最近需要進行電力物檢測相關的業務,因此制作了一個電力物數據集,使用YOLO目標檢測方法進行實驗,記錄實驗過程如下:
數據集標注
首先需要對電力物相關設備進行標注,這里我們選用labelme進行標注,使用無人機進行數據采集,得到了600余張圖像,我們的數據集包含三類:防振錘、間隔棒以及壓接管。
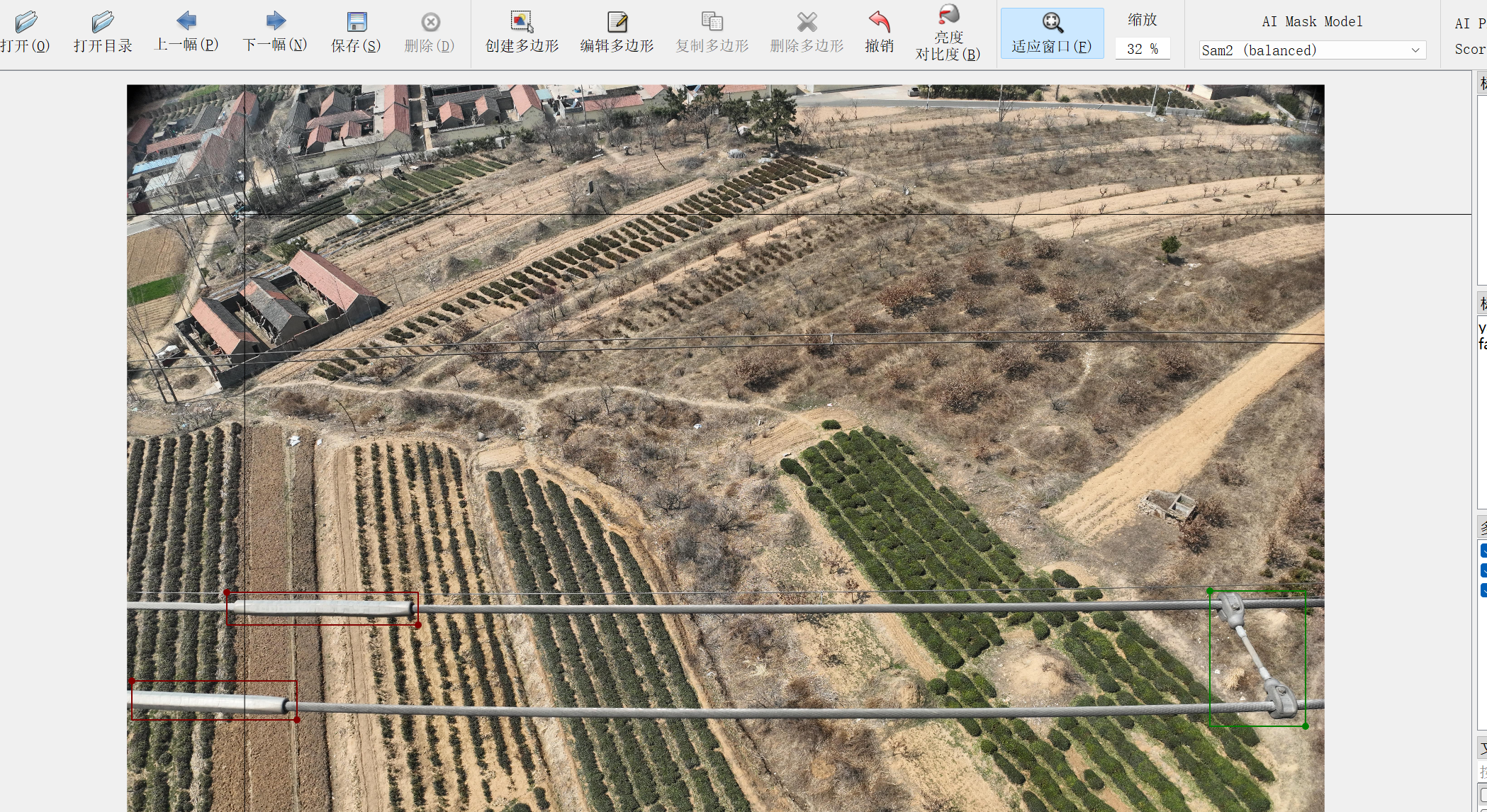
數據集轉換為YOLO格式
使用Labelme標注完后,得到的是JSON文件(COCO格式),我們需要將其進行轉換,同時,還需要將其按照8:2的比例劃分數據集,代碼如下:
import argparse
import json
import os
from tqdm import tqdm
import shutil
import random#矩形轉換
def convert_label_json(json_dir, save_dir, classes):json_paths = os.listdir(json_dir)classes = classes.split(',')if not os.path.exists(save_dir):os.makedirs(save_dir)for json_path in tqdm(json_paths):path = os.path.join(json_dir, json_path)# 嘗試多種編碼讀取 JSONjson_dict = Noneencodings = ["utf-8", "gbk"]for encoding in encodings:try:with open(path, "r", encoding=encoding) as load_f:json_dict = json.load(load_f)breakexcept (UnicodeDecodeError, json.JSONDecodeError):continueif json_dict is None:print(f"Failed to read {json_path}")continueh, w = json_dict['imageHeight'], json_dict['imageWidth']txt_path = os.path.join(save_dir, json_path.replace('.json', '.txt'))txt_file = open(txt_path, 'w')for shape_dict in json_dict['shapes']:label = shape_dict['label']label_index = classes.index(label)points = shape_dict['points']# 提取所有點的 x 和 y 坐標xs = [p[0] for p in points]ys = [p[1] for p in points]# 計算最小外接矩形x_min, x_max = min(xs), max(xs)y_min, y_max = min(ys), max(ys)# 計算中心點和寬高xc = (x_min + x_max) / 2 / wyc = (y_min + y_max) / 2 / hbw = (x_max - x_min) / wbh = (y_max - y_min) / h# 寫入 YOLO 格式line = f"{label_index} {xc:.6f} {yc:.6f} {bw:.6f} {bh:.6f}\n"txt_file.write(line)txt_file.close()# 檢查文件夾是否存在
def mkdir(path):if not os.path.exists(path):os.makedirs(path)def split_datasets(image_dir, txt_dir, save_dir):# 創建文件夾mkdir(save_dir)images_dir = os.path.join(save_dir, 'images')labels_dir = os.path.join(save_dir, 'labels')img_train_path = os.path.join(images_dir, 'train')img_test_path = os.path.join(images_dir, 'test')img_val_path = os.path.join(images_dir, 