?Application of YOLOv8 in monocular downward multiple Car Target detection?????
原文真離譜,文章都不全還發上來
引言
自動駕駛技術是21世紀最重要的技術發展之一,有望徹底改變交通安全和效率。任何自動駕駛系統的核心都依賴于通過精確物體檢測來感知和理解其環境的關鍵能力。佐治亞理工學院呂詩杰的這篇論文通過提出對YOLOv8物體檢測框架的增強,解決了自動駕駛計算機視覺中的基本挑戰。
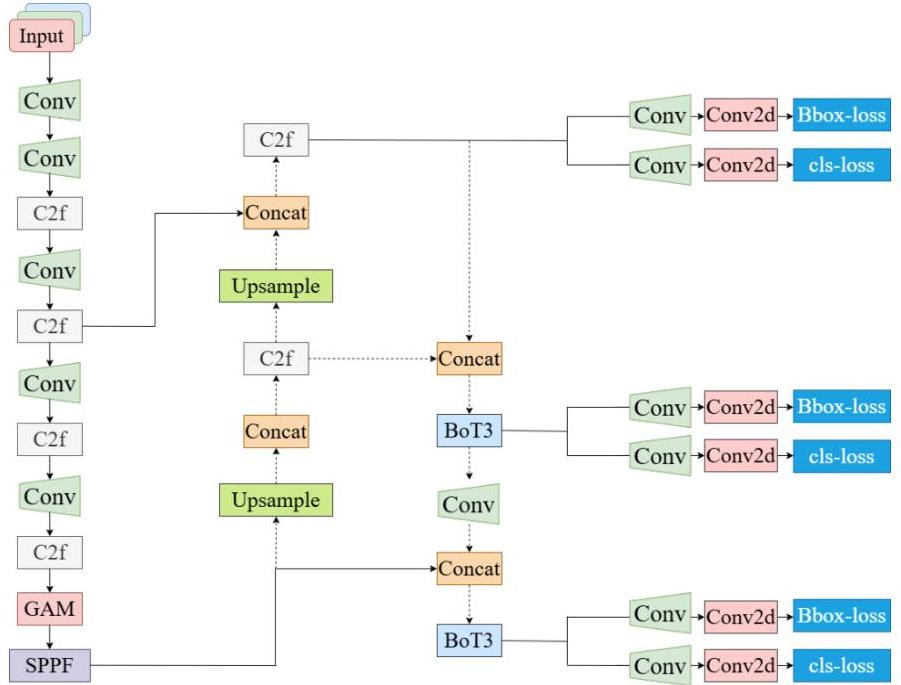
圖1:改進后的YOLOv8架構概述,展示了增強的骨干網絡、頸部網絡和檢測頭組件
該研究特別針對多尺度、小型和遠距離物體的檢測——這些挑戰對于像中國大學生方程式汽車大賽(FSAC)這樣的自動駕駛競賽尤為重要,因為精確快速的目標識別對于安全導航和競爭表現至關重要。
研究背景與動機
當前的自動駕駛系統依賴于各種傳感器技術,包括雷達、攝像頭、激光雷達和超聲波傳感器。然而,每種技術都存在影響實際性能的明顯局限性:
- 雷達系統在惡劣天氣條件和反光表面上精度下降
- 基于攝像頭的系統極易受光照條件和天氣變化的影響,盡管它們提供了豐富的視覺信息
- 高性能傳感器如激光雷達成本高昂,限制了其廣泛應用
- 分辨率限制尤其影響小型或遠距離物體的檢測
該研究通過專注于改進基于攝像頭的物體檢測來解決這些挑戰,這提供了一種更具成本效益的解決方案,同時保持了高性能。YOLO(You Only Look Once)系列模型特別適合此應用,因為它們在速度和精度之間取得了卓越的平衡,使其成為實時自動駕駛應用的理想選擇。
方法論概述
研究方法的核心是通過三項主要的架構改進來增強YOLOv8框架,這些改進旨在解決多尺度物體檢測中的特定挑戰:
- 骨干網絡增強:通過不同分支塊(DBB)集成結構重參數化技術
- 頸部結構改進:實現雙向金字塔網絡模型
- 管道優化:開發新的檢測管道結構
這些修改協同作用,在保持計算效率以實現實時應用的同時,提高了網絡檢測不同尺度物體的能力。
架構改進
C2f-DBB模塊集成
第一個主要增強是在骨干網絡中引入了不同分支塊(DBB)。DBB方法通過集成多個分支來解決多尺度特征提取的挑戰,這些分支專注于輸入圖像的不同尺度和語義方面。
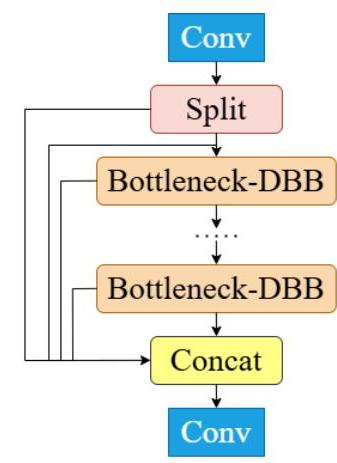
圖2:C2f-DBB模塊結構,顯示了分割、瓶頸-DBB塊和拼接操作
DBB模塊與結構重參數化技術相結合,使得網絡在訓練期間能夠保持多個分支以增強特征學習,然后在推理時將其融合為更簡單的結構以提高效率。這種方法提供了:
- 增強的多尺度特征提取能力
- 改進對小型和遠距離目標的檢測
- 推理時保持計算效率
雙向金字塔網絡
