一、基本操作
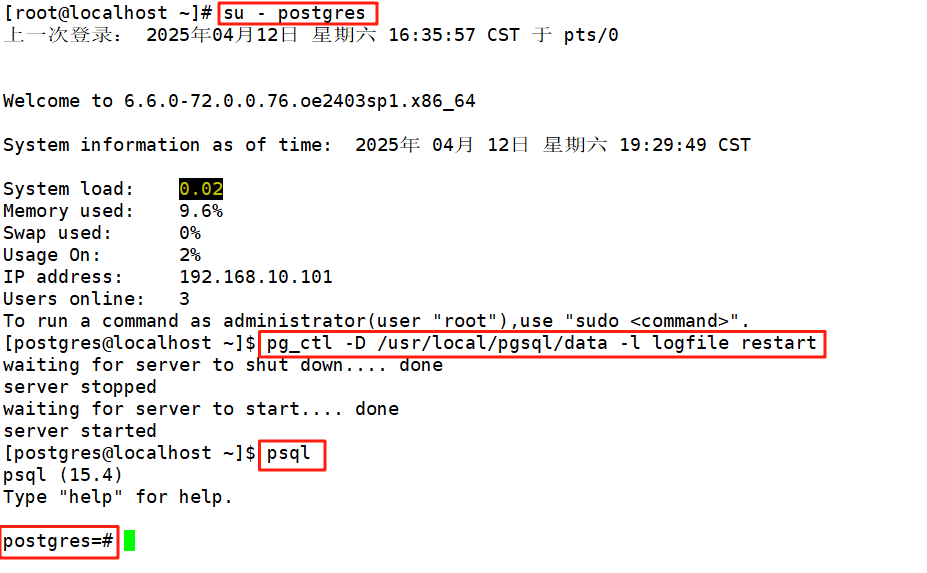
1、登錄
#切換pg用戶 su - postgres#重啟服務 pg_ctl -D /usr/local/pgsql/data -l logfile restart#進入pg psql
2、數據庫操作
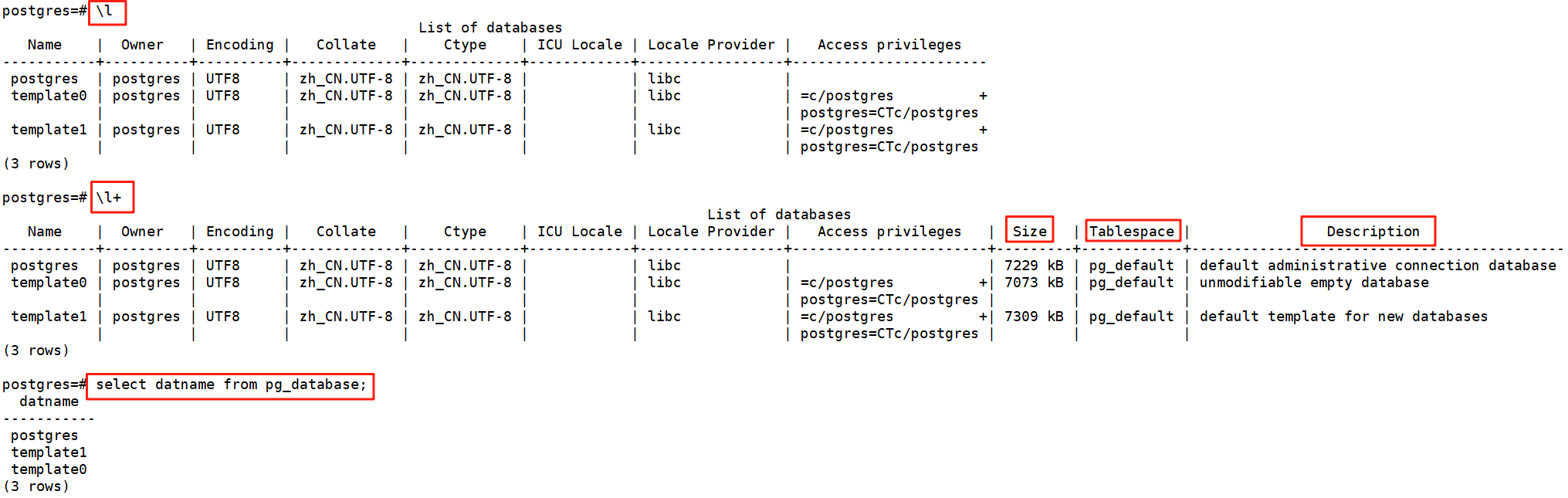
2.1、列出庫
\l\l+select datname from database;
\l+:輸出比\l多了Size,Tablespace 和 Description 列
+:擴展輸出,顯示更多字段或詳細信息
元命令 功能描述 \l 列出所有數據庫 \c [數據庫名] 或 \connect [數據庫名],用于連接數據庫 \dn 列出所有模式(Schema) \db 列出所有表空間 ? 顯示 pgsql 命令的說明(元命令查詢幫助) \q 退出 psql \dt 列出當前數據庫的所有表 \d [TABLE] 查看表結構 \du 列出所有用戶 ????????pg_database 是系統表:它存儲了 PostgreSQL 實例中所有數據庫的元信息(如數據庫名稱、所有者、編碼等)。屬于系統目錄(System Catalog):類似 MySQL的 information schema,PostgreSQl 的系統目錄更底層且直接存儲在pg_catalog 模式中。
????????pg_database 是系統目錄表,所以無論當前連接到哪個數據庫,該表始終可見系統表默認屬于pg_catalog 模式,而pg_catalog 始終位于搜索路徑(search path)的首位。因此,查詢時無需顯式指定模式(如 pg catalog.pg_database)2.2、創建庫
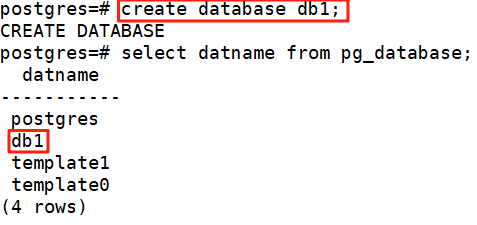
create database db1;
2.3、刪除庫
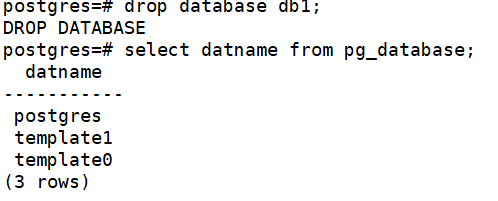
drop database db1;
2.4、切換庫
