調用流程圖:------------------------------以下是代碼------------------------------------------------run.py:
import time
# 導入time模塊,用于記錄數據加載和訓練時間import torch
# 導入PyTorch框架,用于構建和訓練深度學習模型import numpy as np
# 導入NumPy庫,用于進行數值計算和數組操作from train_eval import train, init_network
# 從train_eval.py文件中導入train函數(訓練模型)和init_network函數(初始化網絡參數)from importlib import import_module
# 從importlib中導入import_module函數,用于動態導入模塊import argparse
# 導入argparse模塊,用于解析命令行參數from tensorboardX import SummaryWriter
# 導入tensorboardX的SummaryWriter類,用于可視化訓練過程中的指標(如loss、accuracy等)# 創建一個ArgumentParser對象,描述為“Chinese Text Classification”
parser = argparse.ArgumentParser(description='Chinese Text Classification')# 添加--model參數,類型為字符串,必須輸入,幫助信息提示選擇TextCNN、TextRNN等模型
parser.add_argument('--model', type=str, required=True, help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')# 添加--embedding參數,默認值為'pre_trained',類型為字符串,幫助信息提示選擇預訓練或隨機詞向量
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')# 添加--word參數,默認False,類型為布爾值,幫助信息提示是否使用詞粒度(True)還是字符粒度(False)
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')# 解析命令行傳入的參數,并保存在args變量中
args = parser.parse_args()if __name__ == '__main__':# 程序入口,表示這是主程序執行部分# 設置使用的數據集名稱為'THUCNews'dataset = 'THUCNews' # 數據集# 搜狗新聞: embedding_SougouNews.npz, 騰訊: embedding_Tencent.npz, 隨機初始化: random# 初始化詞向量路徑為搜狗新聞預訓練詞向量文件embedding = 'embedding_SougouNews.npz'# 如果用戶指定使用隨機初始化詞向量if args.embedding == 'random':# 則將embedding設置為'random',表示不使用預訓練詞向量embedding = 'random'# 獲取用戶指定的模型名稱并保存到model_name變量中model_name = args.model # TextCNN, TextRNN等# 如果模型是FastTextif model_name == 'FastText':# 動態導入FastText專用的數據處理工具函數from utils_fasttext import build_dataset, build_iterator, get_time_dif# FastText模型強制使用隨機初始化詞向量embedding = 'random'# 如果不是FastText模型else:# 導入通用的數據處理工具函數from utils import build_dataset, build_iterator, get_time_dif# 使用import_module動態導入對應的模型模塊,例如models.TextCNNx = import_module('models.' + model_name)# 實例化模型配置類Config,傳入數據集和詞向量信息config = x.Config(dataset, embedding)# 設置numpy的隨機種子為1,確保每次運行結果一致np.random.seed(1)# 設置PyTorch CPU模式下的隨機種子為1torch.manual_seed(1)# 設置所有CUDA設備的隨機種子為1,保證GPU訓練結果可復現torch.cuda.manual_seed_all(1)# 設置CuDNN為確定性模式,以確保卷積運算的結果可重復torch.backends.cudnn.deterministic = True# 記錄開始加載數據的時間戳start_time = time.time()# 打印數據加載提示信息print("Loading data...")# 構建數據集,包括詞匯表vocab和訓練、驗證、測試數據vocab, train_data, dev_data, test_data = build_dataset(config, args.word)# 創建訓練數據迭代器train_iter = build_iterator(train_data, config)# 創建驗證數據迭代器dev_iter = build_iterator(dev_data, config)# 創建測試數據迭代器test_iter = build_iterator(test_data, config)# 計算數據加載所用時間time_dif = get_time_dif(start_time)# 打印數據加載耗時print("Time usage:", time_dif)# train# 將詞匯表大小賦值給config.n_vocab,供模型使用config.n_vocab = len(vocab)# 實例化模型,并將其移動到指定設備(CPU/GPU)model = x.Model(config).to(config.device)# 創建TensorBoard日志寫入器,log目錄包含當前時間戳以便區分不同訓練日志writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))# 如果不是Transformer模型if model_name != 'Transformer':# 調用init_network函數初始化網絡參數init_network(model)# 打印模型參數信息print(model.parameters)# 調用train函數開始訓練模型,傳入配置、模型和數據迭代器train(config, model, train_iter, dev_iter, test_iter, writer)
