目錄
一、散點圖
二、氣泡圖
三、相關圖
四、熱力圖
五、二維密度圖
六、多模態二維密度圖
七、雷達圖
八、桑基圖
九、總結
一、散點圖
特點
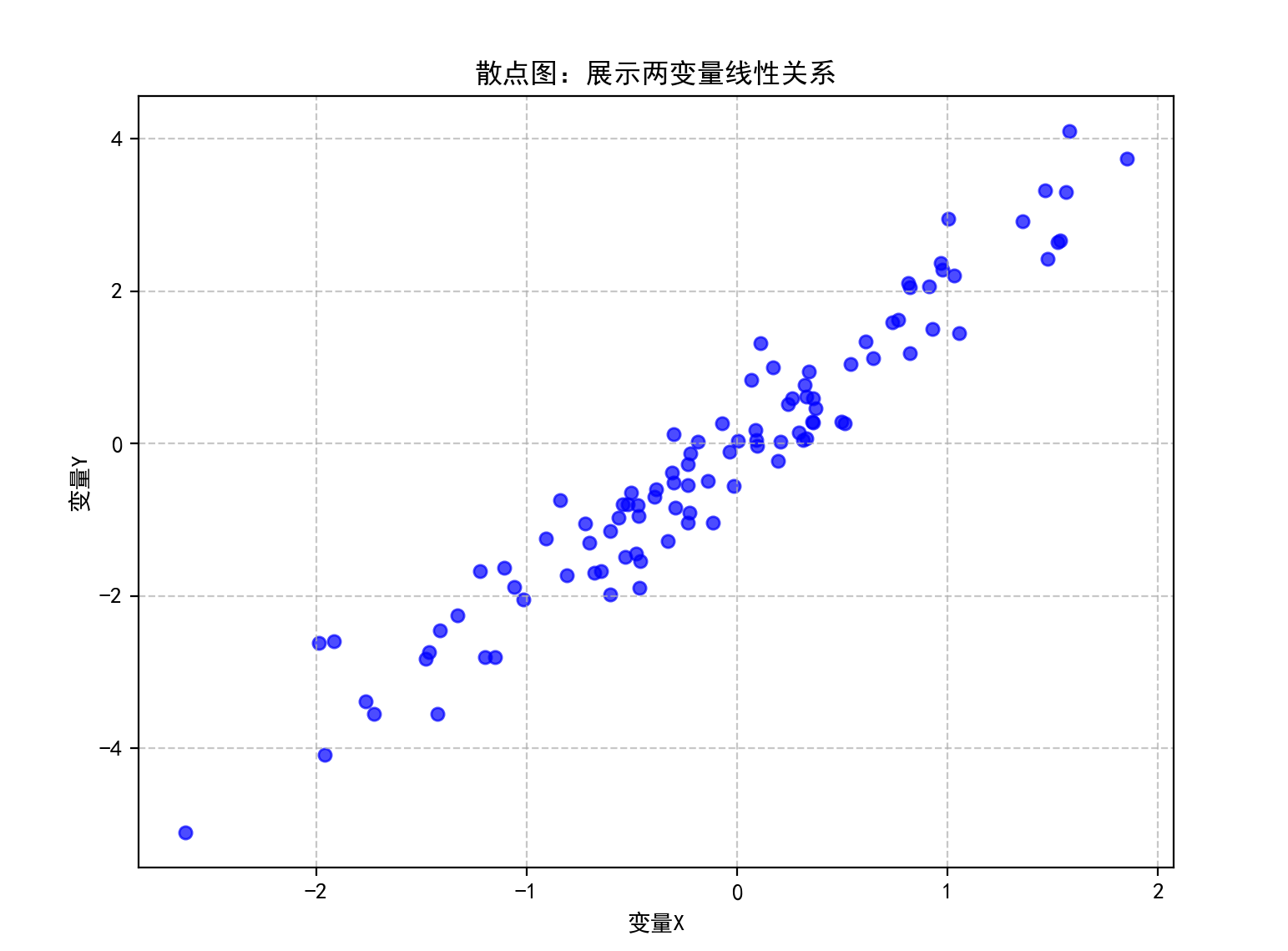
????????通過點的位置展示兩個連續變量之間的關系,可直觀判斷線性相關、非線性相關或無相關關系,點的分布密度和趨勢反映相關性強弱。
應用場景
????????探索性數據分析、驗證變量間關系假設,如身高與體重的關系、溫度與銷售額的關聯。
實現過程
import numpy as np
import matplotlib.pyplot as plt
# 設置支持中文的字體
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "sans-serif"]
# 解決負號顯示問題
plt.rcParams["axes.unicode_minus"] = False
# 生成示例數據
np.random.seed(42)
x = np.random.randn(100)
y = 2 * x + np.random.randn(100) * 0.5
# 繪制散點圖
plt.figure(figsize=(8, 6))
plt.scatter(x, y, color='blue', alpha=0.7, s=30)
plt.title('散點圖:展示兩變量線性關系')
plt.xlabel('變量X')
plt.ylabel('變量Y')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
# 計算相關系數
correlation = np.corrcoef(x, y)[0, 1]
print(f'皮爾遜相關系數: {correlation:.4f}')
結果
二、氣泡圖
特點
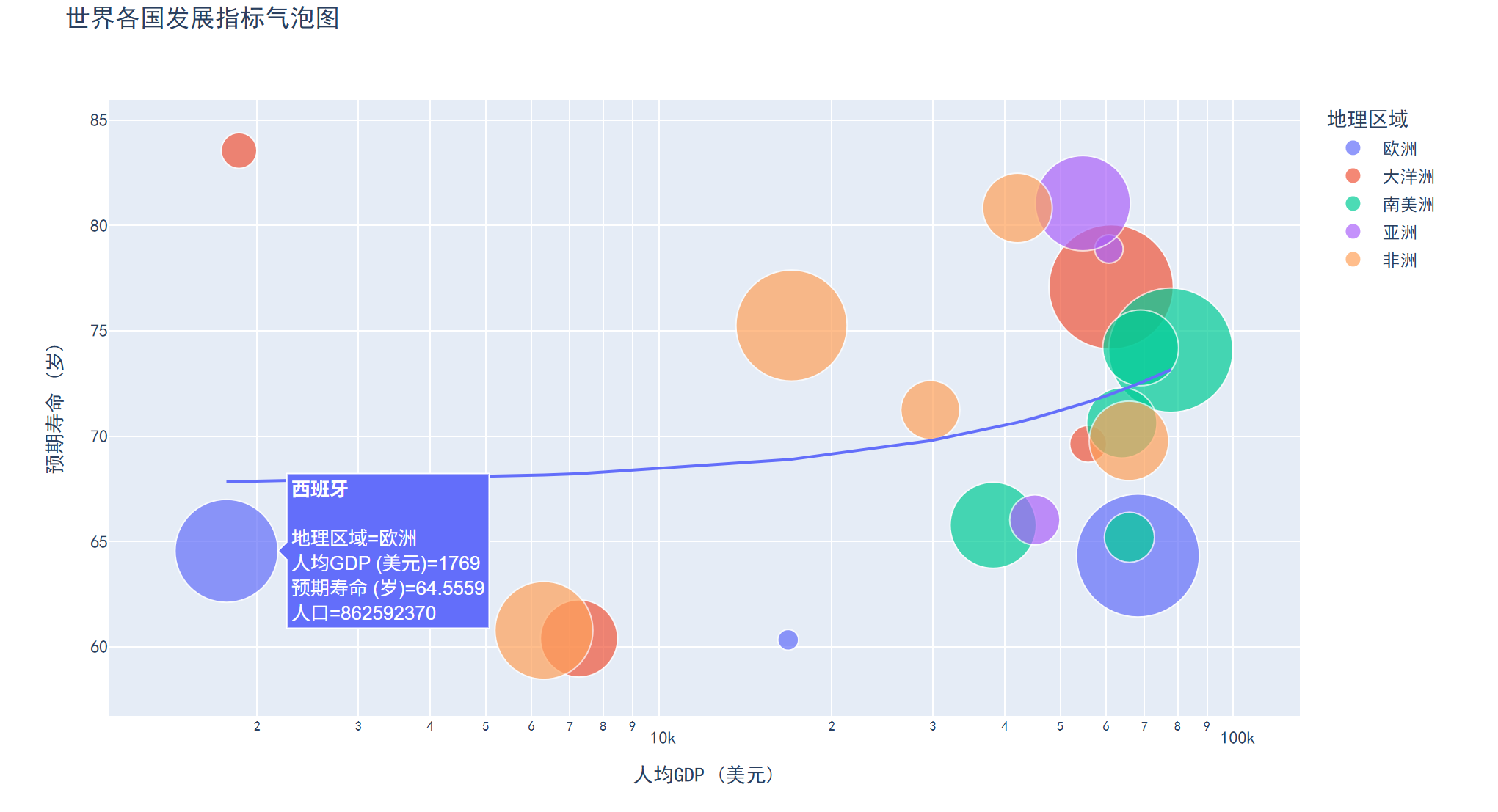
????????在散點圖基礎上增加第三個變量(氣泡大小),可展示三維數據關系,氣泡顏色還可表示第四維變量。
應用場景
????????市場分析(如銷售額、利潤、市場份額)、城市數據可視化(人口、GDP、面積)。
實現過程
import plotly.express as px
import pandas as pd
import numpy as np
# 設置隨機種子
np.random.seed(42)
# 生成模擬數據
n_countries = 20
