Elasticsearch 作為一種高效的全文搜索引擎,廣泛應用于實時搜索、日志分析等場景。而 openGauss,作為一款企業級關系型數據庫,強調事務處理與數據一致性。那么,當這兩者的應用場景和技術架構發生交集時,如何實現它們之間的平滑遷移呢?
本文將探討 Elasticsearch 基礎數據數據遷移至 openGauss 的解決方案,在此,我們首先根據等價實例來看一下 Elasticsearch 和關系型數據庫(如 openGauss)的基礎數據結構:
關系型數據庫操作:
CREATE?TABLE?products (? ? id?INT?PRIMARY?KEY,? ? name?VARCHAR(100),? ? price?DECIMAL(10,2));INSERT?INTO?products?VALUES?(1,?'Laptop',?999.99);
Elasticsearch等價操作:
PUT /products{??"mappings": {? ??"properties": {? ? ??"id": {?"type":?"integer"?},? ? ??"name": {?"type":?"text"?},? ? ??"price": {?"type":?"double"?}? ? }? }}POST /products/_doc/1{??"id": 1,??"name":?"Laptop",??"price": 999.99}
數據組織層級:
-
關系型數據庫:
Database → Table → Row/Column
-
Elasticsearch:
6.x之前:Index → Type → Document (類似Database → Table → Row)
7.x之后:Index → Document (Type被移除,強化了Index≈Table的對應關系)
| Elasticsearch 概念 | 關系型數據庫(如openGauss)概念 | 說明 |
|---|---|---|
| 索引(Index) | 庫-表(Table) | 對應關系 |
| 類型(Type) | (已棄用,7.x后無對應) | 早期版本中類似表分區 |
| 文檔(Document) | 行(Row) | 一條記錄 |
| 字段(Field) | 列(Column) | 數據屬性 |
| 映射(Mapping) | 表結構定義(Schema) | 定義字段類型等 |
| 索引別名(Alias) | 視圖(View) | 虛擬索引/表 |
| 分片(Shard) | 分區(Partition) | 數據水平拆分 |
檢索方式
1、向量檢索
Elasticsearch 向量檢索
# 1. 創建包含向量字段的索引PUT /image_vectors{??"mappings": {? ??"properties": {? ? ??"image_name": {? ? ? ??"type":?"text"? ? ? },? ? ??"image_vector": {? ? ? ??"type":?"dense_vector",? ? ? ??"dims": 512? ? ? }? ? }? }}# 2. 插入向量數據POST /image_vectors/_doc{??"image_name":?"sunset.jpg",??"image_vector": [0.12, 0.34, ..., 0.56] ?// 512維向量}# 3. 精確向量檢索 (script_score)GET /image_vectors/_search{??"query": {? ??"script_score": {? ? ??"query": {"match_all": {}},? ? ??"script": {? ? ? ??"source":?"cosineSimilarity(params.query_vector, 'image_vector') + 1.0",? ? ? ??"params": {? ? ? ? ??"query_vector": [0.23, 0.45, ..., 0.67] ?// 查詢向量? ? ? ? }? ? ? }? ? }? }}# 4. 近似最近鄰搜索 (kNN search)GET /image_vectors/_search{??"knn": {? ??"field":?"image_vector",? ??"query_vector": [0.23, 0.45, ..., 0.67],? ??"k": 10,? ??"num_candidates": 100? }}
openGauss 向量檢索(openGauss 從 7.0 版本開始支持向量檢索功能)
#?1.?創建包含向量字段的表-- 創建表CREATE?TABLE?image_vectors (? id SERIAL?PRIMARY?KEY,? image_name TEXT,? image_vector VECTOR(512) ?-- 512維向量);#2.?插入向量數據INSERT?INTO?image_vectors (image_name, image_vector)?VALUES?('sunset.jpg',?'[0.12, 0.34, ..., 0.56]');#?3.?精確向量檢索 (余弦相似度)-- 使用余弦相似度SELECT?id, image_name,?? ? ? ?1?-?(image_vector?<=>?'[0.23, 0.45, ..., 0.67]')?AS?cosine_similarityFROM?image_vectorsORDER?BY?cosine_similarity?DESCLIMIT?10;#?4.?近似最近鄰搜索 (使用IVFFLAT索引)-- 創建IVFFLAT索引CREATE?INDEX idx_image_vector?ON?image_vectors?USING?IVFFLAT(image_vector)?WITH?(lists?=?100);-- 近似最近鄰查詢SELECT?id, image_name,?? ? ? ?image_vector?<=>?'[0.23, 0.45, ..., 0.67]'?AS?distanceFROM?image_vectorsORDER?BY?distanceLIMIT?10;
2、全文檢索
es全文檢索 相當于 openGauss的LIKE和正則表達式
??????????????
