Stand-In:一種輕量化、即插即用的身份控制方法用于視頻生成
paper是WeChat發布在Arxiv 2025的工作
paper title:Stand-In: A Lightweight and Plug-and-Play Identity Control for Video Generation
Code:鏈接
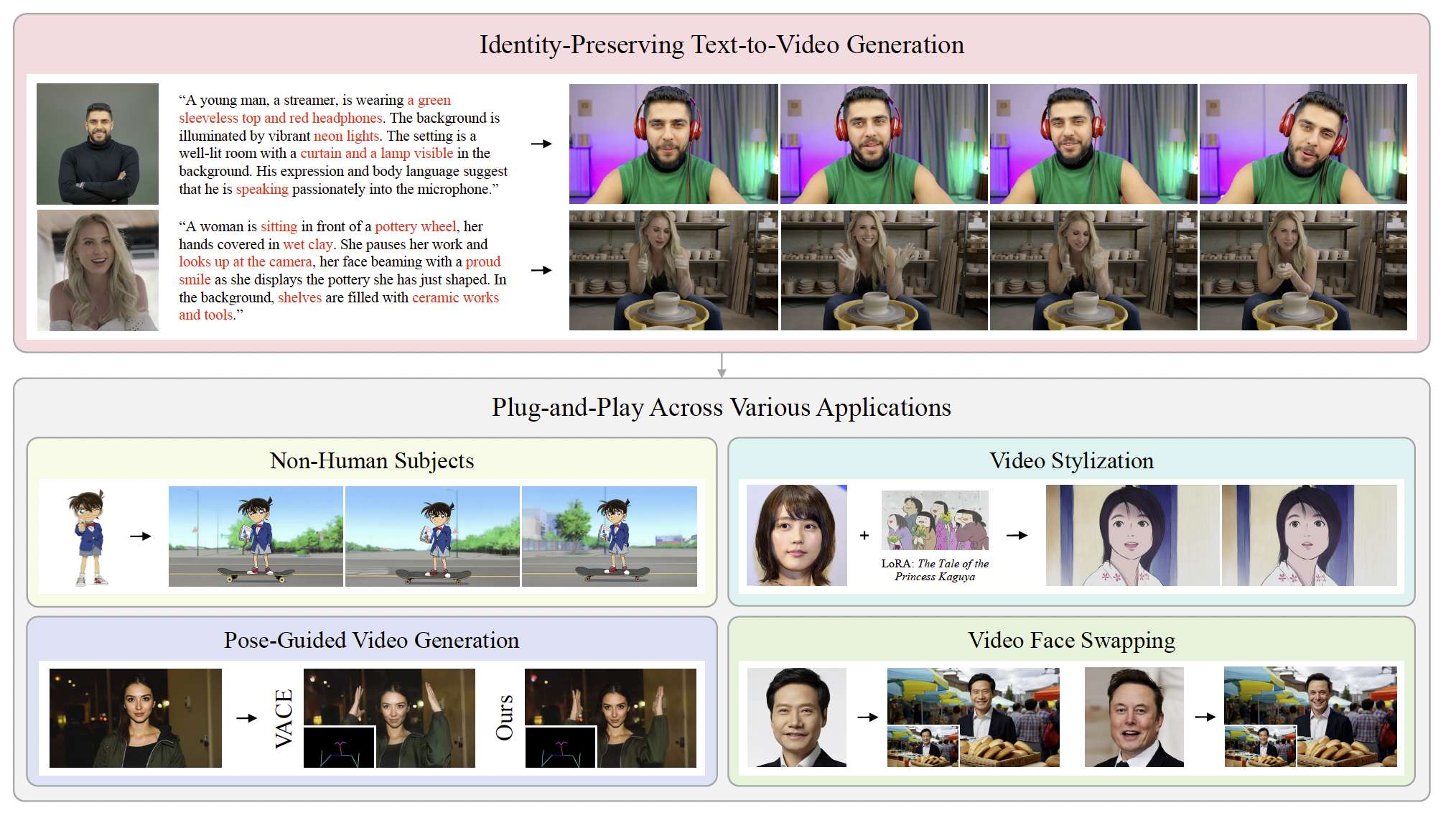
圖1:給定一張參考圖像,我們的方法能夠生成具有強身份保持的視頻。此外,該框架的即插即用設計能夠無縫集成到各種應用中,以增強身份一致性。
Abstract
在生成式人工智能領域,生成與用戶指定身份匹配的高保真人類視頻非常重要但具有挑戰性。現有方法通常依賴于大量的訓練參數,并且缺乏與其他AIGC工具的兼容性。本文提出了一種名為Stand-In的輕量化即插即用框架,用于視頻生成中的身份保持。具體而言,我們在預訓練的視頻生成模型中引入了條件圖像分支。通過帶有條件位置映射的受限自注意力機制實現身份控制,并且僅需2000對數據即可快速學習。盡管只引入并訓練了約1%的額外參數,我們的框架在視頻質量和身份保持方面取得了優異的效果,超過了其他全參數訓練方法。此外,我們的框架還可無縫集成到其他任務中,如基于主體驅動的視頻生成、基于姿態參考的視頻生成、風格化以及人臉替換。
Introduction
隨著擴散模型(Ho, Jain, and Abbeel 2020; Podell et al. 2024; Peebles and Xie 2023)的快速發展,視頻生成(Zheng et al. 2024; Peng et al. 2025; Kong et al. 2024; Hong et al. 2023)已成為生成式人工智能的重要組成部分。在其多樣化的應用中,身份保持的視頻生成具有深遠意義。該任務的目標是生成高質量的視頻,并始終保持給定參考圖像(包含人臉)的身份一致性。這一技術在電影、廣告、游戲等行業中具有廣泛的應用價值。