第二個改進是用雙向金字塔結構取代了原有的單向路徑聚合特征金字塔網絡(PAFPN)。原有的PAFPN的單向性限制了多尺度特征的有效整合,特別是影響了不同尺度目標的性能。
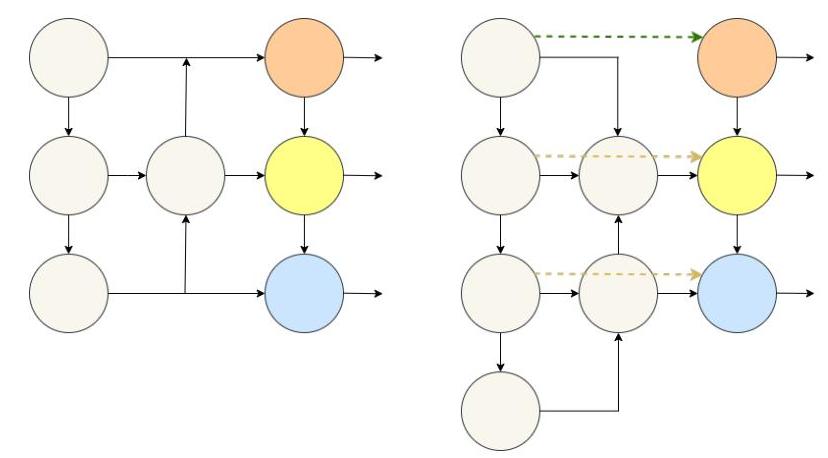
圖3:單向(左)與雙向(右)金字塔網絡結構對比,展示了雙向方法中增強的信息流
雙向設計實現了:
- 信息在自上而下和自下而上兩個方向流動
- 更全面的跨尺度特征融合
- 增強了多尺度目標檢測的性能
- 提高了小型和遠距離目標識別的準確性
注意力機制集成
本研究還引入了注意力機制,以進一步增強特征表示并聚焦于相關的圖像區域。注意力模塊幫助網絡優先處理重要特征,同時抑制噪聲,從而有助于更準確的目標檢測。
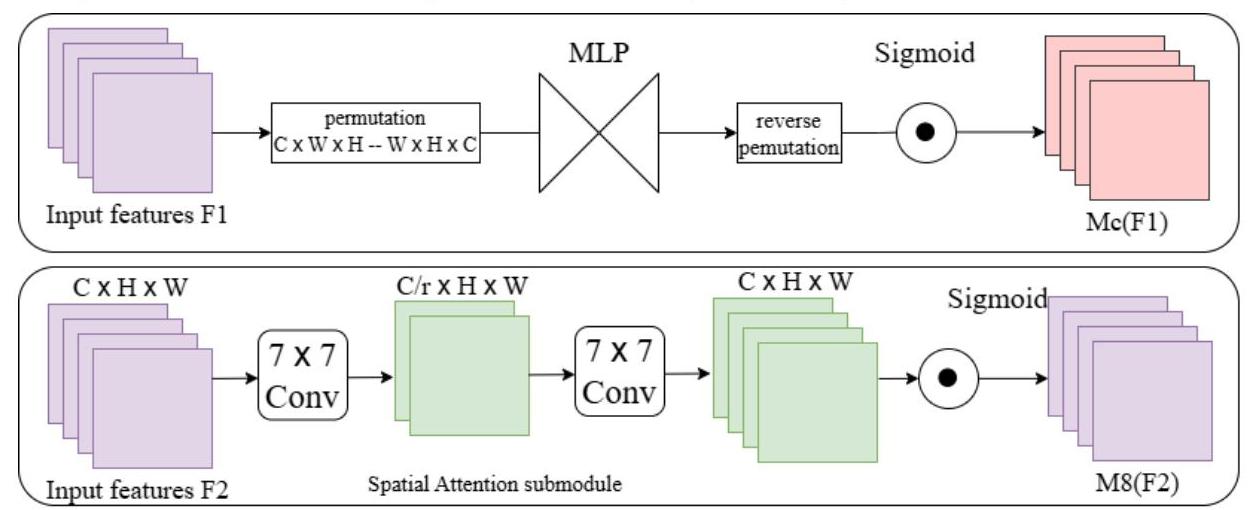
圖4:注意力機制的結構,展示了通道和空間注意力組件,以增強特征表示
實驗設置與評估
實驗評估使用精心選擇的數據集和標準化指標進行,以確保對所提出的改進進行全面評估。
數據集
選擇了兩個專門的數據集進行評估:
- SODA-D (Small Object Detection in Aerial Images - Drone):專門用于無人機航拍圖像中的小目標檢測,提供了與自動駕駛挑戰相關的多種類別
- VisDrone:一個用于無人機視頻分析的大規模數據集,包含來自全球不同城市在各種環境條件下的航拍畫面,面臨的重大挑戰包括遮擋和主要為小型目標
訓練配置
- 圖像分辨率:1280×1280 像素
- 訓練周期:100
- 優化器:SGD,批處理大小為 16
- 內存容量:64GB
- 評估指標:精確率 (P)、召回率 (R)、mAP@0.5、mAP@0.5:0.95、GFLOPS、參數和 FPS
結果與性能分析
實驗結果表明,在兩個數據集上目標檢測性能均顯著提高,驗證了所提出的架構改進的有效性。
定量性能
SODA-D 數據庫結果:
- 基線 YOLOv8:mAP@0.5 為 61.8%,mAP@0.5:0.95 為 36.8%
- 改進模型:mAP@0.5 為 65.2%,mAP@0.5:0.95 為 38.3%
- 改進:mAP@0.5 增加了 3.4%,mAP@0.5:0.95 增加了 1.5%
- 精確率從 70.1% 提高到 72.5%
- 召回率從 56.1% 提高到 58.9%
VisDrone 數據庫結果:
- 基線 YOLOv8:mAP@0.5 為 30.5%,mAP@0.5:0.95 為 16.7%
- 改進模型:mAP@0.5 為 34.5%,mAP@0.5:0.95 為 16.6%
- 改進:mAP@0.5 增加了 4.0%
- 精確率從 42.0% 提高到 44.5%
- 召回率從 31.7% 提高到 33.9%
定性分析
視覺比較表明,增強模型取得了實際的改進,顯示出更準確的目標定位和更高的檢測率,特別是對于較小和更遠的目標。

