文章目錄
- Megatron-LM
- 數據并行
- 模型并行
- 張量并行
- 流水線并行
- 3D并行
Megatron-LM
Megatron是當前大模型訓練時經常使用的一種分布式并行框架,它通過采用DP,TP,PP等來加速模型的訓練,反正就是一個字,好。
大模型在訓練的時候,顯存占用是非常大的,比如一個175B的模型,假設模型參數用FP32表示,即4Byte,那逛模型參數就要700G,梯度700G,Adam兩個動量1400G,很明顯,裝都裝不下,所以采用這些并行技術使得它可以在有限的資源下進行訓練。
補充:Adam優化器:
主要是用來動態調整學習率和梯度更新的方向,每一次更新的時候需要保存其一階矩和二階矩,其中一階矩是梯度的平均值,二階矩是梯度的平方,主要用來動態調整學習率。一階矩和二階矩分別表示為m和v,其相對SGD訓練更加穩定。每一次更新的時候,都需要依賴上一次的計算出的一階矩和二階矩,也就是每一個參數都對對應一個一階矩和二階矩。
數據并行
假設有N張卡,每一張卡都保存一個模型的副本,現在可以將一個batch的數據分割為多個mini-batch,然后分發給每一個模型副本,進行前向傳播,并計算損失和梯度,然后通過All-Reduce操作進行通信和廣播,對每一個GPU計算的梯度進行規約(同步加平均),然后將梯度分發給每一個GPU,每張卡獨立更新,單獨更新模型參數,此時由于更新的梯度相同,模型的初始參數相同,經過更新后,每一個GPU上模型的參數也相同。
但是這種數據并行有哪些限制呢?
第一個是可以使用的GPU數量受限于batch的大小,假設batch是64,那你最多也只能用64張卡了。
另一個就是GPU利用率可能拉不滿,如果batch的數量固定式512,你GPU太多,分發給每一個GPU的數據量太小,那GPU 更新塊,但是通信頻率也就增加了,可能會限制訓練速度。

所有 GPU 必須一起等到梯度計算完成,才能開始 all-reduce,否則會造成阻塞卡頓。 數據并行最適合模型較小、計算量大、batch size 較大時使用。模型較大或 GPU 太多時要考慮混合并行或 ZeRO 分布式技術。 All-Reduce 是一種通信操作,由 NCCL / MPI / Gloo 等通信庫負責實現。它不是庫,而是庫提供的功能
模型并行
梯度累積:
主要是用來模仿大batch進行更新的操作,因為大batch更新往往更見穩定,但是受限于顯存,所以可以用梯度累積的方式,當累積到固定數量的batch之后再進行優化器更新,它通過將多個小 batch 的梯度累加,然后在累積到設定的步數后進行一次更新,從而 模擬了大 batch 的梯度平均效果。
激活檢查點:
主要是用來緩解激活值對顯存的占用壓力,因為按照反向傳播公式,每一個參數更新時,都需要前一層的激活值,這樣的話,每一次更新的時候就需要存儲每一個節點的激活值,對顯存的占用太高,所以就采用梯度檢查點的方式,每隔一定的步數保存激活值,兩個激活值之間的沒有保存的激活值,通過前向傳播再算出來,這也就是用時間換空間了,總的來說,現在所占用的空間復雜度降為 Q ( N ) Q(\sqrt{N}) Q(N?),相當于在更新的時候再做了一次前向傳播。
這也是為什么模型在模型在訓練的時候,不考慮激活值占用顯存的問題,因為它可以通過技術原因繞過去。