train_eval.py
import time
# 導入time模塊,用于記錄數據加載和訓練時間import torch
# 導入PyTorch框架,用于構建和訓練深度學習模型import numpy as np
# 導入NumPy庫,用于進行數值計算和數組操作from train_eval import train, init_network
# 從train_eval.py文件中導入train函數(訓練模型)和init_network函數(初始化網絡參數)from importlib import import_module
# 從importlib中導入import_module函數,用于動態導入模塊import argparse
# 導入argparse模塊,用于解析命令行參數from tensorboardX import SummaryWriter
# 導入tensorboardX的SummaryWriter類,用于可視化訓練過程中的指標(如loss、accuracy等)# 創建一個ArgumentParser對象,描述為“Chinese Text Classification”
parser = argparse.ArgumentParser(description='Chinese Text Classification')# 添加--model參數,類型為字符串,必須輸入,幫助信息提示選擇TextCNN、TextRNN等模型
parser.add_argument('--model', type=str, required=True, help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')# 添加--embedding參數,默認值為'pre_trained',類型為字符串,幫助信息提示選擇預訓練或隨機詞向量
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')# 添加--word參數,默認False,類型為布爾值,幫助信息提示是否使用詞粒度(True)還是字符粒度(False)
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')# 解析命令行傳入的參數,并保存在args變量中
args = parser.parse_args()if __name__ == '__main__':# 程序入口,表示這是主程序執行部分# 設置使用的數據集名稱為'THUCNews'dataset = 'THUCNews' # 數據集# 搜狗新聞: embedding_SougouNews.npz, 騰訊: embedding_Tencent.npz, 隨機初始化: random# 初始化詞向量路徑為搜狗新聞預訓練詞向量文件embedding = 'embedding_SougouNews.npz'# 如果用戶指定使用隨機初始化詞向量if args.embedding == 'random':# 則將embedding設置為'random',表示不使用預訓練詞向量embedding = 'random'# 獲取用戶指定的模型名稱并保存到model_name變量中model_name = args.model # TextCNN, TextRNN等# 如果模型是FastTextif model_name == 'FastText':# 動態導入FastText專用的數據處理工具函數from utils_fasttext import build_dataset, build_iterator, get_time_dif# FastText模型強制使用隨機初始化詞向量embedding = 'random'# 如果不是FastText模型else:# 導入通用的數據處理工具函數from utils import build_dataset, build_iterator, get_time_dif# 使用import_module動態導入對應的模型模塊,例如models.TextCNNx = import_module('models.' + model_name)# 實例化模型配置類Config,傳入數據集和詞向量信息config = x.Config(dataset, embedding)# 設置numpy的隨機種子為1,確保每次運行結果一致np.random.seed(1)# 設置PyTorch CPU模式下的隨機種子為1torch.manual_seed(1)# 設置所有CUDA設備的隨機種子為1,保證GPU訓練結果可復現torch.cuda.manual_seed_all(1)# 設置CuDNN為確定性模式,以確保卷積運算的結果可重復torch.backends.cudnn.deterministic = True# 記錄開始加載數據的時間戳start_time = time.time()# 打印數據加載提示信息print("Loading data...")# 構建數據集,包括詞匯表vocab和訓練、驗證、測試數據vocab, train_data, dev_data, test_data = build_dataset(config, args.word)# 創建訓練數據迭代器train_iter = build_iterator(train_data, config)# 創建驗證數據迭代器dev_iter = build_iterator(dev_data, config)# 創建測試數據迭代器test_iter = build_iterator(test_data, config)# 計算數據加載所用時間time_dif = get_time_dif(start_time)# 打印數據加載耗時print("Time usage:", time_dif)# train# 將詞匯表大小賦值給config.n_vocab,供模型使用config.n_vocab = len(vocab)# 實例化模型,并將其移動到指定設備(CPU/GPU)model = x.Model(config).to(config.device)# 創建TensorBoard日志寫入器,log目錄包含當前時間戳以便區分不同訓練日志writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))# 如果不是Transformer模型if model_name != 'Transformer':# 調用init_network函數初始化網絡參數init_network(model)# 打印模型參數信息print(model.parameters)# 調用train函數開始訓練模型,傳入配置、模型和數據迭代器train(config, model, train_iter, dev_iter, test_iter, writer)