# es 全文檢索GET /products/_search{??"query": {? ??"match": {? ? ??"description":?"search term"? ? }? }}# openGauss 模糊查詢SELECT?* FROM products?WHERE?description LIKE?'%search term%';# openGauss 正則表達式匹配SELECT?* FROM logs?WHERE?message ~?'error|warning';
因此,根據數據層級及檢索方式分析,遷移時將es的索引遷移到openGauss的一張表里。
環境準備
-
已部署7.3 及以上(支持向量)版本的ElasticSearch實例
-
已部署7.0.0-RC1 及以上版本(支持向量)的openGauss實例
-
已安裝3.8 及以上版本的Python環境
-
已安裝涉及的Python庫
pip3 install psycopg2pip3 install requests?pip3 install pyOpenSSL#如果安裝失敗,可以考慮在一個新的虛擬環境中重新安裝所需的庫,執行以下命令:python3 -m venv venvsource?venv/bin/activatepip install requests pyOpenSSL
前置條件
遠程連接權限:
openGauss端:
???????
#修改openGauss配置文件。將遷移腳本所在機器IP地址加入白名單,修改openGauss監聽地址。# 執行以下命令gs_guc?set?-D {DATADIR} -c?" listen_addresses = '\*'"gs_guc?set?-D {DATADIR} -h?"host all all x.x.x.x/32 sha256"# 修改完畢后重啟openGauss。gs_ctl restart -D {DATADIR}
elasticsearch端:
???????
vim?/path/to/your_elasticsearch/config/elasticsearch.yml#修改network.hostnetwork.host:?0.0.0.0
openGauss端創建普通用戶(賦權)、遷移的目標數據庫:
???????
?create?user?mig_test identified?by?'Simple@123';?grant?all?privileges?to?mig_test;?create?database es_to_og?with?owner mig_test;
遷移操作
1、根據本地部署的elasticsearch與openGauss對腳本進行配置修改,需要修改的內容如下:
???????
# Elasticsearch 配置信息es_url?=?'http://ip:port'??# Elasticsearch 服務器地址es_index?=?'your_es_index'??# Elasticsearch 索引名# openGauss 配置信息db_host?=?'127.0.0.1'? ?# openGauss服務器地址db_port?=?5432? ? ? ? ??# openGauss 端口號db_name?=?'your_opengauss_db'?# 遷移到openGauss的數據庫名稱db_user?=?'user_name'? ??# 連接openGauss的普通用戶db_password?=?'xxxxxx'? ?# 連接openGauss的用戶密碼
elasticsearchToOpenGauss.py遷移腳本如下:
???????
import?requestsimport?psycopg2import?jsonimport?refrom?typing?import?List,?Dict,?Any,?Optional,?Union# Elasticsearch 配置信息es_url =?'http://192.168.0.114:9200'??# Elasticsearch 服務器地址es_index =?'my_dynamic_index'??# Elasticsearch 索引名# openGauss 配置信息db_host =?'192.168.0.219'? ?# openGauss服務器地址db_port =?15620? ? ? ? ??# openGauss 端口號db_name =?'es_to_og'?# 遷移到openGauss的數據庫名稱db_user =?'mig_test'? ??# 連接openGauss的普通用戶db_password =?'xxxxxx'? ?# 連接openGauss的用戶密碼RESERVED_KEYWORDS = {? ??"select",?"insert",?"update",?"delete",?"drop",?"table",?"from",?"where",?"group",? ??"by",?"having",?"order",?"limit",?"join",?"inner",?"left",?"right",?"full",?"union",? ??"all",?"distinct",?"as",?"on",?"and",?"or",?"not",?"null",?"true",?"false",?"case",? ??"when",?"then",?"else",?"end",?"exists",?"like",?"in",?"between",?"is",?"like",? ??"references",?"foreign",?"primary",?"key",?"unique",?"check",?"default",?"constraint",? ??"index",?"unique",?"varchar",?"text",?"int",?"bigint",?"smallint",?"boolean",?"timestamp"}# 從 Elasticsearch 獲取數據def?fetch_data_from_es():? ? query = {? ? ? ??"query": {? ? ? ? ? ??"match_all": {}? ? ? ? },? ? ? ??"_source":?True??# 獲取所有字段? ? }? ? response = requests.get(f'{es_url}/{es_index}/_search', json=query)? ??if?response.status_code ==?200:? ? ? ??return?response.json()['hits']['hits']? ??else:? ? ? ??raise?Exception(f"Failed to fetch data from Elasticsearch:?{response.status_code},?