在電商平臺中,基于用戶的協同過濾推薦算法是一種常見的推薦系統方法。它通過分析用戶之間的相似性來推薦商品。以下是一個簡單的實現思路和示例代碼,使用Java語言。
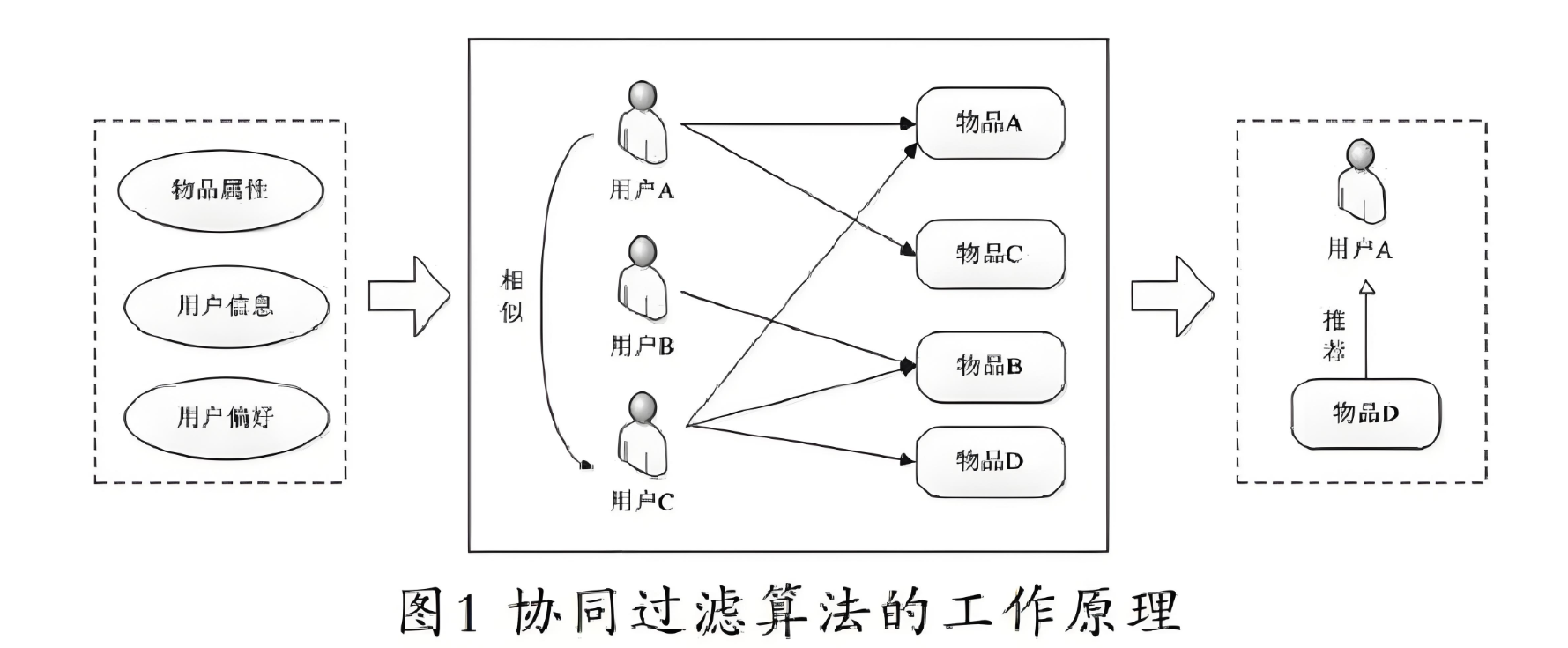
實現思路
- 數據準備:收集用戶的評分數據,通常以用戶-商品評分矩陣的形式存儲。
- 計算相似度:使用余弦相似度或皮爾遜相關系數等方法計算用戶之間的相似度。
- 生成推薦:根據相似用戶的評分,預測目標用戶對未評分商品的評分,并進行推薦。
1. 算法核心思想
基于用戶的協同過濾通過以下步驟工作:
-
計算用戶之間的相似度
-
找到與目標用戶最相似的K個用戶
-
根據這些相似用戶的喜好預測目標用戶可能喜歡的商品
-
推薦預測評分最高的N個商品
?2.Java實現代碼
import java.util.*;public class UserBasedCF {// 用戶-商品評分矩陣private Map<Integer, Map<Integer, Double>> userItemRatingMatrix;// 用戶相似度矩陣private Map<Integer, Map<Integer, Double>> userSimilarityMatrix;// 商品-用戶倒排表private Map<Integer, Set<Integer>> itemUserInverseTable;public UserBasedCF() {userItemRatingMatrix = new HashMap<>();userSimilarityMatrix = new HashMap<>();itemUserInverseTable = new HashMap<>();}/*** 添加用戶評分數據* @param userId 用戶ID* @param itemId 商品ID* @param rating 評分*/public void addRating(int userId, int itemId, double rating) {// 添加到用戶-商品矩陣userItemRatingMatrix.putIfAbsent(userId, new HashMap<>());userItemRatingMatrix.get(userId).put(itemId, rating);// 添加到商品-用戶倒排表itemUserInverseTable.putIfAbsent(itemId, new HashSet<>());itemUserInverseTable.get(itemId).add(userId);}/*** 計算用戶之間的相似度(使用皮爾遜相關系數)*/public void calculateUserSimilarities() {// 獲取所有用戶列表Set<Integer> users = userItemRatingMatrix.keySet();for (int u1 : users) {userSimilarityMatrix.putIfAbsent(u1, new HashMap<>());Map<Integer, Double> u1Ratings = userItemRatingMatrix.get(u1);for (int u2 : users) {if (u1 == u2) continue;Map<Integer, Double> u2Ratings = userItemRatingMatrix.get(u2);// 計算兩個用戶的共同評分商品Set<Integer> commonItems = new HashSet<>(u1Ratings.keySet());commonItems.retainAll(u2Ratings.keySet());if (commonItems.size() < 2) {// 共同評分商品太少,相似度為0userSimilarityMatrix.get(u1).put(u2, 0.0);continue;}// 計算皮爾遜相關系數double sum1 = 0, sum2 = 0;double sum1Sq = 0, sum2Sq = 0;double pSum = 0;for (int item : commonItems) {double r1 = u1Ratings.get(item);double