現有方法可分為兩類:傳統方法(He et al. 2024; Yuan et al. 2025b)使用顯式的人臉編碼器提取身份特征;最新方法(Hu et al. 2025; Liu et al. 2025)則完全訓練擴散變換器。然而,基于人臉編碼器的方法缺乏靈活性,難以捕捉高質量視頻生成所需的細致面部細節;全參數訓練方法則需要大量參數,并且與其他應用缺乏兼容性。因此,以輕量化且靈活的方式實現穩健的身份保持依然是關鍵且具有挑戰性的問題。
為克服這些局限性,我們利用視頻生成模型本身的預訓練VAE,使條件圖像能夠直接映射到與視頻相同的潛空間中。該方法自然地利用了模型固有的能力來提取豐富且細致的面部特征,提供了更為集成和高效的解決方案。此外,為實現輕量化設計并避免引入過多參數,我們采用了帶有條件位置映射的受限自注意力機制。一方面,這可以有效地將參考圖像的特征融合到視頻中;另一方面,它不會改變視頻生成主模型的架構,因此可在其他應用中以即插即用的方式使用,如圖1所示。實驗結果表明,在身份保持視頻生成中,我們的方法在面部相似度和自然度上均達到最高水平,同時所需訓練的參數量最少(如圖2所示)。憑借其即插即用能力,我們的框架可擴展至多種任務,包括主體驅動生成、視頻風格化和人臉替換,同時保持身份一致性。此外,通過與VACE(Jiang et al. 2025)的兼容集成,我們的方法在姿態引導視頻生成中顯著提升了面部相似度。

圖2:與SOTA身份保持視頻生成方法的對比。氣泡的大小表示身份保持所需訓練的參數數量。我們的方法在面部相似度和自然度方面均取得最高性能,同時使用的參數最少。
我們的主要貢獻總結如下:
- 我們提出了Stand-In,這是一種輕量化且即插即用的身份保持視頻生成框架。僅需引入并訓練約1%的額外參數,即可在身份保持、視頻質量和提示遵循方面實現SOTA性能。
- 為在無顯式人臉特征提取器的情況下注入身份信息,我們在視頻生成模型中引入了條件圖像分支。圖像與視頻分支通過帶有條件位置映射的受限自注意力機制共享信息。借助這一輕量化設計,僅使用小規模數據集即可很好地學習身份保持。
