TL;DR:MultiTalk 是一種音頻驅動的多人對話視頻生成。它支持多人對話💬、唱🎤歌、交互控制和👬卡通🙊的視頻創建。
視頻演示
| ?001.mp4? | ?004.mp4? | ?003.mp4? |
| ?002.mp4? | ?005.mp4? | ?006.mp4? |
| ?003.mp4? | ?002.mp4? | ?003.mp4? |
? 主要特點
我們提出了?MultiTalk?,一種用于音頻驅動的多人對話視頻生成的新穎框架。給定一個多流音頻輸入、一個參考圖像和一個提示,MultiTalk 會生成一個視頻,其中包含跟隨提示的交互,并與音頻保持一致的嘴唇動作。
- 💬?真實的對話?- 支持單人和多人生成
- 👥?交互式角色控制?- 通過提示引導虛擬人
- 🎤?泛化表演?- 支持生成卡通人物和歌唱
- 📺?分辨率靈活性:任意縱橫比下的480p和720p輸出
- ???長視頻生成:支持最長 15 秒的視頻生成
🧱模型準備
1. 模型下載
| 模型 | 下載鏈接 | 筆記 |
|---|---|---|
| 廣域網2.1-I2V-14B-480P | 🤗?擁抱臉 | 基本模型 |
| 中文-WAV2VEC2-基 | 🤗?擁抱臉 | 音頻編碼器 |
| 美原-MultiTalk | 🤗?擁抱臉 | 我們的音頻條件權重 |
使用 huggingface-cli 下載模型:
huggingface-cli download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480P huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base huggingface-cli download MeiGen-AI/MeiGen-MultiTalk --local-dir ./weights/MeiGen-MultiTalk
2. 將 MultiTalk 模型鏈接或復制到 wan2.1-I2V-14B-480P 目錄
鏈接方式:
mv weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json_old
sudo ln -s {Absolute path}/weights/MeiGen-MultiTalk/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/
sudo ln -s {Absolute path}/weights/MeiGen-MultiTalk/multitalk.safetensors weights/Wan2.1-I2V-14B-480P/
或者,通過以下方式復制:
mv weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json_old
cp weights/MeiGen-MultiTalk/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/
cp weights/MeiGen-MultiTalk/multitalk.safetensors weights/Wan2.1-I2V-14B-480P/
🔑 快速推理
我們的型號兼容 480P 和 720P 分辨率。當前代碼僅支持 480P 推理。720P 推理需要多個 GPU,我們將很快提供更新。
一些提示
- 唇形同步精度: 音頻 CFG 在 3-5 之間效果最佳。增加音頻 CFG 值以獲得更好的同步。
- 視頻剪輯長度:該模型以 25 FPS 的速度在 81 幀視頻上進行訓練。為了獲得最佳的提示跟隨性能,請在 81 幀處生成剪輯。最多可以生成 201 幀,但較長的剪輯可能會降低提示跟隨性能。
- 長視頻生成:音頻 CFG 會影響各段落之間的色調一致性。將此值設置為 3 可減輕色調變化。
- 采樣步驟:如果你想快速生成視頻,你可以將采樣步驟減少到 10 個甚至 10 個,這不會損害嘴唇同步的準確性,但會影響動作和視覺質量。采樣步驟越多,視頻質量越好。
1. 單人
1) 生成一個 1 塊的短視頻
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/single_example_1.json --sample_steps 40 --frame_num 81 --mode clip --save_file single_exp2) 長視頻生成
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/single_example_1.json --sample_steps 40 --mode streaming --save_file single_long_exp2. 多人
1) 生成一個 1 塊的短視頻
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/multitalk_example_1.json --sample_steps 40 --frame_num 81 --mode clip --save_file multi_exp
2) 長視頻生成
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/multitalk_example_2.json --sample_steps 40 --mode streaming --save_file multi_long_expMultiTalk,這是一種用于音頻驅動的多人對話視頻生成的新穎框架。給定一個多流音頻輸入、一個參考圖像和一個提示,MultiTalk 會生成一個視頻,其中包含跟隨提示的交互,并與音頻保持一致的嘴唇動作。
生成卡通視頻

