一、生產者分區策略
1.1 分區好處
(1)便于合理使用存儲資源,每個Partition在一個Broker上存儲,可以把海量的數據按照分區切割成一塊一塊數據存儲在多臺Broker上。合理控制分區的任務,可以實現負載均衡的效果。
(2)提高并行度,生產者可以以分區為單位發送數據;消費者可以以分區為單位進行消費數據。
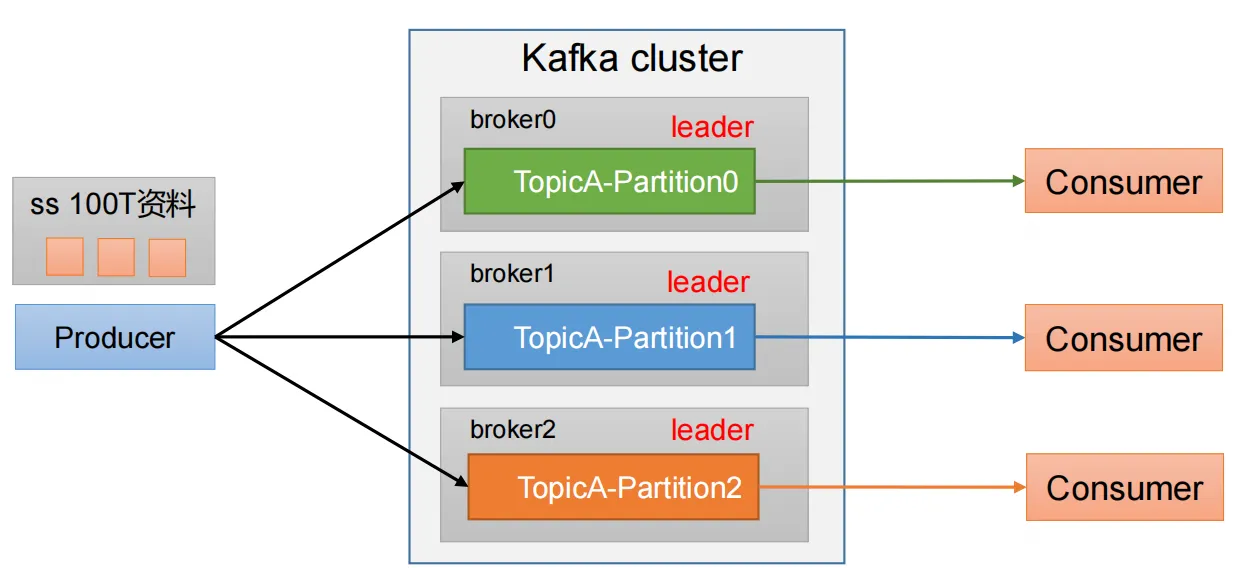
1.2 生產者發送消息的分區策略
1)默認的分區器 DefaultPartitioner
在 IDEA 中 ctrl +n,全局查找 DefaultPartitioner。
/**
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record, use it假如發送消息的時候指定分區,就使用這個分區
* <li>If no partition is specified but a key is present choose a
partition based on a hash of the key假如發送消息沒有指定分區,指定了Key值,對Key進行hash,然后對分區數取模,得到哪個分區就使用哪個分區
* <li>If no partition or key is present choose the sticky
partition(粘性分區) that changes when the batch is full.假如分區和key值都沒有指定,使用粘性分區(黏住它,使用它,發送完畢為止)
*
* See KIP-480 for details about sticky partitioning.
