1.程序的翻譯環境和執行環境
在ANSI C標準的任何一種實現中,存在兩種不同的環境。
第一種是翻譯環境:將源代碼轉換為可執行的機器指令(0/1);
第二種是執行環境:用于實際執行代碼。
2.詳解編譯+鏈接
2.1翻譯環境
程序編譯過程:
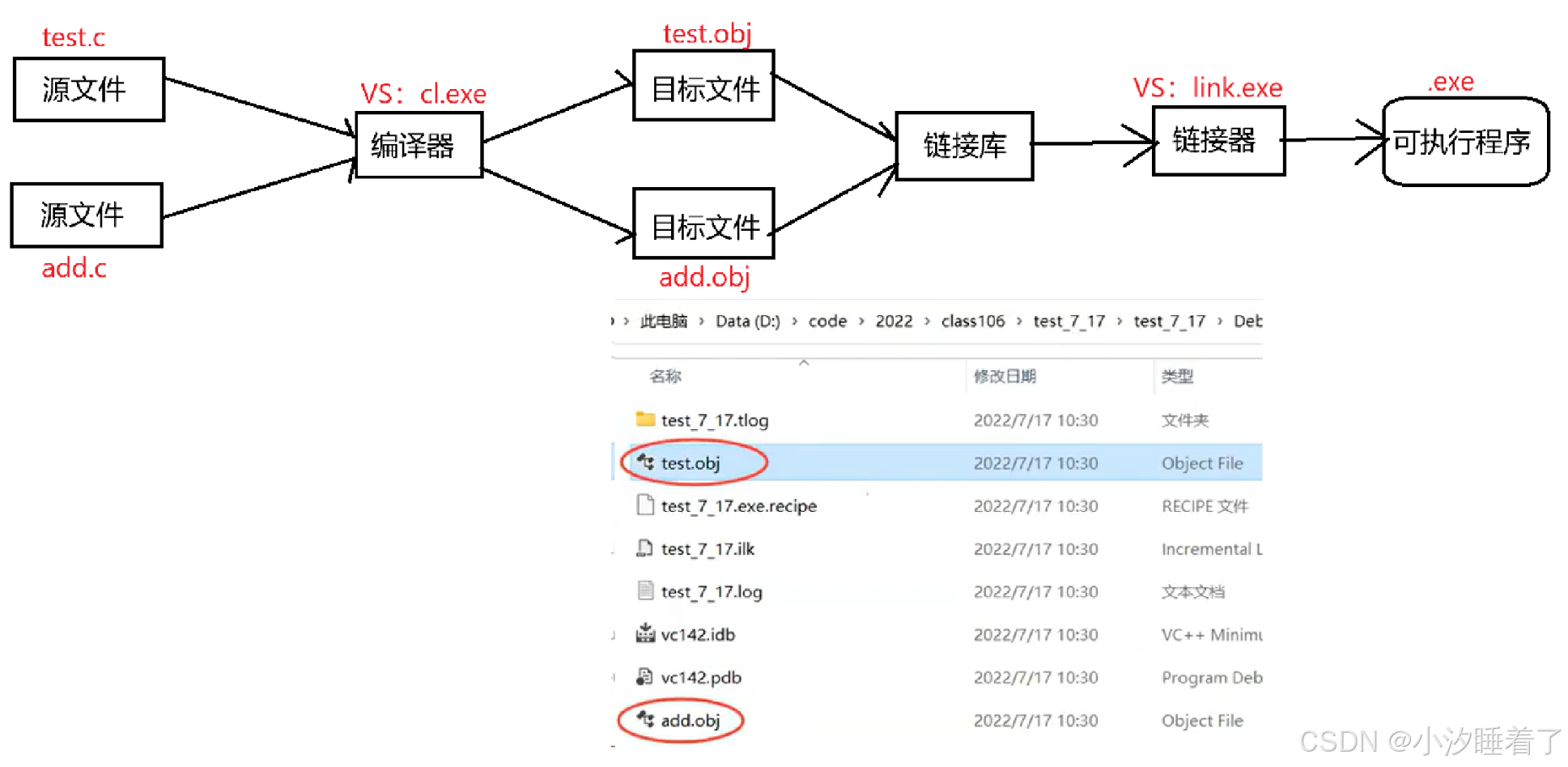
linux系統中的編譯器gcc生成的目標文件:xxx.o
(不同的參數)
2.2編譯本身也分為幾個階段

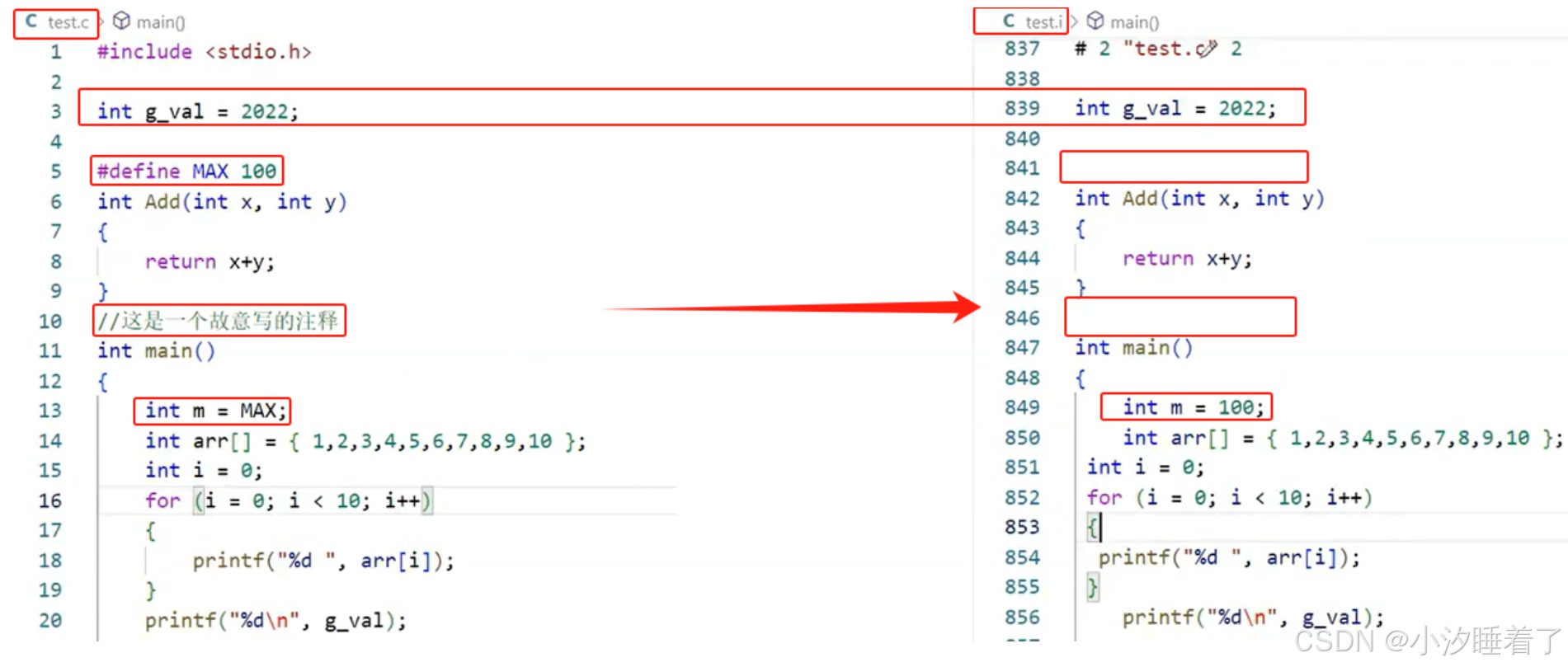
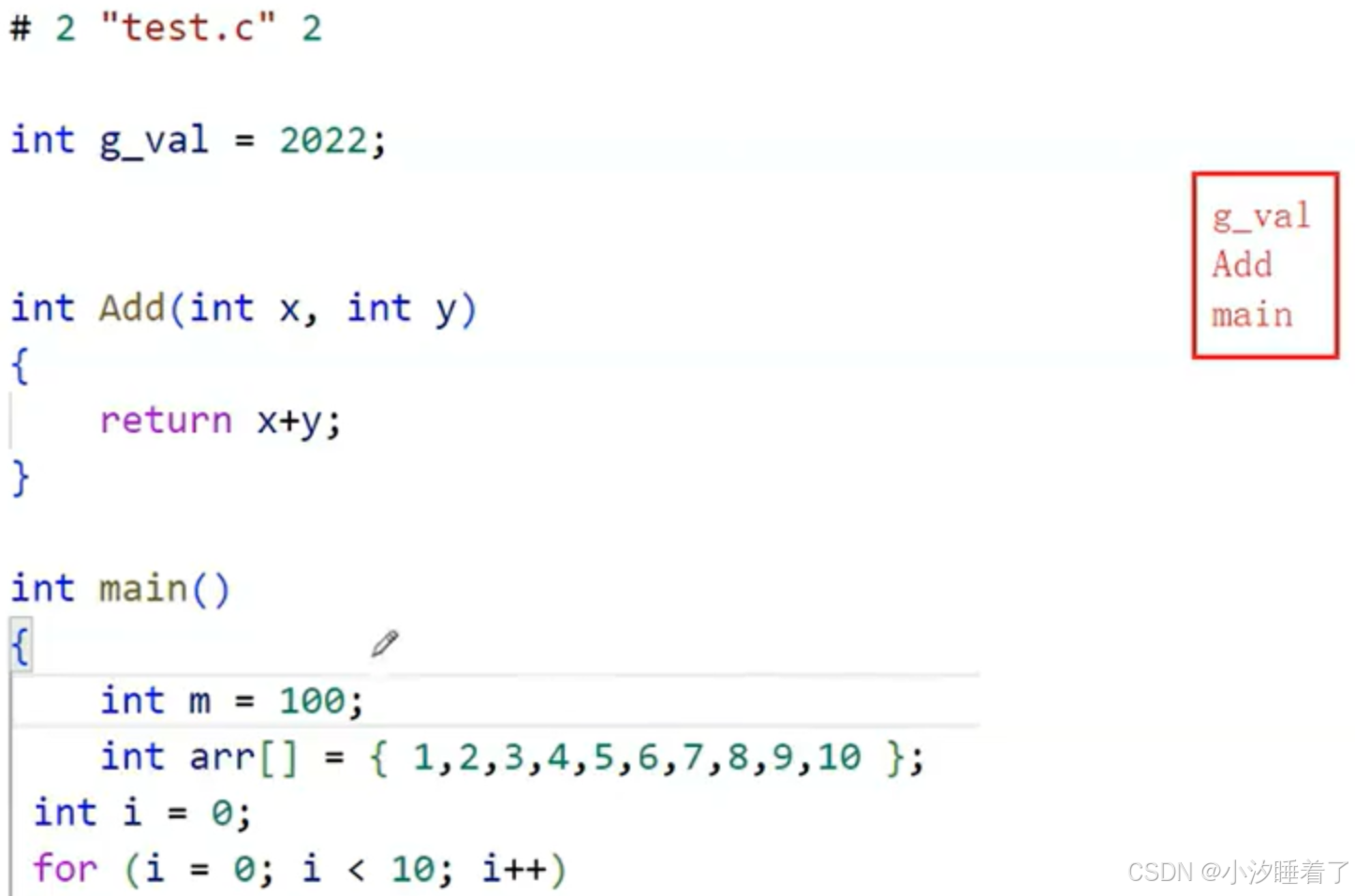
預編譯/預處理:(文本操作)
- 頭文件的包含(#include)
- #define定義符號的替換,刪除定義的符號
- 刪除注釋
- ···
編譯:把C語言代碼轉換成匯編代碼(包括語法分析、詞法分析、符號匯總、語義分析)
匯編:把匯編代碼轉換成二進制指令(機器指令);將編譯時的符號匯總形成符號表
鏈接:合并段表;符號表的合并和重定位
gcc test.c -E -o test.ivim /usr/include/stdio.h
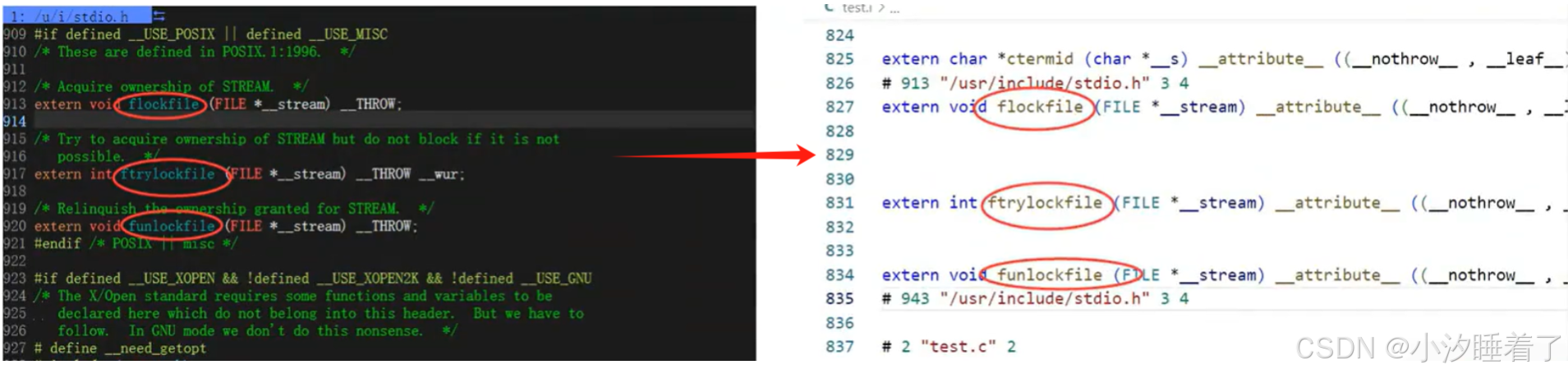
gcc test.c -E -o test.i
gcc test.i -S
//生成test.s
符號匯總:
gcc test.s -c
//生成test.o目標文件(二進制文件)

Linux下的可執行程序是elf格式。
