
標題:<LighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures>
論文:https://arxiv.org/pdf/2507.06109
來源:南京大學;復旦大學;華為諾亞實驗室
文章目錄
- 摘要
- 一、前言
- 二、相關工作
- 2.1 多視角隨意捕捉動作 (Casual Multi-view Capture Motion)
- 2.1 新視角合成
- 2.3 幾何對齊的3DGS
- 2.4 優化相機位姿與輻射場
- 三、Preliminary:3DGS
- 四、Overview
- 五、Plane Scaffold Assembly
- 六、平面感知的穩定優化
- 七、幾何和光度校正
- 實驗
- 1.數據集
- 2.實施細節
- 3.對比方法
- 4.消融實驗
- 5.下游應用
摘要
??三維高斯潑濺(3DGS)技術的最新進展,已能在室內場景中實現具有驚艷畫質的實時新視角合成(NVS)。然而,要實現高保真渲染,需要精心拍攝覆蓋整個場景的圖像,這限制了普通用戶的可及性。我們致力于開發一種基于3DGS的實用型NVS框架,僅需使用手持設備(如移動終端)進行簡單的全景式運動拍攝。雖然這種以旋轉為主、窄基線的拍攝方式(rotation-dominant motion and narrow baseline)便捷,卻給相機位姿估計和三維點云重建帶來挑戰——尤其在缺乏紋理的室內環境中。受全景視圖的 lighthouse-like sweeping motion,LighthouseGS利用移動設備相機位姿和單目深度估計等粗略幾何先驗,并充分結合室內環境中常見的平面結構特征。我們提出了一種名為"plane scaffold assembly"的新型初始化方法,可在這些結構上生成一致的三維點云,隨后通過穩定剪枝策略來提升幾何優化穩定性。針對移動設備常見的運動漂移和自動曝光問題,本研究還引入了幾何與光度校正方案。通過在真實采集與合成的室內場景中進行測試,LighthouseGS實現了超越現有技術的照片級真實感渲染,展現了在全景視圖合成與物體布局方面的應用潛力。