countries = ['中國', '美國', '日本', '德國', '法國', '英國', '意大利', '加拿大','俄羅斯', '巴西', '印度', '澳大利亞', '西班牙', '墨西哥', '韓國','印度尼西亞', '土耳其', '沙特阿拉伯', '瑞士', '荷蘭'
]
# 生成隨機數據
gdp_per_capita = np.random.randint(1000, 80000, n_countries)
population = np.random.randint(5e6, 1.5e9, n_countries)
life_expectancy = np.random.uniform(60, 85, n_countries)
region = np.random.choice(['亞洲', '歐洲', '北美洲', '南美洲', '非洲', '大洋洲'], n_countries)
# 創建DataFrame
df = pd.DataFrame({'國家': countries,'人均GDP': gdp_per_capita,'人口': population,'預期壽命': life_expectancy,'地區': region
})
# 創建氣泡圖
fig = px.scatter(df, x="人均GDP", y="預期壽命", size="人口", color="地區",hover_name="國家", log_x=True, size_max=60,title="世界各國發展指標氣泡圖",labels={"人均GDP": "人均GDP (美元)","預期壽命": "預期壽命 (歲)","地區": "地理區域"})
# 更新布局
fig.update_layout(font=dict(family="SimHei", size=12),legend_title="地理區域",height=600,width=1000
)
# 添加趨勢線
fig.add_traces(px.scatter(df, x="人均GDP", y="預期壽命", trendline="ols").data[1]
)
# 顯示圖表
fig.show()
# 導出為HTML文件
fig.write_html("bubble_chart.html")
結果
三、相關圖
特點
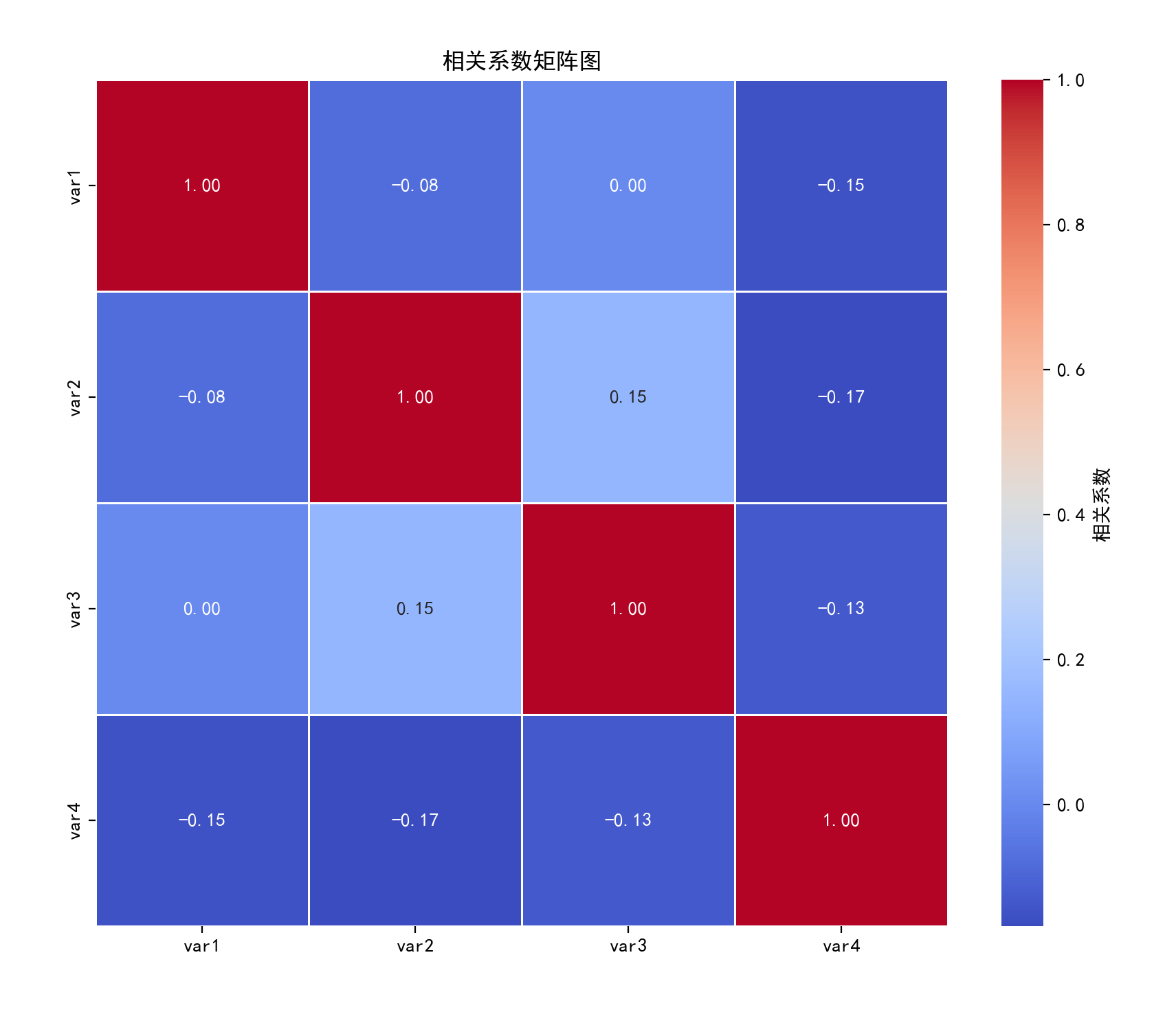
????????展示多個變量間的相關系數矩陣,通常以數值或圖形(如顏色、形狀)表示相關強度和方向。
