1.Hudi應用場景
面對海量數據開發場景,一種支持存儲多種原始數據格式、多種計算引擎、高效的元數據統一管理的存儲方式能極大的提高開發效率。所以在選擇技術選型的時候,這種存儲方式有以下幾個特點:
-
存儲原始數據,這些原始數據來源非常豐富(結構化,非結構化);
-
支持多種計算模型;
-
完善的數據管理能力,要能做到多種數據源接入,實現不同數據之間的連接;
-
靈活的底層存儲,一般用 hdfs 這種廉價的分布式文件系統。
本文會向大家介紹Hudi是如何具備上面集中優勢的。但是Hadoop的技術棧那么復雜、而且Hudi也是近幾年剛興起的技術,為什么還要推薦大家使用Hudi?在這里總結了一下幾點:
-
Hudi對數據的讀取有獨特的優點,它能夠幫助合并DFS上的最小文件,解決了HDFS和云存儲上的小文件問題,能夠顯著提高查詢性能。
-
Hudi提供了刪除存儲在數據湖中數據的能力,可以通過Merge on Read的方式來處理輔助鍵隨機刪除所導致的寫放大(只要 Partition 內有消息變更都需要覆蓋重寫)。
-
Hudi使用細粒度的文件/記錄級別索引來支持Update/Delete記錄,同時還提供寫操作的事務保證。查詢會處理最后一個提交的快照。
-
Hudi對獲取數據變更提供了很好的支持:可以從給定的時間點獲取給定表中updated/inserted/deleted的所有記錄的增量流。
總的來說,它是一種針對分析型業務的、掃描優化的數據存儲抽象,它能夠使DFS數據集在分鐘級的時延內支持變更,也支持下游系統對這個數據集的增量處理。
2.數據入湖橋梁-FlinkCDC
目前 數據庫的數據導入數據湖可以通過 CDC connector 一次性將全量和增量數據導入到 Hudi 格式中;也可以通過消費 Kafka 上的 CDC changelog,通過 Flink 的 CDC format 將數據導入到 Hudi 格式。
CDC 的全稱是 Change Data Capture ,在廣義的概念上,只要是能捕獲數據變更的技術,我們都可以稱之為 CDC 。