*/
public class DefaultPartitioner implements Partitioner {… …
}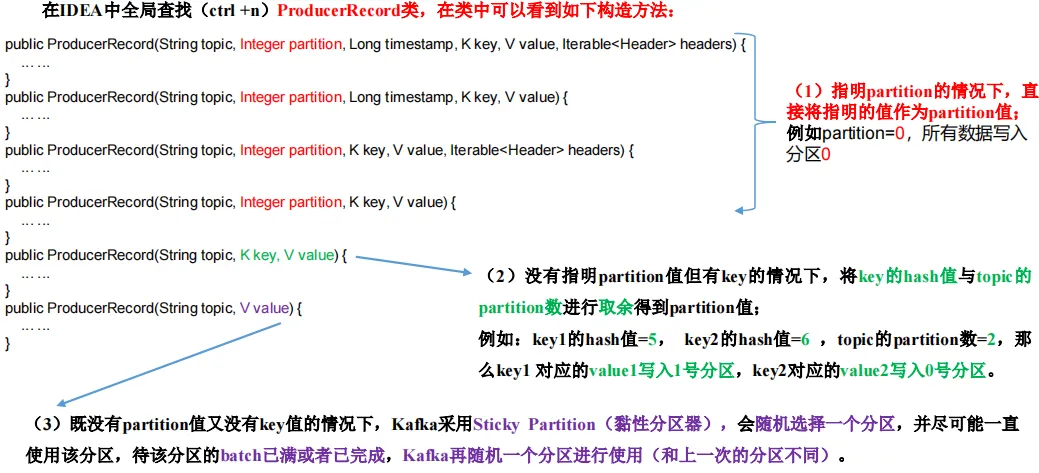
例如:第一次隨機選擇0號分區,等0號分區當前批次滿了(默認16k)或者linger.ms設置的時間到, Kafka再隨機一個分區進行使用(如果還是0會繼續隨機)。
2)案例一
將數據發往指定 partition 的情況下,例如,將所有數據發往分區 1 中。
測試:
①在 node01 上開啟 Kafka 消費者。
kafka-console-consumer.sh --bootstrap-server node01:9092 --topic first②在 IDEA 中執行代碼,觀察 bigdata01 控制臺中是否接收到消息。
bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --topic first③在 IDEA 控制臺觀察回調信息。
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
主題:first->分區:03)案例二
沒有指明 partition 值但有 key 的情況下,將 key 的 hash 值與 topic 的 partition 數進行取余得到 partition 值。
測試:
①key="a"時,在控制臺查看結果。
主題:first->分區:1
主題:first->分區:1
主題:first->分區:1
主題:first->分區:1
主題:first->分區:1
②key="b"時,在控制臺查看結果。
主題:first->分區:2
主題:first->分區:2
主題:first->分區:2
主題:first->分區:2
主題:first->分區:2
③key="f"時,在控制臺查看結果。
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
1.3 自定義分區器
如果研發人員可以根據企業需求,自己重新實現分區器。
1)需求
例如我們實現一個分區器實現,發送過來的數據中如果包含 bigdata,就發往 0 號分區, 不包含bigdata,就發往 1 號分區。
2)實現步驟
(1)定義類實現 Partitioner 接口。
(2)重寫 partition()方法
package com.bigdata.partitioner;import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;import java.util.Map;public class MyPartitioner implements Partitioner {/*** 返回信息對應的分區* @param topic 主題* @param key 消息的 key* @param keyBytes 消息的 key 