應用場景
????????多變量數據分析、特征選擇(如機器學習前篩選相關變量)。
實現過程
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 設置中文字體
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 生成示例數據
np.random.seed(42)
data = pd.DataFrame({'var1': np.random.randn(100),'var2': 0.8 * np.random.randn(100) + 0.2 * np.random.randn(100),'var3': -0.5 * np.random.randn(100) + 0.5 * np.random.randn(100),'var4': np.random.randn(100)
})
# 計算相關系數矩陣
corr_matrix = data.corr()
# 繪制相關圖
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f',linewidths=1, cbar_kws={'label': '相關系數'})
plt.title('相關系數矩陣圖')
plt.show()結果
四、熱力圖
特點
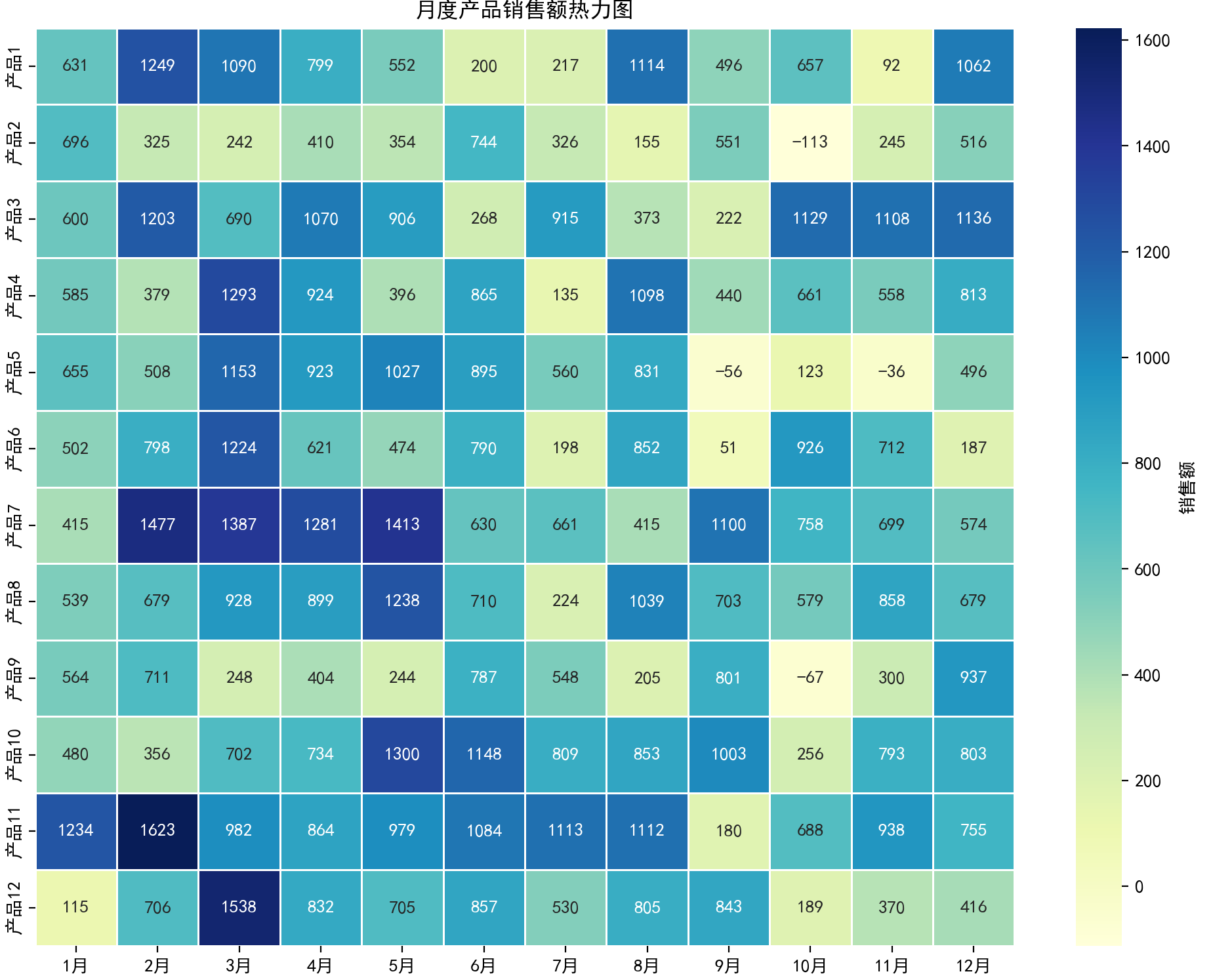
????????用顏色矩陣展示數據值大小,可直觀呈現二維數據的分布模式和熱點區域。
應用場景
????????基因表達數據、時間序列數據(如年度銷售熱力圖)、矩陣數據可視化。
實現過程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.cluster import hierarchy
# 設置中文字體
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 生成示例數據:月度銷售數據
np.random.seed(42)
n_products = 12
n_months = 12
# 創建產品名稱和月份名稱
products = [f'產品{i+1}' for i in range(n_products)]
months = [f'{i+1}月' for i in range(n_months)]