一、前言
?? 照片級真實感新視角合成(NVS)技術對于將現實世界體驗引入虛擬環境至關重要,它能實現沉浸式且真實的交互。這項技術在室內場景中尤其珍貴——我們日常生活中的大部分時間都在室內度過,它讓我們能夠突破物理空間限制,分享栩栩如生的生活體驗。近期,神經渲染技術在NVS領域取得重大進展。神經輻射場(NeRF)[Mildenhall等人,2020]展示了照片級真實感的新視角合成能力,而3D高斯潑濺(3DGS)[Kerbl等人,2023]則發展成為一個強大的框架,既能實現實時渲染又能保持高保真度的視角合成。然而,要獲得高質量渲染效果,仍需拍攝覆蓋整個場景的數百張圖像,這對普通用戶(即非專業人士)在室內環境中使用NVS技術構成了挑戰。
??鑒于這些限制條件,并考慮到用戶友好型采集方法的迫切需求,我們的研究聚焦于一種創新范式——利用自然直觀的單手持移動設備拍攝方式,通過全景式運動讓用戶采集周圍環境[Sweeney等人2019;Ventura2016]。例如,當人們拍攝感興趣的場景時(如蘋果手機的全景模式1),通常會半伸展手臂旋轉相機。這種以旋轉為主導的運動方式不僅能讓用戶輕松采集室內場景,還能提供沉浸式探索體驗,這對房間導覽、室內場景設計等增強現實/虛擬現實應用大有裨益。
??在本研究中,我們探索了一種從室內場景的全景式拍攝中生成逼真神經視圖合成(NVS)的方法,重點在于提升非專業用戶的使用便捷性。與以往依賴由高端相機組成的多相機陣列系統來捕捉360度場景的研究[Lin等人2020;Turki等人2024;Xu等人2023]不同,我們僅使用單個手持相機。然而,全景式拍攝為NVS帶來了額外的技術挑戰。具體而言,窄基線連續拍攝會導致相機姿態估計不準確和三維點云不可靠。這些問題在室內場景的紋理缺失區域會進一步加劇——這些區域因缺乏顯著特征且運動視差有限,使得精確三維重建變得復雜。最終,這些誤差會嚴重降低神經渲染的質量。為解決這些問題,我們利用現成或可估算的粗略幾何先驗信息:相機位姿可輕松從移動設備中提取,而單目深度信息則能通過預訓練網絡[COLMAP-Free 3D Gaussian Splatting CVPR 2024]以合理精度進行估算。
??LighthouseGS 專為通過單手持相機實現室內場景全景式捕捉而設計。該方案利用粗略幾何先驗知識,充分挖掘室內環境(通常包含平面區域)的固有結構特征。具體實現上,我們 通過移動設備(如搭載ARKit的iOS設備)進行全景式運動拍攝,并獲取相機位姿。隨后對采集圖像進行深度和法線信息估計。需要特別說明的是,這些粗略幾何先驗(包括相機位姿和深度/法線信息)可能存在誤差:依賴IMU傳感器進行位姿估計的移動設備易受運動漂移影響,而單目深度估計方法則存在尺度模糊問題。然而,這些幾何先驗信息可與室內場景的平面特征結合使用,從而獲得更精確的估算結果。
??鑒于粗略的幾何先驗信息,LighthouseGS通過將三維高斯分布與室內場景的結構特征相結合進行初始化和優化。我們首先提出了一種 初始化方案——planar scaffold assembly,利用室內場景的平面結構來調整未對齊的深度數據,從而強化全局與局部一致性。不同于傳統基于圖像的整體對齊方式,LighthouseGS采用室內場景中占主導地位的plane-wise 對齊策略,既提升了對齊精度又保留了局部細節。這種方案提供了可靠的初始值,使三維高斯分布能與場景幾何精確對齊。
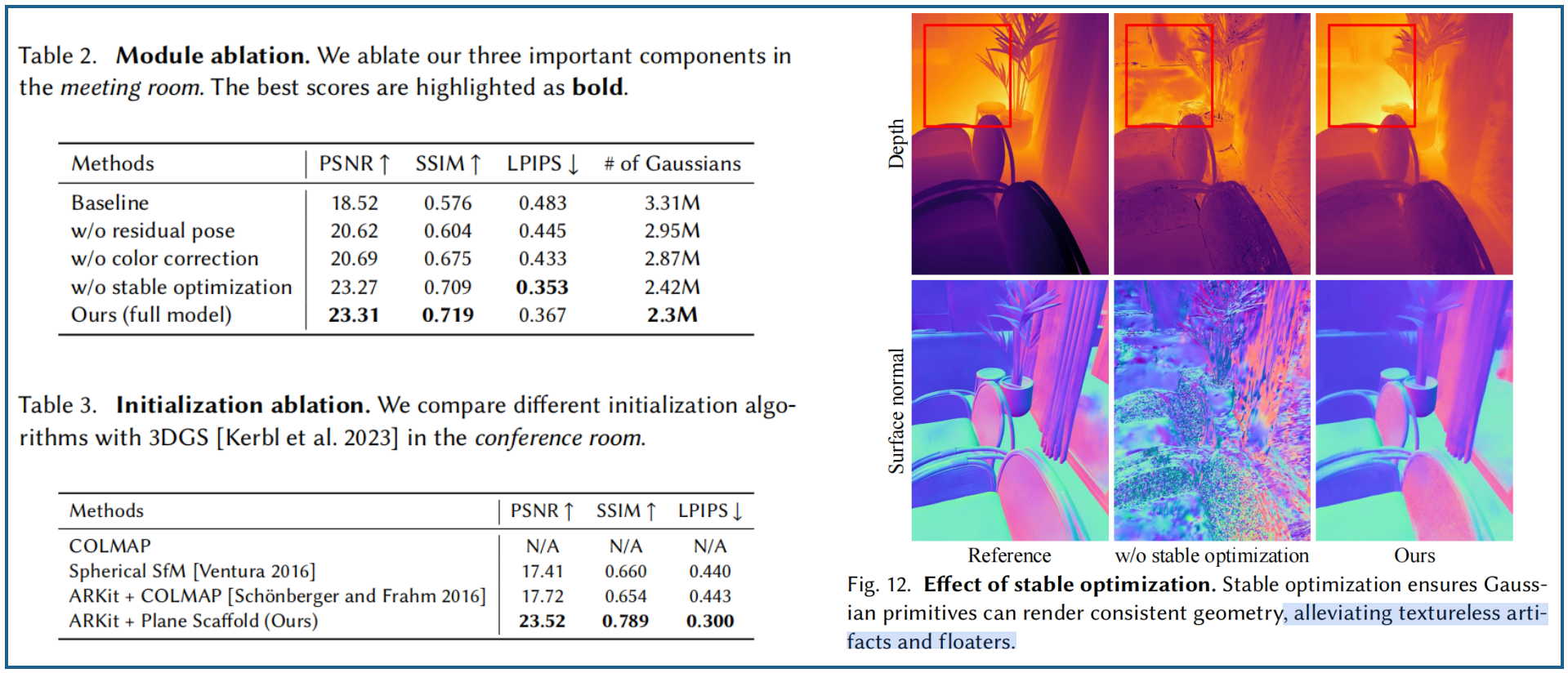
此外,我們提出了一種幾何感知的剪枝策略以提升優化穩定性。3DGS的稠密化,在非紋理區域頻繁出現的過大尺度3D高斯元素——即便它們能準確表征場景——也會被移除,這導致這些區域產生嚴重偽影。為解決此問題,我們保留了高置信度的3D高斯元素,以實現場景幾何與視覺特征的穩定更新。
值得一提的是,LighthouseGS通過光度誤差校正了初始位姿與色彩不一致性問題,有效克服了室內全景采集的挑戰,更高保真渲染新視角。
??為訓練和驗證提出的LighthouseGS框架,我們新收集并生成了采用全景式運動捕捉的真實世界與合成數據集。該數據集涵蓋多樣室內場景,包含自動曝光圖像及每個場景對應的相機位姿。在我們由5個真實場景和5個合成場景構成的數據集上,實驗證明了LighthouseGS框架的有效性。該框架展現出照片級真實感的渲染質量,其表現優于既往神經渲染方法(見圖1)。此外,我們還基于該框架開發了兩項應用:全景視圖合成與物體布局(object placement)。
二、相關工作
2.1 多視角隨意捕捉動作 (Casual Multi-view Capture Motion)
2.1 新視角合成
2.3 幾何對齊的3DGS
2.4 優化相機位姿與輻射場
三、Preliminary:3DGS
??略。


