前言:此篇復習筆記結合了課程ppt和deepseek回答進行總結,如有謬誤懇請指正。
期末考例題
(名詞解釋*10、簡答*6、論述*6)
一、名詞解釋
數據挖掘
過擬合(Overfitting)
Apriori算法
決策樹(Decision Tree)
K-means聚類
數據預處理
信息增益
頻繁項集
剪枝
離群點檢測
集成學習
二、簡答題
解釋數據清洗的概念和重要性。
為什么需要對數據進行歸一化(Normalization)?列舉兩種常用方法。
解釋關聯規則中支持度(Support)和置信度(Confidence)的定義及計算公式。
對比分類與聚類的區別(至少3點)。
ID3決策樹算法如何選擇分裂屬性?寫出其核心公式并解釋含義。
簡述K-means算法的步驟,并說明其局限性。
第一章 緒論
1.1 KDD
從數據中發現知識(KDD):指從大量數據中提取有效的、新穎的、潛在有用的、最終可被理解的模式的非平凡過程。包括數據清理、數據集成、數據選擇、數據變換、數據挖掘、模式評估和知識表示幾個步驟。數據清理、集成、選擇、變換屬于數據預處理過程,模式評估、知識表示是結果的解釋與評估。
KDD過程
數據清理(Data Cleaning)
功能:處理數據中的噪聲、缺失值、不一致和異常數據。
具體任務:
解決不一致問題(如統一單位或格式)。
識別并處理異常值(如使用統計方法或領域知識)。
平滑噪聲數據(如分箱、回歸或聚類)。
填補缺失值(如用均值、中位數或插值法)。
數據集成(Data Integration)
功能:將來自多個數據源的數據合并為一個一致的數據存儲。
具體任務:
處理數據冗余和沖突(如通過相關性分析或沖突檢測)。
解決實體識別問題(如不同數據源中的同名異義或異名同義)。
合并不同數據庫、文件或API的數據。
數據選擇(Data Selection)
功能:從集成后的數據中選擇與分析任務相關的數據子集。
具體任務:
使用維度規約(如主成分分析)或采樣技術減少數據量。
根據目標篩選相關屬性(特征)或樣本(記錄)。
數據變換(Data Transformation)
功能:將數據轉換為適合挖掘的形式。
具體任務:
泛化數據(如用高層次概念替換原始值,如“年齡”替換為“青年”“中年”)。
構造新特征(如聚合或計算派生變量)。
離散化連續數據(如分箱或聚類)。
規范化或標準化數據(如最小-最大縮放、Z-score標準化)。
數據挖掘(Data Mining)
功能:應用算法從數據中提取模式或知識。
具體任務:
調整參數以優化模型性能。
使用算法(如決策樹、神經網絡、Apriori、K-means)發現模式。
選擇挖掘技術(如分類、聚類、關聯規則、回歸、異常檢測)。
模式評估(Pattern Evaluation)
功能:評估挖掘出的模式的有效性和價值。
具體任務:
領域專家評估模式的實際意義。
統計驗證(如假設檢驗或交叉驗證)。
使用興趣度度量(如支持度、置信度、提升度)篩選模式。
知識表示(Knowledge Presentation)
功能:以用戶可理解的方式呈現發現的知識。
具體任務:
集成到決策支持系統或知識庫中。
生成報告或規則(如自然語言描述或邏輯表達式)。
可視化(如圖表、樹狀圖、熱力圖)。
KDD的研究進展:KDD已經從學術研究走向工業級應用,成為企業決策、智慧城市、醫療健康等領域的核心技術。目前的研究的重點是提高原先數據挖掘算法在(空間)數據庫中的執行效率,開發新的模型與算法以及挖掘結果表達的研究,數據挖掘成為人工智能的研究熱點。
數據結構金字塔:數據(未處理過的信息)— 信息(組織、整理之后展現的數據)— 知識(經過讀、看之后得到的知識)— 智慧(知識經過精煉整合萃取出的精華)
1.2 空間數據挖掘