# 生成基礎銷售數據(有季節性和產品類別效應)
base_sales = np.random.rand(n_products, n_months) * 1000
# 添加季節性效應
seasonal_effect = np.sin(np.linspace(0, 2*np.pi, n_months)) * 300
for i in range(n_products):base_sales[i, :] += seasonal_effect * (0.5 + i/24)
# 添加產品類別效應
category_effect = np.random.rand(n_products) * 500
for i in range(n_products):base_sales[i, :] += category_effect[i]
# 添加隨機噪聲
sales_data = base_sales + np.random.randn(n_products, n_months) * 100
# 轉換為DataFrame
df = pd.DataFrame(sales_data, index=products, columns=months)
plt.figure(figsize=(12, 10))
sns.heatmap(df, cmap="YlGnBu", annot=True, fmt=".0f",linewidths=0.5, cbar_kws={"label": "銷售額"})
plt.title('月度產品銷售額熱力圖')
plt.tight_layout()
plt.show()結果
五、二維密度圖
特點
????????通過顏色或等高線展示二維數據的分布密度,比散點圖更適合大數據量場景,可識別數據聚類和分布形態。
應用場景
????????概率密度分析、金融數據分布(如股票收益率)、空間數據熱點分析。
實現過程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 設置中文字體
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
n_samples = 1000
mean = [0, 0]
cov = [[1, 0.7], [0.7, 1]]
x, y = np.random.multivariate_normal(mean, cov, n_samples).T
# 創建DataFrame
df_single = pd.DataFrame({'X': x,'Y': y
})