- 所提框架具有高度的兼容性和泛化性。盡管僅在真人數據上進行訓練,我們的方法也能泛化到卡通、物體等其他主體。此外,我們的方法可即插即用地應用于姿態引導視頻生成、視頻風格化和人臉替換等任務。
Related Work
視頻生成模型 當前的視頻生成模型主要構建在擴散框架(Ho, Jain, and Abbeel 2020)之上,其架構從基于U-Net的設計(Blattmann et al. 2023)顯著發展到基于DiT的方法(Kong et al. 2024; Team 2025; Ma et al. 2025)。在基于U-Net的擴散模型時代,文本到圖像(T2I)框架(Rombach et al. 2022; Podell et al. 2024)通過引入3D卷積和時間注意力(Blattmann et al. 2023)擴展到了視頻生成。AnimateDiff(Guo et al. 2024)進一步推動了這一方向的發展,通過添加時間層重用預訓練的文本到圖像模型權重,以利用其強大的空間生成能力。Latte(Ma et al. 2025)引入了時空分離機制,將不同的DiT模塊分別用于處理空間和時間信息。該方法后來被3D全注意力機制所取代,從而實現了更為一體化的處理。CogVideoX(Yang et al. 2025)和HunyuanVideo(Kong et al. 2024)結合了3D-VAE(Yu et al. 2024)與MM-DiT(Esser et al. 2024)以增強視頻生成能力。WAN2.1(Team 2025)采用3D-VAE并使用DiT骨干網絡進行去噪,通過交叉注意力將語義提示信息注入擴散過程。
身份保持生成 傳統方法通常依賴顯式人臉編碼器進行面部特征提取,以生成身份保持的視頻。IDanimator(He et al. 2024)將預訓練的文本到視頻擴散模型與輕量化人臉適配器結合,從可調的人臉潛在查詢中編碼與身份相關的嵌入。ConsistID(Yuan et al. 2025b)旨在通過擴散變換器中的頻率分解來保持身份一致性。Phantom(Liu et al. 2025)也可以在人物領域中保持身份一致性,作為一個統一的主體一致性視頻生成框架。HunyuanCustom(Hu et al. 2025)是一個多模態定制化視頻生成框架,強調身份一致性,同時支持多樣化的輸入模態。它通過引入先進的條件注入機制和身份保持策略,在高質量視頻生成中取得了優異的性能。他們對擴散變換器進行了全量微調,導致可訓練參數數量龐大。