\c db1;
2.5、查看庫的大小
#以字節為單位返回數據庫的大小 select pg_database_size('db1');

3、數據表操作
3.1、創建表
create table t2(id int);
3.2、復制表
create table t3 as table t2;
3.3、查看內容
select * from t2; select * from t3;
3.4、刪除表
drop table t2;
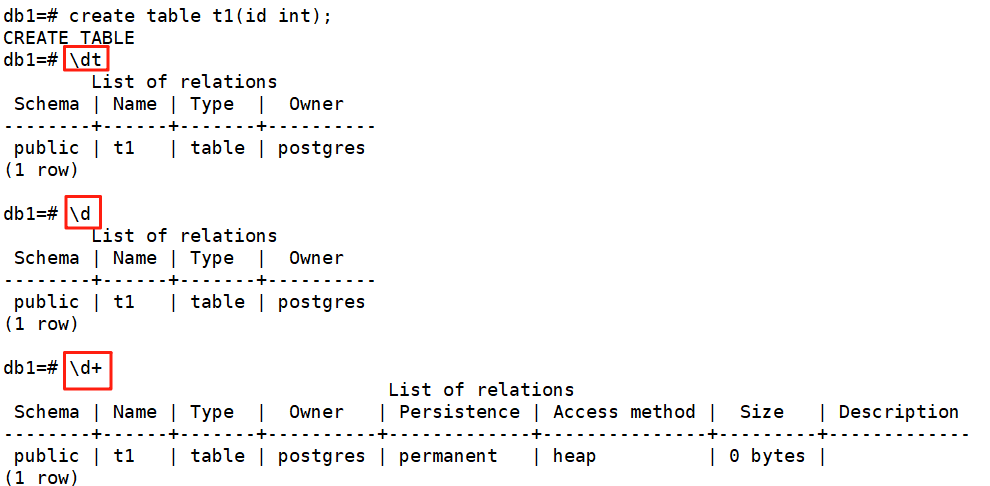
3.5、列出表
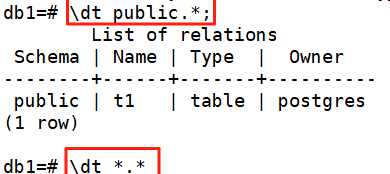
#列出表(顯示 search_path 中模式里的表,默認 public) \dt#列出表,視圖和序列 \d#更詳細的列出表,視圖和序列 \d+#列出指定模式下的表(例如 public) \dt public.*#查看當前數據庫所有表(包括系統表) \dt *.*#使用SQL方式列出當前數據庫中public模式下的所有表及其詳細信息 select * from pg_tables where schemaname='public';
????????pg_tables 是視圖:屬于 pg_catalog 模式,但它是基于 pg_class 和pg_namespace的邏輯視圖,并非物理表。無需切換數據庫,直接查詢pg catalog.pg tables 即可獲取當前數據庫的表信息
3.6、查看表結構
\d t1;



4、模式操作命令
????????在 PostgreSQL 中,模式(Schema)是一個邏輯容器,用于組織和管理數據庫對象(如表、視圖、函數、索引等)。它類似于文件系統中的文件夾,幫助你在同一個數據庫中分類存儲不同的對象,避免命名沖突,并實現權限隔離
4.1、創建模式
#在當前所在的庫創建一個模式aaa create schema aaa;
?4.2、查看所有的模式
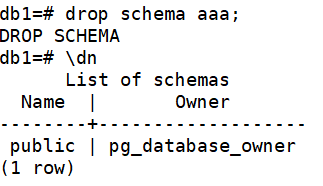
\dn
4.3、SQL 查詢,列出當前庫中所有模式
