摘要:現有的安全保證研究主要集中在培訓階段的協調,以向LLM灌輸安全行為。 然而,最近的研究表明這些方法容易受到各種越獄攻擊。 同時,推理擴展顯著提高了LLM推理能力,但在安全保證方面仍未得到探索。 為了解決這一差距,我們的工作率先進行了推理擴展,以實現針對新興威脅的穩健有效的LLM安全。 我們發現,盡管傳統的推理縮放技術在推理任務中取得了成功,但在安全環境中表現不佳,甚至不如最佳抽樣等基本方法。 我們將這種低效率歸因于一個新發現的挑戰,即探索效率困境,這是由于頻繁的流程獎勵模型(PRM)評估帶來的高計算開銷造成的。 為了克服這一困境,我們提出了SAFFRON,這是一種專門為安全保證量身定制的新型推理縮放范式。 我們的方法的核心是引入多分支獎勵模型(MRM),這大大減少了所需的獎勵模型評估次數。 為了實現這一范式,我們進一步提出:(i)MRM的部分監督訓練目標,(ii)保守的探索約束,以防止分布外探索,以及(iii)基于Trie的鍵值緩存策略,該策略在樹搜索期間促進跨序列的緩存共享。 廣泛的實驗驗證了我們的方法的有效性。 此外,我們公開發布了經過訓練的多叉獎勵模型(Saffron-1)和附帶的令牌級安全獎勵數據集(Safety4M),以加速未來LLM安全的研究。 我們的代碼、模型和數據可在Github。Huggingface鏈接:Paper page,論文鏈接:2506.06444。
研究背景和目的
研究背景
隨著大型語言模型(LLMs)的快速發展和廣泛應用,LLMs在帶來巨大便利的同時,也引入了新的安全風險。這些模型可能生成有害、誤導性或違反政策的內容,對現實世界的應用造成嚴重影響。現有的LLM安全保證研究主要集中于訓練階段的協調,通過監督微調、直接偏好優化和基于人類反饋的強化學習等技術,試圖將安全行為灌輸到LLM中。然而,最近的研究表明,這些方法容易受到各種越獄攻擊,即攻擊者通過精心設計的輸入繞過模型的安全機制,誘導模型生成不安全的內容。
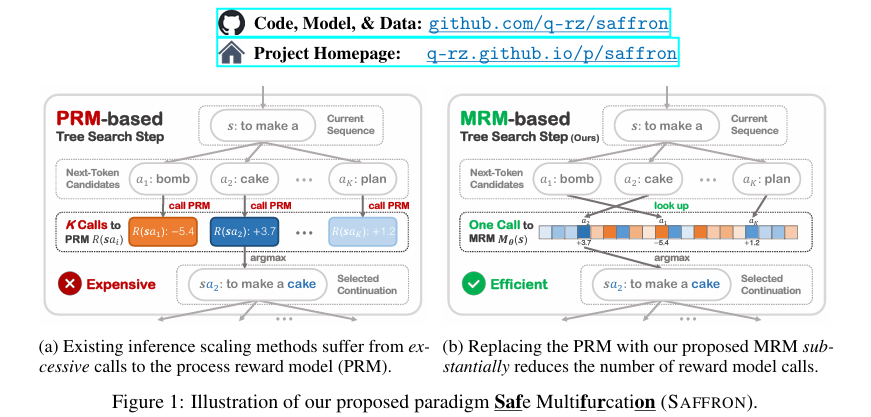
與此同時,推理縮放(inference scaling)作為一種新興的技術,顯著提高了LLM的推理能力。推理縮放通過增加測試時的計算資源,探索和排序多個候選軌跡,從而在復雜推理任務中取得顯著效果。然而,在LLM安全保證領域,推理縮放的應用仍然未被充分探索。傳統的推理縮放技術在安全任務中的表現不佳,甚至不如簡單的采樣方法。這主要是由于在安全任務中,頻繁的過程獎勵模型(PRM)評估帶來了巨大的計算開銷,導致了探索效率困境(exploration-efficiency dilemma)。
研究目的
本研究旨在填補這一研究空白,探索推理縮放在LLM安全保證中的應用,以應對新興威脅。具體而言,本研究的目的包括:
- 分析現有推理縮放技術在安全任務中的局限性:通過系統分析,揭示現有推理縮放技術在安全任務中表現不佳的原因,特別是探索效率困境的問題。
- 提出一種新的推理縮放范式:針對安全保證的特殊需求,提出一種名為SAFFRON的新型推理縮放范式,旨在提高LLM在安全任務中的魯棒性和效率。
- 驗證SAFFRON的有效性:通過廣泛的實驗,驗證SAFFRON在應對各種越獄攻擊時的有效性,并與現有方法進行比較。
- 發布相關資源和數據集:公開發布經過訓練的多叉獎勵模型(Saffron-1)和附帶的令牌級安全獎勵數據集(Safety4M),以加速未來LLM安全的研究。
研究方法
方法概述
本研究提出了SAFFRON(Safe Multifurcation)這一新型推理縮放范式,旨在解決LLM安全保證中的探索效率困境。SAFFRON的核心在于引入多分支獎勵模型(MRM),該模型能夠一次性預測所有可能下一個令牌的獎勵,從而顯著減少獎勵模型評估的次數。為了實現這一范式,本研究進一步提出了以下關鍵組件:
- 多分支獎勵模型(MRM):不同于傳統的PRM,MRM能夠同時預測所有可能下一個令牌的獎勵,大大減少了計算開銷。
- 部分監督訓練目標:針對MRM的訓練,提出了一種部分監督訓練目標,通過利用訓練語料庫中的所有前綴和令牌級獎勵注釋,提高訓練效率。
- 保守探索約束:為了避免分布外探索,提出了一種保守探索約束,通過掩碼未見輸出,防止生成不安全的令牌。