又細分為基于直連查詢的 CDC和基于Binlog的 CDC。
| 對比點 | 基于直連查詢的CDC | 基于Binlog的 CDC |
|---|---|---|
| 是否可以捕獲所有數據變換 | 否 | 是 |
| 延遲性能 | 高延遲 | 低延遲 |
| 執行模式 | Batch 批處理 | Streaming流處理 |
| 對數據庫的壓力 | 壓力較大 | 壓力較小 |
| 開源產品 | kafka JDBC source | Canal |
以下是之前的mysql binlog日志處理流程,例如canal監聽binlog把日志寫入到kafka中。 Flink實時消費Kakfa的數據實現mysql數據的同步,整體上可以分為以下幾個階段。
-
1.mysql開啟binlog
-
2.canal同步binlog數據寫入到kafka
-
3.flink讀取kakfa中的binlog數據進行相關的業務處理。
整體的處理鏈路較長,需要用到的組件也比較多。 Apache Flink CDC可以直接從數據庫獲取到binlog供下游進行業務計算分析。

也就是說數據不再通過canal與kafka進行同步,而flink直接進行處理mysql的數據。節省了canal與kafka的過程。
3.hudi結構介紹
hudi將一個表映射為如下文件結構:
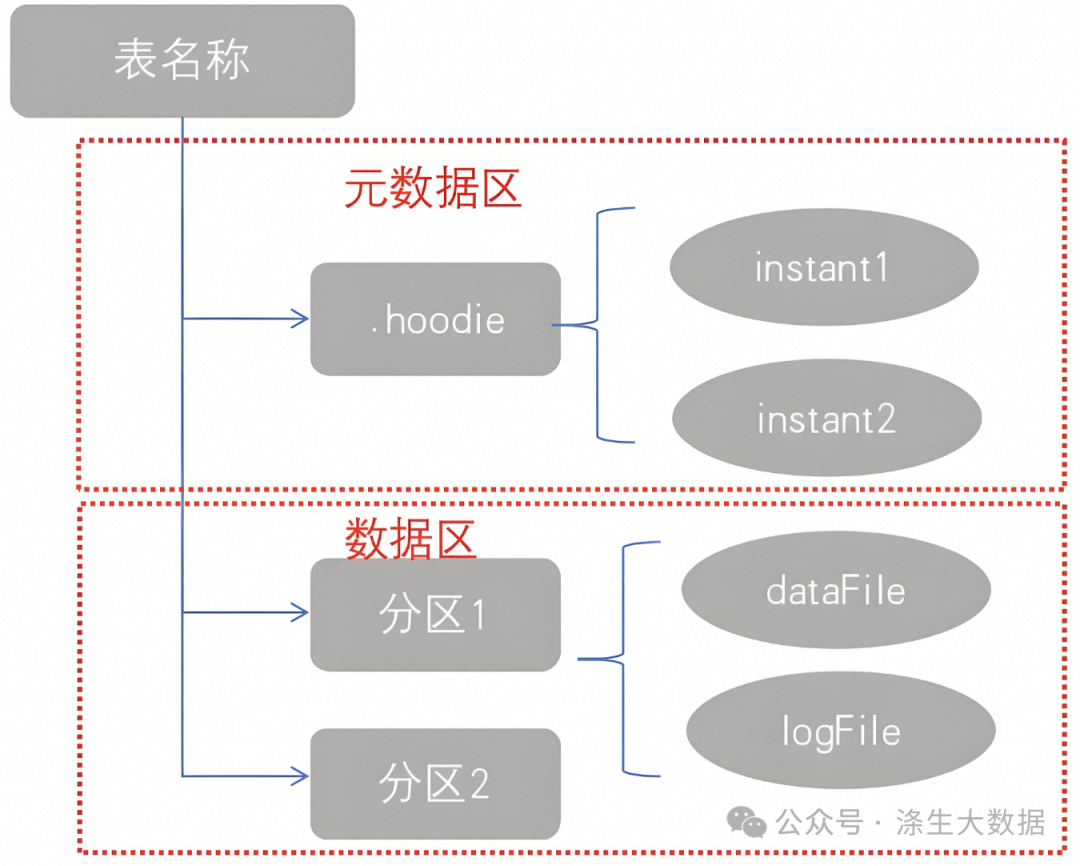
Hudi存儲分為兩個部分:元數據區、數據區。
3.1 元數據
hoodie目錄對應著表的元數據信息,包括表的版本管理(Timeline)、歸檔目錄(存放過時的instant也就是版本),一個instant記錄了一次提交(commit)的行為、時間戳和狀態,hudi以時間軸的形式維護了在數據集上執行的所有操作的元數據;
由于它維護著一條所有操作的不同 Instant組成的 Timeline(時間軸),通過時間軸,用戶可以輕易的進行增量查詢或基于某個歷史時間點的查詢。
Timeline格式:
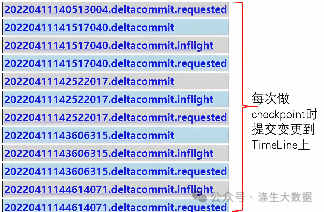