生成歌唱視頻

生成遵循指令的視頻
在一個舒適、溫暖的房間里,尼克·王爾德(Nick Wilde)——一只帶著調皮的笑容的狐貍——坐在朱迪·霍普斯(Judy Hopps)對面,朱迪·霍普斯(Judy Hopps)是一只表情堅定的兔子。 兩人都穿著休閑;Nick 穿著綠色襯衫和條紋領帶,Judy 穿著藍色衣服,耳機放在桌子上。 他們之間的木桌上放著一個迪士尼品牌的杯子。 背景以質樸的內飾為特色,配有燈、窗戶和各種家居用品,營造出溫馨的氛圍。 當 Nick 拿起杯子并輕輕觸摸 Judy 的頭部時,一個中景鏡頭捕捉到了他們的互動,暗示了一段友情和聯系。

一男一女坐在戶外的桌子旁,正在進行交談。 這位女士身穿淺粉色上衣和白色開衫,手里拿著一個紅色的罩杯 咖啡,啜飲一口,然后將其放回碟子上。那個男人,穿著 一件條紋襯衫套在一件白色 T 恤上,全神貫注地看著他的智能手機 專心致志地向下。桌子上裝飾著兩杯紅色咖啡和一個盤子 配羊角面包。背景是一條迷人的歐洲街道,色彩柔和。 建筑物、綠色植物和一把半開著的綠色傘。場景捕獲 一個隨意的日常時刻,擁有溫暖、誘人的氛圍。
兩個人坐在工作室的白色桌子旁,工作室里有藍白相間的吸音墻板。 左邊的一名男子穿著深色休閑上衣,手里拿著一個咖啡杯。 右邊的女人身邊放著一副錄音室耳機。 男人在說話,而女人在聽,偶爾點頭。 女人拿起黑色耳機。大型壁掛式電視顯示技術接口。 該場景暗示了在明亮的工作室環境中配備專業視聽設備的協作工作空間。
More creative videos
Abstract
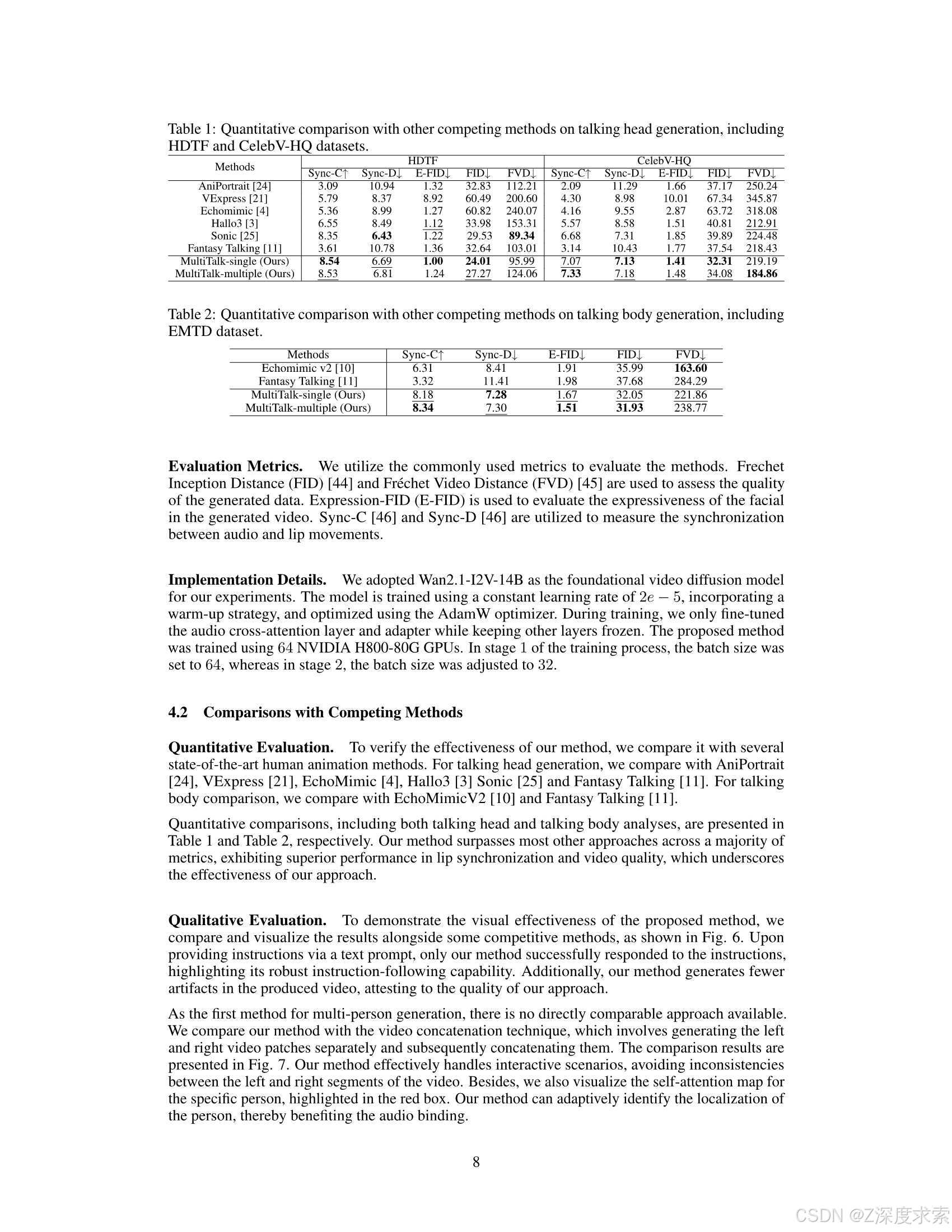
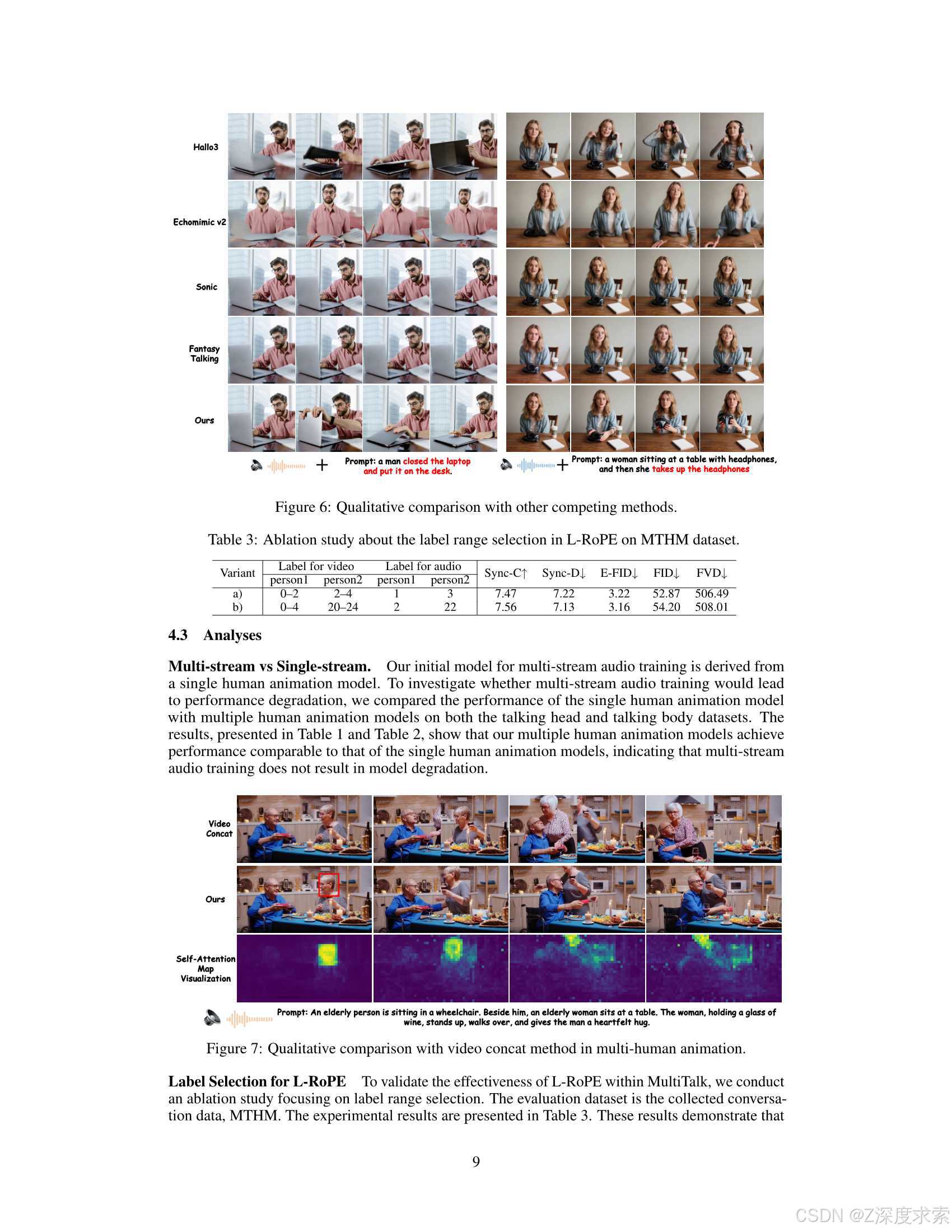