圖5:檢測結果的視覺比較,顯示增強型YOLOv8模型相較于基線模型在準確性和精度方面的提升。
視覺證據支持了定量發現,表明:
- 跨各種物體尺寸的更高檢測精度
- 更精確的邊界框定位
- 在小物體或遠距離物體等挑戰性場景中性能提升
意義與影響
本研究通過以下幾個關鍵領域,對自動駕駛技術和計算機視覺應用的進步做出了重大貢獻:
安全性與可靠性提升
改進的物體檢測能力直接轉化為自動駕駛車輛更高的安全性,具體表現為:
- 更準確地識別障礙物、行人和其他車輛
- 更好的碰撞避免和風險緩解
- 改進路徑規劃和導航的決策
實際應用
對中國大學生方程式智能汽車大賽 (FSAC) 比賽要求的具體關注,展示了在快速和準確檢測至關重要的高風險場景中的實際適用性。這些改進使系統特別適合競技性自動駕駛平臺。
成本效益
通過增強基于攝像頭的物體檢測系統,這項工作有助于實現更具成本效益的自動駕駛汽車開發,與激光雷達等昂貴的傳感器解決方案相比,這可能使自動駕駛技術更易于大規模生產。
技術進步
本研究通過以下方式推動了實時物體檢測的最新技術水平:
- 成功解決了多尺度檢測挑戰
- 提高了小物體的檢測能力
- 保持了實時應用的計算效率
- 為YOLO架構的進一步增強提供了框架
結論
本研究對YOLOv8物體檢測框架進行了全面增強,專門解決了自動駕駛應用中的關鍵挑戰。通過集成結構重參數化技術、雙向金字塔網絡和優化后的管道結構,所提出的系統在檢測多尺度、小型和遠距離物體方面取得了顯著改進。
實驗結果表明,在挑戰性數據集上,性能持續提升,SODA-D和VisDrone數據集上的mAP@0.5分數分別提升了3.4%和4.0%。這些改進雖然是漸進的,但代表著邁向更可靠、更安全的自動駕駛系統的有意義的進展。
這項工作專注于實際應用,特別是在競技性自動駕駛場景中,突出了其在實際部署挑戰中的相關性。通過在成熟的YOLOv8框架上進行構建,而不是開發全新的架構,本研究為現有自動駕駛車輛開發管道中的實際實施和可擴展性提供了途徑。
未來的工作可以探索進一步的架構改進、與其他傳感器模式的集成以及在其他真實世界場景中的驗證,以繼續提升基于視覺的自動駕駛系統的能力。


_csdn)

)







 ----- Python起源)





)
