一、回顧:
- 對深度學習框架Python2.0進行自然語言處理有了一個基礎性的認識
- 注意力模型編碼器(encoder_layer,用于分類的全連接層dense_layer),拋棄了傳統的循環神經網絡和卷積神經網絡,通過注意力模型將任意位置的兩個單詞的距離轉換成1
- 編碼器層和全連接層分開,利用訓練好的模型作為編碼器獨立使用,并且根據具體項目接上不同的尾端,以便在運訓練好的編碼器上通過微調進行訓
二、BERT簡介:?
Bidirectional? Encoder Representation From transformer,替代了 word embedding 的新型文字編碼方案,BERT 實際有多個encoder block疊加而成,通過使用注意力模型的多個層次來獲得文本的特征提取
三、基本架構與應用
1.MLM:隨機從輸入語料中這閉掉一些單詞,然后通過上下文預測該單詞
2.NSP:判斷句子B是否句子A的上下文
四、使用HUGGING FACE獲取BERT與訓練模型
1.安裝
pip install transformers2.引用?
import torch
from transformers import BertTokenizer
from transformers import BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
pretrain_model = BertModel.from_pretrained("bert-base-chinese")3. 運用代碼_獲取對應文本的TOKEN
3.1('bert-base-chinese'模型)
import torch
from transformers import BertTokenizer
from transformers import BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
pretrain_model = BertModel.from_pretrained("bert-base-chinese")tokens = tokenizer.encode("床前明月光",max_length=12,padding="max_length",truncation=True)
print(tokens)
print("----------------------")
print(tokenizer("床前明月光",max_length=12,padding="max_length",truncation=True))
print("----------------------")
tokens = torch.tensor([tokens]).int()
print(pretrain_model(tokens))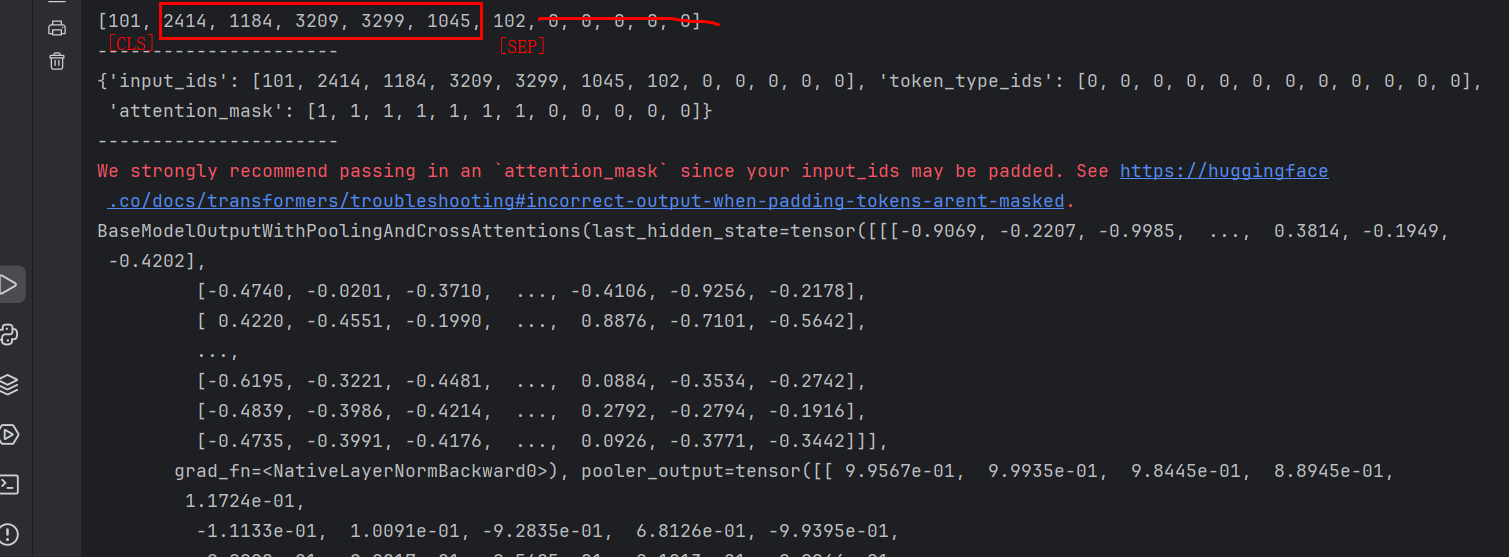
?3.2("uer/gpt2-chinese-ancient"模型)
import torch
from transformers import BertTokenizer,GPT2Model