一個Instant的組成包括:
state
狀態:目前包括REQUESTED(已調度但未初始化)、INFLIGHT(當前正在執行)、COMPLETED(操作執行完成),狀態會轉變,如當提交完成時會從 inflight狀態轉變為 completed狀態。
action操作
對數據集執行的操作類型,如 commit、 deltacommit等:
提交(commit):一次提交表示將一批記錄原子寫入數據集中的過程。
增量提交(delta_commit) :增量提交是指將一批記錄原子寫入到MOR表中,其中數據都將只寫入到日志中。
清理(clean):清理數據集中不再被查詢中使用的文件的較舊版本。
壓縮(compaction):將MOR表中多個log文件進行合并,用以減小數據存儲,本質是將行式文件轉化為列式文件的動作。
timestamp:開始 一個Instant發生的時間戳,Hudi會保證單調遞增。
3.2 數據區
-
數據文件/基礎文件:Hudi將數據以列存格式(Parquet)存放,稱為數據文件/基礎文件。
-
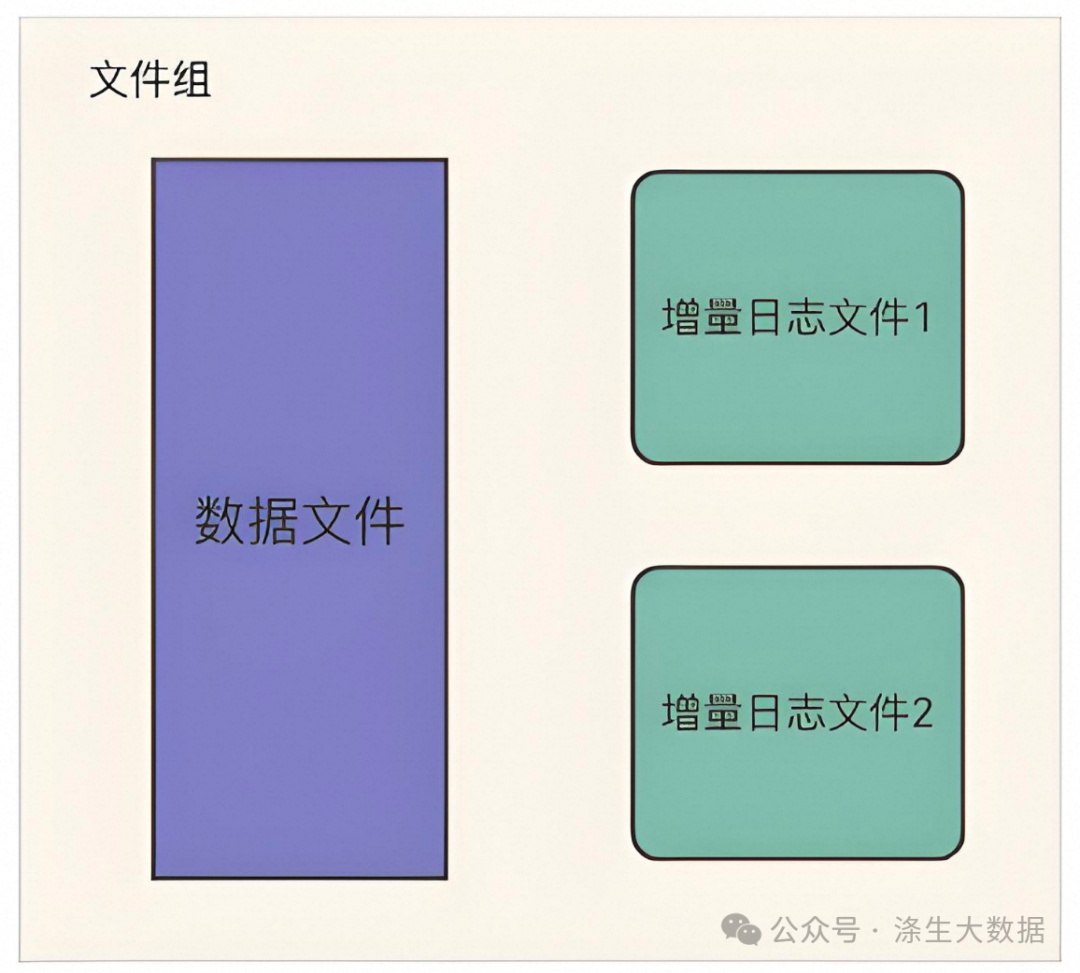
增量日志文件: 在 MOR 表格式中,更新被寫入到增量日志文件中,該文件以 avro 格式存儲。 這些增量日志文件始終與基本文件相關聯。假設有一個名為 data_file_1 的數據文件,對 data_file_1 中記錄的任何更新都將寫入到新的增量日志文件。在服務讀取查詢時,Hudi 將實時合并基礎文件及其相應的增量日志文件中的記錄。
-
文件組(FileGroup):通常根據存儲的數據量,可能會有很多數據文件。 每個數據文件及其對應的增量日志文件形成一個文件組。 在 COW表中,只有基本文件。
-
文件版本:比如COW表每當數據文件發生更新時,將創建數據文件的較新版本,其中包含來自較舊數據文件和較新傳入記錄的合并記錄。
-
文件切片(FileSlice):對于每個文件組,可能有不同的文件版本。 因此文件切片由特定版本的數據文件及其增量日志文件組成。 對于 COW表,最新的文件切片是指所有文件組的最新數據/基礎文件。 對于 MOR表,最新文件切片是指所有文件組的最新數據/基礎文件及其關聯的增量日志文件。