r2 = u2Ratings.get(item);sum1 += r1;sum2 += r2;sum1Sq += Math.pow(r1, 2);sum2Sq += Math.pow(r2, 2);pSum += r1 * r2;}int n = commonItems.size();double num = pSum - (sum1 * sum2 / n);double den = Math.sqrt((sum1Sq - Math.pow(sum1, 2) / n) * (sum2Sq - Math.pow(sum2, 2) / n));double sim = (den == 0) ? 0 : num / den;userSimilarityMatrix.get(u1).put(u2, sim);}}}/*** 為目標用戶推薦商品* @param userId 目標用戶ID* @param k 相似用戶數量* @param n 推薦商品數量* @return 推薦商品ID列表*/public List<Integer> recommendItems(int userId, int k, int n) {if (!userItemRatingMatrix.containsKey(userId)) {return Collections.emptyList();}// 獲取目標用戶已評分的商品Set<Integer> ratedItems = userItemRatingMatrix.get(userId).keySet();// 獲取相似用戶并按相似度排序List<Map.Entry<Integer, Double>> similarUsers = new ArrayList<>(userSimilarityMatrix.get(userId).entrySet());similarUsers.sort((a, b) -> b.getValue().compareTo(a.getValue()));// 取前k個相似用戶if (similarUsers.size() > k) {similarUsers = similarUsers.subList(0, k);}// 計算推薦商品的預測評分Map<Integer, Double> itemPredictions = new HashMap<>();for (Map.Entry<Integer, Double> entry : similarUsers) {int similarUser = entry.getKey();double similarity = entry.getValue();// 獲取相似用戶評過但目標用戶未評的商品Map<Integer, Double> similarUserRatings = userItemRatingMatrix.get(similarUser);for (Map.Entry<Integer, Double> ratingEntry : similarUserRatings.entrySet()) {int item = ratingEntry.getKey();if (!ratedItems.contains(item)) {double rating = ratingEntry.getValue();// 加權評分itemPredictions.merge(item, similarity * rating, Double::sum);}}}// 對預測評分進行歸一化處理for (Map.Entry<Integer, Double> entry : similarUsers) {int similarUser = entry.getKey();double similarity = entry.getValue();Map<Integer, Double> similarUserRatings = userItemRatingMatrix.get(similarUser);for (int item : itemPredictions.keySet()) {if (similarUserRatings.containsKey(item)) {itemPredictions.put(item, itemPredictions.get(item) / Math.abs(similarity));}}}// 