?? 挑戰 。由于運動和室內場景的固有問題,通過全景式拍攝來擬合 3DGS 以實現高保真視圖合成仍具挑戰性。從運動角度來看,全景式運動通常無法正確運行COLMAP算法[估計相機位姿和稀疏點云,2016],原始3DGS論文所述,初始化質量會顯著影響渲染效果。從環境角度來看,室內場景存在同質化區域,且由于自然光和各類間接光源的影響,移動設備的曝光值和白平衡在每次拍攝時都會發生變化。室內場景中缺乏紋理的區域可能通過錯誤密集化導致相機近場漂浮物,因為這些區域僅依賴渲染損失而忽略了幾何特征。此外,現有自適應控制策略依賴于需要敏感調整的啟發式超參數。由于光照的自然過渡,曝光變化會導致多視角間顏色不一致,并難以在新視角中合成未見的顏色。
四、Overview
??全景式運動是普通用戶輕松捕捉周圍環境的常見便捷方式。在這種拍攝模式下,用戶通常以半伸展手臂旋轉相機,使相機軌跡近似于虛擬球面。通過iOS設備的ARKit等內置功能或商業智能手機應用[Abou-Chakra 2023],可獲取全景式運動的連續圖像序列,同時提供相機位姿數據(可能存在誤差)作為初始值使用。輸入數據:圖像序列{ItI_tIt? }和初始位姿{ΠtΠ_tΠt?}(t∈[1,T]t ∈ [1,T]t∈[1,T],TTT 為場景總幀數)。
??LighthouseGS 能夠利用室內固有特征——結構分明但缺乏紋理的平面區域,通過三個步驟的流程:,平面支架裝配,。 1) 預處理階段 ,使用預訓練模型生成輸入圖像ItI_tIt? 的單目深度圖DtD_tDt?和法線貼圖NtN_tNt?( 具體采用CVPR 2024的 [COLMAP-Free 3D Gaussian Splatting,2024]和[Rethinking Inductive Biases for Surface Normal Estimation] )。2) plane scaffold assembly步驟 ,通過 plane primitives 對單目深度估計(即3D點)進行序列對齊,從而確保全局與局部一致性。該步驟構建了一個由一組對齊的三維點及其對應法線組成的 plane scaffold,數據源自平面基元。基于此,初始化3DGS以對齊室內場景幾何,特別是在無紋理區域。3) 結合幾何與光度校正的優化(圖2) ,優化3DGS,同步執行幾何與光度校正,增強室內場景無紋理區域的優化穩定性。通過residual pose refinement 來解決輸入相機位姿的運動漂移問題,并采用可學習的 tone mapping scheme 來改善自動曝光導致的色彩不一致性。這一流程使我們能夠從隨意拍攝的圖像中實現照片級真實感的沉浸式渲染,無需依賴高端相機或SFM技術。