空間數據挖掘(Spatial DataMining,SDM),或稱從空間數據庫中發現知識(Knowledge Discovery from Spatial Databases):是指從空間數據庫中提取用戶感興趣的空間模式與特征、空間與非空間數據的普遍關系及其它一些隱含在數據庫中的普遍的數據特征。
空間數據的特點:海量數據,空間屬性之間的非線性關系、尺度特征、空間信息的模糊性、空間維數的增高、空間數據的缺值。
空間數據庫的特點:存儲了空間對象的一般屬性數據、幾何屬性數據、對象之間的空間關系,其非結構化、分層、矢量柵格數據格式并存的特點,使得其訪問和操作模式更加復雜。
空間數據挖掘VS.數據挖掘:存儲結構非結構化;
空間數據挖掘VS.傳統地學分析:追求在機理不明的情況下對數據的規則、規律的發現和提取。
1.3 相關論述題
為什么要進行KDD
1、解決數據爆炸與信息匱乏的矛盾:
海量數據中蘊含的、能夠直接用于決策或理解的有價值信息和知識卻相對匱乏,KDD從海量數據中提取出真正有用的、可理解的、可操作的知識。
2、揭示隱藏的模式和關系:
數據中往往隱藏著人類難以直接觀察或想象的復雜模式、趨勢、關聯規則和異常情況,KDD 利用數據挖掘等算法技術,能夠自動或半自動地發現這些隱藏的、有價值的知識,揭示數據背后的規律和洞察。
3、支持智能決策:
基于從數據中發現的知識(如預測模型、分類規則、聚類結果),企業、組織和個人可以做出更明智、更數據驅動的決策。
4、將數據轉化為競爭優勢和價值:
KDD是將原始數據轉化為實際商業價值、科學發現或社會效益的關鍵過程。它幫助企業發現新的市場機會、優化流程、降低成本、提升服務質量、開發新產品,從而獲得競爭優勢。
5、自動化知識提取過程:
面對海量數據,依靠人工手動分析來尋找模式和知識是低效、耗時、甚至不可能完成的。
KDD 提供了一個系統化、自動化的流程框架(包括數據預處理、轉換、挖掘、評估、解釋),使得從大數據中高效、大規模地提取知識成為可能。
KDD的應用
遙感影像智能解譯:?運用?聚類、分類算法?從海量衛星/航拍影像中?自動發現?土地覆蓋類型、植被變化趨勢、災害損毀區域等?隱藏知識。
地理文本信息挖掘:?利用?自然語言處理技術?分析社交媒體、新聞等文本,挖掘?帶有地理位置的情緒熱點分布、突發事件的空間位置及傳播規律等?隱含信息。
城市移動模式發現:?通過?軌跡挖掘算法?分析手機信令、出租車 GPS 等數據,揭示?人群活動規律、城市功能區劃分、交通擁堵成因等?潛在模式。
城市環境關聯分析:?應用?關聯規則挖掘、時空分析技術,整合多源傳感器數據,發現?空氣污染與交通流量、工業布局之間的?隱藏關聯,溯源污染。
設施使用規律洞察:?基于?頻繁模式挖掘、預測模型,分析共享單車、充電樁等物聯網數據,預測?需求高峰、優化?設施布局,提升服務效率。
第二章 SDM的理論技術體系
2.1 數據質量度量
數據質量的多維度量:精確度、完整度、一致性、現時性、可信度、附加價值、可訪問性
2.2 數據清洗
空缺值處理方法
- 忽略元組:當類標號缺少時通常這么做(假定挖掘任務設計分類或描述),當每個屬性缺少值的百分比變化很大時,它的效果非常差。
- 人工填寫空缺值:工作量大,可行性低
- 使用一個全局變量填充空缺值:比如使用unknown或-∞
- 使用屬性的平均值填充空缺值
- 使用與給定元組屬同一類的所有樣本的平均值
- 使用最可能的值填充空缺值:使用像Bayesian公式或判定樹這樣的基于推斷的方法
噪聲數據:一個測量變量中的隨機錯s誤或偏差。處理噪聲數據:分箱、聚類、回歸。
分箱平滑噪聲:首先排序數據,并將他們分到等深的箱中,然后可以按箱的平均值平滑、按箱中值平滑、按箱的邊界平滑等等。
注意:下圖中等深度中的深度指每個箱包含的值的數量。