4.Flink Hudi的批流一體
4.1 hudi表介紹
hudi支持兩種表類型:Copy On Write(COW) & Merge On Read(MOR)。
COW表:在數據寫入的時候,通過復制舊文件數據并且與新寫入的數據進行合并,對 Hudi 的每一個新批次寫入都將創建相應數據文件的新版本。
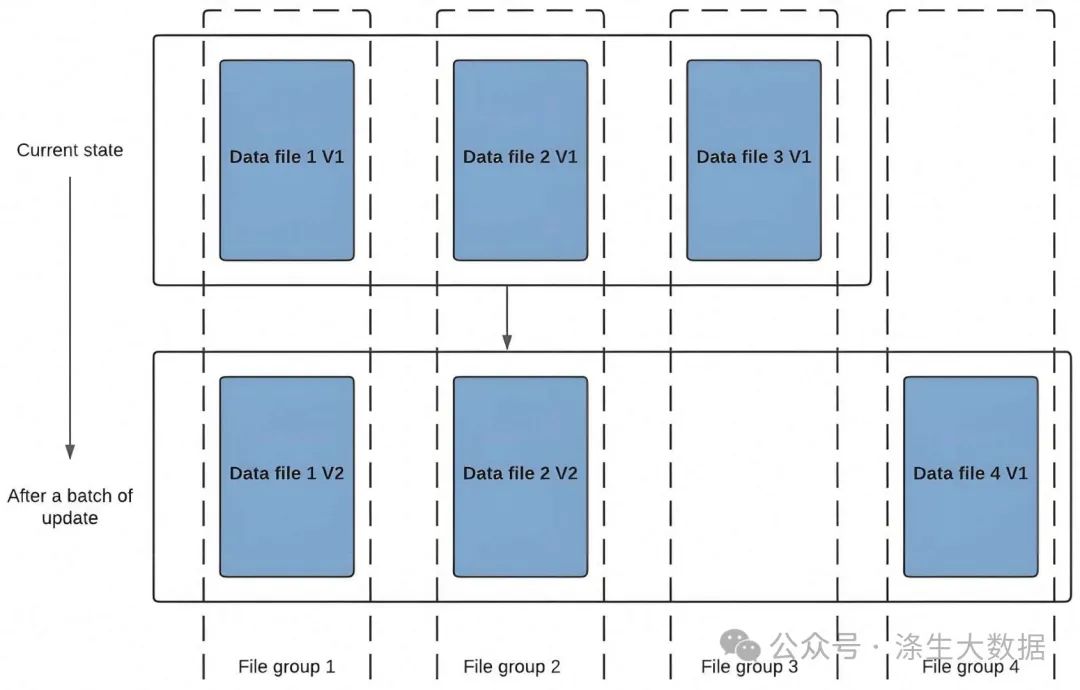
data_file1 和 data_file2 都將創建更新的版本,data file 1 V2 是數據文件 data file 1 V1 的內容與數據文件data file 1 中傳入批次匹配記錄的記錄合并。 由于在寫入期間進行合并,COW 會產生一些寫入延遲。 但是COW 的優勢在于它的簡單性。
MOR表:對于具有要更新記錄的現有數據文件,Hudi 創建增量日志文件記錄更新數據。此在寫入期間不會合并或創建較新的數據文件版本;在進行數據讀取的時候,將本批次讀取到的數據進行Merge。Hudi 使用壓縮機制來將數據文件和日志文件合并在一起并創建更新版本的數據文件。
COW表和MOR表優勢對比:
COW適用于讀多寫少的場景,MOR適用于寫多讀少的場景。
| 對比點 | COW | MOR | 說明 |
|---|---|---|---|
| 更新代價 | 高 | 低 | COW為每批次寫入都會創建更新的數據文件,所以cow的I/O成本高,而MOR更新增量日志文件,其I/O成本低。 |
| 讀取延遲 | 低 | 一般 | COW在寫入就進行了合并,與Cow相比的話,MOR延遲較高。 |
| 寫放大問題 | 高 | 低 | 假設有一個大小為100MB的數據文件,并且每次更新10%的記錄進行4批次寫入,4次寫入之后,Hudi將會存儲5個大小為100Mb的COW數據文件,MOR在4次寫入后,將有1*100MB的文件和4個增量日志文件(10MB)的大小約140MB; |