2.3運行環境
程序執行的過程:
- 程序必須載入內存。在有操作系統的環境中,一般由操作系統完成。在獨立的環境中,程序的載入必須由手工安排,也可能是通過可執行代碼植入只讀內存來完成。
- 程序的執行開始,接著調用main函數。
- 開始執行程序代碼。這時程序將使用一個運行時堆棧(stack),存儲函數的局部變量和返回地址。程序同時也可以使用靜態(static)內存,存儲于靜態內存中的變量在程序的整個執行過程中一直保留它們的值。
- 終止程序。正常中止main函數;也可能是意外終止。
3.預處理詳解
3.1預定義符號
__FILE__ //進行編譯的源文件
__LINE__ //文件當前的行號
__DATE__ //文件被編譯的日期
__TIME__ //文件被編譯的時間
__STDC__ //如果編譯器遵循ANSI C標準,其值為1,否則未定義(gcc編譯器是遵循ANSI C標準的)
這些預定義符號都是語言內置的。
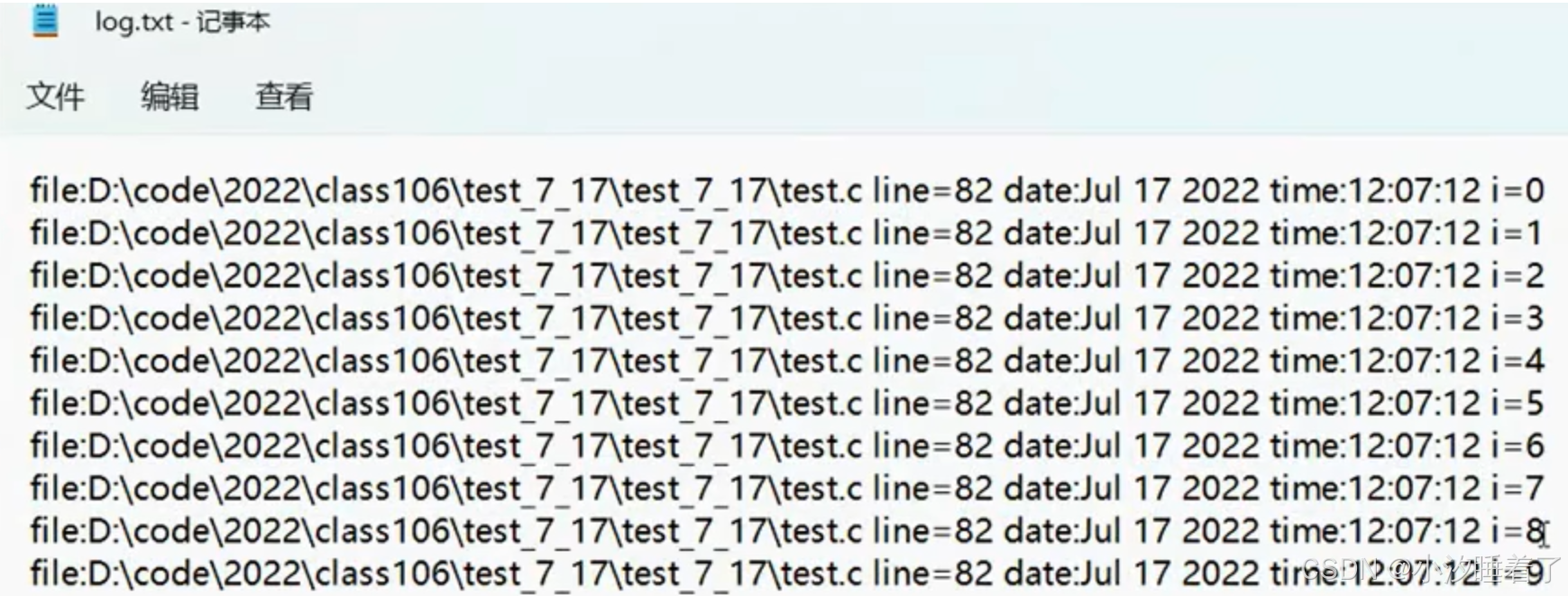
#include <stdio.h>
int main()
{int i = 0;FILE* pf = fopen("log.txt", "w");if (pf == NULL){perror("fopen");return EXIT_FAILURE; //1//EXIT_SUCCESS; //0}for (i = 0; i < 10; i++){fprintf(pf, "file:%s line=%d date:%s time:%s i=%d", __FILE__, __LINE__, __DATE__, __TIME__, i);}fclose(pf);pf = NULL;return 0;