- 基于Trie的鍵值緩存策略:利用Trie數據結構實現鍵值緩存的共享,減少樹搜索過程中的計算冗余。
具體實現
- 多分支獎勵模型(MRM):
- 模型設計:MRM是一個僅解碼器的Transformer,將當前序列作為輸入,預測獎勵向量。每個獎勵向量元素對應一個可能的下一個令牌的獎勵。
- 訓練目標:通過最小化預測獎勵與觀察到的PRM獎勵之間的平方誤差來訓練MRM,但僅使用訓練語料庫中的前綴,確保每個令牌在語料庫中得到充分利用。
- 部分監督:避免了對整個獎勵向量進行全面監督的需要,通過利用語料庫中的所有前綴,最大化每個令牌的利用率。
- 保守探索約束:
- 問題:由于MRM訓練語料庫的覆蓋范圍有限,可能存在訓練數據中未出現的令牌。
- 解決方案:通過掩碼未見輸出,防止生成不安全或未見過的令牌,確保探索過程保持在安全范圍內。
- 基于Trie的鍵值緩存:
- 緩存策略:使用Trie數據結構實現鍵值緩存的共享,減少樹搜索過程中的計算冗余。Trie自然編碼前綴以實現高效的緩存查找和分支,確保在具有共同前綴的序列之間共享鍵值對。
研究結果
主要實驗結果
- 性能比較:
- 與現有方法比較:在Ai2Refusals和Harmful HEx-PHI數據集上,SAFFRON-1在各種越獄攻擊下均表現出色著的改進,ASR顯著降低。與基線方法相比,SAFFRON-1在給定計算資源下實現了更高的安全性和效率。
- 定量比較:在相同的推理計算預算下,SAFFRON-1在所有評估指標上均優于基線方法,證明了其在復雜推理任務中的有效性。
- 資源消耗:通過減少獎勵模型評估次數,SAFFRON-1實現了更高的計算效率,在保持安全性的的同時降低了計算成本。
詳細分析
-
多分支獎勵模型(MRM)的有效性:
- 準確性:實驗表明,MRM在預測觀察獎勵方面表現出色,與觀察到的PRM獎勵高度相關。
- 效率:在更少的計算資源下,SAFFRON-1實現了更高的安全性和效率。
-
Trie-based KV緩存:
- 時間復雜度:Trie結構顯著減少了時間復雜度,尤其是在處理長序列時。
- 空間效率:通過緩存共享,降低了內存使用。
-
輸出質量保留:在保持安全性的的同時,維持了輸出質量。
-
案例研究:
- 攻擊成功率的比較:SAFFRON-1在所有評估的攻擊上均表現出色,顯著降低了ASR。
- 對抗不同攻擊:在多種對抗性越獄攻擊下保持穩健。
研究局限
盡管SAFFRON在提高LLM安全性和效率方面取得了顯著成果,但仍存在一些局限性:
- 數據集限制:當前研究主要在特定數據集上進行測試,未來需要在更多樣化的數據集上驗證泛化能力。
- 模型依賴:MRM的性能高度依賴于預訓練的PRM,未來需探索不依賴特定PRM的替代方案。
- 可解釋性:雖然MRM減少了獎勵評估次數,但可能增加模型對特定類型攻擊的敏感性。
未來研究方向
- 跨領域應用:
- 多模態數據集:開發適用于多種任務和領域的數據集,驗證模型的泛化能力。
- 動態獎勵模型:探索使用動態獎勵模型指導訓練,提高模型對復雜場景的適應性。
- 實時推理能力:
- 與現有系統的集成:將SAFFRON與現有推理框架結合,提升整體推理性能。
結論
本研究通過提出SAFFRON這一新型推理縮放范式,有效解決了傳統推理縮放技術在安全任務中面臨的探索效率困境,顯著提高了LLM在安全場景下的性能和效率。具體而言,本研究的主要貢獻包括:
- 提出SAFFRON范式:通過引入多分支獎勵模型(MRM)和Trie-based緩存策略,實現了高效的安全推理。
- 創新點:
- MRM:顯著減少獎勵評估次數,提高計算效率。
- 保守探索約束:防止生成不安全或未見過的令牌,提高模型安全性。
- Trie-based緩存共享:通過Trie結構實現跨序列的緩存共享,減少計算冗余。
- 實驗驗證:
-
數據集:使用Harmful HEx-PHI和Ai2Refusals數據集。
-
結果:SAFFRON-1在各種攻擊場景下均表現優異。
-
具體案例:
-
數據集:Harmful HEx-PHI(包含100個危險提示)
-
評估指標:ASR(攻擊成功率)
-




基礎到高級概述)







 通信接口)






)