model_name = "uer/gpt2-chinese-ancient"
tokenizer = BertTokenizer.from_pretrained(model_name)
pretrain_model = GPT2Model.from_pretrained(model_name)tokens = tokenizer.encode("春眠不覺曉",max_length=12,padding="max_length",truncation=True)
print(tokens)
print("----------------------")
print(tokenizer("春眠不覺曉",max_length=12,padding="max_length",truncation=True))
print("----------------------")tokens = torch.tensor([tokens]).int()
print(pretrain_model(tokens))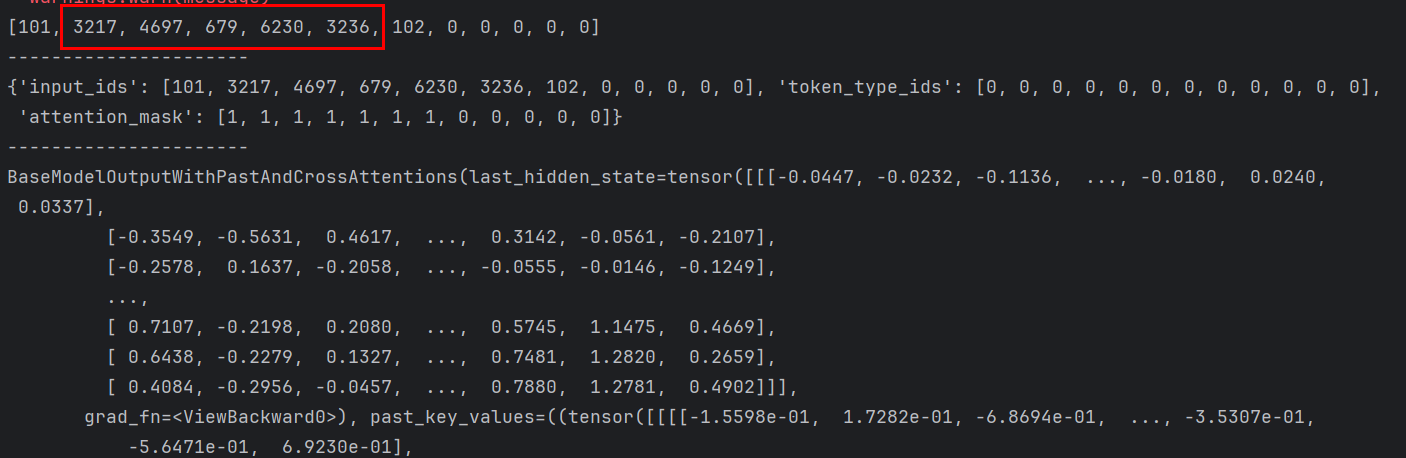
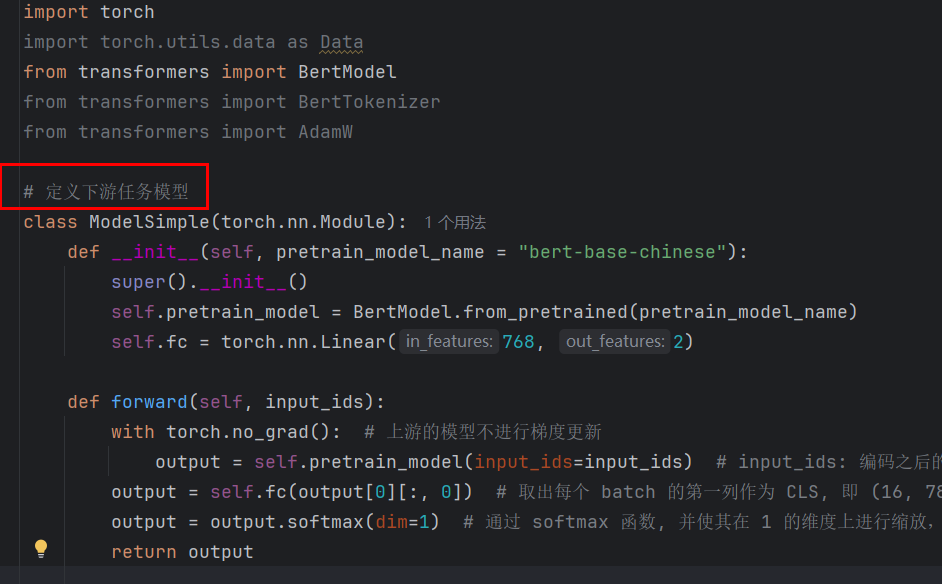
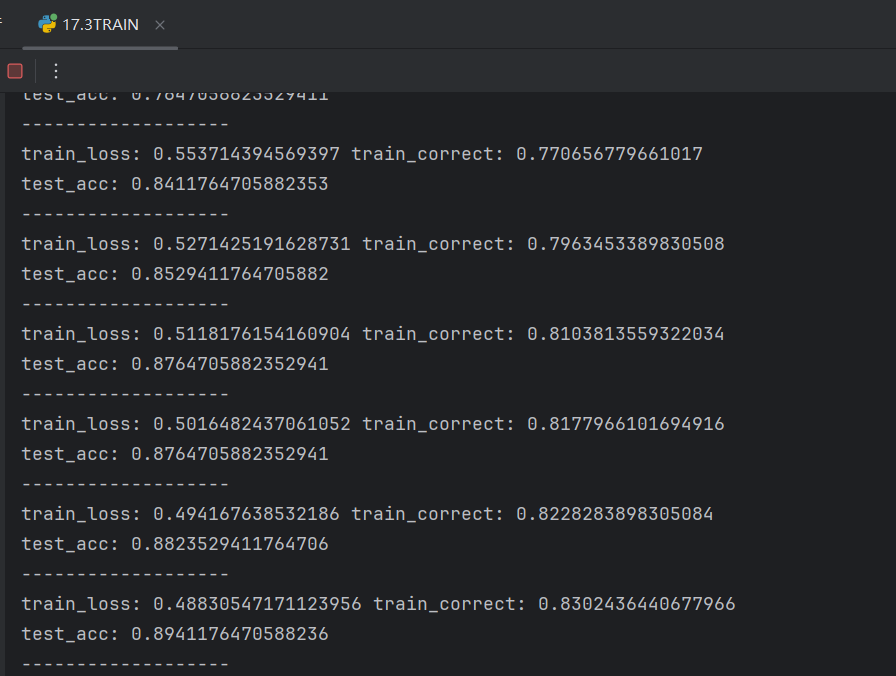
4.進行文本分類
數據準備>數據處理>模型設計>模型訓練
get_data:
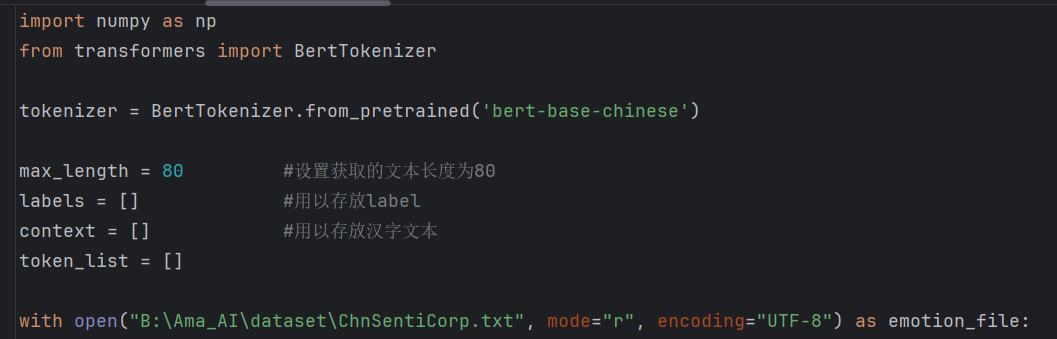
model:
?train:






)






: 心得體會)