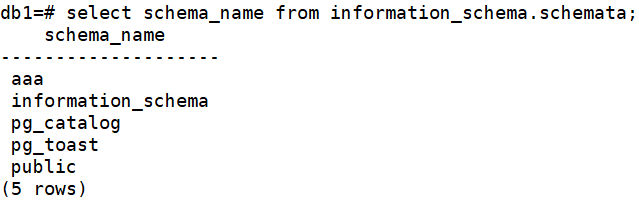
select schema_name from information_schema.schemata;
4.4、默認模式
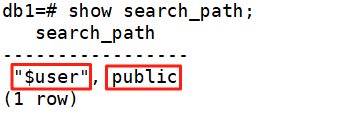
show search_path;????????PostgreSQl 每個數據庫都有一個默認模式 public。
????????如果創建對象(表、視圖等)時不指定模式,默認會放在 public 模式中。
????????通過 search path 參數可以設置模式的搜索優先級(類似 PATH 環境變量)
search path用于控制對象解析順序,避免每次查詢都要寫模式名
$user,public 表示優先查找當前用戶同名模式,再找public 模式。
4.5、刪除模式
#刪除空模式 drop schema aaa;
4.6、在指定模式中創建表
未指定模式時,創建的對象(表,視圖等)會按 search path 順序創建到第一個可用的模式中
#在aaa模式下創建表t2 create table aaa.t2(id int);#創建模式bbb create schema bbb;#在bbb模式下創建表t2 create table bbb.t2(id int);兩個域名空間相互隔離
4.7、切換當前模式
切換模式也就是調整 search_path 的搜索范圍
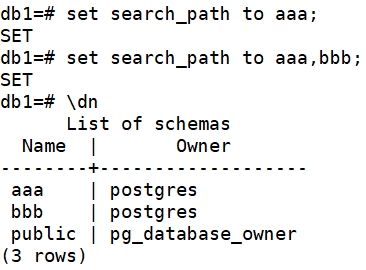
#切換到單個schema set search_path to aaa;#切換到多個schema(優先級按順序) set search_path to aaa,bbb;\dn
4.8、查看當前所在的模式
select current_schema;
4.9、查看搜索路徑
show search_path;
4.10、PostgreSQL 的模式隔離性
????????PostgreSql 的模式是數據庫內的邏輯分組,不同模式可以存在同名表。這也是和 mysql 的不同之處