4.2 hudi表寫入原理介紹
分為三個模塊:數據寫入、數據壓縮與數據清理。
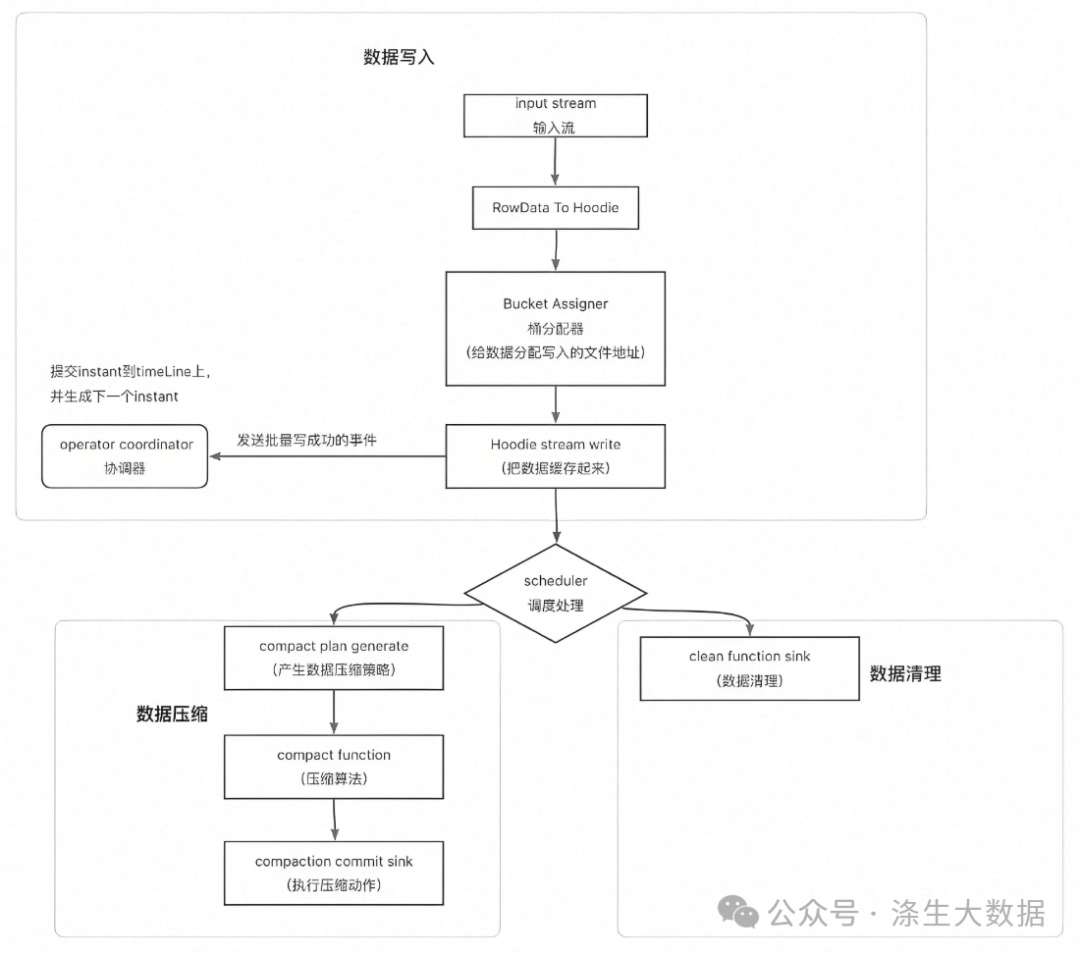
4.2.1 數據寫入
(1)基礎數據封裝:將數據流中flink的RowData封裝成Hoodie實體;
(2)BucketAssigner:桶分配器,主要是給數據分配寫入的文件地址:
(3)Hoodie Stream Writer: 數據寫入,將數據緩存起來,在超過設置的最大flushSize時進行刷新到文件中;
(4)Oprator Coordinator:主要與Hoodie Stream Writer進行交互,提交instant到timeLine上,并生成下一個instant的時間。
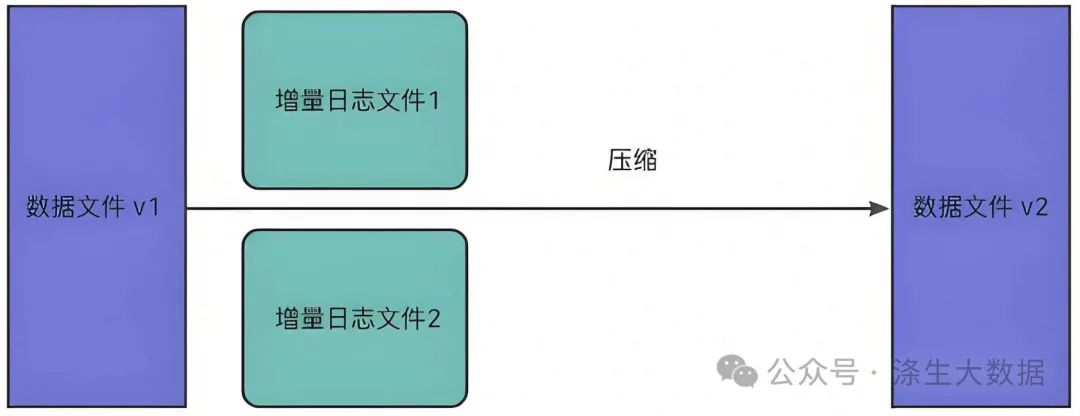
4.2.2 數據壓縮
壓縮( compaction)用于在 MergeOnRead存儲類型時將基于行的log日志文件轉化為parquet列式數據文件,用于加快記錄的查找。
compaction首先會遍歷各分區下最新的parquet數據文件和其對應的log日志文件進行合并,并生成新的FileSlice,在TimeLine 上提交新的Instant:
4.3 hudi表讀取介紹
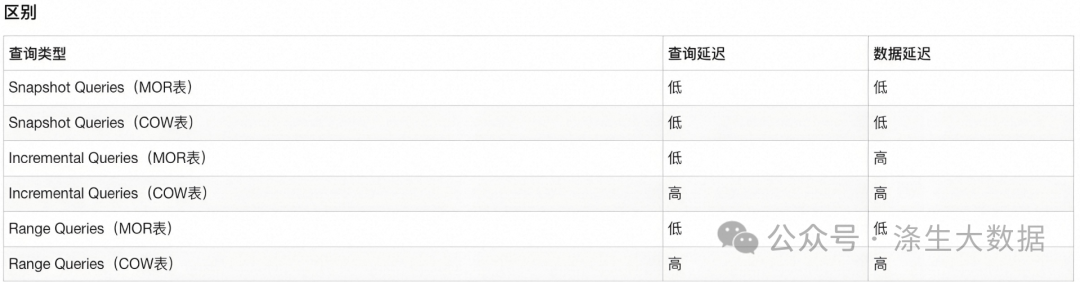
Hudi支持如下三種查詢類型:
快照讀(Snapshot Queries)
-
MOR表查詢:在MOR模式下,Hudi在寫入時將數據寫入到可變的數據文件中,這些文件稱為日志文件。當文件大小達到一定閾值時,Hudi會將這些日志文件歸檔到一個不可變的數據文件中。這些不可變的數據文件稱為快照文件。因此,在MOR模式下,Hudi的查詢快照實際上是查詢這些快照文件。由于MOR表的數據文件是可變的,因此如果一個數據文件中的數據被更新,那么這個更新不會影響已經歸檔為快照文件的數據文件。因此,在查詢MOR表的快照時,Hudi需要同時查詢所有的數據文件和快照文件,以確保查詢結果的正確性。
-