utils.py:
# coding: UTF-8
# 指定文件編碼為UTF-8,支持中文字符import os
# 導入os模塊,用于進行操作系統路徑和文件操作import torch
# 導入PyTorch框架,用于構建和訓練深度學習模型import numpy as np
# 導入NumPy庫,用于數值計算和數組操作import pickle as pkl
# 導入pickle模塊,用于序列化和反序列化Python對象(如保存和加載詞匯表)from tqdm import tqdm
# 從tqdm導入tqdm類,用于在循環中顯示進度條import time
# 導入time模塊,用于記錄時間from datetime import timedelta
# 從datetime導入timedelta類,用于表示時間差MAX_VOCAB_SIZE = 10000
# 設置最大詞表大小為10000個詞UNK, PAD = '<UNK>', '<PAD>'
# 定義特殊符號:未知詞用<UNK>表示,填充符用<PAD>表示def build_vocab(file_path, tokenizer, max_size, min_freq):# 構建詞匯表函數,參數包括數據路徑、分詞器、最大詞表大小和最小出現頻率vocab_dic = {}# 初始化一個空字典來存儲詞匯及其頻次with open(file_path, 'r', encoding='UTF-8') as f:# 打開文本文件進行讀取# 遍歷每一行,并顯示進度條for line in tqdm(f):# 去除首尾空白字符lin = line.strip()if not lin:continue# 如果是空行,則跳過# 使用制表符分割,取第一個部分作為文本內容content = lin.split('\t')[0]# 使用指定的tokenizer對內容進行分詞for word in tokenizer(content):# 統計每個詞的出現次數vocab_dic[word] = vocab_dic.get(word, 0) + 1# 篩選出現頻率大于等于min_freq的詞,并按頻率排序后取前max_size個詞vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]# 將篩選后的詞列表轉換為詞到索引的映射字典vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}# 添加特殊符號到詞典中,UNK排在最后,PAD在其后vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})# 返回構建好的詞匯表字典return vocab_dic# 構建數據集函數,參數為配置對象config和是否使用詞粒度標志use_word
def build_dataset(config, ues_word):# 如果使用詞粒度if ues_word:# 使用空格分詞,即詞級別處理tokenizer = lambda x: x.split(' ')else:# 否則使用字符級別分詞,將字符串轉為字符列表tokenizer = lambda x: [y for y in x]# 如果已經存在詞匯表文件if os.path.exists(config.vocab_path):# 直接加載已有的詞匯表vocab = pkl.load(open(config.vocab_path, 'rb'))# 如果不存在詞匯表文件else:# 調用build_vocab函數構建新的詞匯表vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)# 將新構建的詞匯表保存到磁盤文件中pkl.dump(vocab, open(config.vocab_path, 'wb'))# 打印詞匯表大小print(f"Vocab size: {len(vocab)}")# 加載單個數據集(訓練/驗證/測試)的內部函數def load_dataset(path, pad_size=32):# 初始化數據容器contents = []# 打開數據文件with open(path, 'r', encoding='UTF-8') as f:# 逐行讀取并顯示進度條for line in tqdm(f):# 去除前后空白字符lin = line.strip()# 空行跳過if not lin:continue# 使用制表符分割,獲取文本內容和標簽content, label = lin.split('\t')# 初始化當前句子的token列表words_line = []# 使用tokenizer對內容進行分詞或分字token = tokenizer(content)# 獲取原始序列長度seq_len = len(token)# 如果設置了固定長度if pad_size:# 如果當前句子長度小于pad_sizeif len(token) < pad_size:# 用<PAD>補齊至pad_size長度token.extend([vocab.get(PAD)] * (pad_size - len(token)))else:token = token[:pad_size]# 否則截斷至pad_size長度seq_len = pad_size# word to idfor word in token:# 將詞轉換為對應的索引# 如果詞不在詞典中,使用UNK替代words_line.append(vocab.get(word, vocab.get(UNK)))# 將處理后的數據加入contents列表contents.append((words_line, int(label), seq_len))# 返回處理好的數據集return contents # [([...], 0), ([...], 1), ...]# 分別加載訓練集、驗證集和測試集train = load_dataset(config.train_path, config.pad_size)dev = load_dataset(config.dev_path, config.pad_size)test = load_dataset(config.test_path, config.pad_size)# 返回詞匯表和三個數據集return vocab, train, dev, test# 自定義數據迭代器類