????????跨模式査詢需顯式指定模式名(如 aaa.t2),或通過 search path 設置默認模式。
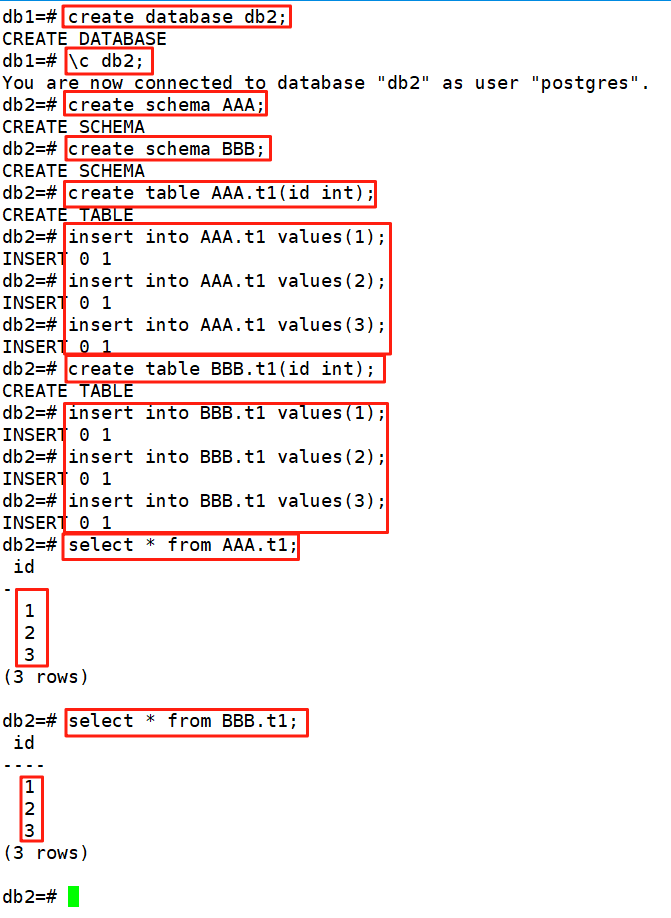
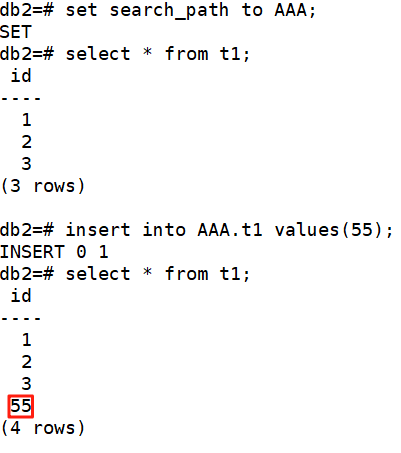
????????無需切換數據庫連接,所有操作在同一數據庫內完成。#1、創建庫 create database db2;#2、創建兩個模式AAA、BBB create schema AAA; create schema BBB;#3、創建同名表 create table AAA.t1(id int); create table BBB.t1(id int);#4、查詢內容 select * from AAA.t1; select * from BBB.t1;#5、設置默認查詢路徑 set search_path to AAA;





5、備份與恢復
????????PostgreSQL 數據庫應當被定期地備份。雖然過程相當簡單,但清晰地理解其底層技術和假設是非常重要的。
備份 PostgreSQL 數據的方法
SQL 轉儲 文件系統級備份 連續歸檔 5.1、 SQL 轉儲
????????SQL 轉儲方法的思想是創建一個由 SQL, 命令組成的文件,當把這個文件回饋給服務器時,服務器將利用其中的SQL 命令重建與轉儲時狀態一樣的數據庫。 PostgreSql 為此提供了工具 pg dump。
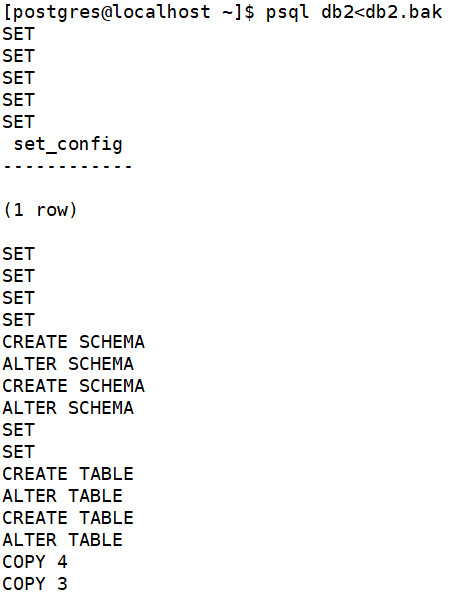
pg_dump db2>db2.bak
????????正如你所見,pgdump 把結果輸出到標準輸出。我們后面將看到這樣做有什么用處。 盡管上述命令會創建一個文本文件,pg dump 可以用其他格式創建文件以支持并行 和細粒度的對象恢復控制。