COW表查詢:在COW模式下,Hudi在寫入時將數據寫入到不可變的數據文件中,這些文件稱為快照文件。當有更新發生時,Hudi會將更新寫入一個新的數據文件中,并將這個新的數據文件作為新的快照文件。因此,在COW模式下,Hudi的查詢快照實際上是查詢這些快照文件。由于COW表的數據文件是不可變的,因此如果一個數據文件中的數據被更新,那么這個更新會生成一個新的數據文件,而不是更新原始的數據文件。因此,在查詢COW表的快照時,Hudi只需要查詢最新的快照文件即可,不需要查詢舊的數據文件。這種方式可以提高查詢性能。
增量讀(Incremental Queries)
-
對于MOR表,增量查詢可以直接在Hudi數據集中運行。這種查詢類型可以在Hudi數據集中基于增量數據執行查詢。MOR表中,每個數據文件都包含了最近一次寫操作之后的所有更改。這意味著,如果在兩個查詢之間執行了一些寫操作,則下一個查詢將只考慮這些更改,并自動過濾掉之前的數據。
-
對于COW表,增量查詢需要從歷史數據中進行計算。在這種情況下,Apache Hudi需要將之前的數據文件加載到內存中,并計算增量數據。
優化讀(Read Optimized Queries)
-
對于MOR表,可以使用時間戳或者Hudi記錄中的默認時間戳進行Range查詢,以查詢特定時間范圍內的數據。Apache Hudi會自動選擇包含所需時間范圍的文件版本,并返回該時間范圍內的數據。
-
對于COW表,同樣可以使用時間戳或默認時間戳進行Range查詢。但由于COW表在每次寫操作中都會創建一個全新的文件版本,因此Apache Hudi需要加載所有歷史數據,并計算出特定時間范圍內的數據。在這種情況下,COW表的查詢時間可能會比MOR表更長。
5.hudi vs Iceberg 數據更新能力
5.1 Iceberg 數據更新
Iceberg 的官方定位是「面向海量數據分析場景的高效存儲格式」。所以它沒有像 Hudi 一樣模擬業務數據庫的設計模式(主鍵+索引)來實現數據更新,而是設計了更強大的文件組織形式來實現數據的 update 操作,詳見下圖:
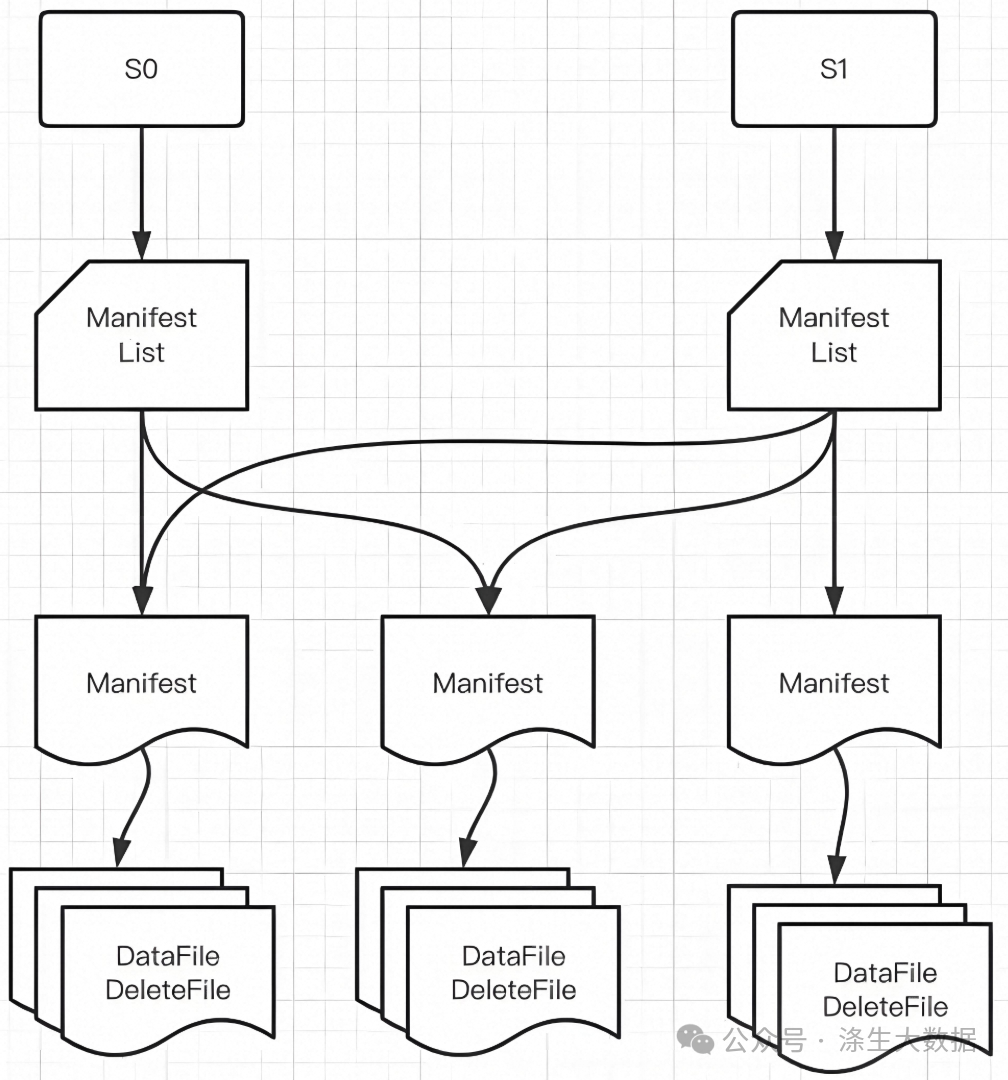
s0,s1代表的是當前操作的一個快照,每次commit都會生成一個快照Snapshot,每個Snapshot快照對應一個manifest list元數據文件組,每個manifest list中包含多個Manifest元數據文件,maifest中記錄了當前操作生成數據所對應的文件地址,也就是data file地址。
Data files(數據文件)
數據文件是Apache Iceberg表真實存儲數據的文件,一般是在表的數據存儲目錄的data目錄下,如果我們的文件格式選擇的是parquet,那么文件是以“.parquet”結尾,Iceberg每次更新會產生多個數據文件。
Snapshot(表快照)
快照代表一張表在某個時刻的狀態,每個快照里面會列出表在某個時刻的所有Data files 列表。Data files存儲在不同的Manifest files里面,Manifest files存儲在一個Manifest list文件里面,而一個Manifest list文件代表一個快照。
Manifest file(清單文件)
Manifest file是一個元數據文件,它列出組成快照(Snapshot)的數據文件(Data files)的列表信息。每行都是每個數據文件的詳細描述,包括數據文件的狀態、文件路徑、分區信息、列級別的統計信息(比如每列的最大最小值、空值數等)、文件的大小以及文件里面數據行數等信息。
Manifest list(清單列表)
Manifest list也是一個元數據文件,它列出構建表快照(Snapshot)的清單。這個元數據文件中存儲的是Manifest file列表,每個Manifest file占據一行。每行中存儲了Manifest file的路徑、其存儲的數據文件(Data files)的分區范圍,增加了幾個數文件、刪除了幾個數據文件等信息,這些信息可以用來在查詢時提供過濾,加快速度。