}
3.2#define
3.2.1#define定義標識符(不加分號)
#define name stuff
#include <stdio.h>#define MAX 1000
#define STR "hello bit"int main()
{int m = MAX;printf("%d\n", MAX); //1000printf("%s\n", STR); //hello bitreturn 0;
}
續行符

3.2.2#define定義宏
#define機制包括了一個規定,允許把參數替換到文本中,這種實現通常稱為宏(macro)或定義宏(define macro)。
#define name(parament-list) stuff
其中的parament-list是一個由逗號隔開的符號表,它們可能出現在stuff中。
注意:參數列表的左括號必須與name緊鄰。如果兩者之間有任何空白存在,參數列表會被解釋為stuff的一部分。
#include <stdio.h>#define SQUARE(X) X*Xint main()
{int r = SQUARE(5); printf("%d\n", r); //25return 0;
}
上面寫法有缺陷eg:
#include <stdio.h>#define SQUARE(X) X*Xint main()
{int r = SQUARE(5+1); //5 + 1 * 5 + 1printf("%d\n", r); //11return 0;
}
修正:不吝嗇括號
#include <stdio.h>#define SQUARE(X) ((X)*(X))int main()
{int r = SQUARE(5+1); //((5 + 1) * (5 + 1))printf("%d\n", r); //36return 0;
}
3.2.3#define替換規則
在程序中擴展#defien定義符號和宏時,需要涉及幾個步驟:
- 在調用宏時,首先對參數進行檢查,看看是否包含任何由#defien定義的符號。如果是,它們首先被替換。
- 替換文本隨后被插入到程序中原來文本的位置。對于宏,參數名被它們的值所替換。
- 最后,再次對結果文件進行掃描,看看它是否包含任何由#define定義的符號。如果是,就重復上述處理過程。
注意:
宏參數和#define定義中可以出現其它#define定義的符號。但是對于宏,不能出現遞歸。
當預處理器搜索#define定義的符號時,字符串常量的內容并不被搜索。
#include <stdio.h>#define M 100
#define DOUBLE(X) ((X)+(X))int main()
{DOUBLE(M+2); //(100+2)//((100+2)+(100+2))return 0;
}
3.2.4#和##
如何把參數插入到字符串中?