五、Plane Scaffold Assembly
??該對齊方案通過利用單目深度估計和ARKit位姿等粗略幾何先驗中的平面結構, 構建全局對齊的密集三維點云(如圖3 )。為解決單目深度圖的尺度模糊性,通過優化單目深度圖的視角尺度和位移參數來適配全局點云。然而這種方法無法處理局部錯位問題,導致高斯函數初始化不準確,進而產生三維幾何合成中的視覺偽影。例如,僅采用全局對齊方案時會在物體層面暴露錯位現象,如圖4所示。
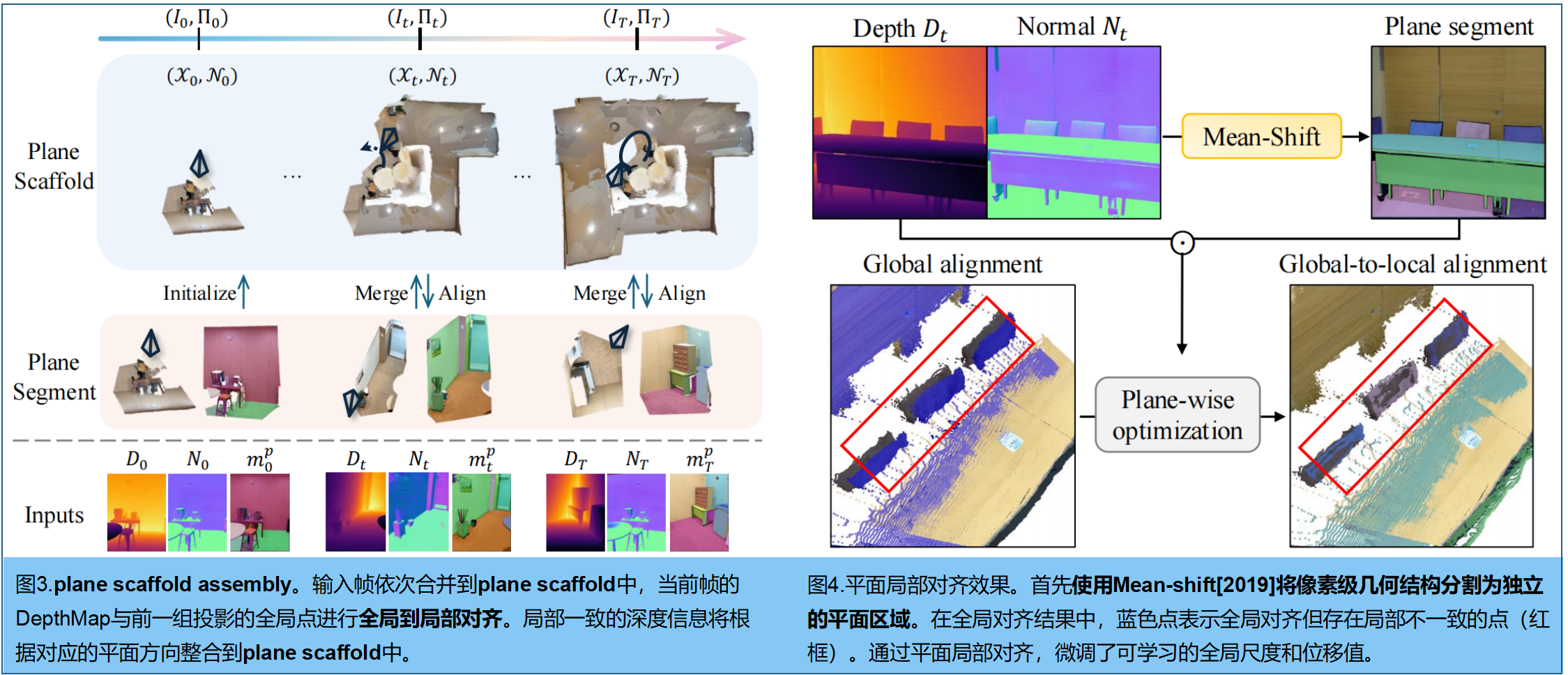
?? 兩階段的Plane Scaffold Assembly方案 :第一階段進行全局圖像對齊,第二階段則基于平面信息通過局部平面對齊來優化幾何一致性。我們依次對連續深度圖像進行全局到局部的對齊處理,最終構建出由全局到局部對齊點集XTX_TXT?和對應平面信息NTN_TNT?(即表面法線)組成的Plane Scaffold SSS。作為參考尺度,我們通過反向投影從首幀深度圖D0D_0D0?中初始化一組對齊的3D點集X0X_0X0?。
?? Image-wise 全局對齊 。給定先前的全局點Xt?1X_{t?1}Xt?1?,新深度圖像DtD_tDt?,圖像級全局對齊的目標是預測一個仿射變換,將給定的深度圖像調整以匹配全局點。值得注意的是,直接在三維空間中將深度圖像與全局點對齊并非易事,因為這需要點對點的對應關系。為此,我們**首先將全局點投影到當前幀中,然后通過仿射變換的簡單可學習系數在二維空間內完成對齊。**通過仿射變換調整深度圖:Dˉt=αtDt+βt\bar{D}_t=α_tD_t+β_tDˉt?=αt?Dt?+βt?,其中αt,βtα_t,β_tαt?,βt? 是可學習的視角尺度和位移參數,由梯度下降法優化,以最小化當前深度與投影全局點之間的誤差:

MMM是 (單目深度Dˉt\bar{D}tDˉt與投影全局點之間) 重疊區域的mask;⊙是逐元素乘法;π(;)\pi(;)π(;)表示相機投影函數。雖然這種基于圖像的整體全局對齊方法能帶來整體性能提升,但 僅依賴單一尺度和位移參數來調整室內場景中不同物體的三維空間,容易導致局部不一致性。為此,我們以全局對齊的尺度和位移參數作為初始值,隨后針對每個局部平面區域進行參數優化。
??
?? Plane-wise 的局部對齊。 研究發現,平面表示能有效呈現室內場景的緊湊結構,尤其適用于墻面、天花板等大面積均質區域。為提取平面區域,基于預處理的深度圖DTD_TDT?和表面法線圖NtN_tNt?, 采用Mean shift聚類算法[2019],將像素級深度數據分割為若干平面,每個平面以segment mask mtp∈RH×Wm_t^p∈R^{H×W}mtp?∈RH×W的二值化掩膜形式呈現。隨后為每個平面ppp定義縮放位移參數(γtp,δtp)(γ_t^p,δ_t^p)(γtp?,δtp?),初始值取自全局參數 (αp,βp)(α_p,β_p)(αp?,βp?)。各平面的縮放深度Dˉtp\bar{D}_t^pDˉtp?通過以下方式計算:

這些局部平面區域,在最小化(每個平面 segment與重疊像素內的投影深度的)投影損失的同時,優化如下:

??最后,對調整后的 平面 segment進行反投影,獲得世界空間中三維點。這些點將與全局點Xt?1X_{t-1}Xt?1?合并(重疊像素除外):

π?1\pi^{?1}π?1(;)利用相機位姿,將(全局對齊的)平面反投影到世界空間。得益于局部平面對齊特性,三維點在不同物體或平面區域之間實現了精準對齊(圖4紅框)。
??最后,生成具有平面信息的全局-局部對齊點集,稱為 plane scaffold S=(XT,NT)S=(X_T,N_T)S=(XT?,NT?)。該方法為全景式運動場景中3D幾何建模(3DGS)初始化,估算出一組基于平面引導的三維點集(COLMAP失敗)。通過降采樣處理該平面支架,以保持點集數量的合理性。
六、平面感知的穩定優化
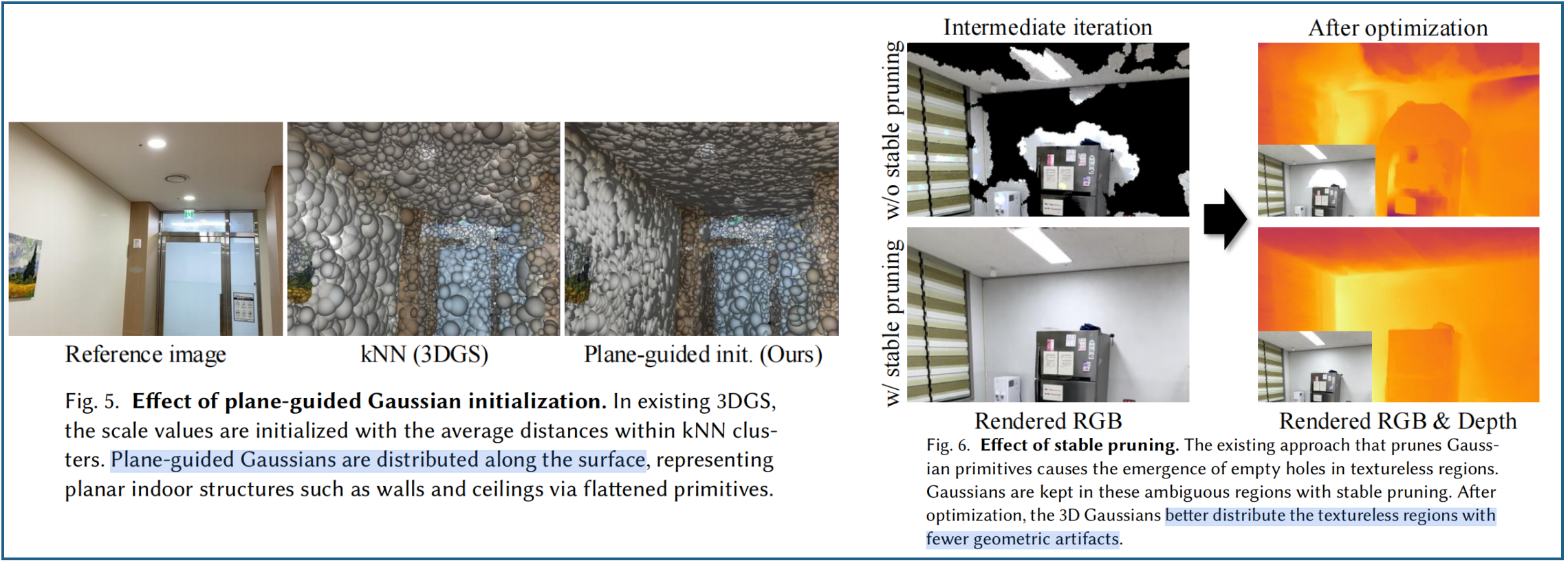
?? 平面引導的初始化 。3DGS根據全局三維點的位置參數,生成一組高斯分布,每個gs的初始尺度由其最近鄰點的平均距離決定,從而形成各向同性的形狀。這些各向同性高斯分布大致填充三維空間而不產生空隙,但無法準確反映室內場景中廣泛存在的平面結構特征。因此,我們通過最小化(最接近表面法線的)軸的尺度,來壓縮初始化的GS基元。將最小值作為尺度參數后,三維高斯分布被初始化為沿對應表面平面展平的薄層結構。圖5展示了現有3DGS與平面引導的GS初始化方法的對比效果。
?? 穩定剪枝 。3DGS的剪枝方案,通過移除過大或透明的高斯分布,常在優化過程中產生大面積空洞(見圖6)。值得注意的是,這類過大高斯分布往往出現在非紋理區域,而傳統剪枝策略通常會將其剔除。由于這些空洞會被不當填充,導致優化過程中的幾何偽影問題,從而影響算法的穩定性。雖然通過自適應密度控制(ADC)分裂或克隆三維高斯函數可以填補大孔洞,但由于ADC僅依賴于從渲染損失中得到的view-space gradients,因此會出現靠近相機的 floater。
??穩定修剪方案,利用不透明度值,來評估3DGS的可靠性,在無紋理區域保留可靠的三維高斯分布(因為這些分布是從表面對齊平面的plane scaffold 中初始化生成)。而且無紋理區域不需要精細細節,可以使用更大的高斯分布來表示。具體而言,首先在圖像的重疊區域內收集大尺寸GS基元,作為修剪候選對象。然后保留不透明度值高于0.5閾值的高置信度高斯分布,能在無紋理區域生成平滑幾何結構且無漂浮物(見圖6)。
?? 平面引導的正則化。 雖然三維高斯函數的初始化采用了本文提出的plane scaffold assembly,但僅依賴渲染損失值并不能保證其在優化過程中的幾何精度。因此,我們通過計算估計的粗略幾何先驗與對應渲染值之間的損失函數,引入額外的損失函數來實現三維高斯函數與場景幾何結構的精準對齊。
??1.角度損失。約束GS法向量與表面保持對齊:

??其中N^\hat{N}N^表示渲染后的法線貼圖,而NNN則是預訓練網絡生成的偽真實法線貼圖。根據[Gaussianpro]的研究方法,通過將公式(2)中的每個高斯顏色cic_ici?替換為對應的法線nin_ini?來計算t時刻的N^\hat{N}N^,其中nin_ini?是具有最小尺度值的旋轉軸。
??2.扁平化損失。根據NeuSG[2023],對每個高斯函數的最小尺度進行正則化處理,使其沿表面扁平化:

sis_isi?表示世界空間中三維高斯分布各軸的scale值。
??3.法線平滑損失。此外,由于3DGS采用非結構化形式,渲染光滑幾何體時常常遇到困難。為解決,我們在渲染后的法線中應用全變差項(Rudin等人,1992年),以最小化相鄰法線之間的差異(LLL是像素數):

??4.深度-法線一致性損失。我們通過正則化渲染后的深度圖,使其在局部區域保持一致性。非結構化的三維高斯函數難以表現平滑表面,容易導致三維空間中的不連續性。我們利用先驗法線圖,來引導渲染深度圖的局部平滑度。首先利用相機內參,將渲染后的深度圖D^\hat{D}D^轉換為逐像素的3D location map。 該損失通過確保三維位置的水平和垂直梯度與對應法線方向正交,從而強制實現表面幾何的平滑性 ,具體如下:

七、幾何和光度校正
??由于設備便攜性設計,該框架仍存在運動漂移、自動曝光/白平衡等固有缺陷。針對這些問題,我們提出了兩種解決方案:殘差位姿微調(Residual Pose refinement)與光度校正(photometric correction.)技術。
??殘差位姿微調。受PoRF算法(2024)啟發,將每幀的殘差位姿參數初始化為單位旋轉矩陣(四元數形式)和零位移向量。在優化3DGS過程中,四元數和位移向量會被轉換為殘差位姿 ΔΠ∈SE(3)ΔΠ∈SE(3)ΔΠ∈SE(3)。調整后的位姿,通過殘差pose與初始pose相乘來實現優化,同時避免直接調整初始粗略pose ΠΠΠ(內參固定):