class DatasetIterater(object):# 初始化方法def __init__(self, batches, batch_size, device):# 設置批量大小self.batch_size = batch_size# 數據批次列表self.batches = batches# 計算完整batch的數量self.n_batches = len(batches) // batch_sizeself.residue = False # 是否有剩余樣本if len(batches) % self.n_batches != 0:self.residue = True# 如果不能整除,標記存在殘余數據# 當前遍歷的起始索引self.index = 0# 數據所在設備(CPU/GPU)self.device = device# 將數據轉換為張量的方法def _to_tensor(self, datas):# 輸入序列轉為LongTensor并移動到指定設備x = torch.LongTensor([_[0] for _ in datas]).to(self.device)# 標簽轉為LongTensor并移動到指定設備y = torch.LongTensor([_[1] for _ in datas]).to(self.device)# 序列長度信息轉為LongTensor并移動到指定設備seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)# 返回輸入、長度和標簽return (x, seq_len), y# 實現迭代器的__next__方法def __next__(self):# 如果有殘余數據且到達最后一個不完整的batchif self.residue and self.index == self.n_batches:# 取出殘余數據batches = self.batches[self.index * self.batch_size: len(self.batches)]# 更新索引self.index += 1# 轉換為張量batches = self._to_tensor(batches)# 返回當前batchreturn batches# 如果索引超過總batch數elif self.index > self.n_batches:self.index = 0# 重置索引raise StopIteration# 拋出停止迭代異常else:# 正常取一個batch# 取出當前batch的數據batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]# 更新索引self.index += 1# 轉換為張量batches = self._to_tensor(batches)# 返回當前batchreturn batchesdef __iter__(self):# 實現__iter__方法,返回自身即可開始迭代return selfdef __len__(self):# 獲取總batch數量if self.residue:# 如果有殘余數據,加1return self.n_batches + 1else:# 否則直接返回完整batch數return self.n_batches# 構建數據迭代器函數
def build_iterator(dataset, config):# 創建DatasetIterater實例iter = DatasetIterater(dataset, config.batch_size, config.device)# 返回迭代器對象return iterdef get_time_dif(start_time):"""獲取已使用時間"""end_time = time.time()time_dif = end_time - start_time# 返回格式化的時間差對象return timedelta(seconds=int(round(time_dif)))if __name__ == "__main__":'''提取預訓練詞向量'''# 下面的目錄、文件名按需更改。# 定義訓練數據集的目錄train_dir = "./THUCNews/data/train.txt"# 定義詞匯表的目錄vocab_dir = "./THUCNews/data/vocab.pkl"# 定義預訓練向量的目錄pretrain_dir = "./THUCNews/data/sgns.sogou.char"# 定義詞向量的維度emb_dim = 300# 定義保存修剪后嵌入層的目錄filename_trimmed_dir = "./THUCNews/data/embedding_SougouNews"# 檢查詞匯表是否已存在if os.path.exists(vocab_dir):# 如果存在,加載詞匯表word_to_id = pkl.load(open(vocab_dir, 'rb'))else:# 如果不存在,定義一個分詞函數,以字為單位構建詞表tokenizer = lambda x: [y for y in x]# 使用訓練數據構建詞匯表word_to_id = build_vocab(train_dir, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)# 保存詞匯表pkl.dump(word_to_id, open(vocab_dir, 'wb'))# 初始化隨機嵌入層矩陣,維度為詞匯表大小乘以詞向量維度embeddings = np.random.rand(len(word_to_id), emb_dim)# 打開預訓練的詞向量文件f = open(pretrain_dir, "r", encoding='UTF-8')# 遍歷預訓練的詞向量文件,更新嵌入層矩陣for i, line in enumerate(f.readlines()):lin = line.strip().split(" ")# 如果當前詞在詞匯表中,則更新其對應的詞向量if lin[0] in word_to_id:idx = word_to_id[lin[0]]emb = [float(x) for x in lin[1:301]]embeddings[idx] = np.asarray(emb, dtype='float32')# 關閉文件f.close()# 保存修剪后的嵌入層矩陣np.savez_compressed(filename_trimmed_dir, embeddings=embeddings)# 主程序入口,用于生成預訓練詞向量文件
utils_fasttext.py:
# coding: UTF-8
# 指定文件編碼為UTF-8,支持中文字符import os
# 導入os模塊,用于進行操作系統路徑和文件操作import torch
# 導入PyTorch框架,用于構建和訓練深度學習模型import numpy as np
# 導入NumPy庫,用于數值計算和數組操作import pickle as pkl
# 導入pickle模塊,用于序列化和反序列化Python對象(如保存和加載詞匯表)from tqdm import tqdm
# 從tqdm導入tqdm類,用于在循環中顯示進度條import time
# 導入time模塊,用于記錄時間from datetime import timedelta
# 從datetime導入timedelta類,用于表示時間差MAX_VOCAB_SIZE = 10000
# 設置最大詞表大小為10000個詞UNK, PAD = '<UNK>', '<PAD>'
# 定義特殊符號:未知詞用<UNK>表示,填充符用<PAD>表示def build_vocab(file_path, tokenizer, max_size, min_freq):# 構建詞匯表函數,參數包括數據路徑、分詞器、最大詞表大小和最小出現頻率vocab_dic = {}# 初始化一個空字典來存儲詞匯及其頻次with open(file_path, 'r', encoding='UTF-8') as f:# 打開文本文件進行讀取# 遍歷每一行,并顯示進度條for line in tqdm(f):# 去除首尾空白字符lin = line.strip()if not lin:continue# 如果是空行,則跳過# 使用制表符分割,取第一個部分作為文本內容content = lin.split('\t')[0]# 使用指定的tokenizer對內容進行分詞for word in tokenizer(content):# 統計每個詞的出現次數vocab_dic[word] = vocab_dic.get(word, 0) + 1# 篩選出現頻率大于等于min_freq的詞,并按頻率排序后取前max_size個詞vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]# 將篩選后的詞列表轉換為詞到索引的映射字典vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}# 添加特殊符號到詞典中,UNK排在最后,PAD在其后vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})# 返回構建好的詞匯表字典return vocab_dic# 構建數據集函數,參數為配置對象config和是否使用詞粒度標志use_word
def build_dataset(config, ues_word):# 如果使用詞粒度if ues_word:# 使用空格分詞,即詞級別處理tokenizer = lambda x: x.split(' ')else:# 否則使用字符級別分詞,將字符串轉為字符列表tokenizer = lambda x: [y for y in x]# 如果已經存在詞匯表文件if os.path.exists(config.vocab_path):# 直接加載已有的詞匯表vocab = pkl.load(open(config.vocab_path, 'rb'))# 如果不存在詞匯表文件else:# 調用build_vocab函數構建新的詞匯表vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)# 將新構建的詞匯表保存到磁盤文件中pkl.dump(vocab, open(config.vocab_path, 'wb'))# 打印詞匯表大小print(f"Vocab size: {len(vocab)}")# 加載單個數據集(訓練/驗證/測試)的內部函數def load_dataset(path, pad_size=32):# 初始化數據容器contents = []# 打開數據文件with open(path, 'r', encoding='UTF-8') as f:# 逐行讀取并顯示進度條for line in tqdm(f):# 去除前后空白字符lin = line.strip()# 空行跳過if not lin:continue# 使用制表符分割,獲取文本內容和標簽content, label = lin.split('\t')# 初始化當前句子的token列表words_line = []# 使用tokenizer對內容進行分詞或分字token = tokenizer(content)# 獲取原始序列長度seq_len = len(token)# 如果設置了固定長度if pad_size:# 如果當前句子長度小于pad_sizeif len(token) < pad_size:# 用<PAD>補齊至pad_size長度token.extend([vocab.get(PAD)] * (pad_size - len(token)))else:token = token[:pad_size]# 否則截斷至pad_size長度seq_len = pad_size# word to idfor word in token:# 將詞轉換為對應的索引# 如果詞不在詞典中,使用UNK替代words_line.append(vocab.get(word, vocab.get(UNK)))# 將處理后的數據加入contents列表contents.append((words_line, int(label), seq_len))# 返回處理好的數據集return contents # [([...], 0), ([...], 1), ...]# 分別加載訓練集、驗證集和測試集train = load_dataset(config.train_path, config.pad_size)dev = load_dataset(config.dev_path, config.pad_size)test = load_dataset(config.test_path, config.pad_size)# 返回詞匯表和三個數據集return vocab, train, dev, test# 自定義數據迭代器類