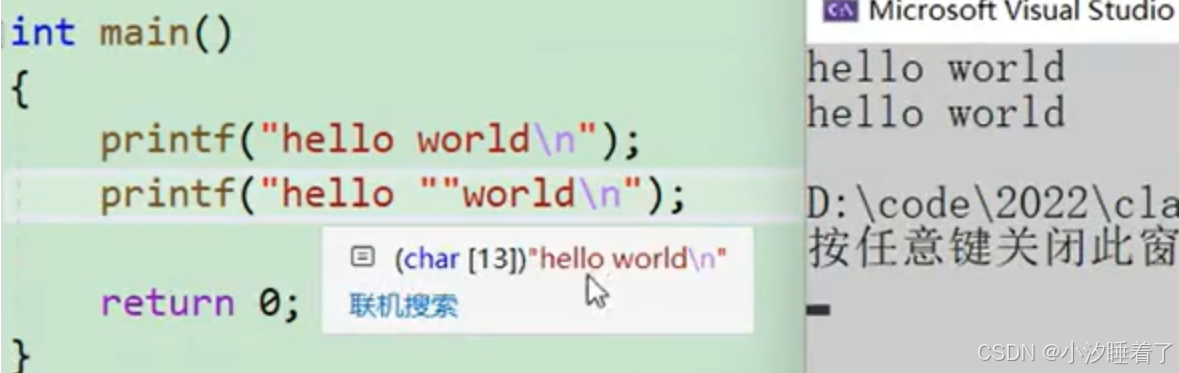
#include <stdio.h>#define PRINT(N) printf("the value of "#N" is %d\n", N)
int main()
{int a = 10;PRINT(a); //printf("the value of ""a"" is %d\n", a);int b = 10;PRINT(b);return 0;
}

#include <stdio.h>#define PRINT(N, FORMAT) printf("the value of "#N" is "FORMAT"\n", N)
int main()
{int a = 10;PRINT(a, %d); int f = 3.14f;PRINT(f, %lf);return 0;
}
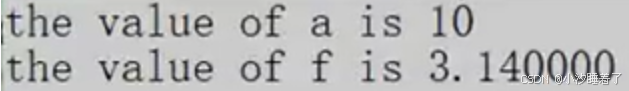
##可以把位于它兩邊的符號合成一個符號。它允許宏定義從分離的文本片段創建標識符。
#include <stdio.h>#define CAT(Class, Num) Class##Num
int main()
{int Class106 = 100;printf("%d\n", CAT(Class, 106)); //100//printf("%d\n", Class106);return 0;
}
3.2.5帶副作用的宏參數
當宏參數在宏的定義中出現超過一次時,如果參數帶有副作用,那么你在使用這個宏的時候就可能出現危險,導致不可預測的后果。副作用就是表達式求值時出現的永久性效果。
#include <stdio.h>
#define MAX(x,y) ((x)>(y)?(x):(y))
int main()
{int a = 5; //6 7int b = 4; //5int m = MAX(a++, b++); //int m = ((a++)>(b++)?(a++):(b++));6 5 > 4 ?6printf("m=%d ", m); //6printf("a=%d b=%d\n", a, b); //7 5return 0;
}
3.2.6宏和函數對比
宏通常被應用于執行簡單的運算。
eg:在2個數中找出較大的一個,為什么不用函數來完成這個任務呢?