????????pg dump 是一個普通的 PostgreSqL, 客戶端應用(盡管是個 相當聰明的東西)這就意味著你可以在任何可以訪問該數據庫的遠端主機上進行備份工作。但是請記住pgdump不會以任何特殊權限運行。具體說來,就是它必須要有你想備份的表的讀 權限,因此為了備份整個數據庫你幾乎總是必須以一個數據庫超級用戶來運行它(如果你沒有足夠的特權 來備份整個數據庫,你仍然可以使用諸如n schema 或-t table選項來備份該數據庫中你能夠 訪問的部分)
????????要聲明pgdump連接哪個數據庫服務器,使用命令行選項-h host和 -p port。默認主機是本地主機或你的 PGHOST 環境變量指定的主機。 類似地,默認端口是環境變量 PGPORT 或(如PGPORT 不存在)內建的默認值。(服務器通常有相同的默認值,所以還算方便。)
????????和任何其他 PostgreSQL 客戶端應用一樣, pg dump 默認使用與當前操作系統用戶名同名的數據庫用戶名進行連接。要使用其他名字,要么聲明-U選項,要么設置環境變量 PGUSER。請注意 pg_dump 的連接也要通過客戶認證機制。
????????pg_dump 對于其他備份方法的一個重要優勢是,pg dump 的輸出可以很容易地在新版本的 PostgreSqL 中載入,而文件級備份和連續歸檔都是極度的服務器版本限定的。pg_dump 也是唯一可以將一個數據庫傳送到一個不同機器架構上的方法,例如從一個 32 位服務器到一個 64 位服務器.
????????由 pg_dump 創建的備份在內部是一致的,也就是說,轉儲表現了 pg_dump開始運行時刻的數據庫快照,且在 pg_dump 運行過程中發生的更新將不會被轉儲pg_dump 工作的時候并不阻塞其他的對數據庫的操作。(但是會阻塞那些需要排它鎖的操作,比如大部分形式的 ALTER TABLE)5.2、從轉儲中恢復
pg_dump 生成的文本文件可以由 psql 程序讀取。 從轉儲中恢復的常用命令是
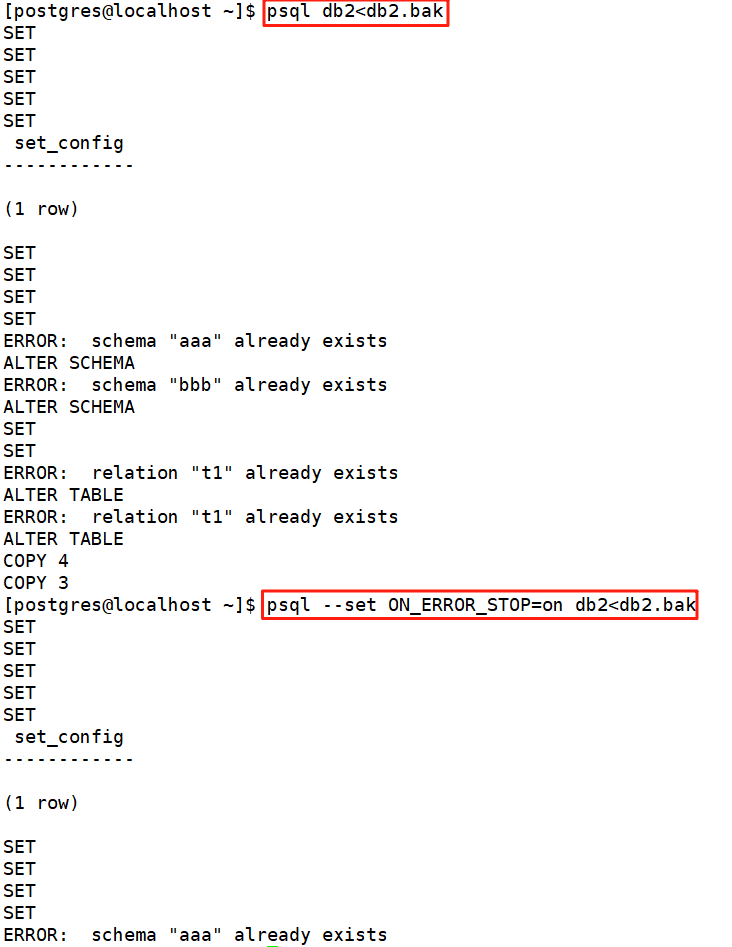
psql db2<db2.bak
