阻塞隊列
阻塞隊列也是一種隊列,先進的先出
阻塞隊列就是對普通的隊列做出的拓展
阻塞隊列的特性
1.線程安全的,我們普通的隊列值線程不安全的
2.具有阻塞的特性:
- a》如果針對一個已經滿了的隊列進行如隊列操作的話,入隊列操作就會阻塞,一直到阻塞隊列不滿了為止(有其他的線程出隊列)
- b》如果針對一個已經空了的隊列進行出隊列操作的話,出隊列操作就會阻塞,一直到阻塞隊列不空了為止(有其他的線程如隊列)
基于阻塞隊列,就可以實現“生產者消費者模型”
舉一個例子,包餃子
包餃子的流程:
- 和面(一般是一個人負責,沒有辦法多線程)
- 搟餃子皮
- 包餃子
(第二步和第三步這兩環節就可以使用多線程了)
這三個滑稽開始同時完成搟餃子皮和包餃子這兩個步驟,這三個滑稽,都是先搟一個餃子皮,再包一個餃子,之后再搟一個餃子皮,再包一個餃子,很明顯這種多線程的包餃子的方式,要比單線程包餃子要快,但是我們只有一個搟面杖,我們三個滑稽就要競爭這個搟面杖,如果1號滑稽拿到了,2號和3號滑稽就得阻塞等待
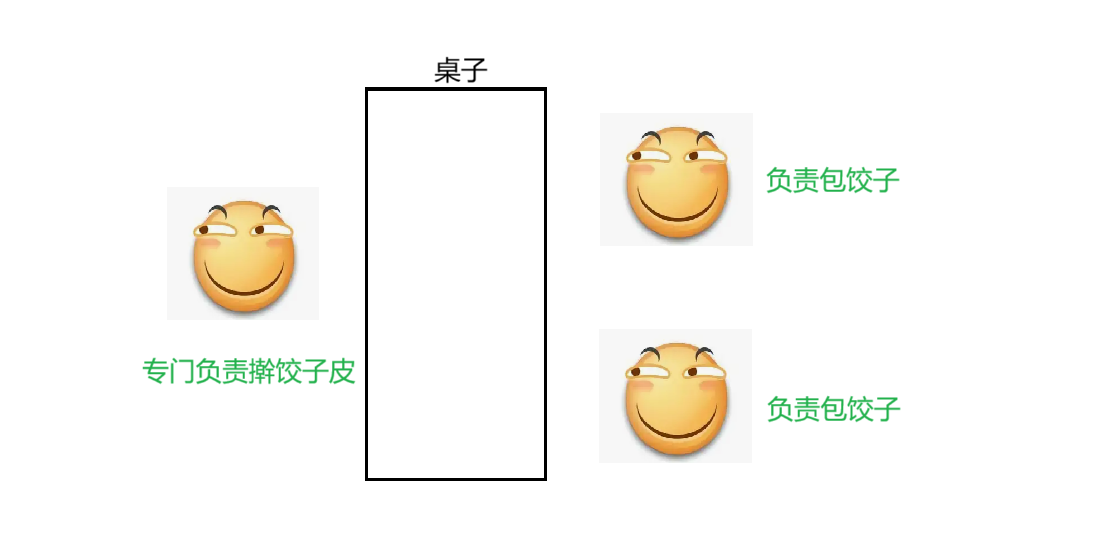
為了解決這個問題,就可以分工協作(如下圖)
此時這個專門負責搟面皮的滑稽就可以一個人獨享搟面杖了,沒有人跟他搶,此時就不會有鎖競爭了
這里的分工協作就構成了生產者消費者模型,搟餃子皮的線程就是生產者(生產餃子皮),另外兩個線程就是消費者(消費餃子皮)
這個桌子就充當起了傳遞餃子皮的作用,這個桌子的角色就相當于是阻塞隊列