序列化后的字節數組* @param value 消息的 value* @param valueBytes 消息的 value 序列化后的字節數組* @param cluster 集群元數據可以查看分區信息* @return*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 假如消息中含有bigdata 發送0分區,否則發送1分區String msg = new String(valueBytes);if(msg.contains("bigdata")){return 0;}return 1;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
(3)使用分區器的方法,在生產者的配置中添加分區器參數
package com.bigdata.producer;import org.apache.kafka.clients.producer.*;import java.util.Properties;
import java.util.concurrent.ExecutionException;public class CustomProducer06 {public static void main(String[] args) throws InterruptedException, ExecutionException {Properties properties = new Properties();// 設置連接kafka集群的ip和端口properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");properties.put("bootstrap.servers", "bigdata01:9092");properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.bigdata.partitioner.MyPartitioner");KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);for (int i = 0; i < 10; i++) {ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("second","abc","加油!:"+i);kafkaProducer.send(producerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {System.out.printf("消息發送給了%d分區\n",(metadata.partition()));}});}kafkaProducer.close();}
}
4)測試
測試按照以下幾種情況:
第一種:使用了自定義分區器,并且指定分區發送
第二種:使用了自定義分區器,并且發送的時候帶有 key 值
第三種:使用了自定義分區器,沒有指定分區和 key
每一種測試時消息發送帶有 bigdata 的,再 換成不含 bigdata 的。
①在 bigdata01 上開啟 Kafka 消費者。
kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first ②在 IDEA 控制臺觀察回調信息。
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
主題:first->分區:0
注意:假如我自定義了一個分區規則,如果代碼中指定了消息發送到某個分區,自定義的分區規則無效。
比如:我自定義了一個分區器,包含 bigdata 發送 0 分區,不包含發送 1 分區,但假如發送消息的時候指定消息發送到 2 分區,那么消息就必然發送 2 分區。不走咱們自定義的分區器規則了。
如果沒有指定分區規則,指定了 key 值,那么依然走我們的自定義分區器,不走默認。
二、消費者分區策略
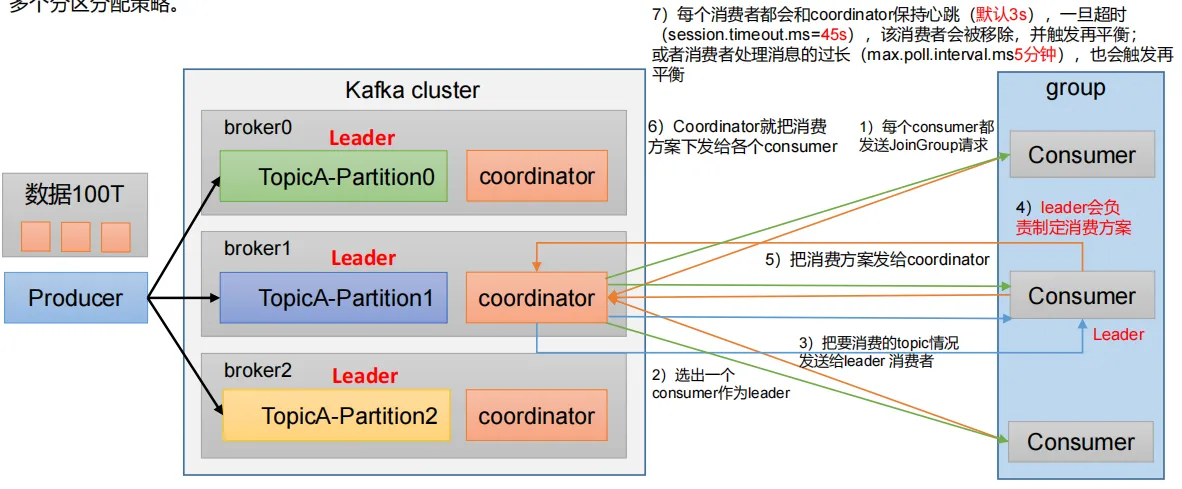
1、一個consumer group中有多個consumer組成,一個 topic有多個partition組成,現在的問題是,到底由哪個consumer來消費哪個partition的數據。
2、Kafka有四種主流的分區分配策略: Range、RoundRobin(輪詢)、Sticky(粘性)、CooperativeSticky(配合的粘性)。
可以通過配置參數partition.assignment.strategy,修改分區的分配策略。默認策略是Range + CooperativeSticky
參數名稱 | 描述 |
heartbeat.interval.ms | Kafka 消費者和 coordinator 之間的心跳時間,默認 3s。 該條目的值必須小于session.timeout.ms,也不應該高于 session.timeout.ms 的 1/3。 |
session.timeout.ms | Kafka 消費者和 coordinator 之間連接超時時間,默認 45s。超 過該值,該消費者被移除,消費者組執行再平衡。 |
max.poll.interval.ms | 消費者處理消息的最大時長,默認是 5 分鐘。超過該值,該 消費者被移除,消費者組執行再平衡 |
partition.assignment.strategy | 消 費 者 分 區 分 配 策 略 , 默 認 策 略 是 Range +CooperativeSticky。Kafka 可以同時使用多個分區分配策略。 可 以 選 擇 的 策 略 包 括 : Range 、 RoundRobin 、 Sticky 、CooperativeSticky |
2.1 Range 以及再平衡
1)Range 分區策略原理
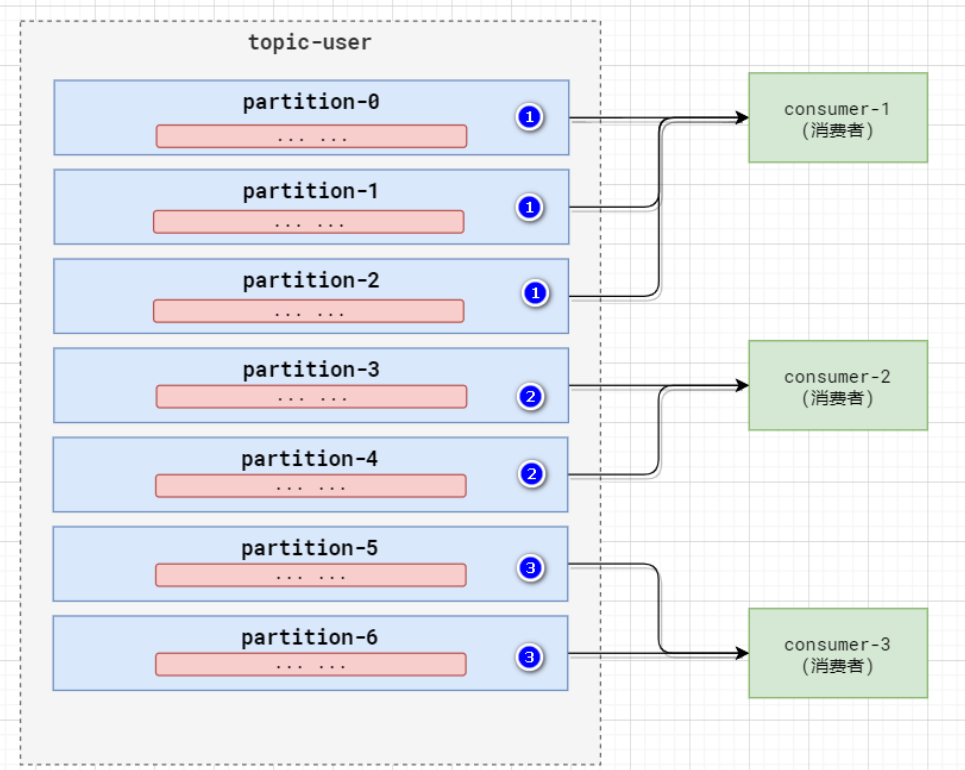
