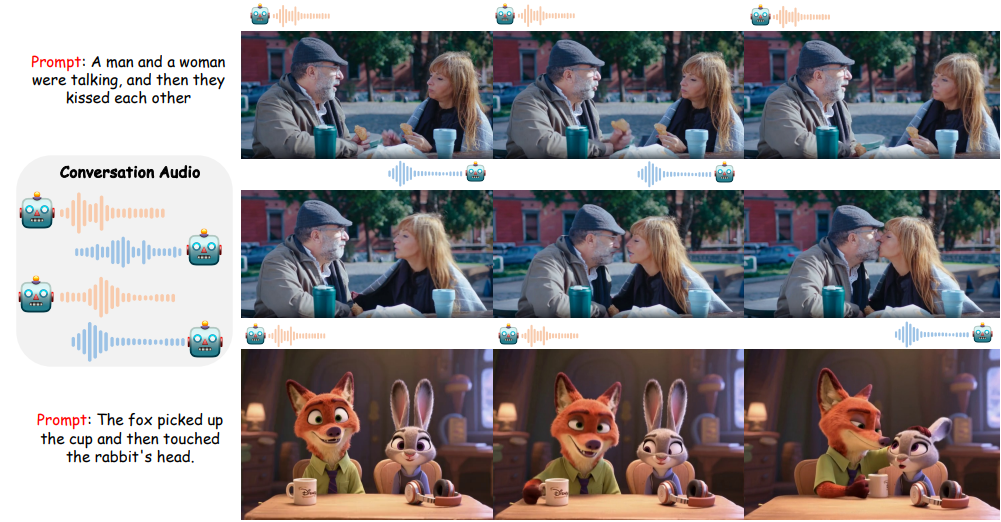
由中山大學、美團、香港科技大學聯合提出的MultiTalk是一個用于音頻驅動的多人對話視頻生成的新框架。給定一個多流音頻輸入和一個提示,MultiTalk 會生成一個包含提示所對應的交互的視頻,其唇部動作與音頻保持一致。
相關鏈接
-
論文:https://arxiv.org/pdf/2505.22647
-
主頁:https://meigen-ai.github.io/multi-talk/
-
代碼:https://github.com/MeiGen-AI/MultiTalk
論文介紹

音頻驅動的人體動畫方法,例如說話頭部和說話身體生成,在生成同步面部動作和引人入勝的視覺質量視頻方面取得了顯著進展。然而,現有方法主要側重于單人動畫,難以處理多流音頻輸入,存在音頻與人物綁定不正確的問題。此外,它們在指令遵循能力方面也存在局限性。
為了解決這一問題,本文提出了一項新的任務:多人對話視頻生成,并引入了一個新框架 MultiTalk 來應對多人生成過程中的挑戰。具體來說,對于音頻注入,我們研究了多種方案,并提出了標簽旋轉位置嵌入 (L-RoPE) 方法來解決音頻和人物綁定問題。此外,在訓練過程中,我們觀察到部分參數訓練和多任務訓練對于保持基礎模型的指令遵循能力至關重要。MultiTalk 在多個數據集(包括說話頭部、說話身體和多人數據集)上取得了優于其他方法的性能,證明了我們方法強大的生成能力。
方法
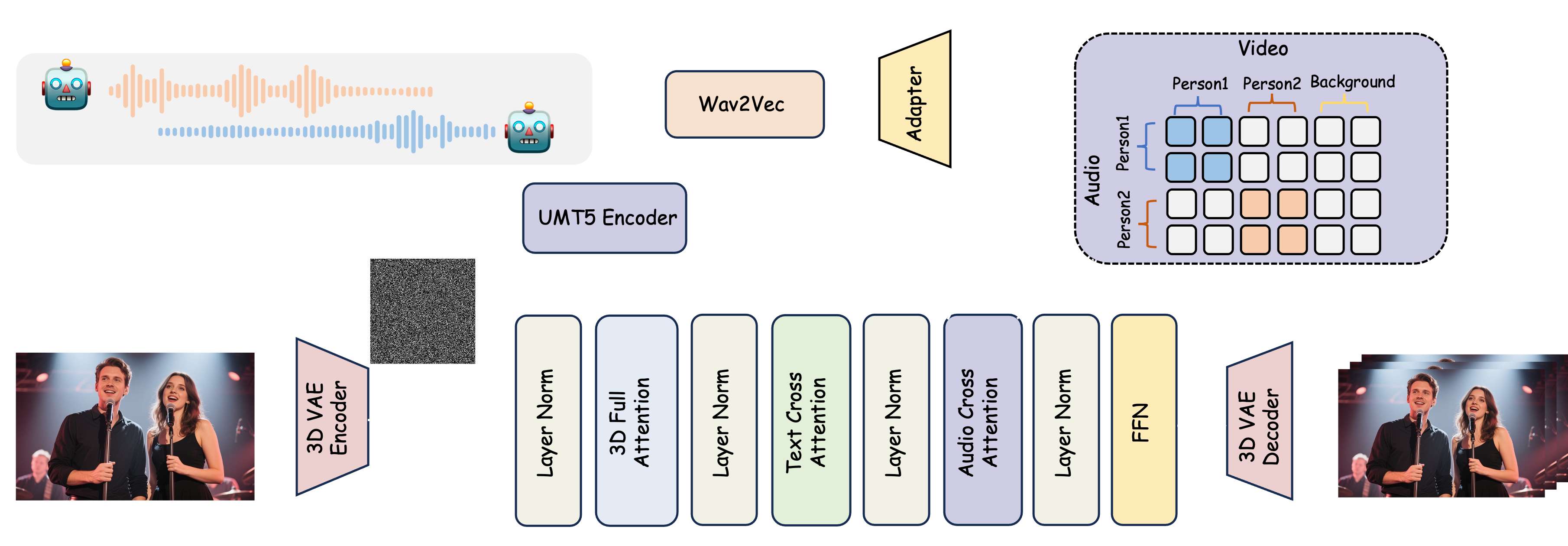
論文提出了一個音頻驅動的視頻生成框架 MultiTalk。該框架新增了一個音頻交叉注意力層,以支持音頻條件。為了實現多人對話視頻生成,論文提出了一種用于多流音頻注入的標簽旋轉位置嵌入 (L-RoPE)。






)







)

——自組織映射詳解)