- 1》假設,搟餃子皮的人的速度非常快,但是包餃子的人的速度很慢,于是桌子上的餃子皮會越來越多,一直到了桌子滿了為止,這時搟餃子皮的人就需要等一等,等包餃子的人消耗一波餃子皮之后再開始搟餃子皮
- 2》假設,搟餃子皮的人的速度很慢,但是包餃子的人的速度很快,就會導致桌子上的餃子皮越來越少,一直到桌子上沒有了餃子皮為止,這時包餃子的人就需要等一等,等搟餃子皮的人搟下餃子皮的時候再開始包餃子
生產者消費者模型,在實際的開發中非常意義:
- 1.引入生產者消費者模型可以更好的“解耦合”(把代碼的耦合程度從高減到低,就稱為解耦合)
- 2.削峰填谷
解耦合
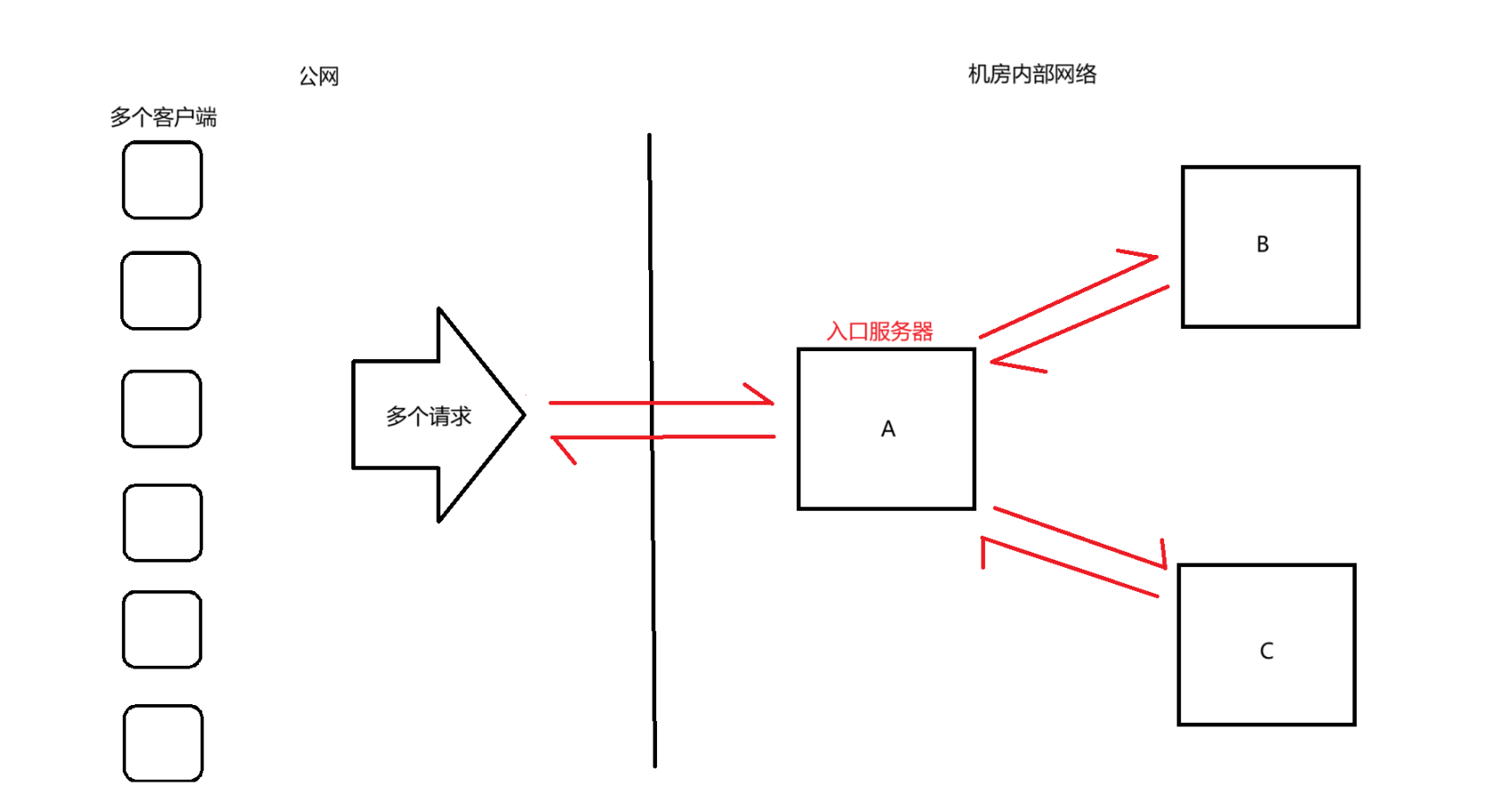
我們實際開發的過程中,通常會設計到“分布式系統”,整個服務器的功能不是由一個服務器完成,而是有多個服務器,每個服務器完成一部分的功能,通過服務器之間的網絡通信,進而完成服務器的整個功能
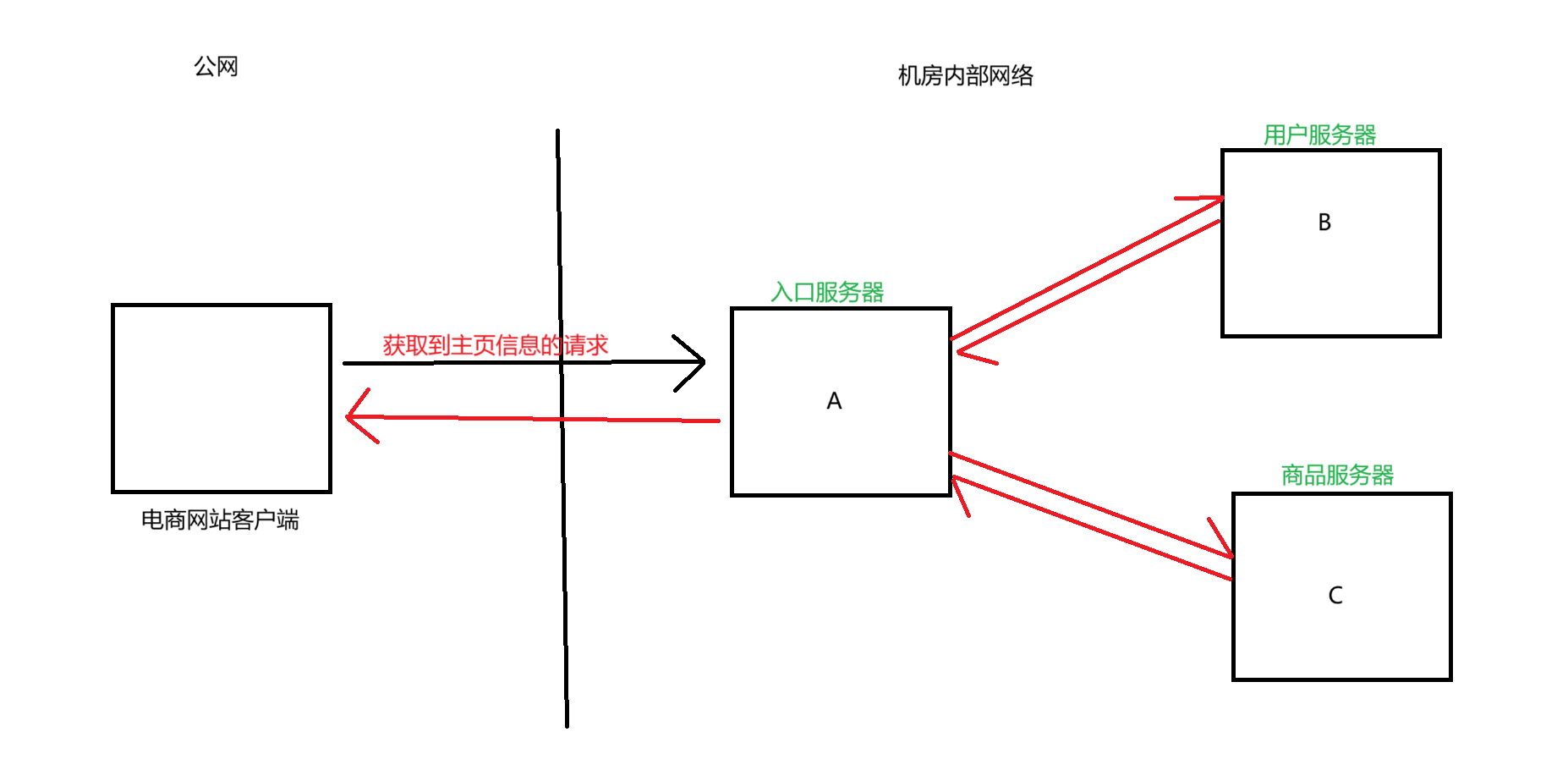
如上圖中,我們的電商網站客戶端向我們的服務器發送了獲取主頁信息的請求,在我們的分布式系統里面,有一個入口服務器專門用來接收來自外部的請求,當我們的入口服務器接收到請求以后,就會調用相關的服務器,主頁的信息包含用戶的信息和商品的信息,于是就會調用用戶服務器和商品服務器,這兩個服務器會將信息返回給入口服務器,入口服務器就會將完整的主頁信息返回給電商客戶端
上述的模型中,A和B,A和C之間的耦合性是比較強的,由于A和B是直接交互的,A的代碼里會涉及到關于B的操作,B的代碼里面也會涉及關于A的操作,A和C也是同理,此時要是B或者C掛了,由于它們和A的耦合性強,就會影響到A,A也可能就掛了