Iceberg 實現 update 的大致邏輯是:先將要刪除的數據寫入 Delete File;然后將「Data File」 JOIN 「Delete File」進行數據比對,實現數據更新。
5.2 hudi 數據更新
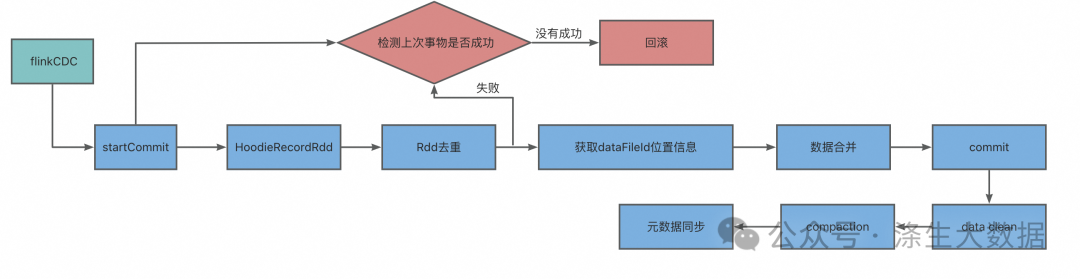
如圖所示,filink cdc寫入Hudi,Upsert執行核心操作如下:
-
開始提交:判斷上次任務是否失敗,如果失敗會觸發回滾操作。然后會根據當前時間生成一個事務開始的請求標識元數據。
-
構造HoodieRecord Rdd對象:Hudi會根據元數據信息構造HoodieRecord Rdd對象,方便后續數據去重和數據合并。
-
數據去重:一批增量數據中可能會有重復的數據,Hudi會根據主鍵對數據進行去重,避免重復數據寫入Hudi表。
-
數據fileId位置信息獲取:在修改記錄中可以根據索引獲取當前記錄所屬文件的fileld,因數據合并時Update操作需要知道向哪個fileid文件寫入新的快照文件。
-
數據合并:在COW表模式中會重寫索引命中的fileId快照文件;在MOR表模式中根據fileId追加到分區中的log文件。
-
完成提交:在元數據中生成xxxx.commit文件,只有生成commit元數據文件,查詢引擎才能根據元數據查詢到剛剛Upsert后的數據。
-
數據清理:用于刪除舊的文件片,以及限制表空間的增長,清理操作在每次寫操作之后自動被執行,同時利用緩存在TimeLine Server上的TimeLine Metadata來防止掃描整個表。
-
Compaction壓縮:主要是MOR模式中才會用到,會將MOR模式中的xxx.log數據合并到xxx.parquet快照文件中去。
5.3 對比總結
Hudi 憑借文件組+索引+主鍵的設計模式,能夠有效減少數據文件的冗余更新,提高數據更新效率。而Iceberg 通過文件組織設計也能達到數據更新效果,但是每一次的 commit 都會產生新的文件,如果寫入/更新頻繁,小文件問題會比較嚴重。










的應用:破解傳統 TF 卡振動脫落與壽命短板)





上報到AppsFlyer)