Range 是對每個 topic 而言的。
首先對同一個topic里面的分區按照序號進行排序,并對消費者按照字母順序進行排序。
假如現在有7個分區,3個消費者,排序后的分區將會是0,1,2,3,4,5,6;消費者排序完之后將會是C0,C1,C2。
通過partitions數/consumer數來決定每個消費者應該消費幾個分區。如果除不盡,那么前面幾個消費者將會多
消費1個分區,
例如,7/3=2余1,除不盡,那么消費者C0便會多消費1個分區。8/3=2余2,除不盡,那么C0和C1分別多
消費一個。
注意:如果只是針對1個topic而言,C0消費者多消費1個分區影響不是很大。但是如果有N多個topic,那么針對每個 topic,消費者C0都將多消費1個分區,topic越多,C0消費的分區會比其他消費者明顯多消費N個分區。
容易產生數據傾斜!
2)Range 分區分配策略案例
(1)修改主題 first 為 7 個分區。
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --alter --topic first --partitions 7
2)這樣可以由三個消費者
CustomConsumer、CustomConsumer1、CustomConsumer2 組成消費者組,組名都為“test”, 同時啟動 3 個消費者。
(3)啟動生產者,發送 500 條消息,隨機發送到不同的分區。
注意:分區數可以增加,但是不能減少。
一個主題,假如副本數想修改,是否可以直接修改?答案是不可以。
如果想修改,如何修改?制定計劃,執行計劃
Kafka 默認的分區分配策略就是 Range + CooperativeSticky,所以不需要修改策略。
默認是Range,但是在經過一次升級之后,會自動變為CooperativeSticky。這個是官方給出的解釋。
默認的分配器是[RangeAssignor, CooperativeStickyAssignor],默認情況下將使用RangeAssignor,但允許通過一次滾動反彈升級到CooperativeStickyAssignor,該滾動反彈會將RangeAssignor從列表中刪除。
(4)觀看 3 個消費者分別消費哪些分區的數據。
假如消費情況和預想的不一樣:
1、集群是否健康,比如某些kafka進程沒啟動
2、發送數據的時候7個分區沒有使用完,因為它使用了粘性分區。如何讓它發送給7個分區呢,代碼中添加:
// 延遲一會會看到數據發往不同分區
Thread.sleep(20);
發現一個消費者消費了,5,6分區,一個消費了0,1,2分區,一個消費了3,4分區。
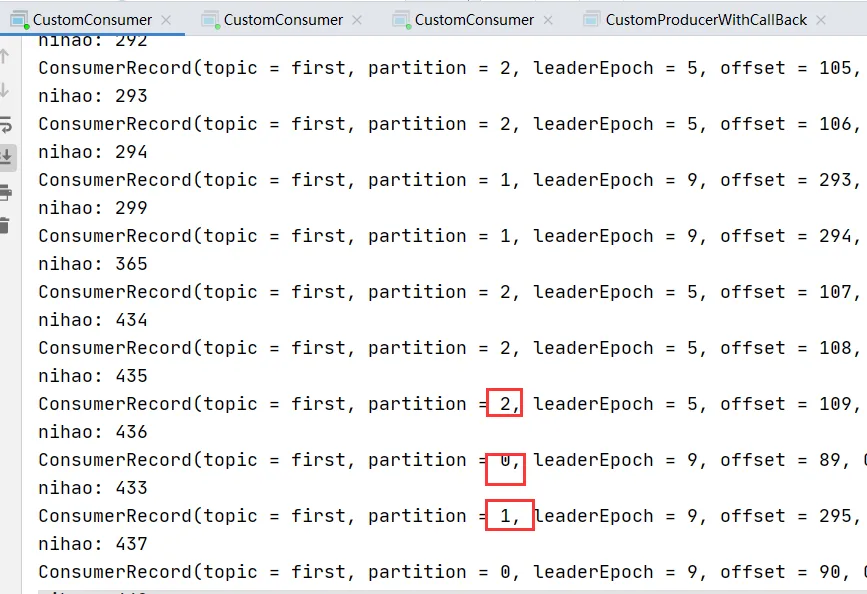
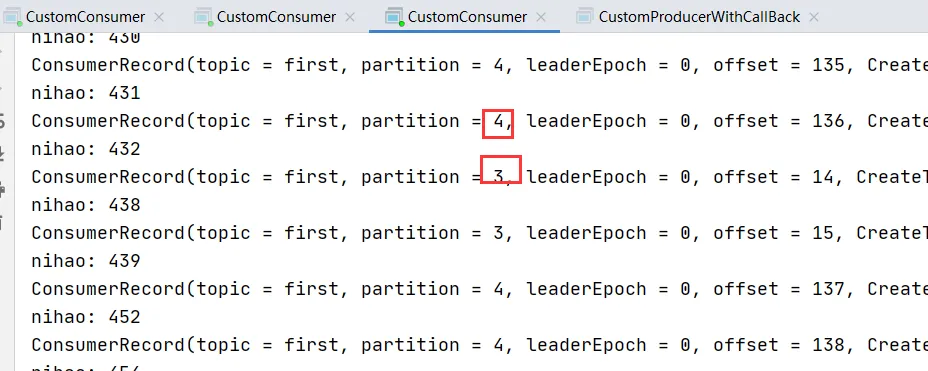
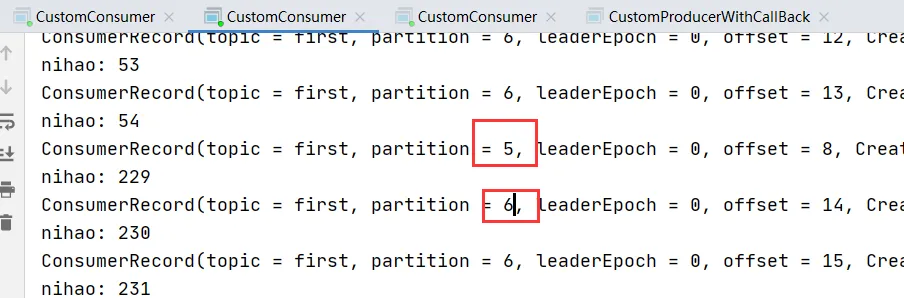
此時并沒有修改分區策略,原因是默認是Range.