引入生產者消費者模型,就可以降低耦合度
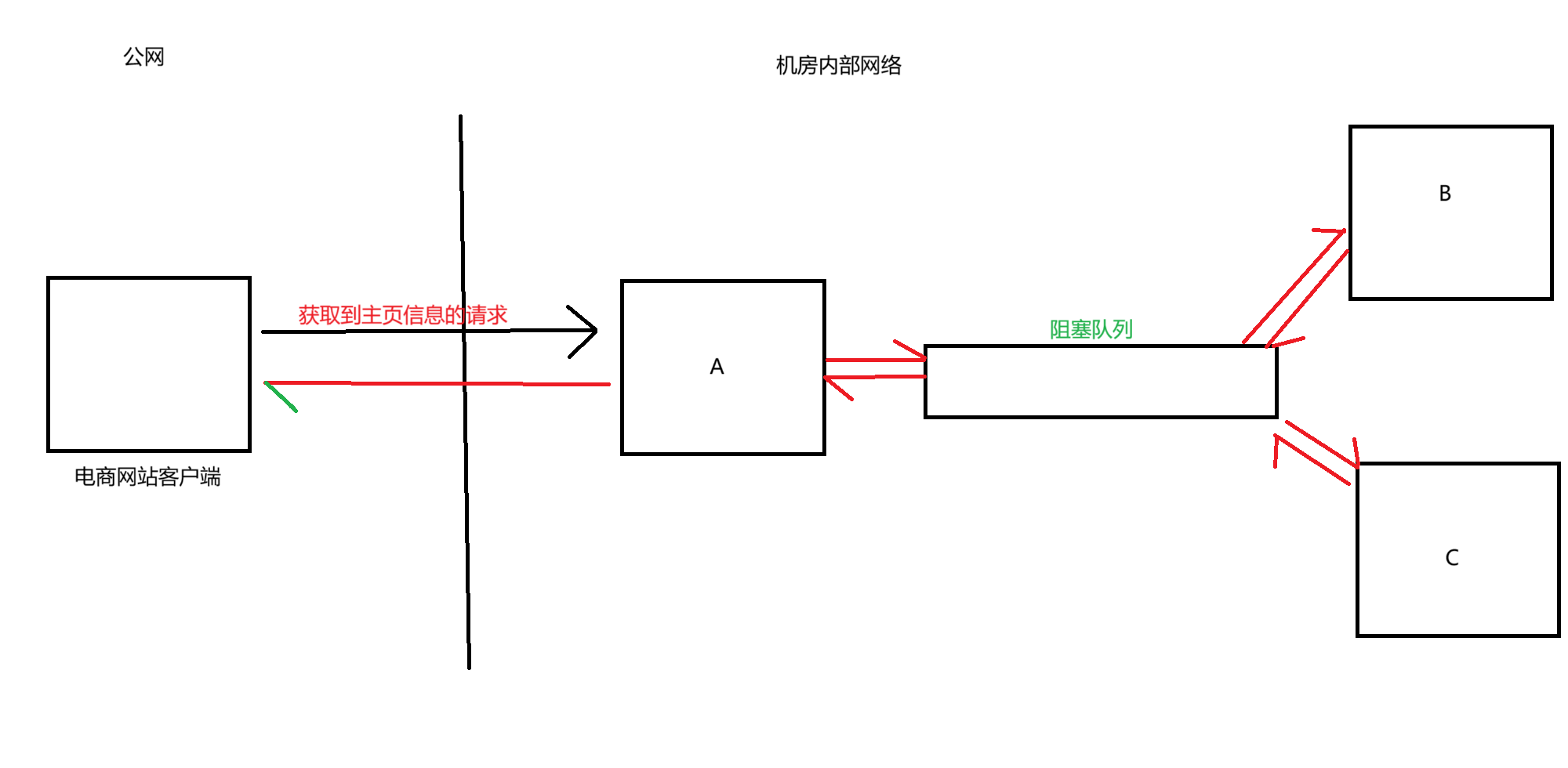
此時A和B,A和C都不是直接交互,而是通過阻塞隊列進行傳話,此時A里面的代碼只需要跟阻塞隊列進行交互,不知道B和C的存在,B和C也不知道A的存在,即使是B和C掛了,對A的影響也是微乎其微,后續如果是要再添加一個D服務器的話,A里面的代碼幾乎也不用變化
加入阻塞隊列的代價是什么呢?
- 最明顯的代價就是引入機器,需要更多的硬件資源,上面的阻塞隊列并不是單純的數據結構,而是實現了這個數據結構的服務器的程序,又被部署到單獨的服務器主機上了,所以加入阻塞隊列意味著需要更多的機器
我們將阻塞隊列或者部署了實現該數據結構的程序的服務器成為消息隊列- 系統的結構便復雜了,需要維護的服務器變多了
- 效率,引入中間商,還是有差價的,請求從A發出到B,中間要歷經阻塞隊列的轉發,這個轉發的過程也是有一定開銷的
削峰填谷
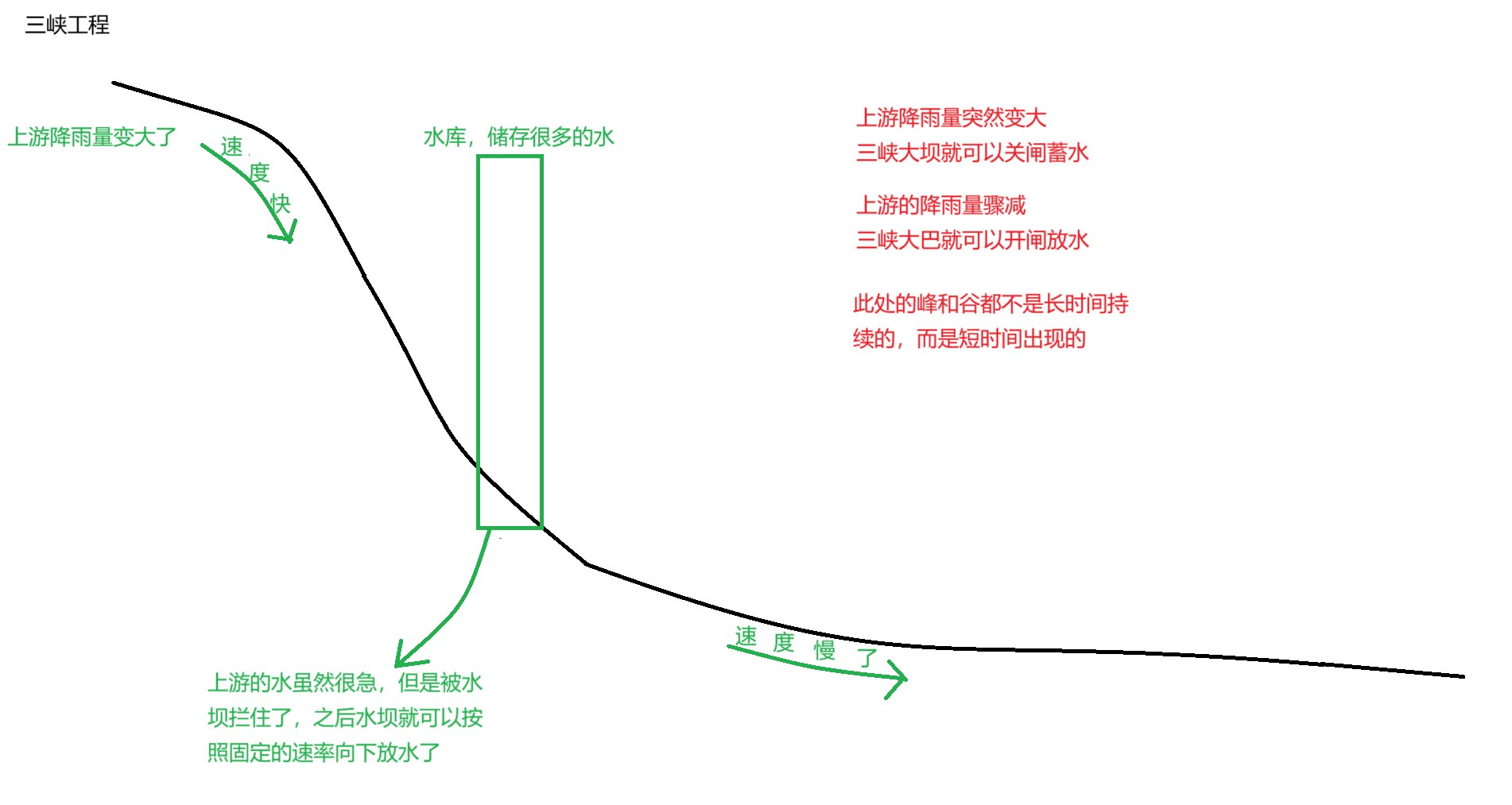
舉一個三峽大壩的例子
外界客戶端發起的請求時固定不變的嗎,并不是,這是屬于“用戶行為”,如果發生一些突發情況,就會使請求劇增,比如滴滴掛了就會使其競品的請求量增加,還有雙十一就會使購物類軟件的需求劇增
當需求劇增了以后,A和B和C的壓力就會變大,就有可能會導致服務器給掛掉,并且A的抗壓能力更強,B和C的抗壓能力更弱,這是為什么呢?