由于圖像用調整后的pose渲染,通過可微分渲染器的反向傳播梯度,來更新殘差pose。減少因運動漂移導致的圖像偽影,特別是在后續序列中漂移誤差逐漸累積的情況下(見圖7)。
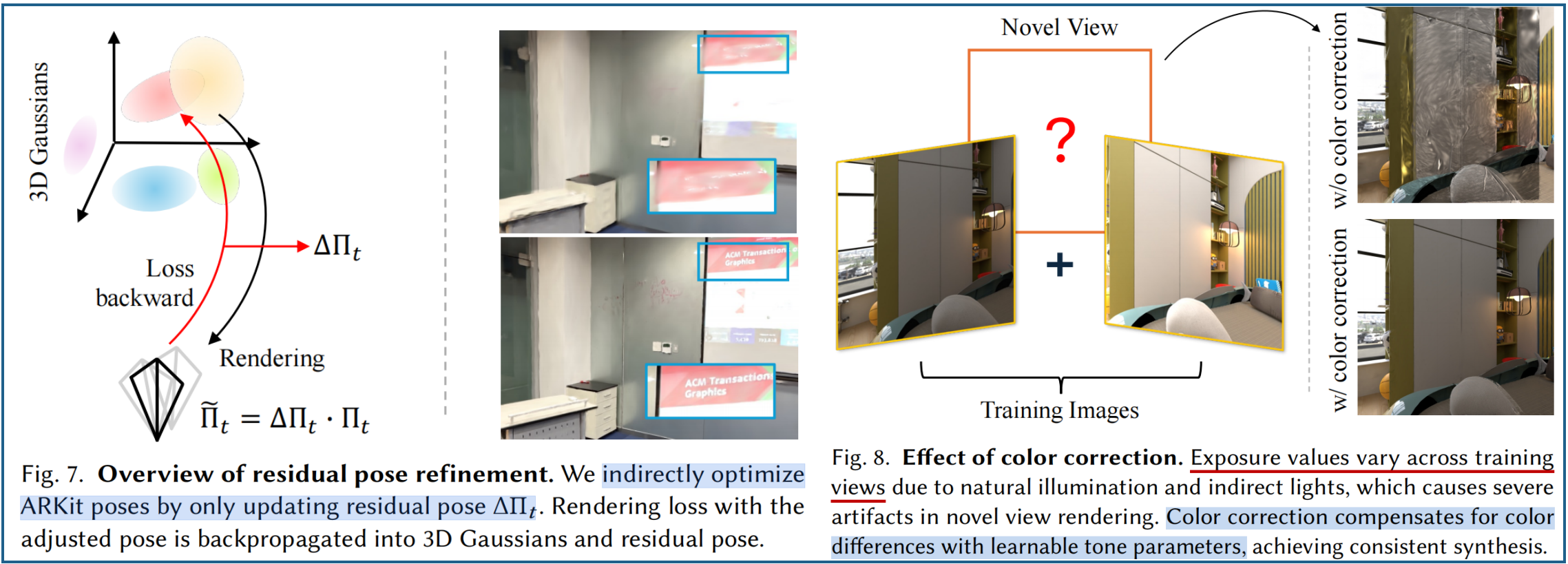
??色彩校正。針對不同視角間顏色、曝光變化問題,采用基于可學習白平衡參數 w∈R3w∈R^3w∈R3和亮度參數b∈R3b∈R^3b∈R3的通道級參數化色彩轉換策略進行校正。在計算渲染損失前,可將渲染圖像I^t\hat{I}_tI^t?轉換為經過色彩校正的圖像 I~t\tilde{I}_tI~t?。

可學習的系數通過可微分光柵化技術進行更新,將梯度反向傳播至這些參數。效果如圖8。
??LighthouseGS損失:


λ1λ_1λ1?和λD?SSIλ_{D?SSI}λD?SSI?設為0.8和0.2。
??幾何損失LgeoL_{geo}Lgeo?通對渲染后的幾何體進行正則化處理,使其三維高斯分布沿表面排列:

