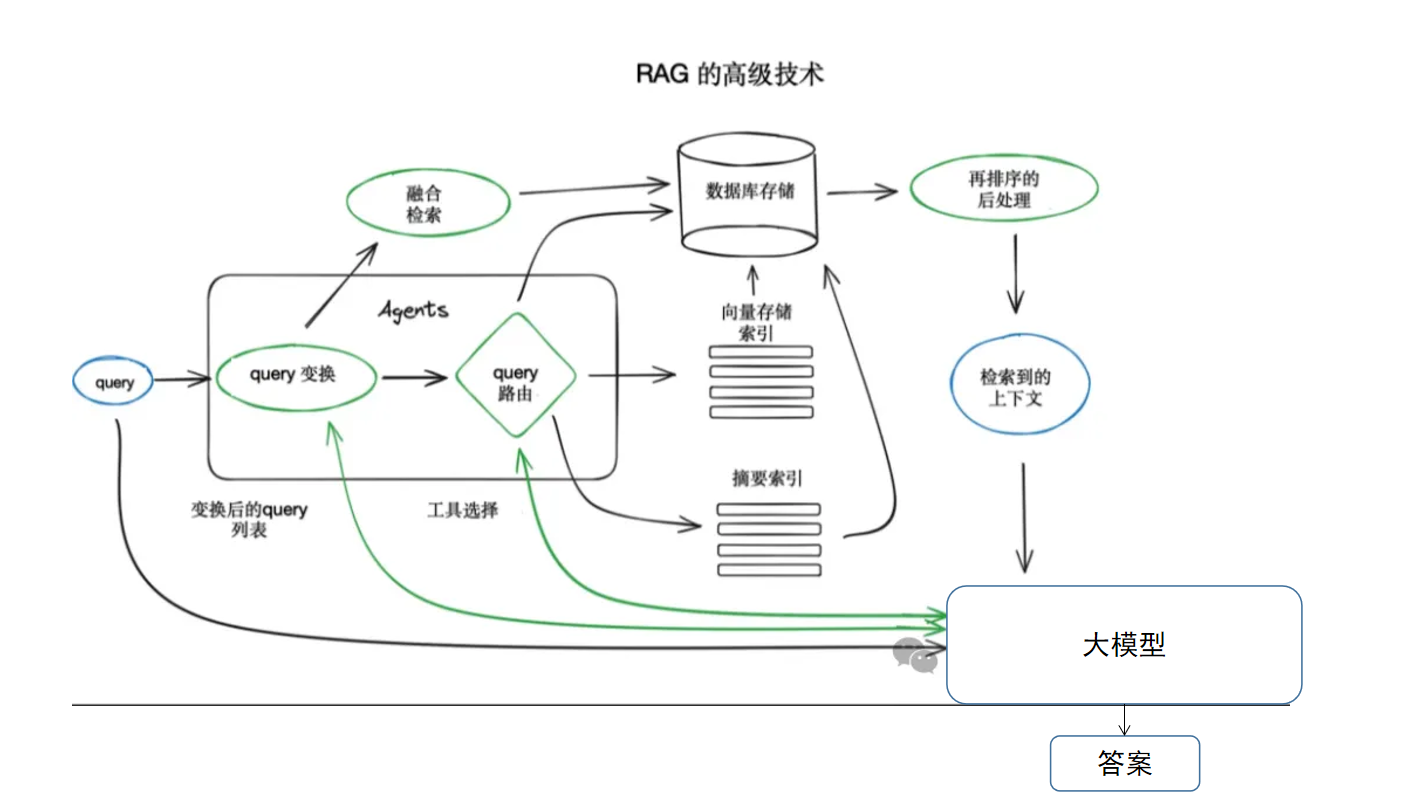
在RAG系統中,有兩個非常重要的模型一個是Embedding模型,另一個則是Rerank模型;這兩個模型在RAG中扮演著重要角色。
Embedding模型的作用是把數據向量化,通過降維的方式,使得可以通過歐式距離,余弦函數等計算向量之間的相似度,以此來進行相似度檢索。
而Rerank的作用是在Embedding檢索的基礎之上,進行更加準確的數據篩選;如果說Embedding模型進行的是一維篩選,那么Rerank模型就是從多個維度進行篩選。
Embedding模型和Rerank模型
在自然語言處理和信息檢索系統中,Embedding模型和Rerank模型是兩類功能不同但常結合使用的技術。
Embedding和Rerank模型都是基于深度學習方式實現的神經網絡模型,但由于其功能不同,因此其實現方式和訓練方法也有一定的區別。
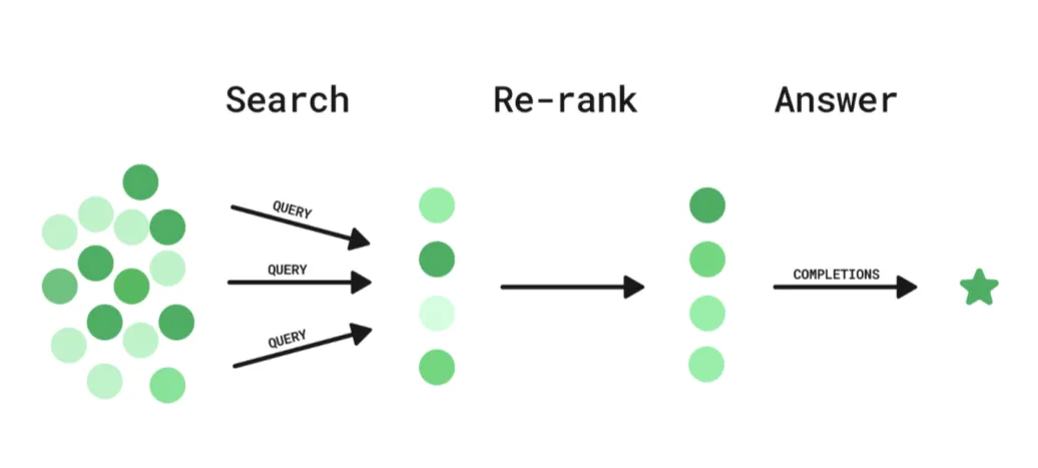
從使用的角度來看,Embedding一般用于數據向量化并快速檢索,而Rerank模型是在快速檢索的基礎之上進行重排序,提升相似度。
但從技術實現的角度來說,兩種模型使用的學習方式和架構是不一樣的;原因就在于兩個模型的實現目的和處理數據的方式。
它們的核心區別在于目標、應用階段和技術實現。以下是詳細對比:
1. 功能目標
| 維度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 核心任務 | 將文本轉化為低維向量,捕捉語義信息 | 對候選結果重新排序,提升相關性 |
| 輸出形式 | 高維或低維向量(如768維向量) | 候選列表的排序分數(如相關性得分) |
| 關注點 | 文本的全局語義表示 | 候選結果與查詢的細粒度匹配 |