- 1》為什么當請求多了以后,服務器就會掛掉呢,服務器處理每個請求都是要消耗硬件資源的(包括但不限于CPU,內存,硬盤,網絡帶寬),雖然每個請求消耗的硬件資源很少,但是架不住請求多呀,所有的請求加到一起的話,總的消耗的資源就多了,只要軟件資源到達瓶頸,服務器就掛了,最直觀的感受就是你跟服務器發請求,他不會返回響應了
- 2》為什么A的抗壓能力要比B和C的抗壓能力更強,A處理的請求比較簡單,每個請求消耗的硬件資源少,B和C處理的請求比較復雜(比如獲取商品的信息,先要從數據庫里面獲取到對應的信息,還要根據一些條件進行匹配過濾篩選),每個請求消耗的硬件資源就多
一旦外界的請求數量出現突發的峰值,這個突發的峰值就會使B和C掛掉
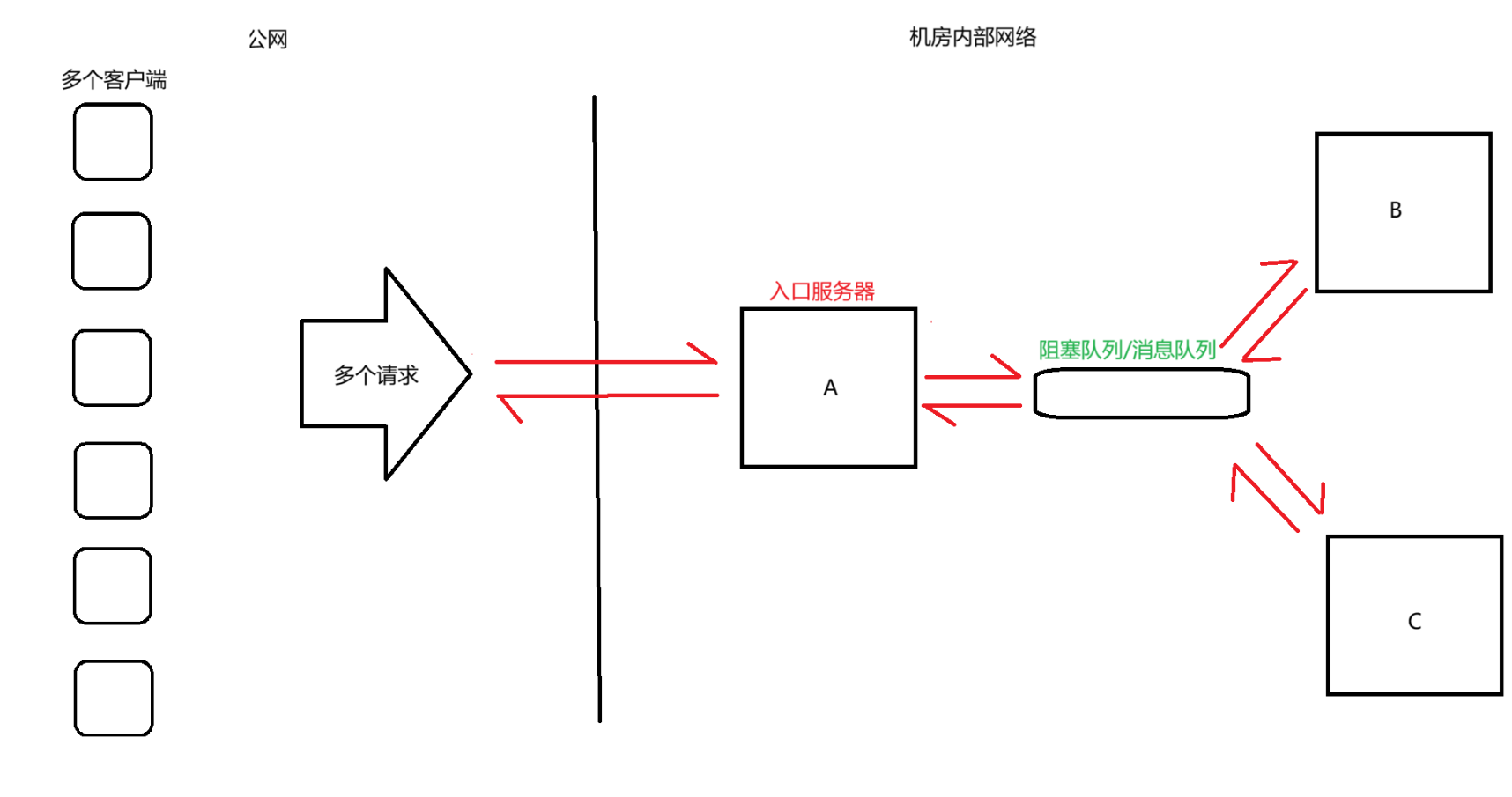
我們現在引入阻塞隊列(消息隊列)
我們的阻塞隊列沒有什么復雜的業務邏輯,只是存儲傳遞數據,所以阻塞隊列的抗壓性很好
所以當我們的外界請求量劇增的時候,也是阻塞隊列來承擔壓力,B和C按照之前的速度來處理請求就可以,引入阻塞隊列可以有效的防止B和C掛掉
請求太多,那接收的服務器會掛掉嗎?
如果請求量一直往上增的話,即使是抗壓能力很強的服務器也會掛掉,所以大廠的系統往往會有非常充裕的冗余量(引入更多的硬件資源,避免上述問題), 如果一臺機器的CPU/內存的占用率超過50%的話,就需要機器進行擴容,保證機器的冗余量在50%,即使請求翻倍了,我們的機器也是能抗住的
可以往A服務器前面加一個阻塞隊列嗎
也不是不可以,但是如果請求一直增加的話,隊列也可能會掛掉
Java標準庫里提供了現成的阻塞隊列數據結構
BlockingQueue就是Java標準庫里面提供的,它是一個接口,以下是關于這個接口的實現
- Array Blocking Queue
- LinkedBlockingQueue
- PriorityBlockingQueue
- 我們使用put和offer都是一樣的入隊列,但是put是帶有阻塞功能的,offer沒有阻塞的功能(隊列滿了會返回結果)
- take方法出隊列,也是帶有阻塞功能的
- 但是阻塞隊列沒有提供帶有阻塞功能獲取隊列首元素的方法

public class Test12 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue=new ArrayBlockingQueue<>(100);queue.put("aaa");String elem=queue.take();System.out.println("elem是"+elem);elem=queue.take();System.out.println("elem是"+elem);}
}
上述代碼的結果就是只輸出一次“elem是aaa”,之后線程就進入了WAITING的阻塞狀態(如下圖)

阻塞隊列的實現
關于阻塞隊列的使用是簡單的,上述關于阻塞隊列的介紹只是序幕,接下來是正題,我們要自己實現一個阻塞隊列
實現一個阻塞隊列,我們的步驟如下:
- 先實現一個普通的隊列
- 再加上線程安全
- 再加上阻塞功能
阻塞隊列我們基于數組來實現(環形數組)
如何判斷一個隊列是空還是滿呢?