# 繪制二維密度圖
plt.figure(figsize=(12, 10))
sns.kdeplot(x='X', y='Y', data=df_single, fill=True, cmap='Blues', alpha=0.7)
plt.title('二維密度圖')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()結果

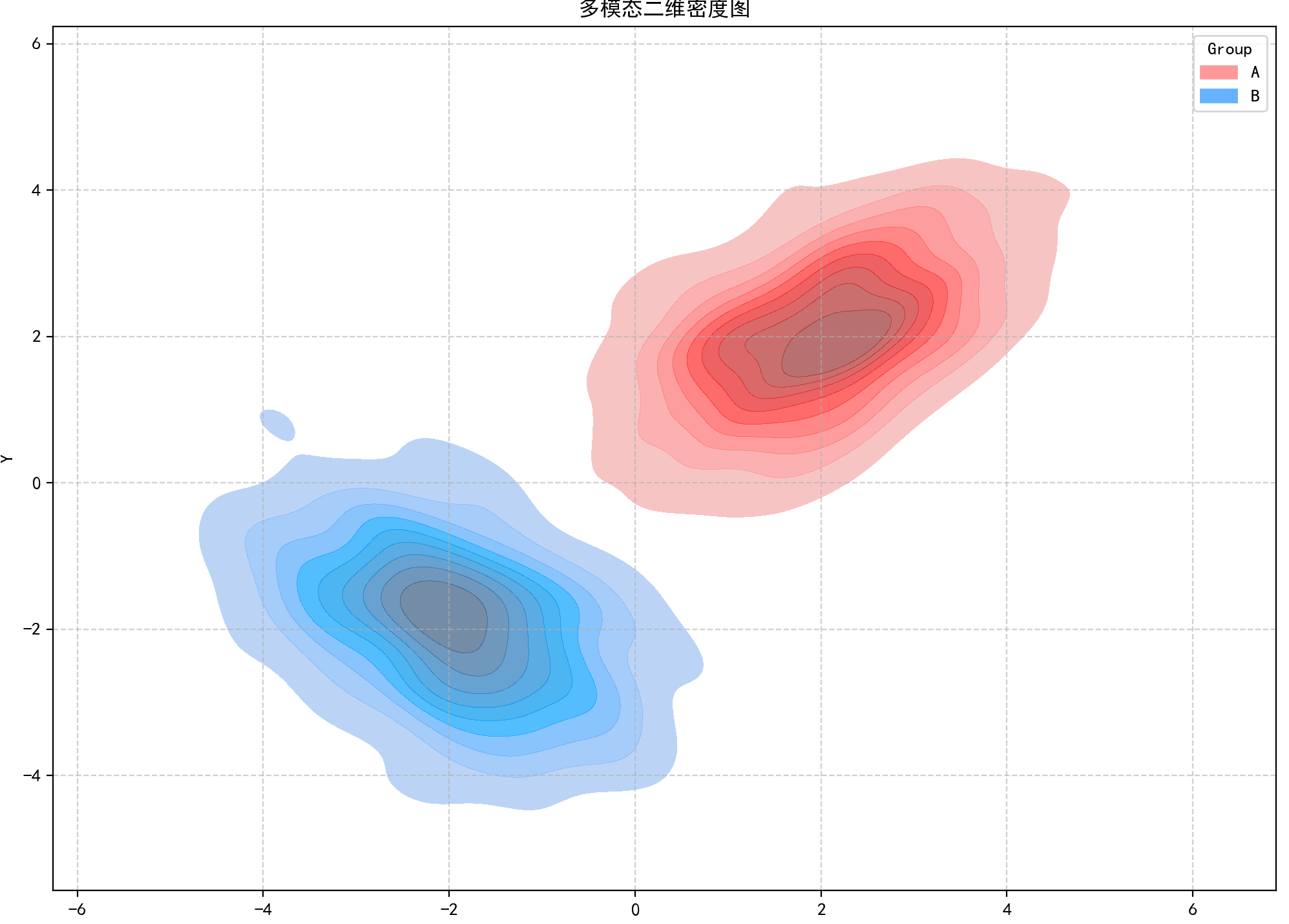
六、多模態二維密度圖
特點
????????捕捉數據中多個密度峰值(模態),反映復雜集群結構,無需預設聚類數。
應用場景
????????客戶分群(消費行為)、金融風險(市場狀態分類)、生物信息(細胞亞型)。
實現過程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 設置中文字體
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 2. 多模態分布
# 創建兩個不同的分布
n1 = 800
n2 = 500
# 第一個分布
mean1 = [2, 2]
cov1 = [[1, 0.5], [0.5, 1]]
x1, y1 = np.random.multivariate_normal(mean1, cov1, n1).T
# 第二個分布
mean2 = [-2, -2]
cov2 = [[1, -0.5], [-0.5, 1]]
x2, y2 = np.random.multivariate_normal(mean2, cov2, n2).T
# 合并數據
x_multi = np.concatenate([x1, x2])
y_multi = np.concatenate([y1, y2])
groups = np.concatenate([['A']*n1, ['B']*n2])
# 創建DataFrame
df_multi = pd.DataFrame({'X': x_multi,'Y': y_multi,'Group': groups
})
# 繪制多模態二維密度圖
plt.figure(figsize=(12, 10))
sns.kdeplot(x='X', y='Y', hue='Group', data=df_multi,fill=True, common_norm=False, alpha=0.7,palette=['#FF9999', '#66B2FF'])