示例
-
Embedding模型:將“如何訓練神經網絡?”轉換為向量,用于檢索相似問題。
-
Rerank模型:對初步檢索的100個答案排序,將最相關的答案排到前3。
2. 應用階段
| 維度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 所處流程 | 檢索階段 :快速生成候選集 | 精排階段 :優化候選集的順序 |
| 數據規模 | 處理海量數據(如百萬級文檔) | 處理小規模候選集(如Top 100~1000) |
| 性能要求 | 要求高效(毫秒級響應) | 可接受較高延遲(需復雜計算) |
典型場景
-
Embedding模型:用于搜索引擎的初步召回(如從10億文檔中篩選出Top 1000)。
-
Rerank模型:在推薦系統中對Top 100結果精細化排序,提升點擊率。
3. 技術實現
| 維度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 模型類型 | 無監督/自監督學習(如BERT、Sentence-BERT) | 有監督學習(如Pairwise Ranking、ListNet) |
| 輸入輸出 | 單文本輸入 → 固定維度向量 | 查詢+候選文本對 → 相關性分數 |
| 特征依賴 | 僅依賴文本本身的語義信息 | 可融合多特征(語義、點擊率、時效性等) |
模型舉例
-
Embedding模型:
-
通用語義編碼:BERT、RoBERTa
-
專用場景:DPR(Dense Passage Retrieval)
-
-
Rerank模型:
-
傳統方法:BM25 + 特征工程
-
深度模型:ColBERT、Cross-Encoder
-





)