2.3 數據集成
數據集成將多個數據源中的數據整合到一個一致的存儲中。
數據集成的作用
1、構建統一數據視圖:通過模式轉換、數據清洗解決命名沖突、格式差異、單位不統一等問題,形成標準化數據集。
2、提升數據質量與一致性:在集成過程中清洗冗余、修正錯誤、補全缺失值,確保后續數據挖掘以及分析結果可靠
2.4 數據變換
1、平滑:去除數據中的噪聲 (分箱、聚類、回歸)2、聚集:匯總,數據立方體的構建3、數據概化:沿概念分層向上匯總4、規范化:將數據按比例縮放,使之落入一個小的特定區間最小-最大規范化、z-score規范化、小數定標規范化5、屬性構造:通過現有屬性構造新的屬性,并添加到屬性集中;以增加對高維數據的結構的理解和精確度。

分層聚類:建立聚類的層次結構,存儲在多層索引樹中。有聚合型(agglomerative)和分裂型(divisive)兩類。
聚合法最初將每個數據點作為一個單獨的聚類,然后迭代合并,直到最后的聚類中包含所有的數據點。它也被稱為自下而上的方法。分裂聚類遵循自上而下的流程,從一個擁有所有數據點的單一聚類開始,迭代地將該聚類分割成更小的聚類,直到每個聚類包含一個數據點。
數據離散化:?通過將屬性域劃分為區間,減少給定連續屬性值的個數。區間的標號可以代替實際的數據值。
概念分層:通過使用高層的概念(比如:青年、中年、老年)來替代底層的屬性值(比如:實際的年齡數據值)來規約數據。
方法:分箱、直方圖分析、聚類分析、基于熵的離散化、通過自然劃分分段。
第三章 空間關聯規則挖掘技術
3.1 空間關聯規則挖掘
頻繁模式:頻繁地出現在數據集中的模式;(可以是項集、子序列或子結構)
頻繁項集:如果項集的頻率大于(最小支持度×D中的事務總數),則稱該項集為頻繁項集。
關聯規則挖掘:發現大量數據中項集之間有趣的關聯。(1)找出所有的頻繁項集;(2)由頻繁項集產生強關聯規則。
支持度和置信度計算
支持度是指事務集D中包含A∪B的百分比,support(A→B)=P(A∪B);
置信度是指D中包含A的事務同時也包含B的百分比,confidence(A→B)=P(B|A)=P(A∪B)/P(A)

3.2 Apriori算法示例
L1、L2、L3:頻繁k項集
連接步:為找出Lk,通過將Lk-1與自身連接產生候選k項集的集合。
剪枝步:如果一個候選k項集的(k-1)項集不在L(k-1)中,則該候選也不可能是頻繁的,可以從Ck中刪去。如下圖中{A,B}和{A,E}不是頻繁項集,因此在由L2產生L3的過程中,可以將{A,B,C}、{A,B,E}、{A,E,C}刪去。

由上述過程可以產生所有頻繁項集,后續根據頻繁項集可以找強關聯規則。?
如何提高Apriori算法效率
1、基于散列的技術(散列項集到對應的桶中)?:將每個項集通過相應的hash函數映射到hash表中的不同的桶中,這樣可以通過將桶中的項集技術跟最小支持計數相比較先淘汰一部分項集。
2、事務壓縮(壓縮進一步迭代的事務數):不包含任何k-項集的事務不可能包含任何(k+1)-項集,這種事務在下一步的計算中可以加上標記或刪除。
3、劃分(為找候選項集劃分數據):將事務集劃分為不同分區,找出所有的局部頻繁項集,再通過評估每個候選的實際支持度,以確定全局頻繁項集。
3、抽樣(在給定數據的一個子集挖掘):選擇原始數據的一個樣本,在這個樣本上用Apriori算法挖掘頻繁模式。通過犧牲精確度來減少算法開銷,為了提高效率,樣本大小應該以可以放在內存中為宜,可以適當降低最小支持度來減少遺漏的頻繁模式。可以通過一次全局掃描來驗證從樣本中發現的模式,通過第二此全局掃描來找到遺漏的模式。
4、動態項集計數(在掃描的不同點添加候選項集):在掃描的不同點添加候選項集,這樣,如果一個候選項集已經滿足最少支持度,則在可以直接將它添加到頻繁項集,而不必在這次掃描的以后對比中繼續計算。
3.3 FP-growth算法示例
頻繁模式增長(FP-growth):發現頻繁模式而不產生候選頻繁項集。(1)掃描數據庫,導出頻繁項集的集合(1項集);(2)將項按照降序排序;(3)再次掃描數據庫構建FP樹并生成頻繁項集。具體過程可參考b站視頻:關聯規則挖掘FP-growth例題?????![]() https://www.bilibili.com/video/BV1HS4y1G7h6?spm_id_from=333.788.videopod.sections&vd_source=487cc32bed199e5a2a5013ff10b420e4
https://www.bilibili.com/video/BV1HS4y1G7h6?spm_id_from=333.788.videopod.sections&vd_source=487cc32bed199e5a2a5013ff10b420e4