plt.title('多模態二維密度圖')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()結果
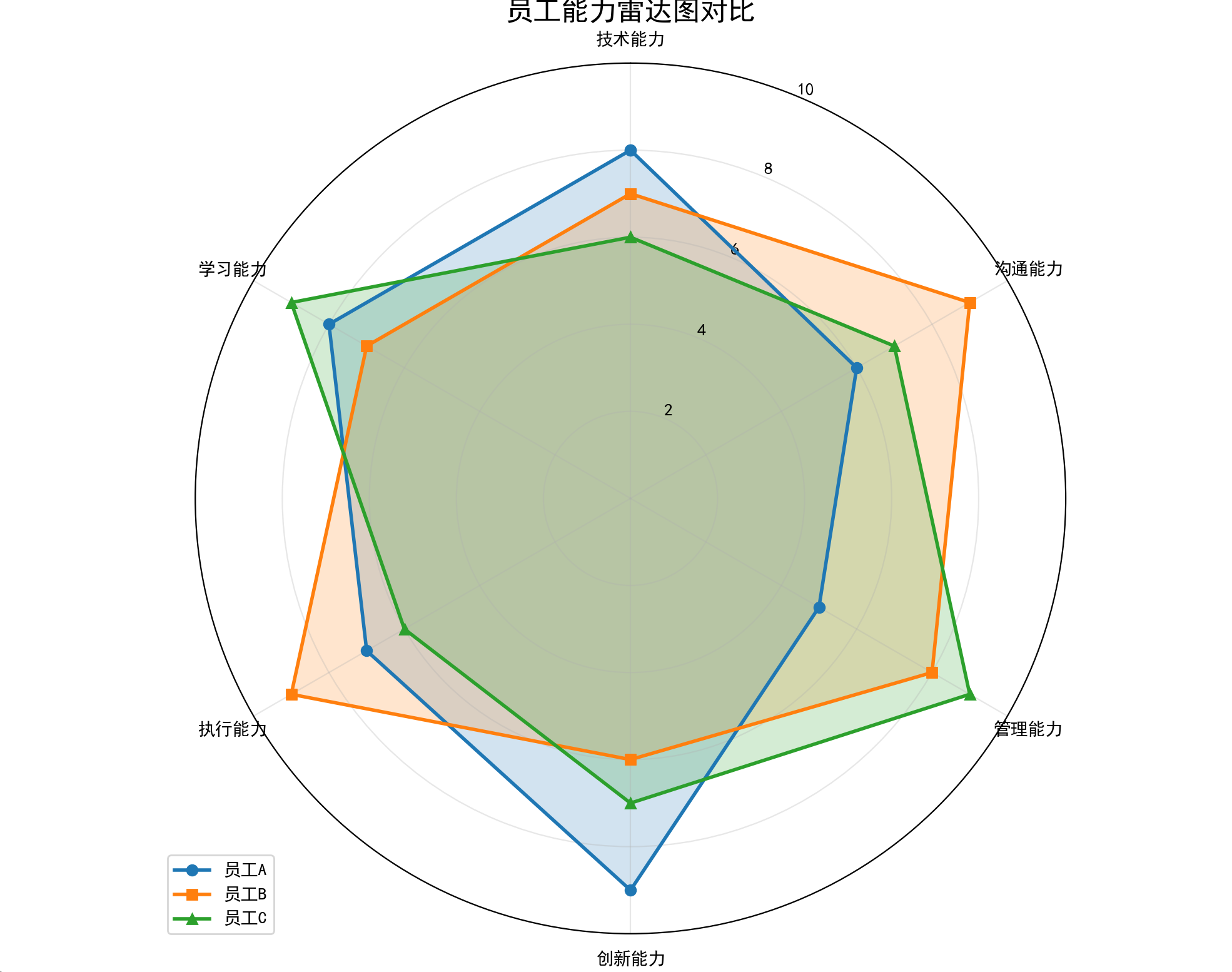
七、雷達圖
特點
????????以原點為中心輻射出多條坐標軸,每個樣本用多邊形連接各維度值,直觀比較多變量綜合表現。適合展示樣本在多個維度的均衡性或偏科情況。
應用場景
????????產品多維度評分(如手機的性能、價格、續航、拍照等)。人才評估(如員工的溝通、技術、管理、創新能力)。競爭對手分析(多指標對比)。
實現過程
import numpy as np
import matplotlib.pyplot as plt
# 設置中文字體
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False
# 定義評估維度
dimensions = ['技術能力', '溝通能力', '管理能力', '創新能力', '執行能力', '學習能力']
n_dims = len(dimensions)
# 生成3名員工的評分數據(1-10分)
employee1 = [8, 6, 5, 9, 7, 8] # 技術和創新突出
employee2 = [7, 9, 8, 6, 9, 7] # 溝通和執行突出
employee3 = [6, 7, 9, 7, 6, 9] # 管理和學習突出
# 準備雷達圖數據(閉合多邊形)
angles = np.linspace(0, 2*np.pi, n_dims, endpoint=False).tolist()
employee1 += employee1[:1]
employee2 += employee2[:1]
employee3 += employee3[:1]
angles += angles[:1]
# 繪制雷達圖
plt.figure(figsize=(10, 10))
ax = plt.subplot(111, polar=True)
# 繪制各維度網格線
ax.set_theta_offset(np.pi/2) # 起始角度設為上方
ax.set_theta_direction(-1) # 順時針旋轉
ax.set_thetagrids(np.degrees(angles[:-1]), dimensions)
ax.set_ylim(0, 10)
ax.grid(True, alpha=0.3)