- 浪費一個格子,tail最多走到head前面的一個格子
- 引入size變量
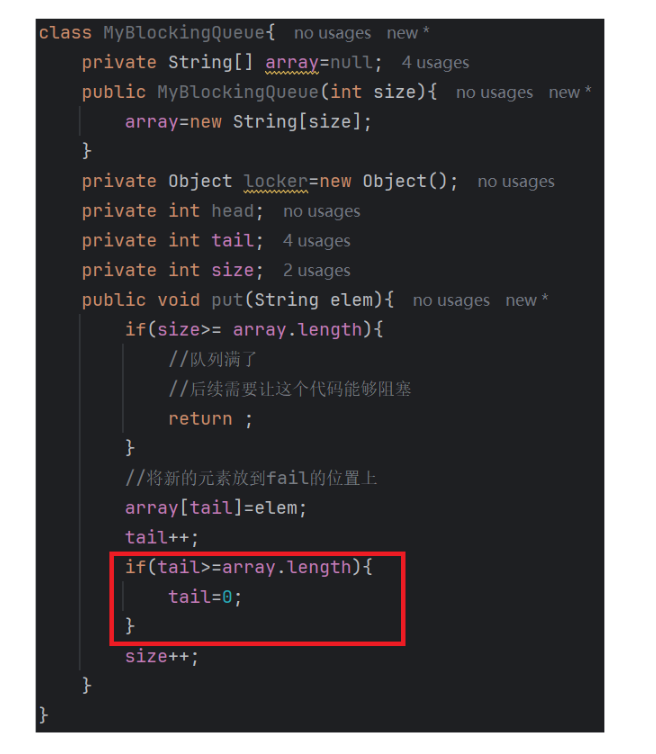
環形數組
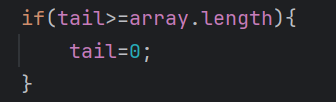
上圖是我們實現的一個普通的隊列,注意看我們紅色方框標注的部分,他是我們環形數組中最重要的部分,這個代碼能夠保證我們的數組下標到達末尾之后又可以回0下標的位置
看上圖的寫法,是我們上面紅框部分的另一種寫法
- 當tail小于array.length時,tail最終的值就是tail本身
- 當tail等于array.length時,tail最終的結果就是0,又回到0下標的位置

上述的兩種寫法又什么區別呢?那種方法會更好?
我們從兩方面來講
- 開發效率(代碼是否容易理解)
- 運行效率(代碼執行的速度快不快)
開發效率
- 我們先看下圖的代碼
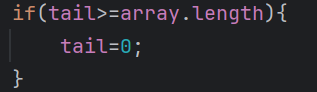
這個代碼里面主要是條件跳轉語句,條件跳轉語句的執行速度非常快,而且tail=0的這個賦值操作,并不是每次都要執行,只有條件成立的時候才會執行,當條件不成立的時候,就不會執行,直接跳過- 我們來看另一種的寫法
這種寫法里面有取余操作,%本質上是除法,除法是比較低效的指令,我們的CPU擅長于加減,計算加減的速度要比計算乘除的速度要快,除了取余操作,還有賦值操作,這個賦值操作是100%會觸發的,不像我們第一種寫法,根據條件來判斷是否要執行賦值操作,并不是每次都要賦值這樣對比下來的話還是我們第一種的寫法的運行效率高

開發效率
- 第一種寫法還是很通俗易懂的
無非就是一個if加一個賦值的操作,只要是個程序員就可以看懂- 第二種寫法里面有“%”
這個百分號雖然也簡單,但是在不同的編程語言中%的作用可能還有一些不太一樣,在代碼的理解性上來說的話,雖然這種寫法不難理解,但是對比第一種還是略微遜色一些所以在開發效率方面來說還是第一種寫法略勝一籌

所以無論是開發效率還是運行效率來說,第一種寫法是最優解
加鎖
接下來我們加入鎖,解決線程安全問題
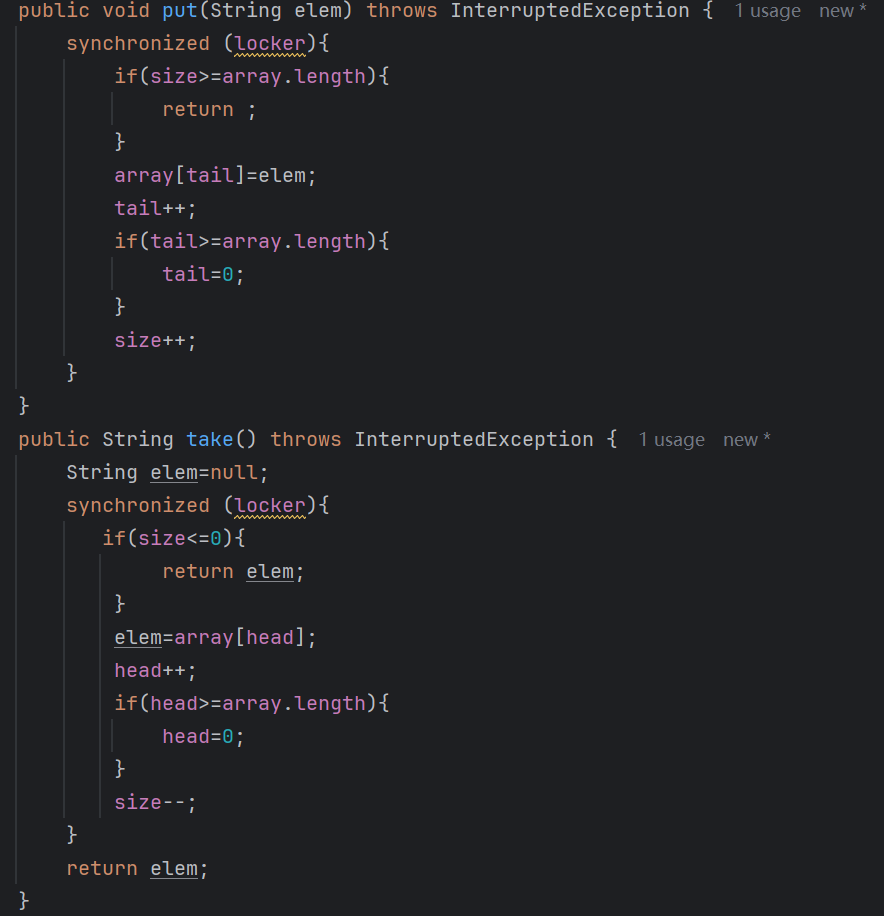
我們知道多線程代碼里面寫操作時會有線程安全問題的,比如上圖中紅框里面的操作,但是我們上圖中綠框的操作是否要加鎖呢?