class DatasetIterater(object):# 初始化方法def __init__(self, batches, batch_size, device):# 設置批量大小self.batch_size = batch_size# 數據批次列表self.batches = batches# 計算完整batch的數量self.n_batches = len(batches) // batch_sizeself.residue = False # 是否有剩余樣本if len(batches) % self.n_batches != 0:self.residue = True# 如果不能整除,標記存在殘余數據# 當前遍歷的起始索引self.index = 0# 數據所在設備(CPU/GPU)self.device = device# 將數據轉換為張量的方法def _to_tensor(self, datas):# 輸入序列轉為LongTensor并移動到指定設備x = torch.LongTensor([_[0] for _ in datas]).to(self.device)# 標簽轉為LongTensor并移動到指定設備y = torch.LongTensor([_[1] for _ in datas]).to(self.device)# 序列長度信息轉為LongTensor并移動到指定設備seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)# 返回輸入、長度和標簽return (x, seq_len), y# 實現迭代器的__next__方法def __next__(self):# 如果有殘余數據且到達最后一個不完整的batchif self.residue and self.index == self.n_batches:# 取出殘余數據batches = self.batches[self.index * self.batch_size: len(self.batches)]# 更新索引self.index += 1# 轉換為張量batches = self._to_tensor(batches)# 返回當前batchreturn batches# 如果索引超過總batch數elif self.index > self.n_batches:self.index = 0# 重置索引raise StopIteration# 拋出停止迭代異常else:# 正常取一個batch# 取出當前batch的數據batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]# 更新索引self.index += 1# 轉換為張量batches = self._to_tensor(batches)# 返回當前batchreturn batchesdef __iter__(self):# 實現__iter__方法,返回自身即可開始迭代return selfdef __len__(self):# 獲取總batch數量if self.residue:# 如果有殘余數據,加1return self.n_batches + 1else:# 否則直接返回完整batch數return self.n_batches# 構建數據迭代器函數
def build_iterator(dataset, config):# 創建DatasetIterater實例iter = DatasetIterater(dataset, config.batch_size, config.device)# 返回迭代器對象return iterdef get_time_dif(start_time):"""獲取已使用時間"""end_time = time.time()time_dif = end_time - start_time# 返回格式化的時間差對象return timedelta(seconds=int(round(time_dif)))if __name__ == "__main__":'''提取預訓練詞向量'''# 下面的目錄、文件名按需更改。# 定義訓練數據集的目錄train_dir = "./THUCNews/data/train.txt"# 定義詞匯表的目錄vocab_dir = "./THUCNews/data/vocab.pkl"# 定義預訓練向量的目錄pretrain_dir = "./THUCNews/data/sgns.sogou.char"# 定義詞向量的維度emb_dim = 300# 定義保存修剪后嵌入層的目錄filename_trimmed_dir = "./THUCNews/data/embedding_SougouNews"# 檢查詞匯表是否已存在if os.path.exists(vocab_dir):# 如果存在,加載詞匯表word_to_id = pkl.load(open(vocab_dir, 'rb'))else:# 如果不存在,定義一個分詞函數,以字為單位構建詞表tokenizer = lambda x: [y for y in x]# 使用訓練數據構建詞匯表word_to_id = build_vocab(train_dir, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)# 保存詞匯表pkl.dump(word_to_id, open(vocab_dir, 'wb'))# 初始化隨機嵌入層矩陣,維度為詞匯表大小乘以詞向量維度embeddings = np.random.rand(len(word_to_id), emb_dim)# 打開預訓練的詞向量文件f = open(pretrain_dir, "r", encoding='UTF-8')# 遍歷預訓練的詞向量文件,更新嵌入層矩陣for i, line in enumerate(f.readlines()):lin = line.strip().split(" ")# 如果當前詞在詞匯表中,則更新其對應的詞向量if lin[0] in word_to_id:idx = word_to_id[lin[0]]emb = [float(x) for x in lin[1:301]]embeddings[idx] = np.asarray(emb, dtype='float32')# 關閉文件f.close()# 保存修剪后的嵌入層矩陣np.savez_compressed(filename_trimmed_dir, embeddings=embeddings)# 主程序入口,用于生成預訓練詞向量文件
/models/TextCNN.py:
# coding: UTF-8
# 指定文件編碼為UTF-8,支持中文字符
# 導入PyTorch框架,用于構建和訓練深度學習模型
import torch# 從PyTorch中導入神經網絡模塊,用于定義神經網絡層
import torch.nn as nn# 導入PyTorch的功能性函數模塊,如激活函數、卷積等
import torch.nn.functional as F# 導入NumPy庫,用于進行數值計算和數組操作
import numpy as np"""配置參數"""
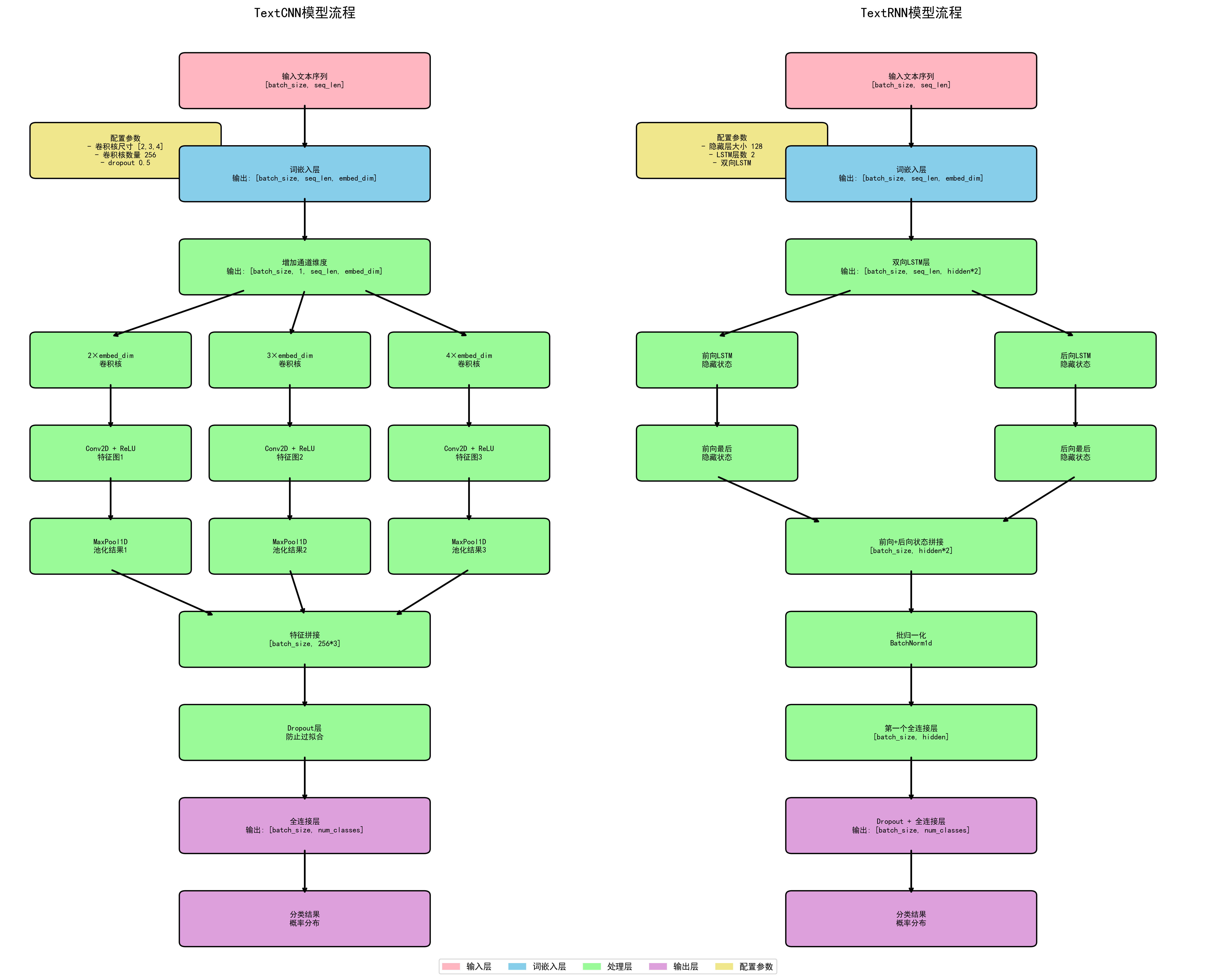
