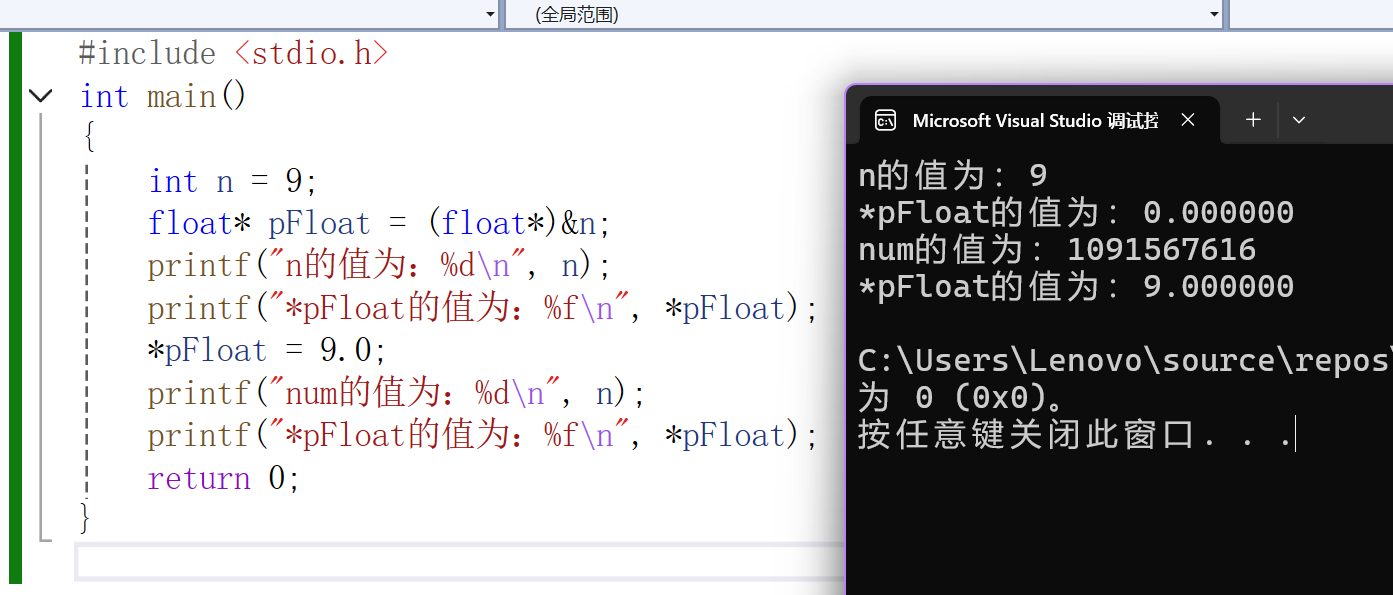
? ? ? ? 上述代碼的具體分析:創建了整型變量n,初始化為9。分別用整型和浮點型的形式進行打印,經過預測答案應該是:9 9.0 9 9.0(錯誤答案),但是經過運行發現并不是這樣的結果。這種現象說明浮點數和正數在內存中的存儲方式并不相同。
2.浮點數的存儲
????????上面的代碼中,num 和*pFloat在內存中明明是同一個數,為什么浮點數和整數的解讀結果會差別這么大?要理解這個結果,一定要搞懂浮點數在計算機內部的表示方法。 根據國際標準IEEE(電氣和電子工程協會)754,任意一個二進制浮點數V,可以表示成下面的形式:

? ? ? ? 舉例子來說:十進制的5.0,寫成二進制是 101.0 ,相當于 1.01×2^2 。那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。十進制的 -5.0,寫成二進制是 -101.0 ,相當于 -1.01×2^2 。那么,S=1,M=1.01,E=2。
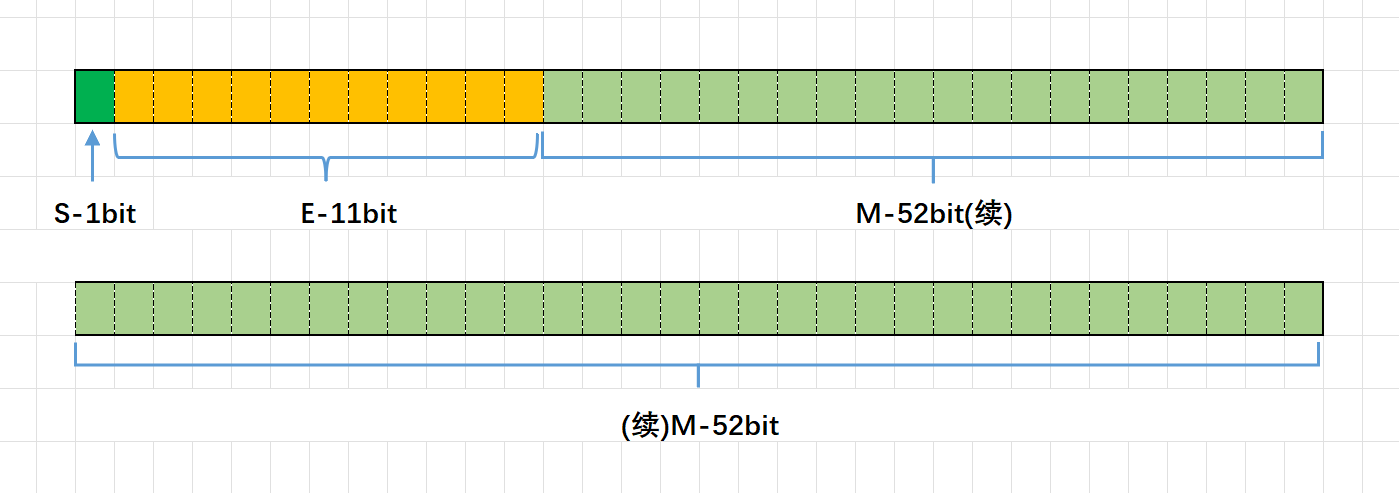
????????IEEE 754規定:對于32位的浮點數,最高的1位存儲符號位S,接著的8位存儲指數E,剩下的23位存儲有效數字M;對于64位的浮點數,最高的1位存儲符號位S,接著的11位存儲指數E,剩下的52位存儲有效數字M。