看上圖的情況,如果只給寫操作加鎖的話,是會出現線程問題的如何加鎖,鎖放到哪里合適,加了鎖是否還有問題,這是多線程里面的難點,我們需要確保所有順序的情況下,程序的執行結果是正確的
以上就是我們加了鎖之后的代碼


加入阻塞
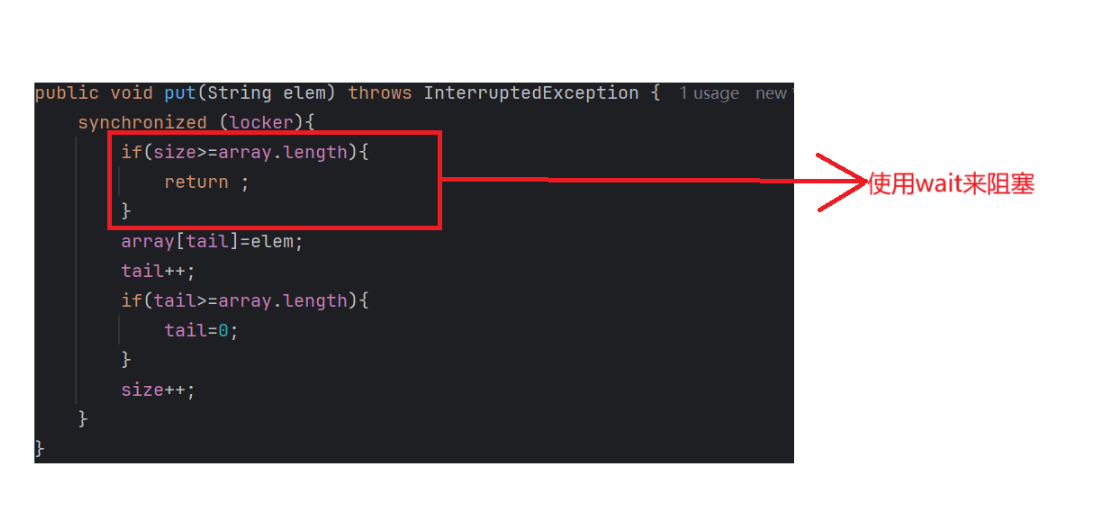
上圖中我們恰好吧wait加到if里面,恰好if剛好在synchronized里面了
如果我們此時數組滿了的話,就會執行wait,線程就會進入阻塞,此時就需要另一個線程來notify這個阻塞的線程,當隊列不滿時,也就是有線程出隊列了以后,就可以將阻塞的線程喚醒了
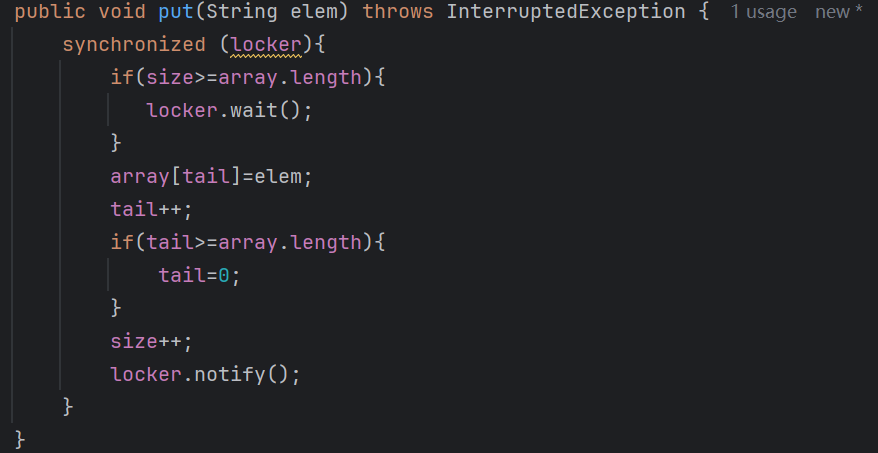
于是我們就在put方法里面出隊列之后,調用notify喚醒阻塞的插入線程
同理,出隊列的時候隊列如果為空的話,也需要阻塞等待插入的線程插入元素之后被喚醒,完整的代碼如下
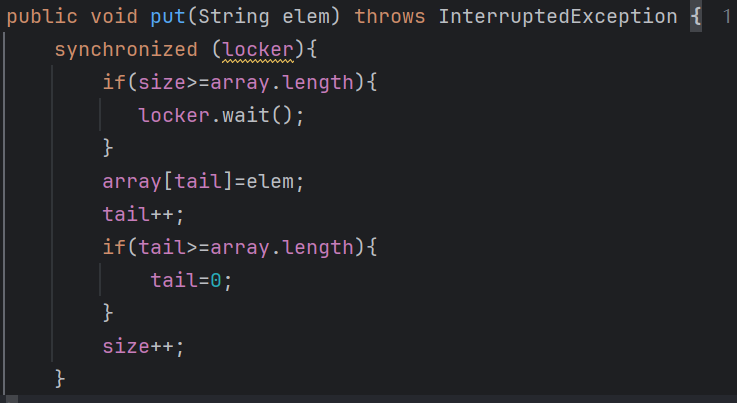
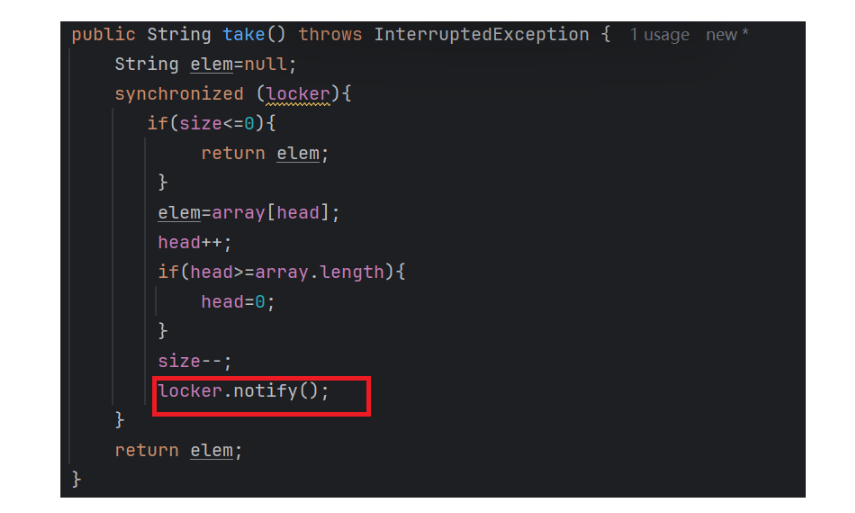
這里的喚醒操作我們不要使用notifyall,只要隨機喚醒一個即可
假如我們現在有多個線程的插入操作都阻塞了,此時我們有一個線程出隊列成功,即使我們將所有的入隊列線程都喚醒的話,因為只空出來一個空,只有一個線程能成功插入,其他剩下的線程只能繼續阻塞等待
這個代碼還有一個問題
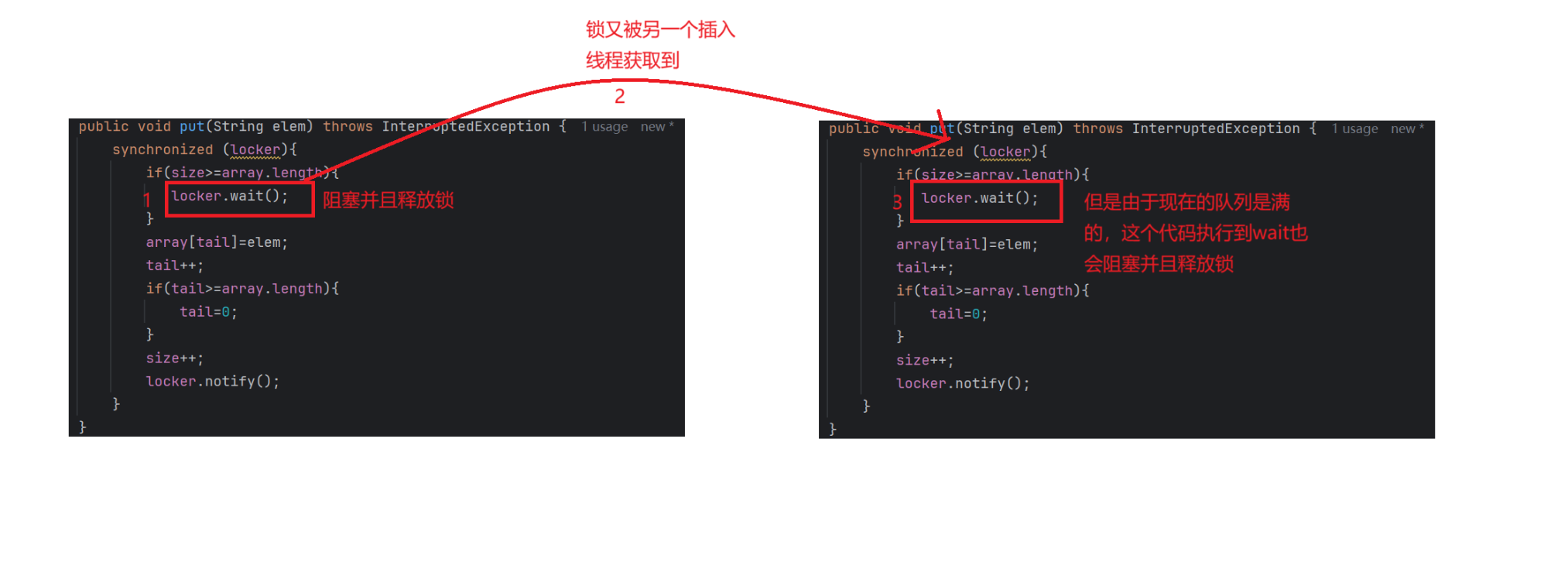
假設我們現在的隊列已經滿了