class Config(object):# 初始化配置類,傳入數據集名稱和詞向量類型(預訓練或隨機)def __init__(self, dataset, embedding):# 設置模型名稱為TextCNNself.model_name = 'TextCNN'# 訓練集路徑,格式為{dataset}/data/train.txtself.train_path = dataset + '/data/train.txt'# 驗證集路徑,格式為{dataset}/data/dev.txtself.dev_path = dataset + '/data/dev.txt'# 測試集路徑,格式為{dataset}/data/test.txtself.test_path = dataset + '/data/test.txt'# 從class.txt中讀取類別列表,并去除每行兩端空白字符self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]# 詞匯表保存路徑,格式為{dataset}/data/vocab.pklself.vocab_path = dataset + '/data/vocab.pkl'# 模型保存路徑,格式為{dataset}/saved_dict/TextCNN.ckptself.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'# 日志保存路徑,格式為{dataset}/log/TextCNNself.log_path = dataset + '/log/' + self.model_name# 如果embedding不是random,則加載預訓練詞向量;否則設為Noneself.embedding_pretrained = torch.tensor(np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32')) \if embedding != 'random' else None# 設置設備:如果CUDA可用則使用GPU,否則使用CPUself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# dropout比率,在訓練過程中隨機失活部分神經元以防止過擬合self.dropout = 0.5# 若驗證集loss在1000個batch內未下降,則提前終止訓練self.require_improvement = 1000# 類別數量,由class.txt中讀取得到self.num_classes = len(self.class_list)# 詞表大小,在后續運行時動態賦值self.n_vocab = 0# 訓練輪數,總共訓練20個epochself.num_epochs = 20# mini-batch大小,每次訓練使用的樣本數為128self.batch_size = 128# 句子統一長度,短句填充,長句截斷self.pad_size = 32# 學習率,控制參數更新步長self.learning_rate = 1e-3# 如果有預訓練詞向量,字向量維度為預訓練維度;否則默認為300維self.embed = self.embedding_pretrained.size(1) \if self.embedding_pretrained is not None else 300# 卷積核尺寸,分別使用2、3、4長度的卷積核提取特征self.filter_sizes = (2, 3, 4)# 卷積核數量,即輸出通道數,每個尺寸的卷積核都有256個self.num_filters = 256'''Convolutional Neural Networks for Sentence Classification'''
# 文本分類的卷積神經網絡原始論文引用標題# 定義TextCNN模型類,繼承自nn.Module
class Model(nn.Module):# 構造函數,初始化模型結構def __init__(self, config):# 調用父類構造函數super(Model, self).__init__()# 如果提供了預訓練詞向量if config.embedding_pretrained is not None:# 使用預訓練詞向量,并允許微調(freeze=False)self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:# 否則# 創建一個隨機初始化的詞嵌入層,設置padding_idx為最后一個索引self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)# 創建多個一維卷積層,每個卷積核高度分別為2、3、4,寬度為詞向量維度self.convs = nn.ModuleList([nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])# 添加Dropout層,防止過擬合self.dropout = nn.Dropout(config.dropout)# 全連接層,輸入大小為所有卷積核輸出拼接后的總長度,輸出為類別數self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)# 定義卷積+池化函數,用于處理每個卷積層的輸出def conv_and_pool(self, x, conv):# 應用ReLU激活函數并通過卷積層,然后去掉第四個維度(單列)x = F.relu(conv(x)).squeeze(3)# 在時間維度上做最大池化,再去除第二個維度x = F.max_pool1d(x, x.size(2)).squeeze(2)# 返回池化后的結果return x# 前向傳播函數,定義數據如何通過網絡流動def forward(self, x):# 調試信息:打印輸入張量形狀print(x[0].shape)# 將輸入的token索引轉換為詞向量表示out = self.embedding(x[0])# 在第2維增加一個通道維度,使其適配Conv2d輸入要求out = out.unsqueeze(1)# 對不同尺寸的卷積核分別進行卷積和池化操作,并將結果拼接在一起out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)# 應用Dropout,減少過擬合風險out = self.dropout(out)# 最終通過全連接層得到分類輸出out = self.fc(out)# 返回模型輸出結果return out/models/TextRNN.py:
# coding: UTF-8
# 指定文件編碼為UTF-8,支持中文字符
# 導入PyTorch框架,用于構建和訓練深度學習模型
import torch# 從PyTorch中導入神經網絡模塊,用于定義神經網絡層