# 繪制員工評分
ax.plot(angles, employee1, 'o-', linewidth=2, label='員工A')
ax.fill(angles, employee1, alpha=0.2)
ax.plot(angles, employee2, 's-', linewidth=2, label='員工B')
ax.fill(angles, employee2, alpha=0.2)
ax.plot(angles, employee3, '^-', linewidth=2, label='員工C')
ax.fill(angles, employee3, alpha=0.2)
# 添加圖例和標題
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
plt.title('員工能力雷達圖對比', fontsize=16)
plt.tight_layout()
plt.show()結果
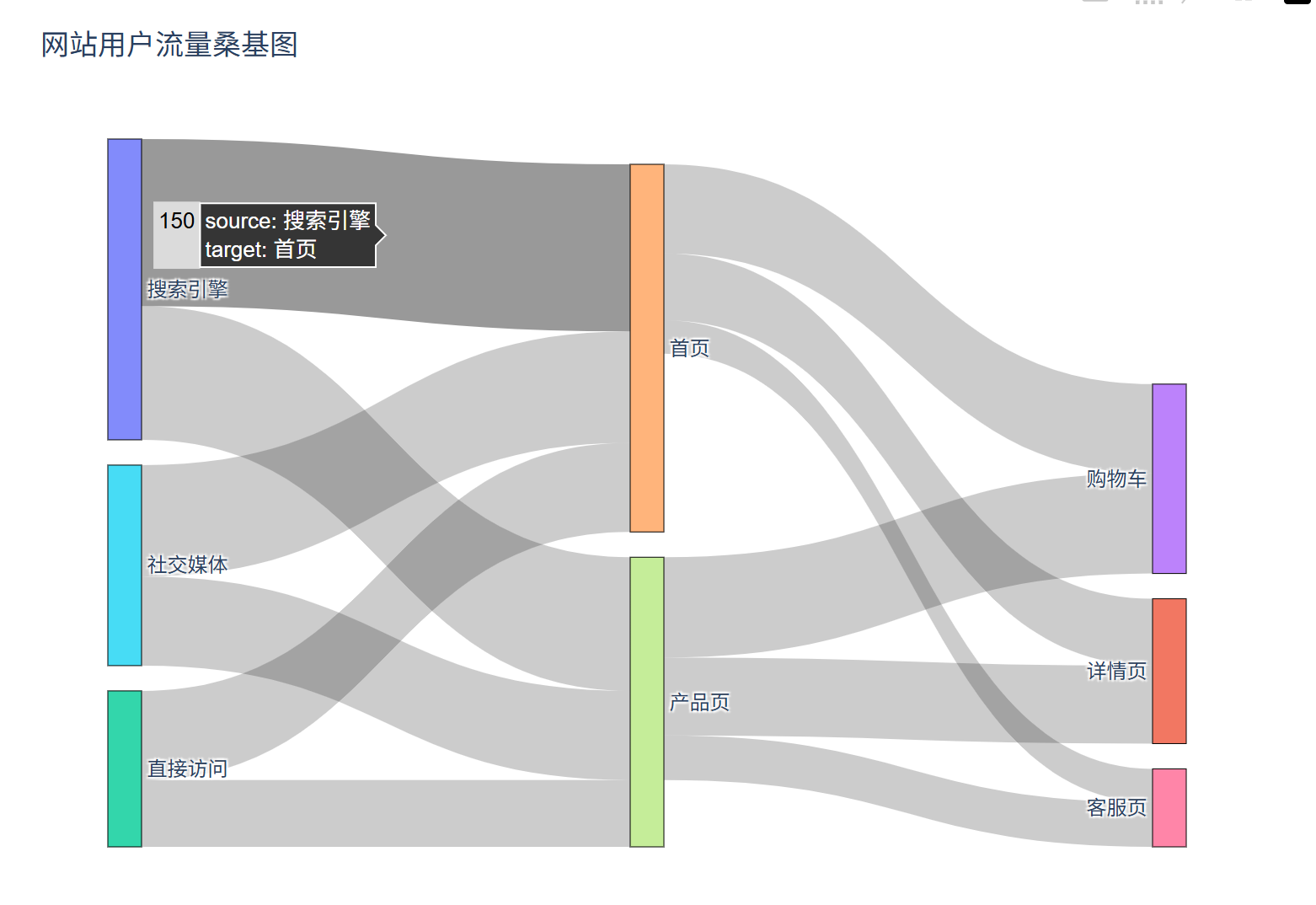
八、桑基圖
特點
????????用帶箭頭的流線表示數據流向,流線寬度反映流量大小,適合展示物質、能量、資金等的傳遞路徑與分配比例。
應用場景
????????供應鏈分析(原材料→加工→成品的價值流動)。網站流量分析(用戶從不同渠道到各頁面的跳轉路徑)。
實現過程
import plotly.graph_objects as go
import pandas as pd
# 生成用戶流量數據(渠道→頁面→轉化的流向)
source = ['搜索引擎', '社交媒體', '直接訪問', '搜索引擎', '社交媒體', '直接訪問','產品頁', '產品頁', '產品頁', '首頁', '首頁', '首頁']
target = ['首頁', '首頁', '首頁', '產品頁', '產品頁', '產品頁','購物車', '詳情頁', '客服頁', '購物車', '詳情頁', '客服頁']
value = [150, 100, 80, 120, 80, 60, 90, 70, 40, 80, 60, 30] # 流量值
# 創建DataFrame
data = pd.DataFrame({'source': source,'target': target,'value': value
})
# 定義節點標簽
all_nodes = list(set(source + target))