原因:
1.用于調用函數和從函數返回的代碼可能比實際執行這個小型計算工作所需要的時間更多。所以宏比函數在程序的規模和速度方面更勝一籌。
2.更為重要的是函數的參數必須聲明為特定的類型。所以函數只能在類型合適的表達式上使用。反之宏可以適用于整型、長整型、浮點型等可以>來比較的類型。宏是與類型無關的。
函數調用(參數傳參、棧幀創建)——>計算——>函數返回
宏的缺點:
1.每次使用宏的時候,一份宏定義的代碼將插入到程序中。除非宏比較短,否則可能大幅度增加程序的長度。
2.宏是沒法調試的。
3.宏由于類型無關,也就不夠嚴謹。
4.宏可能會帶來運算符優先級的問題,導致程序容易出錯。
宏有時候可以做函數做不到的事情。比如宏的參數可以出現類型,但是函數不可以。
#define MALLOC(num, type) (type*)malloc((num)*sizeof(type))int main()
{//malloc(40);//malloc(10, int); //errorint* p = (int*)MALLOC(10, int);//int* p = (int*)malloc((10)*sizeof(int));return 0;
}
| 屬性 | #define定義宏 | 函數 |
|---|---|---|
| 代碼長度 | 每次使用時,宏代碼都會被插入到程序中。除了非常小的宏除外,程序的長度會大幅度增長 | 函數代碼只出現于一個地方。每次使用這個函數時,到調用那個地方 |
| 執行速度 | 更快 | 存在函數的調用和返回的額外開銷,所以相對慢一些 |
| 操作符優先級 | 宏參數的求值是在所有周圍表達式的上下文環境里,除非加上括號,否則鄰近操作符的優先級可能會產生不可預料的后果,所以建議宏在書寫時多些括號 | 函數參數只在函數調用時求值一次,它的結果值傳遞給函數。表達式的求值結果更容易預測 |
| 帶有副作用的參數 | 參數可能被替換到宏體中的多個位置,所以帶有副作用的參數求值可能會產生不可預料的結果 | 函數參數只在傳參的時候求值一次,結果更容易控制 |
| 參數類型 | 宏的參數與類型無關,只要對參數的操作是合法的,它就可以適用于任何參數類型 | 函數的參數是與類型有關的,如果參數的類型不同,就需要不同的函數,即使它們執行的任務是相同的 |
| 調試 | 宏是不方便調試的 | 函數是可以逐語句/逐過程調試的 |
| 遞歸 | 宏是不能遞歸的 | 函數是可以遞歸的 |
3.2.7命名約定
一般來講函數和宏的使用語法很相似。所以語言本身沒法幫我們區分二者。那我們平時的習慣是:把宏名全部大寫;函數名不要全部大寫。
3.2.8#undef
這條指令用來移除一個宏定義。
#undef name
#define M 100#include <stdio.h>int main()