3)Range 分區分配再平衡案例
(1)停止掉 0 號消費者,快速重新發送消息觀看結果(45s 以內,越快越好)。
1 號消費者:消費到 3、4 號分區數據。
2 號消費者:消費到 5、6 號分區數據。
0號的數據,沒人消費。
說明:0 號消費者掛掉后,消費者組需要按照超時時間 45s 來判斷它是否退出,所以需
要等待,時間到了 45s 后,判斷它真的退出就會把任務分配給其他 broker 執行。
(2)再次重新發送消息觀看結果(45s 以后)。
1 號消費者:消費到 0、1、2、3 號分區數據。
2 號消費者:消費到 4、5、6 號分區數據。
說明:消費者 0 已經被踢出消費者組,所以重新按照 range 方式分配。
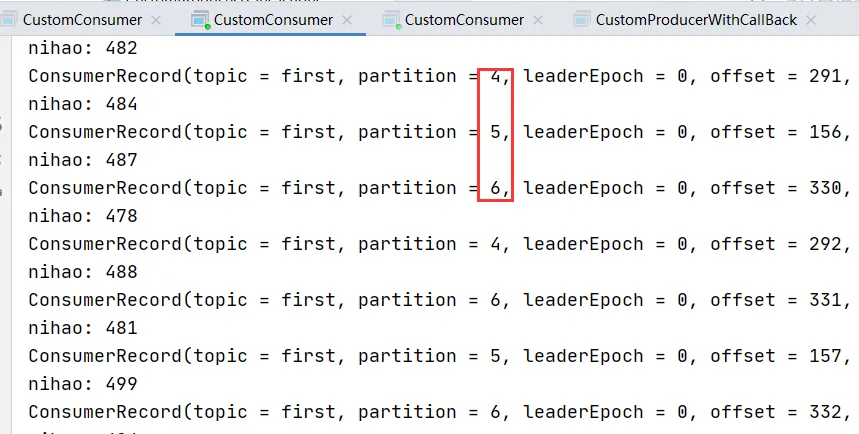
2.2 RoundRobin(輪詢) 以及再平衡
1)RoundRobin 分區策略原理
RoundRobin針對集群中所有Topic而言。
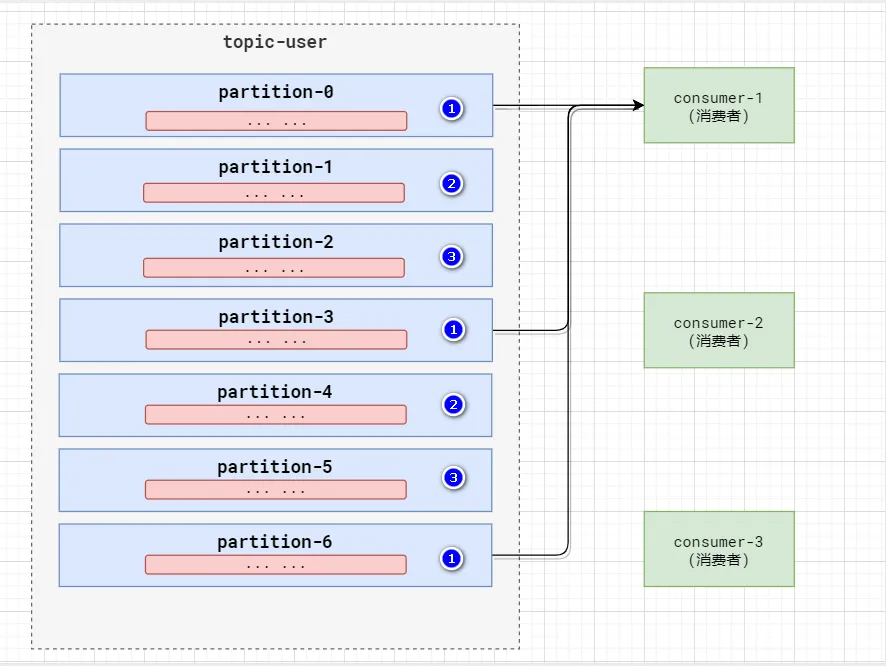
RoundRobin輪詢分區策略,是把所有的partition和所有的consumer都列出來,然后按照hashcode進行排序,最后
通過輪詢算法來分配partition給到各個消費者。
2)RoundRobin 分區分配策略案例
(1)依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三個消費者代 碼中修改分區分配策略為 RoundRobin。

輪詢的類的全路徑是:
org.apache.kafka.clients.consumer.RoundRobinAssignorA list of class names or class types, ordered by preference, of supported partition assignment strategies that the client will use to distribute partition ownership amongst consumer instances when group management is used. Available options are:org.apache.kafka.clients.consumer.RangeAssignor: Assigns partitions on a per-topic basis.