其中 dumpfile 就是 pg dump 命令的輸出文件。這條命令不會創建數據庫dbname,你必須在執行 psql 前自己從 template0 創建(例如,用命令 createdb-T template0 dbname)。psql 支持類似pg dump 的選項用以指定要連接的數據庫服務器和要使用的用戶名。參閱 psql 的手冊獲取更多信息。非文本文件轉儲可以使用 pg restore 工具來恢復。
在開始恢復之前,轉儲庫中對象的擁有者以及在其上被授予了權限的用戶必須已經存在。如果它們不存在,那么恢復過程將無法將對象創建成具有原來的所屬關系以及權限(有時候這就是你所需要的,但通常不是)
默認情況下,psq1 腳本在遇到一個 SQL 錯誤后會繼續執行。你也許希望在遇到一個 SQL, 錯誤后讓 psql 退出,那么可以設置 ON ERROR STOP 變量來運行 psql,這將使 psq1 在遇到 SQL 錯誤后退出并返回狀態 :psql --set ON_ERROR_STOP=on db2<db2.bak
不管怎樣,你將只能得到一個部分恢復的數據庫。作為另一種選擇,你可以指定讓整個恢復作為一個單獨的事務運行,這樣恢復要么完全完成要么完全回滾這種模式可以通過向 psql傳遞-L?或--single-transaction 命令行選項來指定。在使用這種模式時,注意即使是很小的一個錯誤也會導致運行了數小時的恢復被回滾。但是,這仍然比在一個部分恢復后手工清理復雜的數據庫要更好。
pg dump 和 psql 讀寫管道的能力使得直接從一個服務器轉儲一個數據庫到另一個服務器成為可能,例如:
?pg_dump -h host1 dbname | psql -h host2 dbname注意:
pg_dump 產生的轉儲是相對于 template0。這意味著在 templatel 中加入的任何語言、過程等都會被 pg_dump 轉儲。結果是,如果在恢復時使用的是一個自定義的 template1,你必須從 template0 創建一個空的數據庫,正如上面的例子所示。
一旦完成恢復,在每個數據庫上運行 ANALYZE 是明智的舉動,這樣優化器就有有用的統計數據了。

6、遠程連接
6.1、編輯配置文件
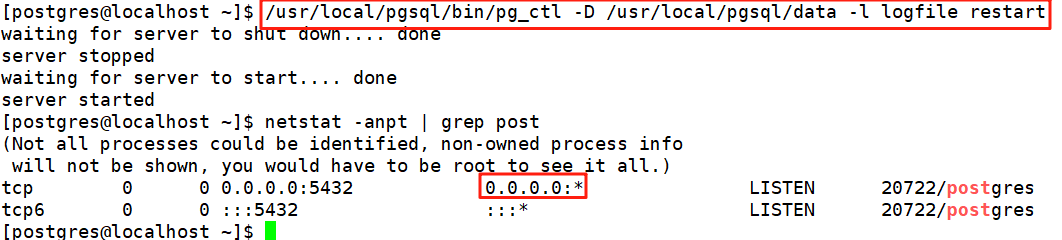
