今日凌晨,OpenAI宣布開源兩款全新大模型——GPT-oss-120B(1168億參數)與GPT-oss-20B(209億參數),成為全球首個支持商業化應用的開放權重推理模型。該模型專為AI智能體(Agent)設計,集成函數調用、網絡搜索、Python代碼執行等功能,旨在降低開發者構建安全、高性能AI應用的門檻。
技術突破:混合專家架構與超長上下文處理
GPT-oss采用創新的混合專家(MoE)架構,通過動態分配計算資源提升效率:
- GPT-oss-120B:36層結構,每token前向傳遞激活51億參數,配備128個專家模塊;
- GPT-oss-20B:24層結構,每token激活36億參數,專家模塊縮減至32個。
模型注意力機制融合GPT-3的帶狀窗口與全密集模式,帶寬128 token,結合旋轉位置嵌入(RoPE)和YaRN技術,將上下文長度擴展至131072 token,顯著提升長文本處理能力。此外,根均方歸一化(RMSNorm)與門控SwiGLU激活函數進一步優化了非線性表達能力。
性能媲美閉源旗艦,硬件需求差異顯著
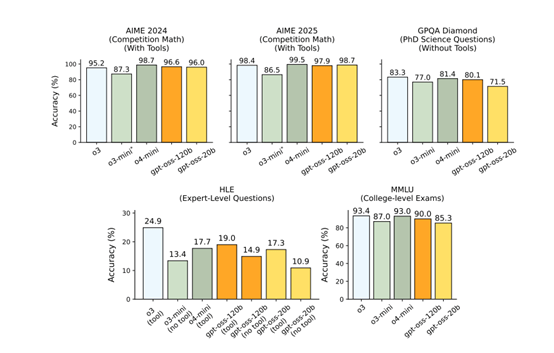
OpenAI公布的數據顯示,GPT-oss在多項基準測試中表現亮眼:
- 數學推理:GPT-oss-120B在AIME(美國數學邀請賽)測試中以96.6%準確率接近o4-mini的98.7%;
- 編程能力:Codeforces競賽問題測試中,120B模型Elo評分達2622,略低于o4-mini的2719;
- 多語言支持:法語、德語、西班牙語任務準確率分別達84.6%、83.0%、85.9%。
硬件需求方面,120B版本需80GB GPU顯存,而20B版本僅需16GB GPU即可運行。OpenAI宣稱20B模型可適配高端手機,但這一說法引發爭議——部分開發者指出,16GB顯存要求遠超當前主流移動設備配置。
開源戰略升級:數十億美元研發免費開放
OpenAI聯合創始人兼CEO薩姆·阿爾特曼(Sam Altman)在長文中強調,GPT-oss是“首款最先進、可商用的開放權重推理模型”,其意義在于讓全球開發者“直接控制和修改AI,保障隱私與靈活性”。他同時表示,模型已通過內部安全基準測試,尤其在生物安全領域加強了風險管控。
行業分析認為,此次開源標志著OpenAI戰略轉向:在面臨市場競爭壓力下,通過釋放小型化、高性能模型鞏固技術領導力。盡管阿爾特曼將此舉包裝為“賦能人類”,但外界普遍認為,這是對Meta、馬斯克xAI等開源競品的直接回應。
業界反響:開源運動迎來轉折點
GP:T-oss的發布引發熱議
- 支持者認為,將媲美o4-mini的模型開源等同于“將前沿技術民主化”,可能加速AI應用創新;
- 質疑者則指出,20B模型的手機適配性存疑,且OpenAI仍未公開Grok系列開源計劃,或存在“選擇性開放”嫌疑;
- 競品對比:有開發者調侃稱,“馬斯克承諾的Grok-3開源仍未兌現,OpenAI已用GPT-oss改寫行業規則”。
OpenAI重申其使命:“確保AGI造福全人類”。阿爾特曼表示,GPT-oss的發布旨在建立“以民主價值觀為基礎的開放AI技術棧”,通過免費授權推動全球協作。隨著模型代碼與權重陸續公開,一場圍繞“開源vs閉源”的AI競賽正進入新階段。
注:本文基于OpenAI官方發布信息及公開測試數據整理,手機運行可行性需等待實測驗證。






:AI+Apache ECharts:生成各種專業圖表)
下)


)
)

)




—— 程序的“數據基石”)