org.apache.kafka.clients.consumer.RoundRobinAssignor: Assigns partitions to consumers in a round-robin fashion.
org.apache.kafka.clients.consumer.StickyAssignor: Guarantees an assignment that is maximally balanced while preserving as many existing partition assignments as possible.
org.apache.kafka.clients.consumer.CooperativeStickyAssignor: Follows the same StickyAssignor logic, but allows for cooperative rebalancing.3)RoundRobin 分區分配再平衡案例
(1)停止掉 0 號消費者,快速重新發送消息觀看結果(45s 以內,越快越好)。
1 號消費者:消費到 2、5 號分區數據
2 號消費者:消費到 4、1 號分區數據
0 號消費者 以前對應的數據沒有人消費
說明:0 號消費者掛掉后,消費者組需要按照超時時間 45s 來判斷它是否退出,所以需要等待,時間到了 45s 后,判斷它真的退出就會把任務分配給其他 broker 執行。
(2)再次重新發送消息觀看結果(45s 以后)。
1 號消費者:消費到 0、2、4、6 號分區數據
2 號消費者:消費到 1、3、5 號分區數據
說明:消費者 0 已經被踢出消費者組,所以重新按照 RoundRobin 方式分配。
2.3 Sticky 以及再平衡
粘性分區定義:可以理解為分配的結果帶有“粘性的”。即在執行一次新的分配之前, 考慮上一次分配的結果,盡量少的調整分配的變動,可以節省大量的開銷。 粘性分區是 Kafka 從 0.11.x 版本開始引入這種分配策略,首先會盡量均衡的放置分區 到消費者上面,在出現同一消費者組內消費者出現問題的時候,會盡量保持原有分配的分區不變化。
比如分區有 0 1 2 3 4 5 6
消費者有 c1 c2 c3
c1 消費 3個 c2 消費2個 c3 消費2個分區
跟以前不一樣的是,c1 消費的3個分區是隨機的,不是按照 0 1 2 這樣的順序來的。
1)需求
設置主題為 first,7 個分區;準備 3 個消費者,采用粘性分區策略,并進行消費,觀察
消費分配情況。然后再停止其中一個消費者,再次觀察消費分配情況。
2)步驟
(1)修改分區分配策略為粘性。
注意:3 個消費者都應該注釋掉,之后重啟 3 個消費者,如果出現報錯,全部停止等
會再重啟,或者修改為全新的消費者組。
// 修改分區分配策略
ArrayList<String> startegys = new ArrayList<>();
startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, startegys);(2)使用同樣的生產者發送 500 條消息。
可以看到會盡量保持分區的個數近似劃分分區。
3)Sticky 分區分配再平衡案例
(1)停止掉 0 號消費者,快速重新發送消息觀看結果(45s 以內,越快越好)。
1 號消費者:消費到 2、5、3 號分區數據。
2 號消費者:消費到 4、6 號分區數據。
0 號消費者的任務沒人頂替它消費
說明:0 號消費者掛掉后,消費者組需要按照超時時間 45s 來判斷它是否退出,所以需
要等待,時間到了 45s 后,判斷它真的退出就會把任務分配給其他 broker 執行。
(2)再次重新發送消息觀看結果(45s 以后)。
1 號消費者:消費到 2、3、5 號分區數據。
2 號消費者:消費到 0、1、4、6 號分區數據。
說明:消費者 0 已經被踢出消費者組,所以重新按照粘性方式分配。
2.4 CooperativeSticky 的解釋【新的kafka中剛添加的策略】
在消費過程中,會根據消費的偏移量情況進行重新再平衡,也就是粘性分區,運行過程中還會根據消費的實際情況重新分配消費者,直到平衡為止。
好處是:負載均衡,不好的地方是:多次平衡浪費性能。
動態平衡,在消費過程中,實施再平衡,而不是定下來,等某個消費者退出再平衡。



)

,背包問題總結)
)







![[機器學習]03-基于核密度估計(KDE)的鳶尾花數據集分類](http://pic.xiahunao.cn/[機器學習]03-基于核密度估計(KDE)的鳶尾花數據集分類)