import torch.nn as nn# 導入PyTorch的功能性函數模塊,如激活函數、卷積等
import torch.nn.functional as F# 導入NumPy庫,用于進行數值計算和數組操作
import numpy as np"""配置參數"""
class Config(object):# 初始化配置類,傳入數據集名稱和詞向量類型(預訓練或隨機)def __init__(self, dataset, embedding):# 設置模型名稱為TextRNNself.model_name = 'TextRNN'# 訓練集路徑,格式為{dataset}/data/train.txtself.train_path = dataset + '/data/train.txt'# 驗證集路徑,格式為{dataset}/data/dev.txtself.dev_path = dataset + '/data/dev.txt'# 測試集路徑,格式為{dataset}/data/test.txtself.test_path = dataset + '/data/test.txt'# 從class.txt中讀取類別列表,并去除每行兩端空白字符self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]# 詞匯表保存路徑,格式為{dataset}/data/vocab.pklself.vocab_path = dataset + '/data/vocab.pkl'# 模型保存路徑,格式為{dataset}/saved_dict/TextRNN.ckptself.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'# 日志保存路徑,格式為{dataset}/log/TextRNNself.log_path = dataset + '/log/' + self.model_name# 如果embedding不是random,則加載預訓練詞向量;否則設為Noneself.embedding_pretrained = torch.tensor(np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32')) \if embedding != 'random' else None# 設置設備:如果CUDA可用則使用GPU,否則使用CPUself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# dropout比率,在訓練過程中隨機失活部分神經元以防止過擬合self.dropout = 0.5# 若驗證集loss在1000個batch內未下降,則提前終止訓練self.require_improvement = 1000# 類別數量,由class.txt中讀取得到self.num_classes = len(self.class_list)# 詞表大小,在后續運行時動態賦值self.n_vocab = 0# 訓練輪數,總共訓練10個epochself.num_epochs = 10# mini-batch大小,每次訓練使用的樣本數為128self.batch_size = 128# 句子統一長度,短句填充,長句截斷self.pad_size = 32# 學習率,控制參數更新步長self.learning_rate = 1e-3# 如果有預訓練詞向量,字向量維度為預訓練維度;否則默認為300維self.embed = self.embedding_pretrained.size(1) \if self.embedding_pretrained is not None else 300# LSTM隱藏層大小,表示每個時刻LSTM輸出的特征維度self.hidden_size = 128# LSTM層數,堆疊兩層LSTM網絡self.num_layers = 2'''Recurrent Neural Network for Text Classification with Multi-Task Learning'''
# 引用論文標題:基于多任務學習的文本分類循環神經網絡# 定義TextRNN模型類,繼承自nn.Module
class Model(nn.Module):# 構造函數,初始化模型結構def __init__(self, config):# 調用父類構造函數super(Model, self).__init__()# 如果提供了預訓練詞向量if config.embedding_pretrained is not None:# 使用預訓練詞向量,并允許微調(freeze=False)self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:# 否則# 創建一個隨機初始化的詞嵌入層,設置padding_idx為最后一個索引self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)# 創建雙向LSTM層,輸入維度為詞向量維度,輸出維度為hidden_size,num_layers層,batch_first=True表示輸入形狀為(batch, seq, feature)self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,bidirectional=True, batch_first=True, dropout=config.dropout)# 全連接層,將LSTM輸出的最后一時刻的拼接結果映射到類別空間self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)# 前向傳播函數,定義數據如何通過網絡流動def forward(self, x):# 解包輸入數據,x是token索引,_ 是其他信息(如seq_len),但此處忽略x, _ = x# 將輸入的token索引轉換為詞向量表示,形狀為[batch_size, seq_len, embed]out = self.embedding(x)# 輸入到LSTM中,out是所有時間步的輸出,形狀為[batch_size, seq_len, hidden_size*2](因為是雙向)out, _ = self.lstm(out)# 取LSTM最后一步的輸出作為句子表示,輸入全連接層得到分類結果out = self.fc(out[:, -1, :])# 返回模型輸出結果return out





exec函數族詳解)







)
(Michael Artin))
)