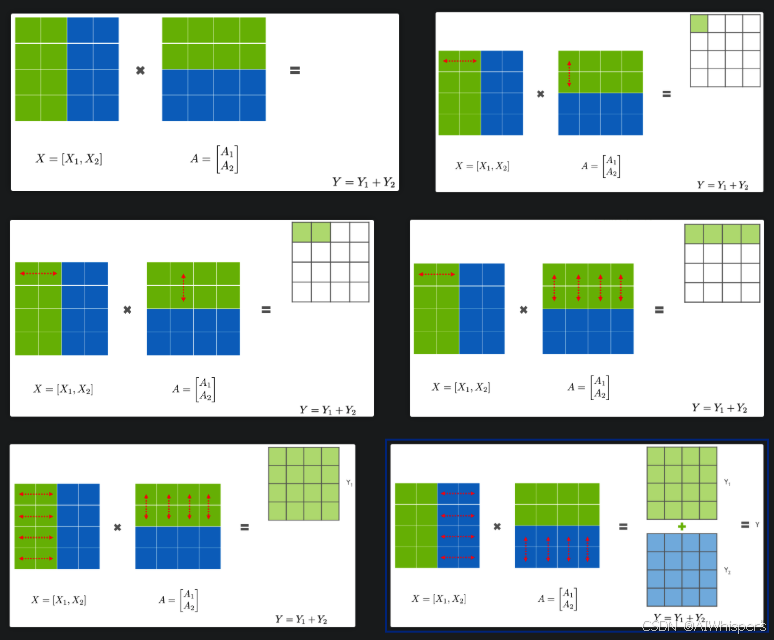
張量并行
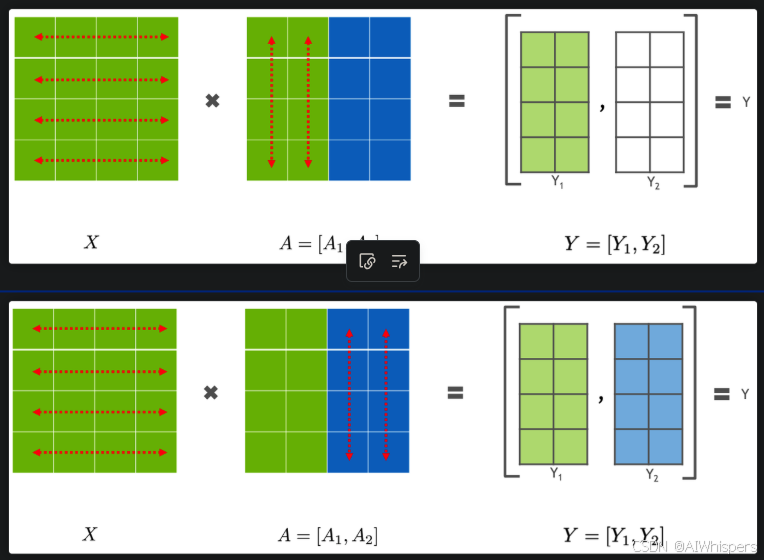
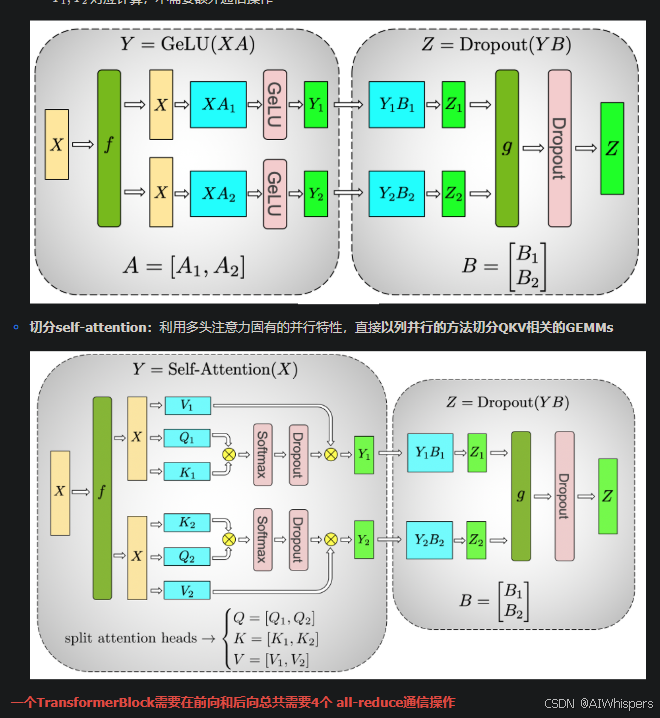
如果一個GPU裝不下一整個模型,那么就可以對模型進行拆分,相當于橫著或者豎著來一刀,一般來說,對于大矩陣的乘積計算,我們可以將其分成多個小矩陣的乘積和加和,根據拆分方式的不同可以分為行并行和列并行,一般來說,列并行更好一些,因為在計算激活值的時候不需要先進行通信。通信的原因還是GELU是非線性函數,需要根據全局的信息進行計算。

行并行:
列并行:
流水線并行
流水線并行通過將模型按網絡層劃分為多組,每一組在一個GPU上。
目前主流的流水線并行方法包括Gpipe和PipeDream,降低空泡率。Megatron用的時Visual pipeline.1F1B,一前向一反向。
實際上流水線并行和張量并行是正交的,可以同時存在。
3D并行

3D并行就是混合數據并行DP,張量并行TP和流水線并行PP。四路張量,四路流水線,2路數據





![Qt中的OpenGL (4)[紋理]](http://pic.xiahunao.cn/Qt中的OpenGL (4)[紋理])
)





)