Method
在本節中,我們首先介紹所提方法的整體框架。接著,詳細說明帶有條件位置映射的受限自注意力機制。最后,我們給出數據收集過程。
Conditional Image Branch
為提取面部特征,傳統方法依賴顯式人臉編碼器,這類方法缺乏靈活性,并且常常無法保留高質量重建所需的精細面部細節。相比之下,我們提出利用視頻生成模型的預訓練VAE。
該策略將條件圖像直接映射到與視頻相同的潛空間中,使我們能夠自然地利用預訓練視頻生成模型的內在能力來提取豐富的面部特征。
整體框架如圖3所示。我們采用Wan2.1 14B T2V(Team 2025)作為視頻生成基礎模型,該模型使用擴散變換器(DiT)架構。給定一張包含人臉的參考圖像,我們首先使用預訓練VAE編碼器將其編碼到潛空間中。圖像潛向量與視頻潛向量經歷相同的分塊和編碼過程。
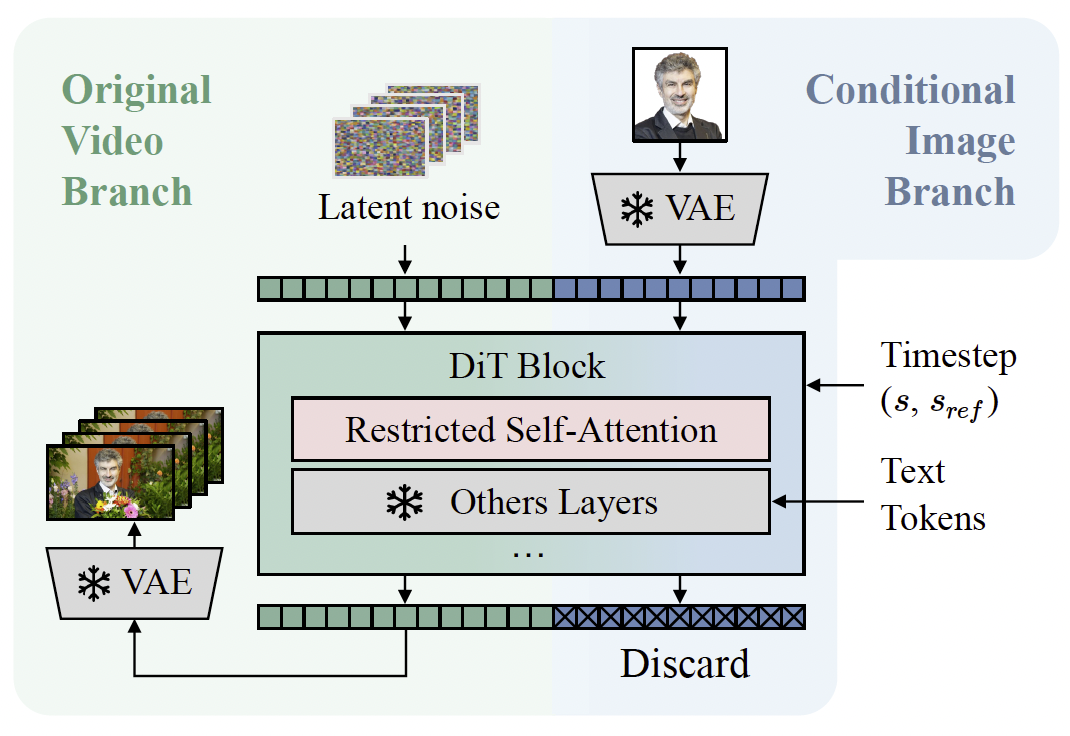
圖3:我們的身份保持文本到視頻生成框架概覽。我們在原有視頻分支的基礎上引入了條件圖像分支。給定條件圖像,VAE編碼器將其映射為token,這些token與視頻潛token進行拼接,然后送入DiT。在DiT模塊中,通過受限自注意力機制將身份信息融入視頻特征中。
隨后,圖像token與視頻token在序列維度上進行拼接,并通過連續的網絡模塊聯合處理。最后,在最終層中丟棄圖像token。
設sss表示擴散過程中的去噪時間步。為了保持參考圖像的靜態特性(其作為條件輸入而非參與去噪過程),我們保持其時間不變性。這通過將其時間步固定為零來實現,即sref=0s_{ref} = 0sref?=0。
現在,我們已經將條件圖像編碼到與視頻相同的特征空間中,接下來的挑戰是:如何讓視頻特征能夠以輕量且易于學習的方式有效地引用圖像信息?
