目錄
?
一、背景介紹
二、KNN 算法原理
2.1 核心思想
2.2 距離度量方法
2.3 算法流程
2.4算法結構:
三、KNN 算法代碼實現
3.1 基于 Scikit-learn 的簡單實現
3.2 手動實現 KNN(自定義代碼)
四、K 值選擇與可視化分析
4.1 K 值對分類結果的影響
4.2 交叉驗證選擇最優 K 值
五、KNN 算法的優缺點與優化
5.1 優點
5.2 缺點
5.3 優化方法
六、KNN 算法的應用場景
七、KNN 與其他算法的對比
八、小結
?
一、背景介紹
K 近鄰算法(K-Nearest Neighbors, KNN)是機器學習中最簡單、最直觀的算法之一,其核心思想源于人類對相似事物的判斷邏輯 ——“近朱者赤,近墨者黑”。該算法無需復雜的訓練過程,直接通過計算樣本間的距離來進行分類或回歸,廣泛應用于圖像識別、文本分類、推薦系統等領域。
二、KNN 算法原理
2.1 核心思想
KNN 的核心思想是:對于一個待預測樣本,找到訓練數據中與其最相似的 K 個樣本(近鄰),根據這 K 個樣本的類別(分類問題)或數值(回歸問題)進行投票或平均,從而確定待預測樣本的類別或數值。
關鍵點:
相似性度量:通過距離函數衡量樣本間的相似性。
K 值選擇:近鄰數量 K 對結果影響顯著。
投票機制:分類問題通常采用多數投票,回歸問題采用均值或加權平均。
2.2 距離度量方法
常見的距離度量方法包括:
歐氏距離:適用于連續變量,計算兩點間的直線距離。
曼哈頓距離:適用于城市網格路徑等場景,計算兩點間的折線距離。
余弦相似度:適用于文本、圖像等高維數據,衡量向量間的方向相似性。
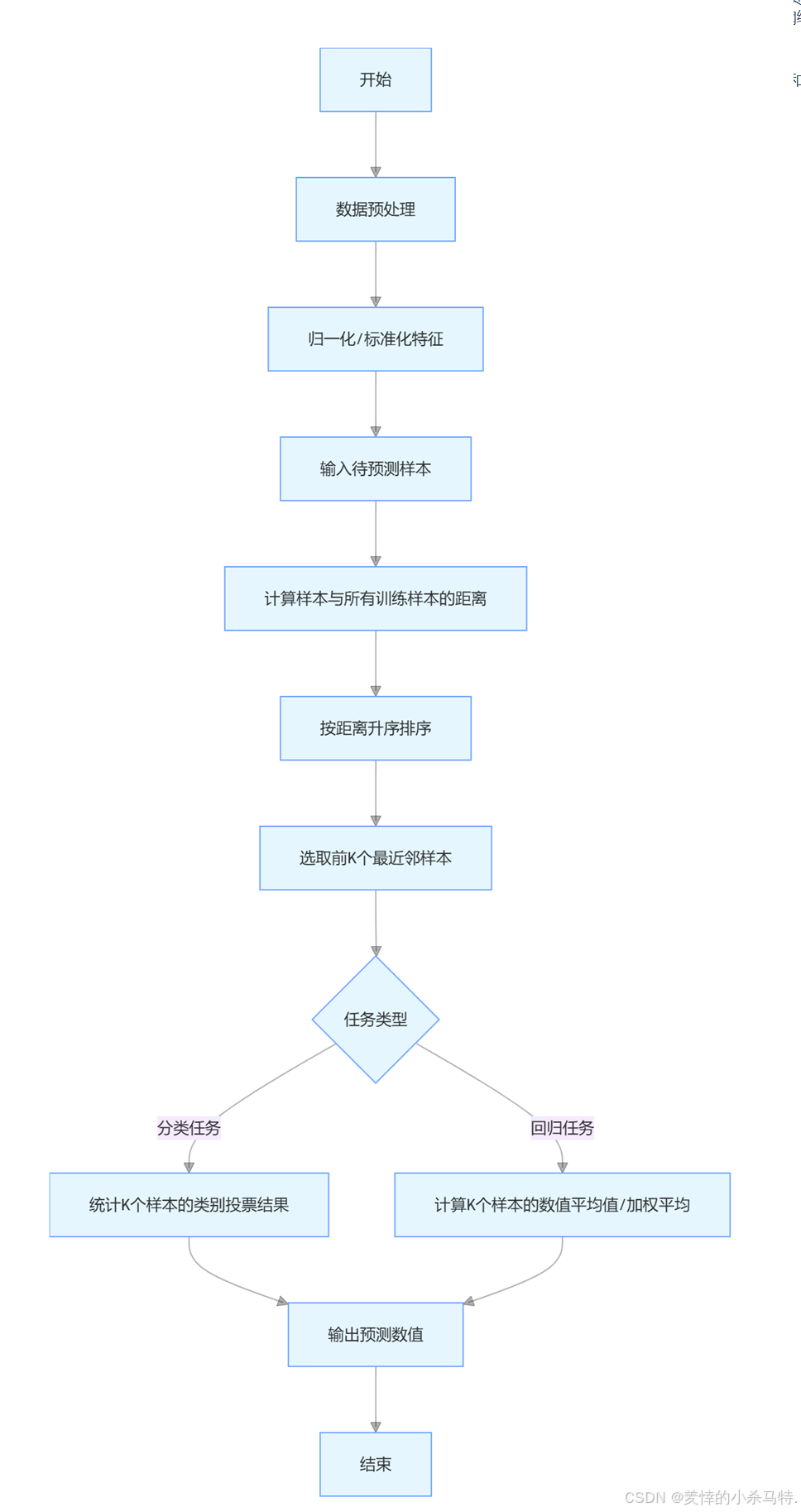
2.3 算法流程
KNN 算法的典型流程如下:
1·數據預處理:對數據進行清洗、歸一化,避免特征量綱影響距離計算。
2·計算距離:計算待預測樣本與所有訓練樣本的距離。
3·選擇近鄰:按距離升序排列,選取前 K 個最近鄰樣本。
4·分類 / 回歸決策:
分類:統計 K 個近鄰的類別,選擇出現次數最多的類別。
回歸:計算 K 個近鄰數值的平均值或加權平均值。
2.4算法結構:
三、KNN 算法代碼實現
3.1 基于 Scikit-learn 的簡單實現
以鳶尾花數據集(Iris Dataset)為例,演示 KNN 分類的完整流程。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score# 加載鳶尾花數據集
iris = datasets.load_iris()
X = iris.data[:, :2] # 僅取前兩個特征,便于可視化
y = iris.target
feature_names = iris.feature_names[:2]# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 數據標準化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 創建KNN分類器(K=5)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)# 預測測試集
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy with K=5: {accuracy:.2f}") # 輸出:Accuracy with K=5: 0.98
3.2 手動實現 KNN(自定義代碼)
為深入理解算法原理,我們手動實現 KNN 分類器:
class CustomKNN:def __init__(self, n_neighbors=3):self.n_neighbors = n_neighborsdef fit(self, X_train, y_train):self.X_train = X_trainself.y_train = y_traindef predict(self, X_test):predictions = []for x in X_test:# 計算距離distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]# 獲取最近的K個樣本索引k_indices = np.argsort(distances)[:self.n_neighbors]# 獲取對應的類別k_nearest_labels = self.y_train[k_indices]# 多數投票most_common = np.bincount(k_nearest_labels).argmax()predictions.append(most_common)return np.array(predictions)# 使用自定義KNN
custom_knn = CustomKNN(n_neighbors=3)
custom_knn.fit(X_train, y_train)
y_pred_custom = custom_knn.predict(X_test)
print(f"Custom KNN Accuracy: {accuracy_score(y_test, y_pred_custom):.2f}") # 輸出:0.96
四、K 值選擇與可視化分析
4.1 K 值對分類結果的影響
K 值是 KNN 算法的核心超參數,其大小直接影響分類結果:
- K 值過小:模型復雜度高,易受噪聲影響,導致過擬合。
- K 值過大:模型趨于平滑,可能忽略局部特征,導致欠擬合。
示例:在鳶尾花數據集上,不同 K 值的分類邊界差異如下:
def plot_decision_boundary(clf, X, y, title, k=None):plt.figure(figsize=(8, 6))x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8)# 繪制散點圖for i, color in zip([0, 1, 2], ['r', 'g', 'b']):idx = np.where(y == i)plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i], edgecolor='k')plt.xlabel(feature_names[0])plt.ylabel(feature_names[1])plt.title(f"KNN Decision Boundary (K={k})")plt.legend()plt.show()# K=1(過擬合)
knn1 = KNeighborsClassifier(n_neighbors=1)
knn1.fit(X_train, y_train)
plot_decision_boundary(knn1, X_test, y_test, "K=1", k=1)# K=15(欠擬合)
knn15 = KNeighborsClassifier(n_neighbors=15)
knn15.fit(X_train, y_train)
plot_decision_boundary(knn15, X_test, y_test, "K=15", k=15)