此處省略添加事務的步驟,最終FP樹如下圖所示。

從最低頻的i5開始,找到所有條件模式基,根據支持度確定條件FP樹,排列組合得到頻繁項集。i5的頻繁項集求解過程如下。其他項同理,不再展示。
注:過程源自視頻截圖。
Apriori算法VS.FP-growth算法:
從時間效率上,① Apriori算法需要多次掃描數據庫,對于挖掘k項集需要掃描至少k次數據庫;而FP-growth算法僅需要進行兩次掃描,分別用于構建頭表和構建FP-Tree;②Apriori算法在項數多或最小支持度低時會產生海量的候選項集,而FP-growth算法直接通過FP-Tree的結構和遞歸挖掘策略發現頻繁項集。
從空間效率上,空間效率取決于數據特性,對于事務長、項之間關聯性強、共享前綴多的密集數據集,FP-Tree的壓縮效果極佳,空間效率更高;對于非常稀疏的數據集,事務短且差異大,共享前綴少時,由于還要存儲節點、指針等結構,壓縮效果不好,還有可能比原始數據更大。
多層關聯規則挖掘:是一種在具有層次結構的數據中發現跨不同抽象層級項之間關聯規則的方法。"多層"指數據項具有明確的層級劃分,通常由領域知識構建的樹狀分類體系。方法:受控的層交叉單項過濾策略、檢查冗余的多層關聯規則。
對強關聯規則的批評

強規則不一定有趣:置信度和支持度度量不足以過濾掉這些無趣的關聯規則。因此,需要引入提升度(lift)的概念:
lift(A,B)=P(A∪B)/P(A)P(B)?
如果值小于1,則二者是正相關的,大于1則是負相關。這種負相關無法被支持度-置信度框架識別。
元規則:是指導關聯規則生成的高層規則模板,通過預定義規則結構和約束條件,縮小搜索空間,提升挖掘效率。年齡(X,青年) ∧ 購買(X,手機) → 購買(X,耳機)
空間謂詞:空間謂詞是描述地理對象間空間關系的邏輯條件,用于構建空間關聯規則或查詢。相鄰(城市A, 城市B) → 經濟合作(A,B)
第四章 空間聚類挖掘技術
4.1 聚類挖掘
聚類:聚類是根據某個相似性準則對模式集進行自動分組,達到組內差異最小、組間差異最大的過程。其中每個分組稱之為“類別”,也叫“簇”(cluster)。由于根據模式間的相似性與差異性進行自動歸類,聚類被看作是一種非監督學習過程,因此也被稱為“非監督分類”。

