前言
之前的文章里,我已經介紹了傳統的AE能夠將高維輸入壓縮成低維表示,并重建出來,但是它的隱空間結構并沒有概率意義,這就導致了傳統的AE無法自行生成新的數據(比如新圖像)。因此,我們希望:
- 隱空間向量?
?是連續、結構良好的
- 并且可以在隱空間中采樣?
這就是VAE的目標:構造一個“生成型AutoEncoder”。
一、回顧AE
前面的文章中,我已經詳細介紹了AE,這里我們簡單回顧一下AE干了什么,如下圖所示:
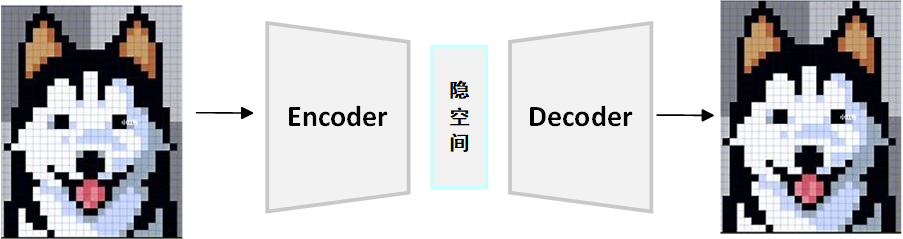
AE基于一個簡單卻新穎的概念:獲取輸入數據??,將其壓縮成低維表示,然后再將其重構成原始形式。拿圖像舉例,圖像通常包含數萬個數值,而低維表示通常是一個包含10-100維的向量,這些低維表示存儲在更緊湊的隱空間中,使用訓練好的AE,它可以根據隱空間表示來重建圖像。
但是如何生成新圖像呢?我們很容易想到的是從這個隱空間中隨機采樣一些點,然后通過AE的Decoder來生成圖像,如下圖所示:
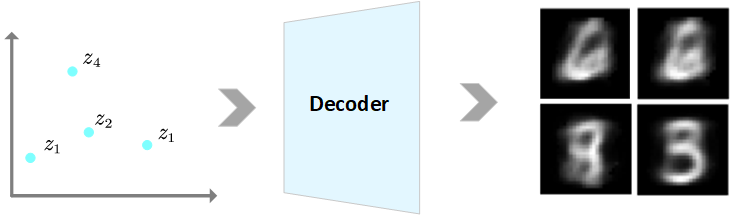
?通過上圖,雖然AE能夠通過隱空間隨機采樣一些點,來生成新圖像,但是,由于隱空間是無組織、不規則的,因此隱空間的大部分區域都不會產生有意義的新圖像。
還有一種方式,就是取編碼后的圖像,然后對其隱空間附近的點進行采樣,生成與原始圖片相似的新圖像:

?但是,通過圖片我們會發現,由于隱空間的結構太差,即時采樣附近的點,也無法生成與原始圖像同樣意義的新圖像或者只能生成與原始圖像近似的圖像。
總而言之,由于AE壓縮的隱空間的結構具有缺陷,因此不能生成有意義的新數據。因此如果能生成一個連續、結構良好的隱空間,那么就能對采樣點生成連貫的新數據了,這就是VAE要做的事了。
二、VAE所用的概率基礎
1. 隨機變量與概率密度函數(PDF)
給定一個隨機變量?,它的概率密度函數?
?描述了采樣得到某個值?
?的相對可能性有多大:
- 概率密度?
?并不是概率本身,而是在一個非常小的區間?
?上,采樣值落入這個區間的概率近似為?
- 積分為1,:所有可能值的總概率為1,
2. 期望
從X中不斷采樣,會得到一組值的平均,稱為期望:
它表示從分布中采樣所期望的平均值
3. 聯合分布
若我們有兩個變量??和?
,則它們的聯合分布記為:
它給出了所有可能組合?的概率密度
4. 邊緣分布
每個變量對自己的分布,可以通過聯合分布進行積分(邊緣化)得到:
- 對于?
?積分得到?
?的邊緣分布:
- 對于?
5. 條件概率密度
條件概率表示在已知某一變量的情況下,另一個變量的概率分布,根據貝葉斯公式,可以得到:
- 已知z,求 x 的條件概率
- 已知x,求 z 的條件概率
三、VAE的原理
2014年,Diederik P. Kingma在他的論文《Auto-Encoding Variational Bayes》里首次提出了變分自編碼器,簡稱VAE,它的核心思想之一就是貝葉斯統計。
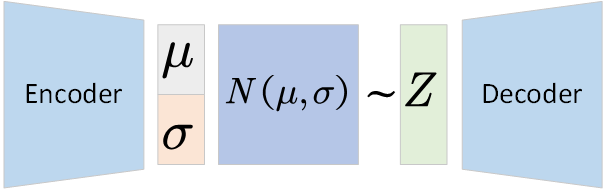
1. VAE的目標
我們希望給定數據? ,能夠學習隱空間?
?的分布,并能從?
?中生成“相似”的
,即從先驗分布中采樣?
(
為先驗概率),通過解碼器生成?
(
為似然概率)。由于VAE屬于生成模型,因此我們關注的是:
如下所示:
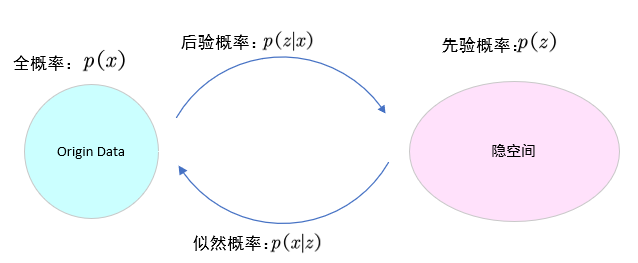
核心思想就是如果能從后延分布中采樣隱空間向量,這些隱空間向量由原始數據生成,來自原始數據分布??,如果我們能夠將這些隱空間向量重建回原數據,我們就能從原始數據分布中生成新的樣本。由于我們不知道隱空間分布
?的確切形狀,因此我們假設隱空間分布是一個正態分布,然后就能計算似然概率?
?,它衡量從隱空間重建圖像的可能性有多大,但是我們仍然不知道后驗概率?
?,因此就需要使用“變分自編碼器中的變分推斷了”
2. 變分推斷
上面我們已經知道了,不知道真實分布的后驗概率??,所以我們引入一個近似后驗分布?
?來近似后驗概率?
,這個近似后驗分布包括參數
?和
,這個參數可以用Encoder來學習;然后我們使用一個Decoder從學習到的近似后驗概率中采樣隱空間向量來重構數據。
具體來說,我們使用變分下界(ELBO)來近似優化?:
根據Jensen不等式:
即:
這個下界Loss,就是我們用來訓練模型的目標函數
3. 對下界(ELBO)推導
根據聯合概率?,代入目標函數:
這就是VAE的損失函數,由兩部分組成:
重構項,表示從隱空間變量 z 重建原始輸入 x 的可能性:
KL散度,也叫正則化項,用來衡量我們學到的近似后驗分布??與先驗分布?
?之間的差距:
4. VAE的整體流程:
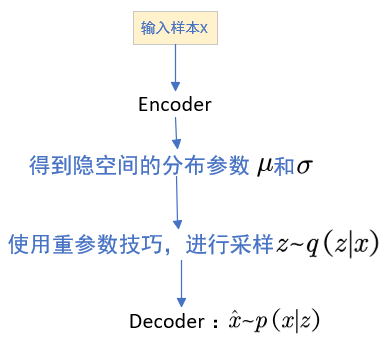
5. 重參數技巧
為了讓采樣過程可導,VAE使用重參數技巧,這樣就可以把 z 寫成可導的形式,就能訓練模型了:
6. 最終VAE損失
在實際中,我們最大化ELBO(最小化負對數),因此最終優化的是:
其中,KL項可以表示為:
四、Pytroch具體實現
接下來,我使用MNIST手寫數字數據集來簡單訓練一下VAE流程:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoadertransform = transforms.ToTensor()
train_dataset = datasets.MNIST('./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)class VAE(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(784, 400)self.fc_mu = nn.Linear(400, 20)self.fc_logvar = nn.Linear(400, 20)self.fc2 = nn.Linear(20, 400)self.fc3 = nn.Linear(400, 784)def encode(self, x):h1 = F.relu(self.fc1(x))return self.fc_mu(h1), self.fc_logvar(h1)def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):h3 = F.relu(self.fc2(z))return torch.sigmoid(self.fc3(h3))def forward(self, x):x = x.view(-1, 784)mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvardef loss_fn(recon_x, x, mu, logvar):BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())return BCE + KLD
總結
以上就是VAE的全部內容,相信小伙伴們看到這已經對VAE有了更深刻的理解:VAE將概率建模引入AE中,讓模型可以從隱空間中采樣生成新樣本,它通過最大化變分下界ELBO優化目標函數,使用重參數技巧來使得采樣過程可導。但是,VAE生成圖像時較模糊。
如果小伙伴們覺得本文對各位有幫助,歡迎:👍點贊 |?? 收藏 | ?🔔 關注。我將持續在專欄《人工智能》中更新人工智能知識,幫助各位小伙伴們打好扎實的理論與操作基礎,歡迎🔔訂閱本專欄,向AI工程師進階!



 ----- Python起源)





)


)
---靶場體會小白心得 ---jacko)


進行安全日志分析)
3-0 等級保護測評要求現行技術標準)