4.2 交叉驗證選擇最優 K 值
通過交叉驗證可以有效選擇最優 K 值:
from sklearn.model_selection import cross_val_score# 候選K值
k_values = range(1, 31)
cv_scores = []for k in k_values:knn = KNeighborsClassifier(n_neighbors=k)scores = cross_val_score(knn, X_train, y_train, cv=5, scoring='accuracy')cv_scores.append(scores.mean())# 繪制K值與準確率曲線
plt.plot(k_values, cv_scores, marker='o', linestyle='--', color='b')
plt.xlabel('K Value')
plt.ylabel('Cross-Validation Accuracy')
plt.title('K Value Selection via Cross-Validation')
plt.show()
五、KNN 算法的優缺點與優化
5.1 優點
簡單易懂:原理直觀,無需復雜數學推導。
無需訓練:直接使用訓練數據進行預測。
泛化能力強:對非線性數據分布有較好的適應性。
5.2 缺點
計算復雜度高:預測時需計算與所有訓練樣本的距離。
存儲成本高:需存儲全部訓練數據。
對噪聲敏感:K 值過小時,異常值可能顯著影響結果。
5.3 優化方法
數據預處理:歸一化、特征選擇。
近似最近鄰搜索:KD 樹、球樹等加速算法。
加權投票:根據距離賦予不同權重。
六、KNN 算法的應用場景
- 圖像識別與分類:常用于手寫數字識別、人臉識別等任務。
- ?推薦系統:基于用戶或物品的相似度進行推薦。
- ?醫療診斷:根據患者的臨床指標預測疾病類別。
- ?異常檢測:通過判斷樣本與近鄰的距離識別異常點。
七、KNN 與其他算法的對比
| 算法 | 核心思想 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| KNN | 基于相似性投票 / 平均 | 簡單直觀、無需訓練 | 計算慢、存儲成本高、高維性能差 | 小規模數據、實時預測 |
| 邏輯回歸 | 基于概率的線性分類 | 訓練快、可解釋性強 | 僅適用于線性可分數據、需調參 | 二分類、概率預測 |
| 決策樹 | 基于特征劃分的樹結構分類 | 可解釋性強、能處理非線性數據 | 易過擬合、對噪聲敏感 | 分類規則提取、快速預測 |
八、小結
KNN 算法以其簡單性和直觀性成為機器學習入門的經典算法,適用于小規模、低維數據的快速分類 / 回歸任務。盡管存在計算效率和高維性能的局限,但其思想為許多復雜算法提供了基礎。通過數據預處理、近似搜索和加權機制,KNN 的實用性可進一步提升;未來,隨著硬件計算能力的提升和近似搜索算法的發展,KNN 在大規模數據中的應用可能迎來新突破。結合深度學習的特征提取能力,可構建更強大的混合模型。
?
?
)


![[Go] Option選項設計模式 — — 編程方式基礎入門](http://pic.xiahunao.cn/[Go] Option選項設計模式 — — 編程方式基礎入門)

)


--Java版)



rpmyum)
![[git]忽略.gitignore文件](http://pic.xiahunao.cn/[git]忽略.gitignore文件)

)


人臉識別(python實現))