3.浮點數存的過程
????????IEEE 754對有效數字M和指數E,還有一些特別的規定。前面說過, M>=1,也就是說,M可以寫成 1.xxxxxx 的形式,其中 xxxxxx 表示小數部分。IEEE 754規定,在計算機內部保存M時,默認這個數的第一位總是1,因此可以被舍去,只保存后面的 xxxxxx小數部分。比如保存1.01的時候,只保存01,等到讀取的時候,再把第一位的1加上去。這樣做的目的,是節省1位有效數字。以32位浮點數為例,留給M只有23位,將第一位的1舍去以后,等于可以保存24位有效數字。
? ? ? ? 至于指數E,情況就比較復雜,首先,E為一個無符號整數。這意味著,如果E為8位,它的取值范圍為0~255;如果E為11位,它的取值范圍為0~2047。但是,科學計數法中的E是可以出現負數的,所以IEEE 754規定,存入內存時E的真實值必須再加上一個中間數,保證E最后成為一個無符號整數。對于8位的E,這個中間數是127;對于11位的E,這個中間數是1023。比如,2^10的E是10,所以保存成32位浮點數時,必須保存成10+127=137,二進制形式即10001001。
4.浮點數取的過程
????????指數E從內存中取出還可以再分成三種情況:
E不全為0或不全為1時,
浮點數就采用下面的規則表示,即指數E的計算值減去127(或1023),得到真實值,再將有效 數字M前加上第一位的1(將存的過程倒著來一遍)。
? ? ? ? 比如:0.5的二進制形式為0.1,由于規定正數部分必須為1,即將小數點右移1位,則為1.0*2^ (-1),其階碼為-1+127(中間值)=126,表示為01111110,而尾數1.0去掉整數部分為0,補齊0到23位 00000000000000000000000,則其二進制表示形式為:
0 01111110 00000000000000000000000
E全為0時
浮點數的指數E等于1-127(或者1-1023)即為真實值,有效數字M不再加上第一位的1,而是還原為0.xxxxxx的小數。這樣做是為了表示±0,以及接近于0的很小的數字。
0 00000000 00100000000000000000000
E全為1時
如果有效數字M全為0,表示±無窮大(正負取決于符號位S);
0 11111111 00010000000000000000000
5.題目解析
? ? ? ? 經過上面的學習,我們接下來看引例的題目。
#include <stdio.h>
int main()
{int n = 9;float *pFloat = (float *)&n;printf("n的值為:%d\n",n);printf("*pFloat的值為:%f\n",*pFloat);*pFloat = 9.0;printf("num的值為:%d\n",n);printf("*pFloat的值為:%f\n",*pFloat);return 0;
}
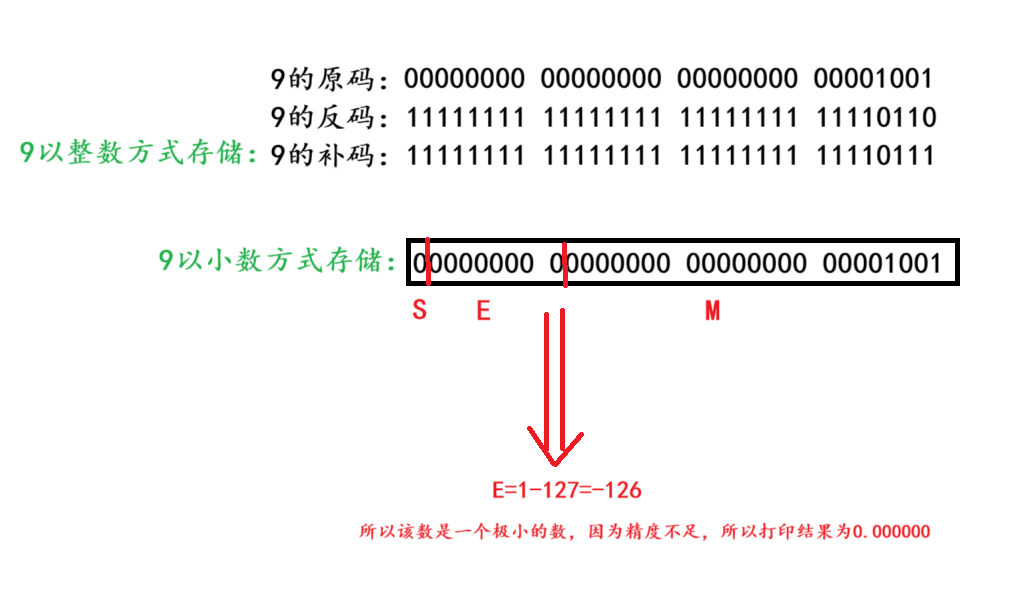

? ? ? ? 上述題目的具體解釋:代碼首先創建了整型變量n,用于存儲整型9。接下來以%d形式打印有符號整型,結果就是9;但是浮點數在內存中會將9的原碼以folat類型來分類存儲S M E。如圖一所示:前一位表示S,接下來8位表示E,后面的23位表示M。根據E為全0的定義,打印的精度不足,最后就會打印出:0.000000;下來在內存中存儲小數9.0,但是卻以整數方式讀取數據,內存就會認為存儲的浮點數是整數的補碼,得到原碼后,打印結果就是對應的10進制數字;因為是浮點數的存儲,所以如圖二:S=0 M=1.001 E=3。最終以%f 形式打印,結果就是:9.000000。









)



:Vue3 表格動態增加刪除行解決方案)





(持續更新))