'val')label_train_path = os.path.join(labels_dir, 'train')label_test_path = os.path.join(labels_dir, 'test')label_val_path = os.path.join(labels_dir, 'val')mkdir(images_dir)mkdir(labels_dir)mkdir(img_train_path)mkdir(img_test_path)mkdir(img_val_path)mkdir(label_train_path)mkdir(label_test_path)mkdir(label_val_path)# 數據集劃分比例,訓練集75%,驗證集15%,測試集15%,按需修改train_percent = 0.8val_percent = 0.2test_percent = 0total_txt = os.listdir(txt_dir)num_txt = len(total_txt)list_all_txt = range(num_txt) # 范圍 range(0, num)num_train = int(num_txt * train_percent)num_val = int(num_txt * val_percent)num_test = num_txt - num_train - num_valtrain = random.sample(list_all_txt, num_train)# 在全部數據集中取出trainval_test = [i for i in list_all_txt if not i in train]# 再從val_test取出num_val個元素,val_test剩下的元素就是testval = random.sample(val_test, num_val)print("訓練集數目:{}, 驗證集數目:{},測試集數目:{}".format(len(train), len(val), len(val_test) - len(val)))for i in list_all_txt:name = total_txt[i][:-4]srcImage = os.path.join(image_dir, name + '.jpg')srcLabel = os.path.join(txt_dir, name + '.txt')if i in train:dst_train_Image = os.path.join(img_train_path, name + '.jpg')dst_train_Label = os.path.join(label_train_path, name + '.txt')shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)elif i in val:dst_val_Image = os.path.join(img_val_path, name + '.jpg')dst_val_Label = os.path.join(label_val_path, name + '.txt')shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)else:dst_test_Image = os.path.join(img_test_path, name + '.jpg')dst_test_Label = os.path.join(label_test_path, name + '.txt')shutil.copyfile(srcImage, dst_test_Image)shutil.copyfile(srcLabel, dst_test_Label)if __name__=="__main__":# labelme生成的json格式標注轉為yolov8支持的txt格式"""python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dogs""""parser = argparse.ArgumentParser(description='json convert to txt params')parser.add_argument('--json-dir', type=str,default='D:\project_mine\detection\datasets/fangxiandata\data/labels', help='json