模式表示:是指為聚類算法選定類別的個數、聚類模式數目、特征數目、類型和尺度等要素的過程,這些是聚類分析的原始信息。模式是由一組特征構成的向量,包括定量特征和定性特征。?
定量特征分為連續型、離散型、間隔型;定性特征分為名稱型、順序性等。相似性度量:指選定能夠衡量模式間親疏關系的指標體系過程,一般用模式對間的距離函數來定義其相似/鄰近關系。但也由基于(距離)/密度/模型的相似性度量方法。
數據分組:聚類分析的主體部分,一般可分為分割式聚類、層次型聚類、基于密度的聚類、基于模型的聚類。
數據抽象:提取簡單和緊湊的數據集表示的過程。?
聚類挖掘的要求
可伸縮性:能夠適應大數據集。
多類型屬性支持:兼容數值、分類、序數等混合數據類型。
任意形狀發現:突破球狀簇限制(歐氏/曼哈頓距離易導致偏差)。
參數依賴最小化:減少人工輸入(如簇數),避免結果敏感性問題。
噪聲魯棒性:容忍離群點、缺失值等噪聲干擾。
順序不敏感:輸入數據順序變化不影響聚類結果。
高維處理能力:克服維數災難(高維稀疏數據挑戰)。
約束聚類支持:融合用戶定義約束(如業務規則)優化分組。
可解釋性:結果需關聯語義,滿足應用場景需求。
4.2 K-Means算法
K-Means聚類算法核心思想是通過迭代的方式,將數據劃分為K個不同的簇,并使得每個數據點與其所屬簇的質心(中心點或均值點)之間的距離之和最小。
算法的執行過程通常包括以下幾個步驟:
初始化:隨機選擇K個數據點作為初始的簇質心。
分配:根據每個數據點與各個簇質心的距離,將其分配給最近的簇。
更新:重新計算每個簇的質心,即取簇內所有數據點的平均值作為新的質心。
迭代:重復分配和更新步驟,直到滿足終止條件,如簇質心不再發生顯著變化或達到預設的迭代次數。
K-means聚類算法的優點與局限性
K-means算法的優點在于其簡單易懂、計算速度快且易于實現。
缺點:
①僅當簇的均值有定義時才能使用;
②用戶必須事先給定要生成的簇數k;
③不能保證其收斂于全局最優解,并且她常常終止于一個局部最優解;
④不適合于發現非凸狀的簇,或者差別很大的簇;
⑤對噪聲和離群點敏感,因為當噪聲點歸為一個簇時,很容易扭曲簇的形狀。
BIRCH:利用層次結構的平衡迭代規約和聚類,?是一種用于大規模數據集的增量式層次聚類算法。其核心思想是將數據點信息壓縮為聚類特征 (CF) 向量,并動態構建內存中的CF-樹來高效維護數據聚類摘要,從而實現快速、可伸縮的聚類,尤其擅長減少I/O開銷。它常作為預聚類步驟使用。
CF-樹:聚類特征樹,是?BIRCH 聚類算法的核心內存數據結構,是一種高度平衡樹。其節點存儲聚類特征 (CF) 條目?(CF = (N, LS, SS)),用于壓縮概括子簇或子節點群的信息。CF 向量具有可加性,支持高效合并和計算統計量(質心、半徑等)。通過分支因子?B、葉節點因子?L?和閾值?T?控制樹的結構與子簇緊密度,支持數據的動態增量更新。
密度聚類,DBSCAN算法(重要)?


4.3 DBSCAN算法?

第五章 空間分類和空間趨勢項分析
區分分類VS.預測:
分類:預測分類標號(或離散值);根據訓練數據集和類標號屬性,構建模型來分類現有數據,并用來分類新數據。
預測:建立連續函數值模型,比如預測空缺值。
區分有監督VS.無監督
有指導的學習(用于分類):模型的學習在被告知每個訓練樣本屬于哪個類的“指導”下進行;新數據使用訓練數據集中得到的規則進行分類
無指導的學習(用于聚類):每個訓練樣本的類編號是未知的,要學習的類集合或數量也可能是事先未知的;通過一系列的度量、觀察來建立數據中的類編號或進行聚類。
5.1 過擬合
過擬合:過擬合是指機器學習模型在訓練數據上表現過于優異(如準確率高、誤差低),但在未知數據(測試集或新樣本)上表現顯著下降的現象。
核心原因:
模型復雜度過高:模型過度學習訓練數據中的噪聲或隨機波動(而非底層規律);
訓練數據不足:數據量少導致模型無法泛化到真實分布;
訓練迭代過多(如神經網絡):過度優化訓練集細節。
解決方案:
降低模型復雜度:減少參數數量(如剪枝決策樹、減少神經網絡層數);
正則化(Regularization):添加懲罰項(如L1/L2正則化);
增加數據量:數據增強(圖像/文本)、收集更多樣本;
交叉驗證:早停法(Early Stopping)防止過度訓練;
集成方法:如Bagging(降低方差)。
5.2 信息增益
此段落內容來自博客:信息增益的計算![]() https://blog.csdn.net/guomutian911/article/details/78599450
https://blog.csdn.net/guomutian911/article/details/78599450
熵的概念:

信息增益計算方法:
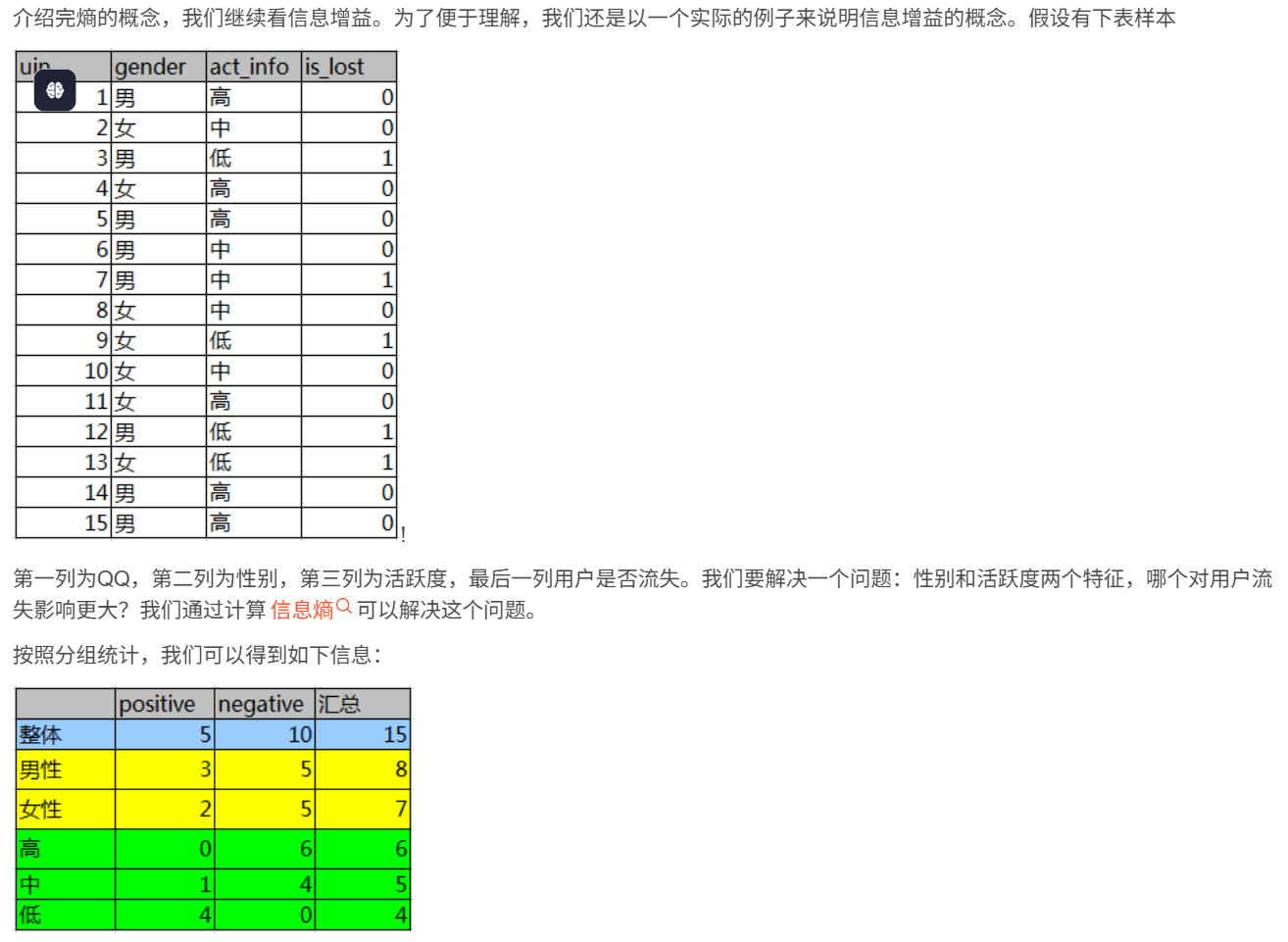

通過信息增益構造決策樹:


5.3 貝葉斯分類
貝葉斯分類:統計學分類方法,可以預測類隸屬關系的概率,如一個給定的元組屬于一個特定類的概率。
計算樸素貝葉斯分類過程(以上面的8.1例題數據為例)