Audio-driven human animation methods, such as talking head and talking body generation, have made remarkable progress in generating synchronized facial movements and appealing visual quality videos. However, existing methods primarily focus on single human animation and struggle with multi-stream audio inputs, facing incorrect binding problems between audio and persons. Additionally, they exhibit limitations in instruction-following capabilities. To solve this problem, in this paper, we propose a novel task: Multi-Person Conversational Video Generation, and introduce a new framework, MultiTalk, to address the challenges during multi-person generation. Specifically, for audio injection, we investigate several schemes and propose the Label Rotary Position Embedding (L-RoPE) method to resolve the audio and person binding problem. Furthermore, during training, we observe that partial parameter training and multi-task training are crucial for preserving the instruction-following ability of the base model. MultiTalk achieves superior performance compared to other methods on several datasets, including talking head, talking body, and multi-person datasets, demonstrating the powerful generation capabilities of our approach.
Method
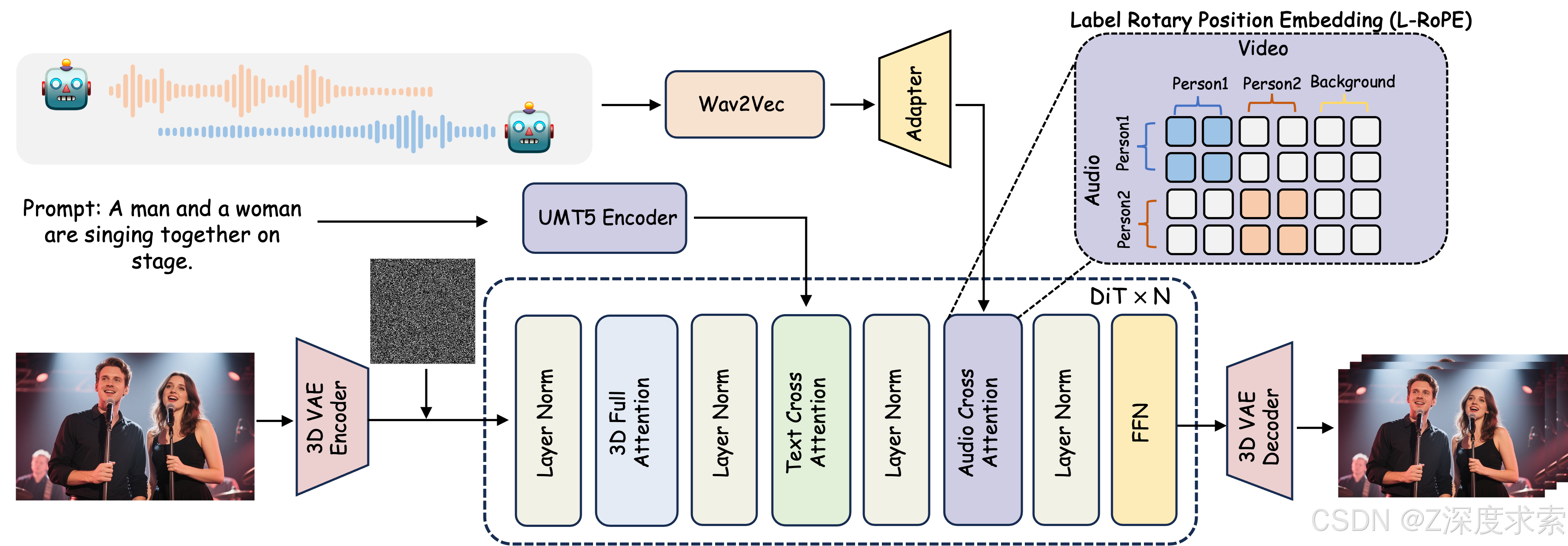
In this work, we propose MultiTalk, an audio-driven video generation framework. Our framework incorporates an additional audio cross-attention layer to support audio conditions. To achieve multi-person conversational video generation, we propose a Label Rotary Position Embedding (L-RoPE) for multi-stream audio injection.

MultiTalk,一個音頻驅動的視頻生成框架。 我們的框架包含一個額外的音頻交叉注意力層來支持音頻條件。 為了實現多人對話視頻的生成,我們提出了一種用于多流音頻注入的標簽旋轉位置嵌入 (L-RoPE)。














)
開發環境搭建_第一篇)


:運行時類型識別)








)