path dir')parser.add_argument('--save-dir', type=str,default='D:\project_mine\detection\datasets/fangxiandata\data/outputs' ,help='txt save dir')parser.add_argument('--classes', type=str, default='fangzhenchui,jiangebang,yajieguan',help='classes')#,道路,房屋,水渠,橋args = parser.parse_args()json_dir = args.json_dirsave_dir = args.save_dirclasses = args.classesconvert_label_json(json_dir, save_dir, classes)# 將圖片和標注數據按比例切分為 訓練集和測試集# """# python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data# """parser = argparse.ArgumentParser(description='split datasets to train,val,test params')parser.add_argument('--image-dir', type=str,default='D:\project_mine\detection\datasets/fangxiandata\data/images', help='image path dir')parser.add_argument('--txt-dir', type=str,default='D:\project_mine\detection\datasets/fangxiandata\data/outputs' , help='txt path dir')parser.add_argument('--save-dir', default='D:\project_mine\detection\datasets/fangxian',type=str, help='save dir')args_split = parser.parse_args()image_dir = args_split.image_dirtxt_dir = args_split.txt_dirsave_dir_split = args_split.save_dirsplit_datasets(image_dir, txt_dir, save_dir_split)
數據集配置
我們的數據集放到了fangxian文件夾中,需要設置對應的數據集配置文件:
path: ../datasets/fangxian # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:0: fangzhenchui1: jiangebang2: yajieguan
開啟訓練
我們使用YOLO11網絡,設置batch為8,epoch為100
from ultralytics import YOLO
model=YOLO("yolo11.yaml")
# Train the model
results = model.train(data="fangxian.yaml",epochs=100,batch=8, # 根據GPU顯存調整(T4建議batch=8)imgsz=640,device="0", # 指定GPU IDoptimizer="AdamW",lr0=1e-4,warmup_epochs=4,label_smoothing=0.1,amp=True)

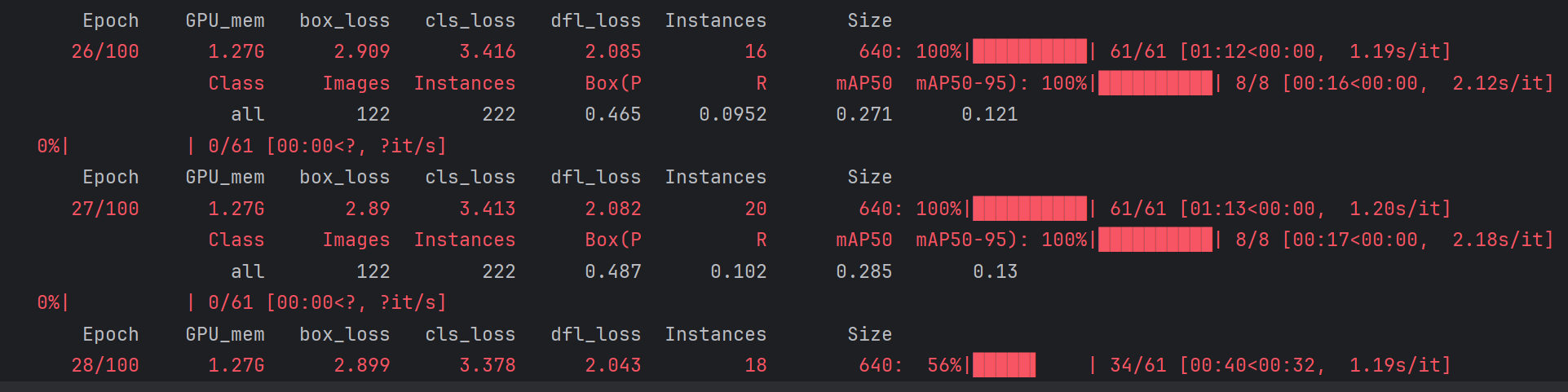
訓練過程
從訓練過程來看,這個數據集可能較為復雜,且博主沒有使用任何預訓練模型,因此其擬合的較慢,前十幾個epoch都均為0,但從第20個epoch開始,其AP值逐漸有起色

隨后AP便逐漸正常了。
















![[electron]預腳本不顯示內聯script](http://pic.xiahunao.cn/[electron]預腳本不顯示內聯script)