此時我們的put方法就會在wait阻塞,并且釋放鎖
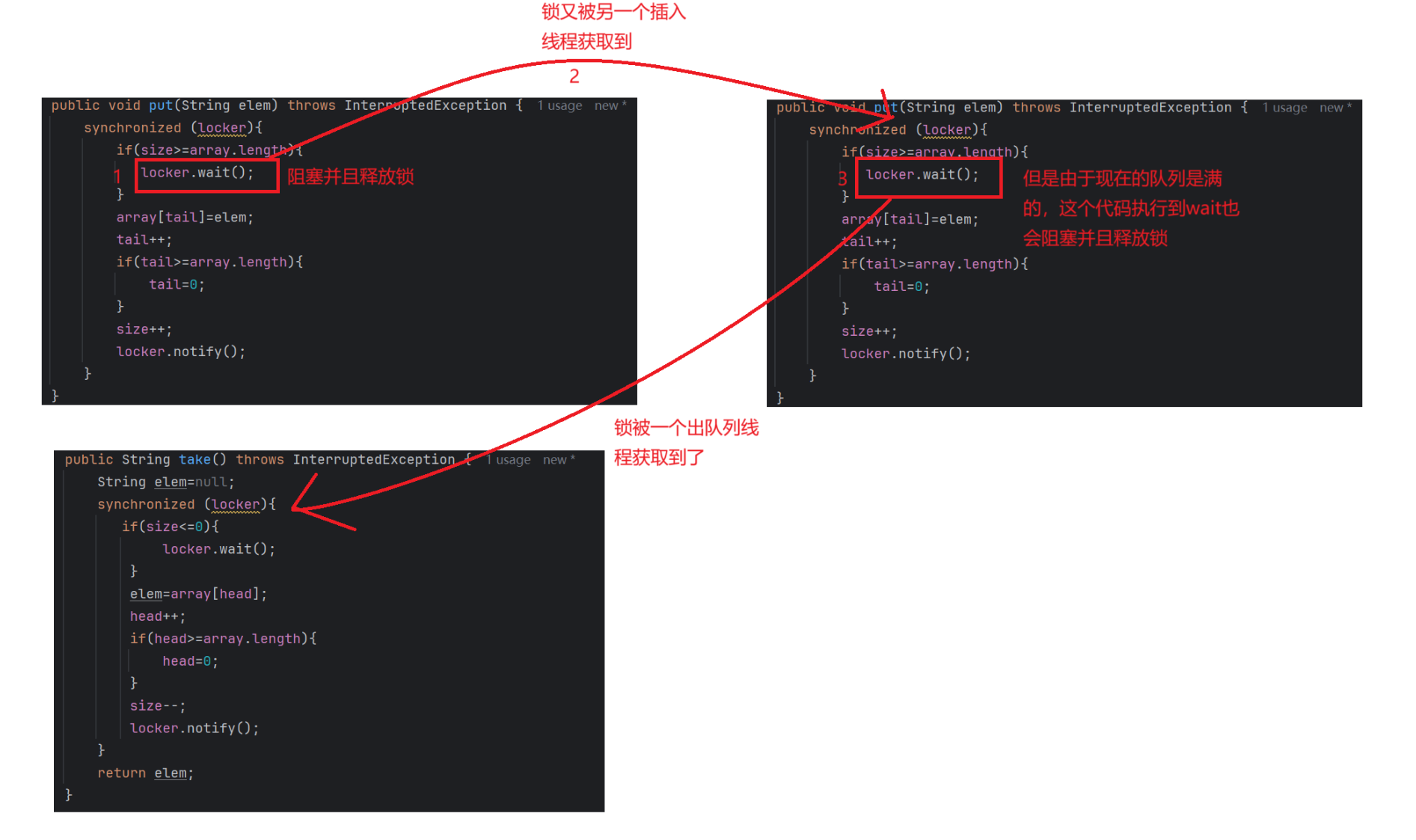
此時鎖又被另一個插入線程獲取到,但是這個線程也是執行到wait阻塞并且釋放鎖了
之后鎖被一個出隊列線程獲取到了,于是開始出隊列
出隊列的notify就會喚醒一個入隊列線程,如上圖的1步驟
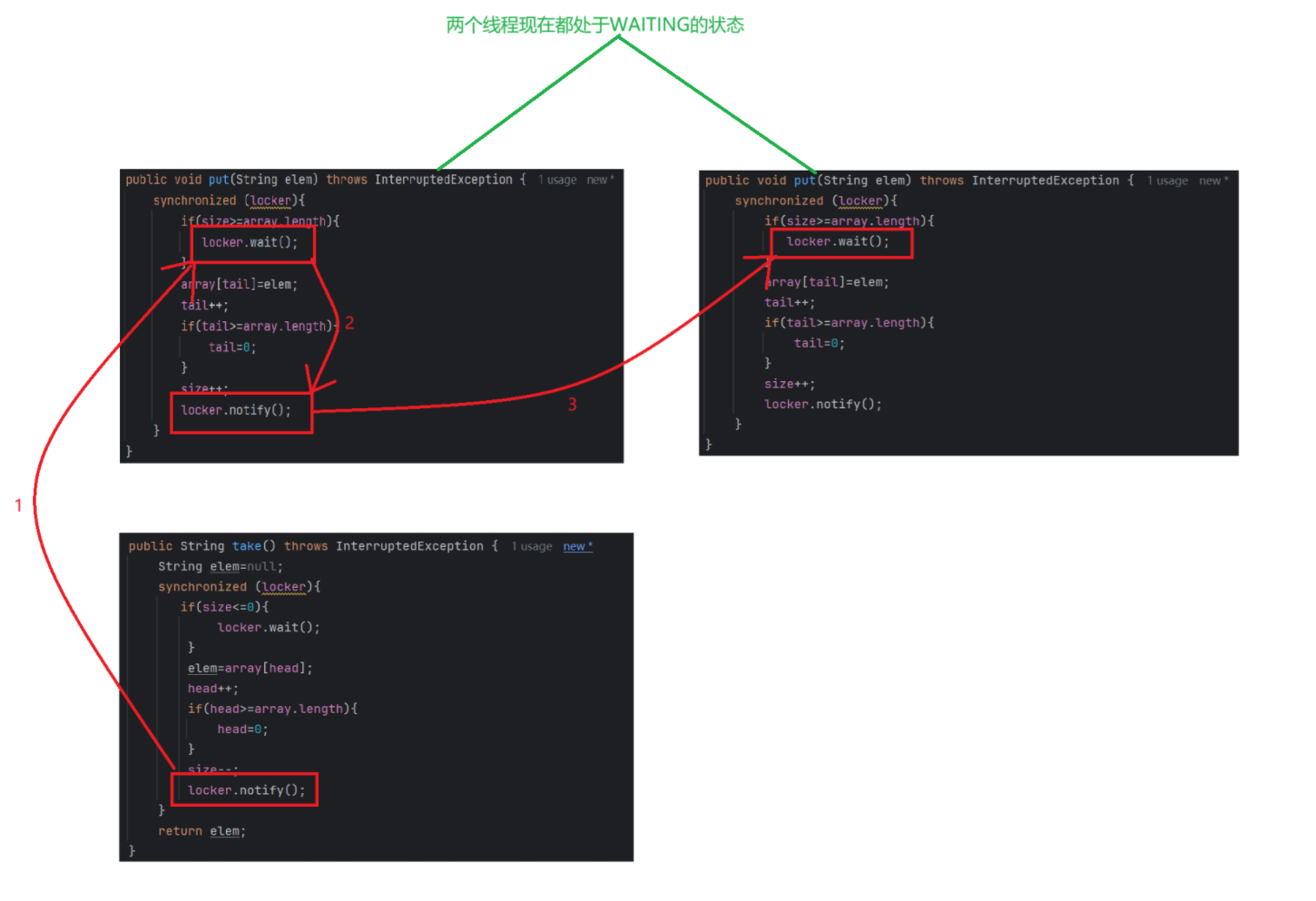
put方法執行完以后,這個被喚醒的線程獲取到鎖,執行到locker.notify的時候,就有可能吧另一個阻塞的入隊列線程喚醒,如上圖的3步驟
但是我們的put方法里面的notify初心是要喚醒阻塞的出隊列線程的,現在卻把入隊列線程喚醒了,出現了bug,也就是線程安全問題該怎么解決這個問題呢?
- 我們的wait外面是if的條件判斷,if其實是"一錘子買賣",if判斷之后,wait有可能進入阻塞,一旦阻塞了,下次被喚醒之后間隔的時間就是滄海桑田,這個過程中if里面的條件就有可能發生改變
- 我們只需要將if改成while即可,意味著喚醒之后還要再判斷一次,wait之前判斷一次,喚醒之后判斷一次,雙重保險,相當于是又確認了一次,如果再判斷一次還是滿著的話,就再wait進入阻塞
我們Java標準庫里面也是推薦wait和while搭配使用
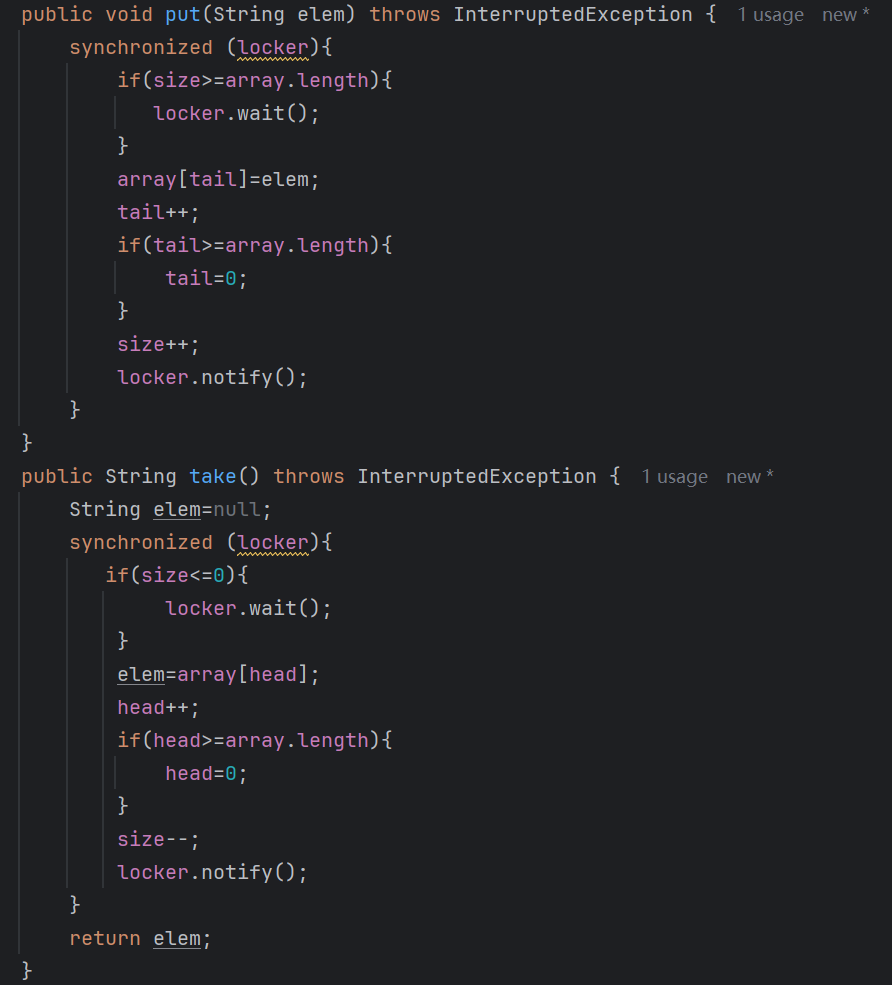
完整的代碼
class MyArrayBlockingQueue{private String[] array=null;public MyArrayBlockingQueue(int size){array=new String[size];}private Object locker=new Object();private int head;private int tail;private int size;public void put(String elem) throws InterruptedException {synchronized (locker){if(size>=array.length){locker.wait();}array[tail]=elem;tail++;if(tail>=array.length){tail=0;}size++;locker.notify();}}public String take() throws InterruptedException {String elem=null;synchronized (locker){if(size<=0){locker.wait();}elem=array[head];head++;if(head>=array.length){head=0;}size--;locker.notify();}return elem;}
}
實際開發中,生產者開發者模型中,不僅僅只有一個生產者和消費者,這里的生產者和消費者不僅僅是一個線程,而是一個服務器程序,或者一組服務器程序,但是核心還是阻塞隊列,使用synchronized和wait/notify達到線程安全和阻塞





)








)