{printf("%d\n", M); //100
#undef M printf("%d\n", M); //errorreturn 0;
}
3.3命令行定義
linux下gcc編譯器實現:
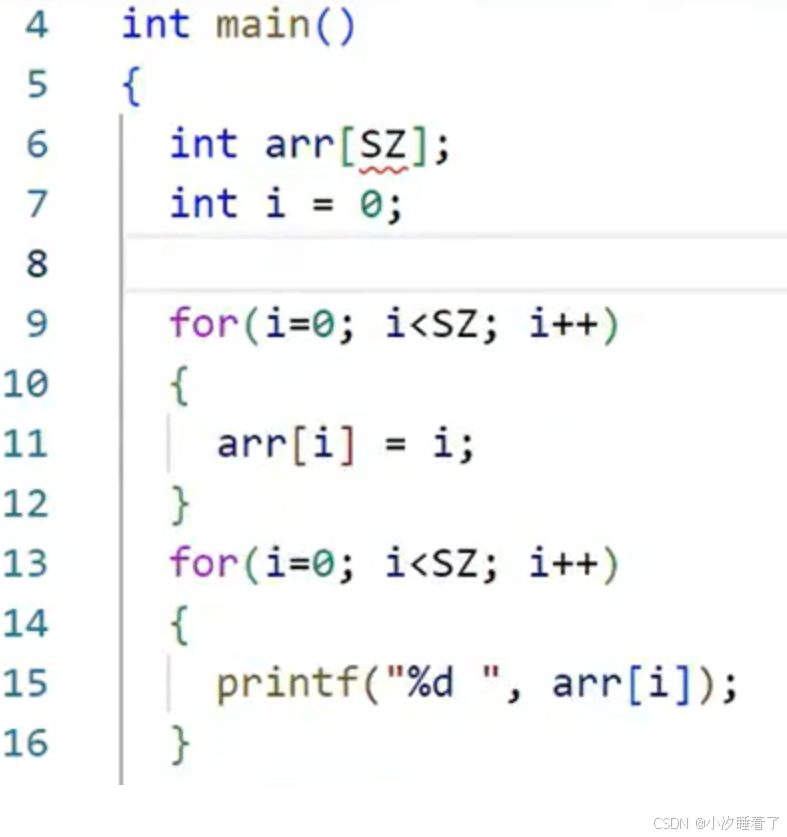
編譯指令
gcc test.c -D SZ=10
3.4條件編譯
在編譯一個程序的時候我們如果要將一條語句(一組語句)編譯或放棄是很方便的。因為我們由條件編譯指令。
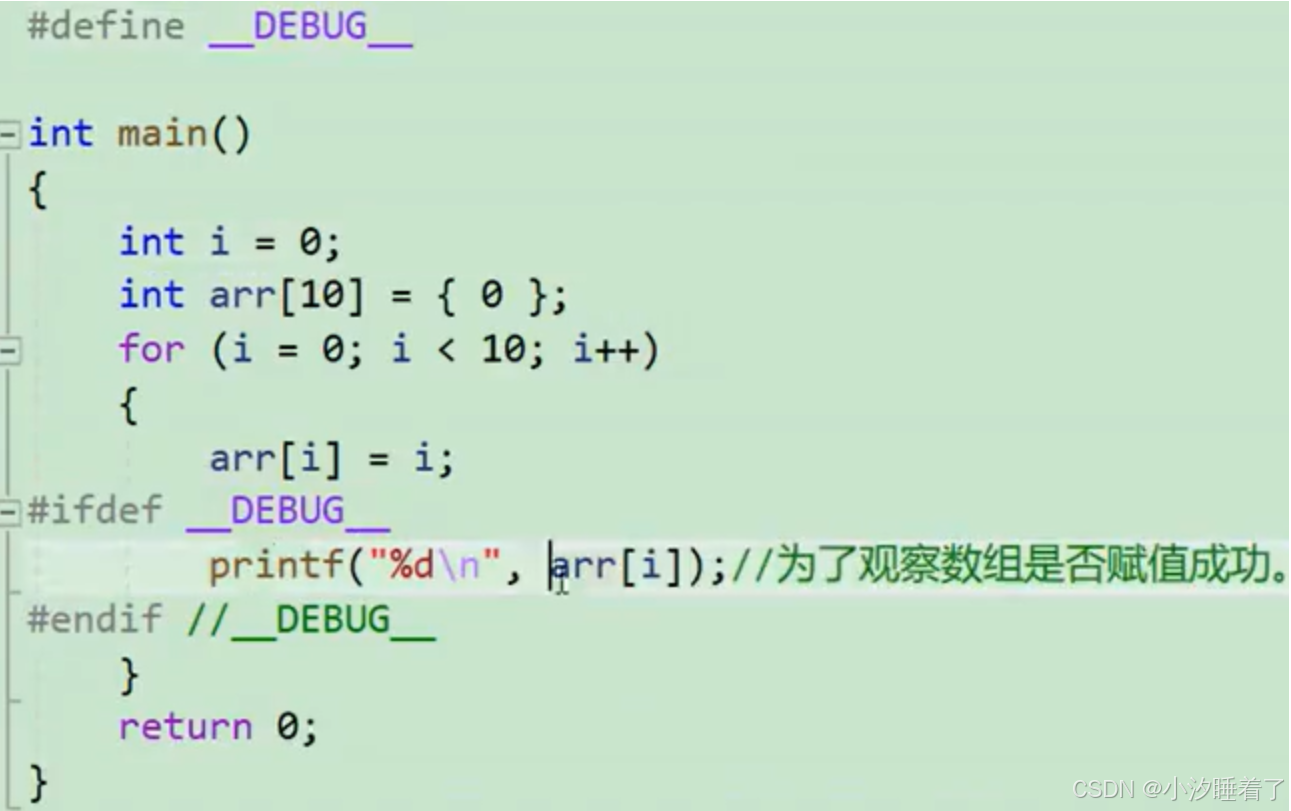
常見的條件編譯指令:
#if 常量表達式//···
#endif
#include <stdio.h>#if 0
int main()
{printf("hehe\n");return 0;
}
#endif
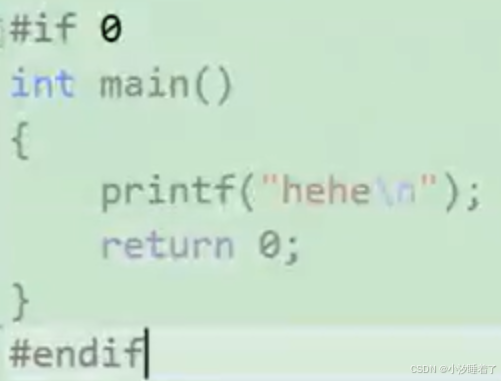
2.多個分支的條件編譯
#if 常量表達式//···
#elif 常量表達式//···
#else 常量表達式//···
#endif
#define MAX 3#include <stdio.h>int main()
{
#if M<5printf("hehe\n");
#elif M==5 printf("haha\n");
#elseprintf("heihei\n");
#endifreturn 0;
}
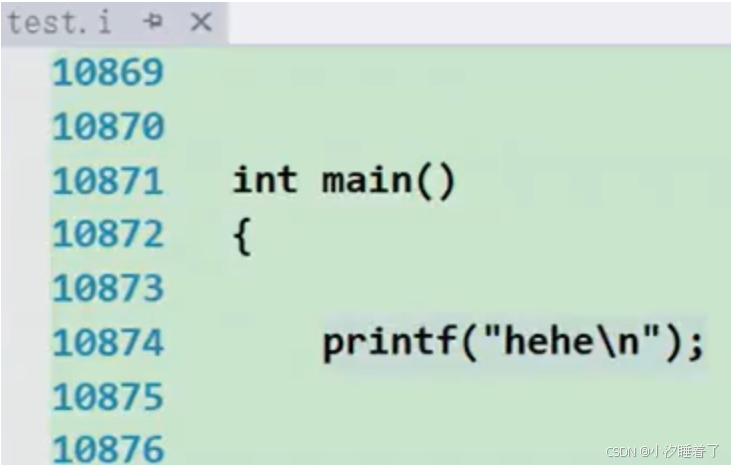
預編譯代碼:
3.判斷是否被定義
#if defined(symbol)
#ifdef symbol#if !defined(symbol)
#ifndef symbol
//#define MAX 100#include <stdio.h>int main()
{
#if !defined(MAX)printf("max\n");
#endifreturn 0;
}
#define MAX 100#include <stdio.h>int main()
{
#ifdef MAXprintf("max\n");
#endifreturn 0;
}
//#define MAX 100#include <stdio.h>int main()
{
#ifndef MAXprintf("max\n");
#endifreturn 0;
}
4.嵌套指令
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#ifdef OPTION2unix_version_option2();#endif
#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif
#endif
3.5文件包含
防止頭文件被多次重復的包含。
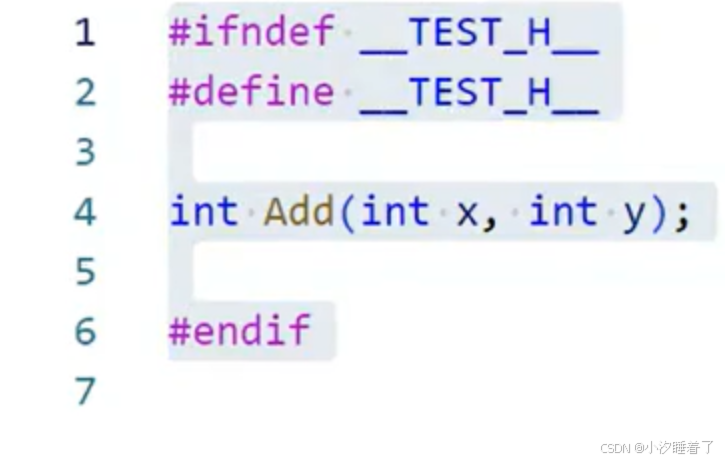
方案1:
#ifndef __TEST_H__
#define __TEST_H__
···
#endif
方案2:
#pragma once
#include <stdio.h> //庫文件包含
#include "test.h" //本地文件包含
<>和""的區別:查找的策略不同。
<>查找策略:直接去庫目錄下查找;
""查找策略:先去代碼所在的路徑下查找;如果找不到,再去庫目錄下查找。
Linux環境的標準頭文件的路徑:
/usr/include
VS環境的標準頭文件的路徑:(不同版本有差異)
C:\Program Files(x86)\Microsoft Visual Studio 12.0\VC\include
//這是VS2013的默認路徑
4.其他預處理指令
#error
#pragma
#line
···
不做介紹,自己了解,參考《C語言深度解剖》
#pragma pack()在結構體部分介紹。
百度筆試題(offsetof宏的實現)
寫一個宏,計算結構體中某變量相對于首地址的偏移,并給出說明。
#include <stdio.h>
#include <stddef.h>struct S
{char c1;int i;char c2;
};
int main()
{struct S s = {0};printf("%d\n", offsetof(struct S, c1)); //0printf("%d\n", offsetof(struct S, i)); //4printf("%d\n", offsetof(struct S, c2)); //8return 0;
}
#define OFFSETOF(type, m_name) (size_t)&(((type*)0)->m_name)
#include <stdio.h>struct S
{char c1;int i;char c2;
};
int main()
{struct S s = {0};printf("%d\n", OFFSETOF(struct S, c1)); //0printf("%d\n", OFFSETOF(struct S, i)); //4printf("%d\n", OFFSETOF(struct S, c2)); //8return 0;
}
總結
今天就暫且更新至此吧,期待下周再會。如有錯誤還請不吝賜教。希望對您學習有所幫助,翻頁前留下你的支持,以防下次失蹤了嗷。
作者更新不易,免費關注別手軟。



















中正確安裝 Rust)