node_indices = {node: i for i, node in enumerate(all_nodes)}
data['source_idx'] = data['source'].map(node_indices)
data['target_idx'] = data['target'].map(node_indices)
# 繪制桑基圖
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=all_nodes),link=dict(source=data['source_idx'],target=data['target_idx'],value=data['value'])
)])
# 更新布局
fig.update_layout(title_text="網站用戶流量桑基圖",width=800,height=600
)
fig.show()結果
九、總結
| 圖表類型 | 特點 | 應用場景 | 優點 | 缺點 |
|---|---|---|---|---|
| 散點圖 | 兩點坐標展示變量關系 | 探索兩變量關聯、異常值檢測 | 直觀易讀,發現線性關系 | 僅支持兩變量,大數據量易亂 |
| 氣泡圖 | 散點 + 大小 / 顏色展示 3-4 維數據 | 市場分析、城市數據可視化 | 多維數據同屏展示,信息密度高 | 維度過多易重疊,布局復雜 |
| 相關圖 | 矩陣展示多變量相關系數 | 特征選擇、多變量探索 | 全面呈現相關性,數值顏色雙標注 | 僅反映線性相關,需結合驗證 |
| 熱力圖 | 顏色矩陣展示二維數據分布 | 基因表達、時間序列、點擊數據 | 突出熱點區域,適合模式識別 | 數值精度低,顏色映射需謹慎 |
| 二維密度圖 | 等高線 / 顏色展示數據分布密度 | 金融數據、空間數據、生物數據 | 識別聚類和密度峰值,適合大數據 | 抽象度高,參數影響結果 |
| 多模態密度圖 | 捕捉數據多個密度峰值 | 客戶分群、金融風險、細胞亞型 | 自動識別集群,無需預設聚類數 | 計算復雜,對噪聲敏感 |
| 雷達圖 | 多軸多邊形展示多維度均衡性 | 產品對比、能力評估、綜合實力分析 | 直觀展示優劣維度,適合綜合評估 | 維度限≤8,數值比較不精確 |
| 桑基圖 | 流線寬度展示數據流向與流量 | 供應鏈、流量分析、貿易進出口 | 清晰展示流動路徑,流量對比直觀 | 節點過多易混亂,布局較復雜 |



)
)


)




)