按預測評分排序并返回前n個商品List<Map.Entry<Integer, Double>> sortedItems = new ArrayList<>(itemPredictions.entrySet());sortedItems.sort((a, b) -> b.getValue().compareTo(a.getValue()));List<Integer> recommendations = new ArrayList<>();for (int i = 0; i < Math.min(n, sortedItems.size()); i++) {recommendations.add(sortedItems.get(i).getKey());}return recommendations;}// 測試代碼public static void main(String[] args) {UserBasedCF recommender = new UserBasedCF();// 模擬用戶評分數據recommender.addRating(1, 101, 5.0);recommender.addRating(1, 102, 3.0);recommender.addRating(1, 103, 2.5);recommender.addRating(2, 101, 2.0);recommender.addRating(2, 102, 2.5);recommender.addRating(2, 103, 5.0);recommender.addRating(2, 104, 2.0);recommender.addRating(3, 101, 2.5);recommender.addRating(3, 104, 4.0);recommender.addRating(3, 105, 4.5);recommender.addRating(3, 107, 5.0);recommender.addRating(4, 101, 5.0);recommender.addRating(4, 103, 3.0);recommender.addRating(4, 104, 4.5);recommender.addRating(4, 106, 4.0);recommender.addRating(4, 107, 2.0);// 計算用戶相似度recommender.calculateUserSimilarities();// 為用戶1推薦2個商品List<Integer> recommendations = recommender.recommendItems(1, 2, 2);System.out.println("為用戶1推薦的商品: " + recommendations);}
}?3. 代碼說明
-
數據結構:
-
userItemRatingMatrix: 存儲用戶對商品的評分 -
userSimilarityMatrix: 存儲用戶之間的相似度 -
itemUserInverseTable: 商品到用戶的倒排表,加速計算
-
-
核心方法:
-
addRating(): 添加用戶評分數據 -
calculateUserSimilarities(): 計算用戶相似度(使用皮爾遜相關系數) -
recommendItems(): 為目標用戶生成推薦列表
-
-
推薦過程:
-
找到與目標用戶最相似的K個用戶
-
收集這些相似用戶評價過但目標用戶未評價的商品
-
計算這些商品的預測評分(加權平均)
-
返回評分最高的N個商品作為推薦
-
4. 實際應用中的優化建議
-
數據稀疏性問題:
-
實現降維技術(如SVD)
-
使用混合推薦方法(結合基于內容的推薦)
-
-
性能優化:
-
使用稀疏矩陣存儲數據
-
實現增量更新機制,避免全量計算
-
使用MapReduce或Spark進行分布式計算
-
-
冷啟動問題:
-
對于新用戶,可以使用熱門商品推薦
-
對于新商品,可以使用基于內容的推薦
-
-
業務適配:
-
考慮時間衰減因素(最近的評分權重更高)
-
加入業務規則過濾(如庫存、價格區間等)
-






)


:基于 PyTorch 的手寫體識別案例手冊)

頻率求解與仿真實踐(2))

)
,Hadoop, Spark, Hive 的關系)



)