Restricted Self-Attention
在上述DiT模塊中,參考圖像token和視頻token在大多數模塊(包括層歸一化、交叉注意力和前饋網絡)中是獨立處理的,唯一的例外是自注意力層。自注意力層能夠在所有token之間進行信息交換,從而自然地使視頻token能夠引用身份信息。然而,由于參考圖像作為靜態條件存在,它應當不受視頻動態內容的影響。因此,為了在引入身份信息的同時保持其獨立性,我們提出將DiT中的自注意力層替換為一種受限版本,該版本顯式地防止圖像查詢訪問視頻鍵。
如圖4所示,對于一個自注意力層,我們首先分別為圖像和視頻token計算Query、Key和Value,分別記為QI,KI,VIQ_I, K_I, V_IQI?,KI?,VI?和QV,KV,VVQ_V, K_V, V_VQV?,KV?,VV?。隨后,我們將KVK_VKV?與KIK_IKI?拼接,并將VVV_VVV?與VIV_IVI?拼接用于QVQ_VQV?。為了增強模型在保持固有生成魯棒性的同時利用身份相關信息的能力,我們在圖像token的QKV投影中引入了低秩適配(LoRA)。
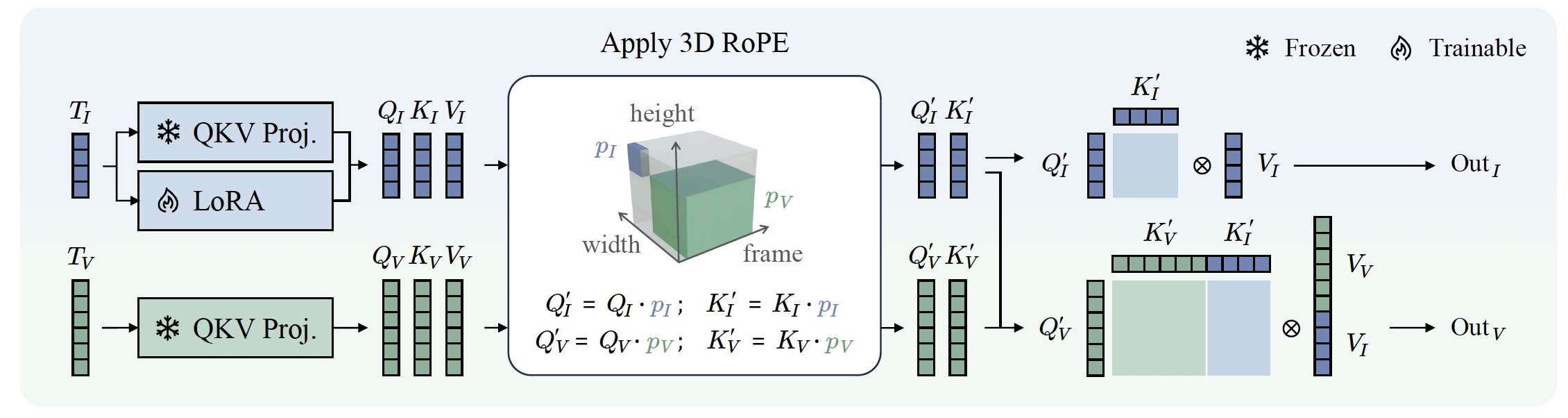
圖4:我們的受限自注意力設計:對于輸入的視頻token和圖像token,我們分別計算它們的Query、Key和Value矩陣。接著,對Query和Key矩陣應用3D RoPE。最后,圖像矩陣獨立運行,而視頻的Query則使用圖像與視頻的Key和Value矩陣拼接后進行注意力計算。
條件位置映射 為了在受限自注意力中有效區分圖像token和視頻token,我們使用了一種專門的條件位置映射策略。具體而言,我們采用三維旋轉位置嵌入(3D RoPE)(Su et al. 2024),其中所有與參考圖像相關的token都被分配到一個獨立且專用的坐標空間。這種設計確保了參考圖像與視頻token之間的清晰分離,并有助于精確建模二者的交互關系。
在時間維度上,我們為參考圖像token分配固定的時間因子-1,而將視頻token映射到非負的時間位置。這種分配方式將圖像token建立為時間不變的條件輸入,從而引導模型在整個去噪過程中將參考圖像的身份信息作為恒定指導,而不是與視頻時間序列中的瞬態幀特定特征混淆。
在空間維度上,我們采用不重疊的坐標策略,以實現參考圖像與視頻內容的空間解耦。視頻幀在坐標域(h,w)∈[0,HV)×[0,WV)(h,w) \in [0,H_V) \times [0,W_V)(h,w)∈[0,HV?)×[0,WV?)內分布,而參考圖像token被映射到專用的坐標子空間[HV,HV+HI)×[WV,WV+WI)[H_V, H_V+H_I) \times [W_V, W_V+W_I)[HV?,HV?+HI?)×[WV?,WV?+WI?),其中HIH_IHI?和WIW_IWI?表示參考圖像的空間尺寸。
這種不重疊的空間分配通過幾何分離實現了兩個主要目標:一方面,自然減少了虛假的空間相關性,防止模型過度依賴像素級匹配;另一方面,保持參考圖像的語義意義,將其作為全局身份先驗。這樣,模型會更專注于從參考token中提取整體語義特征,而不是將其視為必須在位置上與視頻內容對齊的局部模式。
設pIp_IpI?為圖像token的坐標,pVp_VpV?為視頻token的坐標,我們對視頻token應用3D RoPE的方式如下:
QI′=QI?pI,KI′=KI?pI,(1)Q'_I = Q_I \cdot p_I,\quad K'_I = K_I \cdot p_I, \tag{1} QI′?=QI??pI?,KI′?=KI??pI?,(1)
QV′=QV?pV,KV′=KV?pV,(2)Q'_V = Q_V \cdot p_V,\quad K'_V = K_V \cdot p_V, \tag{2} QV′?=QV??pV?,KV′?=KV??pV?,(2)
其中?\cdot?表示Hadamard積。受限自注意力的輸出計算為:
OutI=Attention(QI′,KI′,VI),(3)\text{Out}_I = \text{Attention}(Q'_I, K'_I, V_I), \tag{3} OutI?=Attention(QI′?,KI′?,VI?),(3)
OutV=Attention(QV′,[KV′,KI′],[VV,VI]),(4)\text{Out}_V = \text{Attention}(Q'_V, [K'_V, K'_I], [V_V, V_I]), \tag{4} OutV?=Attention(QV′?,[KV′?,KI′?],[VV?,VI?]),(4)
其中[,][\, , \,][,]表示拼接操作。
KV緩存 由于條件圖像的時間步固定為sref=0s_{ref}=0sref?=0,其Key和Value矩陣在整個擴散去噪過程中保持不變。因此,在推理時我們可以緩存KIK_IKI?和VIV_IVI?以加速計算。這些矩陣在第一次去噪步驟中計算并存儲,后續步驟無需重復計算。
Dataset Collection and Processing
我們構建了一個以人為中心的視頻數據集,包含來自公開可用來源的2000段高分辨率視頻序列。該數據集保證了多樣且全面的表現形式,包括不同種族、年齡范圍、性別身份以及多種多樣的動作。利用VILA(Lin et al. 2024)多模態標注框架,我們為每個視頻自動生成密集的文本標注,從而實現了強文本-視頻對齊。
為使數據集與我們的視頻生成基礎模型(Team 2025)的預訓練分布保持一致,并減輕生成質量可能的下降,我們對視頻進行了如下預處理:每段視頻重采樣為25 FPS,然后裁剪并調整為832×480像素的分辨率。在這些處理后的視頻中,我們隨機采樣連續81幀的片段用于訓練。
對于每個視頻片段,相應的參考人臉圖像從原始(未重采樣)視頻中提取,具體流程如下:
- 從原始視頻中隨機選取5幀。
- 使用RetinaFace(Deng et al. 2020)檢測并裁剪人臉區域。
- 將裁剪的人臉圖像調整為512×512像素。
- 使用BiSeNet(Yu et al. 2018)進行人臉解析,并將背景替換為純白色,以防止背景信息泄露。
用于訓練的最終圖文視頻對示例如圖5所示。

圖5:我們以人為中心的視頻數據集示例。
Experiments
Implementation Details
我們采用秩為128的LoRA,僅應用于每個DiT模塊中圖像token的QKV投影。對于參數量為14B的Wan2.1模型,這僅增加了1.53億個可訓練參數(占基礎模型的1%),使前饋計算時間增加了3.6%,FLOPs增加了2.6%。在使用KV緩存進行推理時,開銷極小:運行時間僅比視頻生成基礎模型增加2.3%,FLOPs僅增加0.07%。這一可以忽略的成本表明,我們的身份保持方法是輕量化的。模型在Nvidia H20 GPU上以批量大小48訓練3000步。在推理過程中,BiSeNet被用作自動預處理步驟。



