λnormλ_{norm}λnorm?和λd2nλ_{d2n}λd2n?分別設置為0.05和0.2。前三個損失項用于約束渲染后的法線圖,而深度-法線一致性損失則用于約束渲染后的深度值。
實驗
1.數據集
??真實數據。Nerfcapture軟件 可保存iPhone ARKit拍攝的多張圖像及其對應參數。在拍攝目標區域時,用戶需保持雙臂自然伸展并旋轉設備。這些圖像幾乎覆蓋了運動中心點的整個空間范圍。這種自然運動方式并不嚴格遵循原點球面運動理論[文圖拉2016],而全景式運動模式則代表了一種更實用且不受限的方法。我們的數據集包含五種不同室內環境:陽臺、更衣室、食品儲藏室、餐廳和會議室。每個場景最多采集100幀圖像,分辨率為1920×1440像素。
??合成場景。Blender軟件[,支持基于物理的渲染技術。根據場景規模不同,我們在固定全景運動中心周圍20或30厘米半徑范圍內生成合成圖像。基于ARKit跟蹤系統的統計分析[Kim等人2022],我們進一步在真實相機位姿中添加漂移噪聲以模擬位姿誤差。本數據集包含五個合成室內場景:游戲室、臥室、主臥、客廳和工作室。每個場景均包含100張自動曝光圖像及其對應的相機位姿,分辨率均為1024×1024像素
2.實施細節
??本文采用絕對梯度累積算法的AbsGS[葉等人,2024年],該方法通過避免高斯函數過度重建時的梯度沖突,更精準地呈現高保真紋理特征。優化過程共進行3萬次迭代,前1.5萬次迭代每100步進行一次致密化處理。針對真實場景和合成場景,我們分別設置0.0008和0.0004作為稠密化梯度閾值。高斯參數采用Adam優化器[金馬與巴,2015年],幾何校正和光度校正的可學習系數也使用該優化器。所有實驗均在單塊RTX 4090顯卡上完成。
??首先凍結訓練好的三維高斯模型,在20000次迭代過程中持續優化測試視角的相機位姿和色調映射參數,以評估未見過的拍攝角度。隨后測量指標量化:峰值信噪比(PSNR)、結構相似性指數(SSIM)以及局部圖像偽影抑制性能(LPIPS)。
3.對比方法
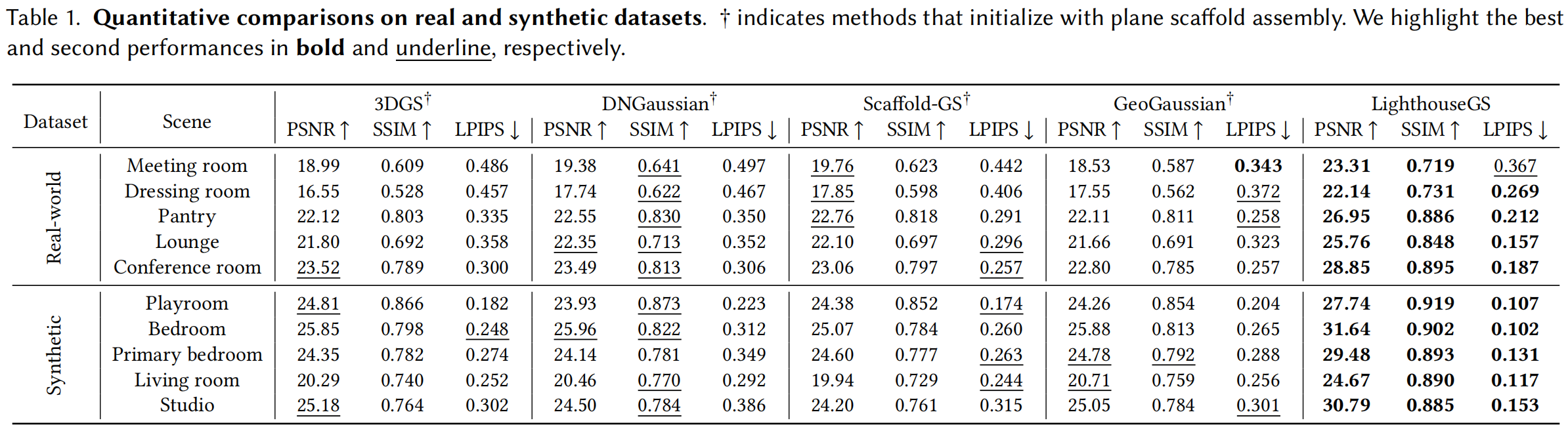
??3DGS 、DNGaussian[2024]、Scaffold-GS[2024]和GeoGaussian[2025]。
DNGaussian是一種單目深度正則化方法,通過將高斯位置與場景幾何結構對齊,并通過對局部深度塊進行歸一化處理來優化細節。我們基于相同單目深度數據重新實現了該方法。Scaffold-GS能夠通過動態預測高斯參數(基于錨點和視角),有效呈現具有視圖依賴效應或偽影的場景。GeoGaussian將三維高斯初始化為與表面法線對齊的細長橢球體,并在室內場景中優化相鄰橢球體保持共面狀態。
??現有所有方法都依賴COLMAP,然而在實際場景中,由于需要實現全景式運動,經常失敗。LighthouseGS采用plane scaffold assembly的3D點云,以及ARKit相機位姿,作為基準初始化,定量對比見表1(添加?符號以區分采用相同初始化方案)
??定性對比:LighthouseGS對輸入相機位姿和自動曝光圖像的誤差具有魯棒性(見紅色方框),物體的形狀與細節得以清晰重建,完全消除了模糊偽影(如試衣間中拖鞋的細節); 與容易在不同,LigthouseGS在處理這類無紋理區域產生的漂浮感時表現更優(見藍色方框):在食品儲藏室的天花板和墻面區域,過度平滑的表面和大量斑點VS紋理細節增強的規整表面。
真實數據集結果:



??
??
4.消融實驗
??COLMAP是常規的3DGS初始化方法,但在全景式運動場景中常無法準確估計三維點和相機位姿。為解決這一問題,我們嘗試使用ARKit位姿運行COLMAP進行點云三角測量(標記為ARKit + COLMAP)。盡管利用了相機位姿作為先驗信息,但COLMAP生成的點云精度不足且分布極稀疏,導致性能受限。我們還提出了球面立體光測量(Spherical SfM)[Ventura,2016年],這是一種專為類似全景式運動的球面運動設計的特殊SfM流程。然而,由于該方法存在必須將相機置于球面上才能成功運行的嚴格約束,其性能仍顯不足。相比之下,plane scaffold assembly在定性和定量方面均展現出穩健性能(見圖13)。通過將plane scaffold assembly產生的密集三維點與表面精確對齊,可以觀察到場景幾何結構得到良好呈現且無幾何偽影,尤其在非紋理區域表現尤為突出。

??
??
5.下游應用

??









數據庫計算容量評估)
網絡爬蟲)



訓練的教師強制(Teacher Forcing)方法)


)