vim /usr/local/pgsql/data/postgresql.conf ###編輯內容### listen_addresses = '*'#重啟服務 /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile restart#查看監聽狀態 netstat -anpt | grep post
6.2、配置訪問權限
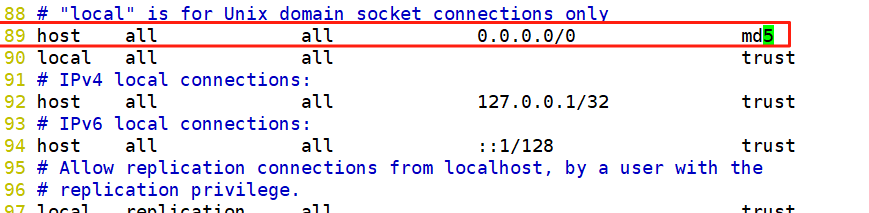
配置項 說明 host 指定連接類型,host 表示適用于 TCP/IP 遠程連接,本地連接常用 local all(數據庫) 定義適用的數據庫,all 表示所有數據庫,也可指定特定數據庫名,如 mydatabase all(用戶) 定義適用的用戶,all 表示所有用戶,也可指定特定用戶名,如 myuser 0.0.0.0/0 定義適用的客戶端 IP 地址或范圍,0.0.0.0/0 表示無 IP 地址限制,也可指定具體 IP(如 192.168.1.100 )或范圍(如 192.168.1.0/24 ) trust 定義認證方法,trust 表示無需密碼等認證可直接連接,僅適合本地或受信網絡環境(開發 / 測試),生產環境建議用更安全的如 md5、password(新版本 PostgreSQL 建議 scram - sha - 256 ) 6.2、配置用戶密碼
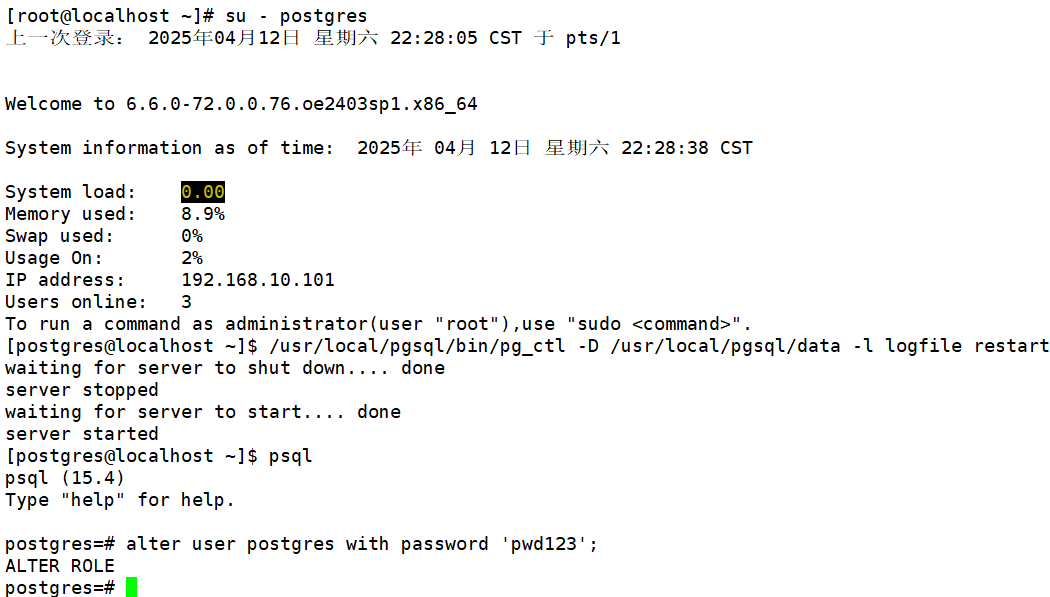
#修改用戶的認證方式 alter user postgres with password '123465';#重啟服務 /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile restart
6.3、遠程登錄
psql -h 192.168.10.101 -U postgres
rpicam-apps可用選項介紹之常用選項)
;大語言模型(LLM)詳解;Transformer 模型結構詳解;大模型三要素:T-P-G 原則)



:工作機制)
)


)