袋裝法(Bagging)是一種并行式集成學習方法。其核心思想是通過自助采樣法(Bootstrap Sampling)從原始數據集中有放回地抽取多個子數據集,分別訓練多個同質基學習器(如決策樹),最終通過投票(分類)或平均(回歸)聚合預測結果。代表算法為隨機森林。
提升法(Boosting)是一種序列式集成學習方法。其核心思想是通過迭代訓練多個弱學習器(如淺層決策樹),每一輪調整樣本權重或關注前一輪錯誤樣本,最終通過加權投票(分類)或加權求和(回歸)結合預測結果。典型代表:XGBoost。
5.4 k最鄰近算法
k最近鄰算法(The k-Nearest Neighbor Algorithm,KNN)
定義:一種基于實例的惰性學習分類與回歸方法。
核心思想:通過計算待測樣本與訓練集中所有樣本的距離,選取距離最近的?kk?個鄰居,根據鄰居的多數投票(分類)或平均值(回歸)進行預測。
算法流程:
輸入待測樣本、訓練集及參數?kk;
計算待測樣本與所有訓練樣本的距離(常用歐氏距離);
選擇距離最近的?k?個鄰居;
分類任務:輸出鄰居中占比最高的類別;
回歸任務:輸出鄰居標簽的均值。
第六章 拓展內容
大數據的特點:
Volume(數據量大):如遙感影像、社交媒體數據、傳感器數據等。
Velocity(速度快):實時或近實時數據流(如氣象數據、交通數據)。
Variety(多樣性):結構化(如數據庫)、半結構化(如JSON)、非結構化(如遙感影像、文本)。
Veracity(真實性):數據質量、噪聲、不確定性(如GPS定位誤差)。
Value(價值密度低):需挖掘高價值信息(如從海量遙感數據中提取災害信息)。
大數據的分析流程:
數據采集:遙感影像、社交媒體、物聯網(IoT)數據等。
數據存儲與管理:分布式存儲(HDFS)、時空數據庫(PostGIS)。
數據預處理:清洗(去噪)、歸一化、空間插值、坐標轉換。
數據分析:機器學習(如分類、聚類)、空間統計分析(如熱點分析)。
數據可視化:GIS 地圖、時空動態展示(如熱力圖)。
決策支持:應用于智慧城市、災害監測等。
遙感圖像特征提取方法:
光譜特征:波段反射率(如NDVI植被指數)。
紋理特征:GLCM(灰度共生矩陣)、Gabor濾波。
形狀特征:邊緣檢測(Canny算子)、形態學運算。
空間特征:對象基分類(OBIA)、空間上下文信息。
深度學習特征:CNN(卷積神經網絡)自動提取高層特征。
遙感指數的概念:
遙感指數是通過?多光譜波段計算?的定量指標,用于增強特定地物信息,例如:
NDVI(歸一化植被指數):(NIR?Red)/(NIR+Red)(NIR?Red)/(NIR+Red),監測植被健康。
NDWI(歸一化水體指數):(Green?NIR)/(Green+NIR)(Green?NIR)/(Green+NIR),提取水體。
NDBI(歸一化建筑指數):(SWIR?NIR)/(SWIR+NIR)(SWIR?NIR)/(SWIR+NIR),識別城市建筑。
文本數據挖掘的概念:
文本數據挖掘(Text Mining)?是指從非結構化或半結構化文本數據中自動提取有價值的信息、模式和知識的過程。它結合了自然語言處理(NLP)、機器學習(ML)和統計學?方法,用于分析大規模文本數據,并轉化為結構化信息,以支持決策和分析。例如:
社交媒體分析(如Twitter、微博的災害輿情監測)
地名識別與地理編碼(如從新聞中提取位置信息)
文獻挖掘(如科研論文中的空間趨勢分析)
文本數據挖掘面臨的挑戰:
非結構化數據:文本格式多樣(如縮寫、方言)。
空間隱含性:如“北京暴雨”需關聯地理坐標。
多語言處理:全球數據需跨語言分析。
實時性要求:如災害事件的快速輿情分析。
信息要素的類型:
空間數據:位置、形狀(點、線、面)。
屬性數據:描述性信息(如人口、土地利用類型)。
時間數據:時序變化(如城市擴張動態)。
關系數據:拓撲關系(如相鄰、包含)。
地理編碼的概念:
地理編碼指將地名的詳細地址以地理坐標(如經緯度)表示的過程。其中,將地址信息映射為地理坐標的過程稱之為地理編碼;將地理坐標轉換為地址信息的過程稱之為逆地理編碼。
元數據的概念:
描述數據的數據,用于?數據共享與管理,例如:
遙感影像元數據:成像時間、傳感器類型、空間分辨率。
GIS數據元數據:坐標系、數據來源、字段說明。
網頁數據采集方法:
API 調用:如Twitter API、Google Maps API。
網絡爬蟲(Web Scraping):Scrapy、BeautifulSoup。
地理空間數據采集:OpenStreetMap(OSM)數據下載。
實時數據流:MQTT、Kafka(如氣象傳感器數據)。
)








從連續到離散:雙積分小車狀態空間的數字實現)




的調用)



![[GESP202312 五級] 烹飪問題](http://pic.xiahunao.cn/[GESP202312 五級] 烹飪問題)
)