{response.text}")# 獲取索引映射信息def?fetch_mapping(es_url, es_index):? ? response = requests.get(f'{es_url}/{es_index}/_mapping')? ??if?response.status_code ==?200:? ? ? ??return?response.json()? ??else:? ? ? ??raise?Exception(f"Failed to fetch mapping:?{response.status_code},?{response.text}")def?get_field_type(es_url:?str, es_index:?str, field_name:?str) ->?str:? ??""" 獲取 Elasticsearch 字段的類型 """? ? mappings = fetch_mapping(es_url, es_index)? ??print(f"Field name:?{field_name}")? ??print(f"map:?{mappings}")? ??# 獲取 properties 字段? ? properties = mappings.get(es_index, {}).get('mappings', {}).get('properties', {})? ??# 遍歷并查找字段的類型? ? field_type =?'text'??# 默認類型為 'text'? ??if?field_name?in?properties:? ? ? ? field_type = properties[field_name].get('type',?'text')? ??elif?'fields'?in?properties.get(field_name, {}):? ? ? ??# 如果字段有子字段(比如 keyword),獲取 'keyword' 類型? ? ? ? field_type = properties[field_name]['fields'].get('keyword', {}).get('type',?'text')? ??return?field_typedef?convert_dict_to_jsonb(value):? ??# 如果 value 是字典類型,遞歸調用該函數處理其中的每個元素? ??if?isinstance(value,?dict):? ? ? ??return?json.dumps({k: convert_dict_to_jsonb(v)?for?k, v?in?value.items()})? ??# 如果 value 是列表類型,遞歸處理其中的每個元素? ??elif?isinstance(value,?list):? ? ? ??return?json.dumps([convert_dict_to_jsonb(v)?for?v?in?value])? ??# 如果是其他類型(如字符串、數字),直接返回該值? ??else:? ? ? ??return?value# 映射 Elasticsearch 數據類型到 openGauss 類型def?map_to_opengauss_type(es_type:?str, dim:?Optional[int] =?None) ->?str:? ??"""Map Elasticsearch types to openGauss types"""? ??if?isinstance(es_type, (dict,?list)): ?# 如果 es_type 是字典類型,則需要特殊處理? ? ? ??return?'JSONB'? ? type_map = {? ? ? ??"long":?"BIGINT", ?# 大整數? ? ? ??"integer":?"INTEGER", ?# 整數? ? ? ??"short":?"SMALLINT", ?# 小整數? ? ? ??"byte":?"SMALLINT", ?# 小字節? ? ? ??"float":?"REAL", ?# 浮點數? ? ? ??"double":?"DOUBLE PRECISION", ?# 雙精度浮點數? ? ? ??"boolean":?"BOOLEAN", ?# 布爾值? ? ? ??"keyword":?"VARCHAR", ?# 關鍵字(字符串類型)? ? ? ??"text":?"TEXT", ?# 長文本? ? ? ??"date":?"TIMESTAMP", ?# 日期類型? ? ? ??"binary":?"BYTEA", ?# 二進制數據? ? ? ??"geo_point":?"POINT", ?# 地理坐標(經緯度)? ? ? ??"geo_shape":?"GEOMETRY", ?# 復雜地理形狀? ? ? ??"nested":?"JSONB", ?# 嵌套對象? ? ? ??"object":?"JSONB", ?# 對象? ? ? ??"ip":?"INET", ?# IP 地址? ? ? ??"scaled_float":?"REAL", ?# 擴展浮動類型(帶縮放的浮動)? ? ? ??"float_vector":?f"VECTOR({dim})"?if?dim?else?"VECTOR", ?# 浮動向量類型? ? ? ??"dense_vector":?f"VECTOR({dim})"?if?dim?else?"VECTOR", ?# 稠密向量類型? ? ? ??"binary_vector":?f"BIT({dim})"?if?dim?else?"BIT", ?# 二進制向量類型? ? ? ??"half_float":?"REAL", ?# 半精度浮動? ? ? ??"unsigned_long":?"BIGINT", ?# 無符號長整數? ? ? ??"date_nanos":?"TIMESTAMP", ?# 高精度日期時間? ? ? ??"alias":?"TEXT", ?# 別名(通常是字段的別名)? ? }? ??# 如果 es_type 在映射表中,直接返回映射后的類型? ??if?es_type?in?type_map:? ? ? ??print(f"es_type:{es_type}?----- og_type:?{type_map[es_type]}")? ? ? ??return?type_map[es_type]? ??else:? ? ? ??print(f"Warning: Unsupported Elasticsearch type '{es_type}', defaulting to 'TEXT'")? ? ? ??return?'TEXT'??# 默認使用 TEXT 類型# 函數:將非法字符替換為下劃線def?sanitize_name(field_name:?str) ->?str:? ??"""處理字段名,確保不會與保留字沖突,且將非字母數字字符替換為下劃線"""? ??# 將所有非字母數字字符替換為下劃線? ? sanitized_name = re.sub(r'[^a-zA-Z0-9_]',?'_', field_name)? ??# 如果是保留字,則加雙引號? ??if?sanitized_name.lower()?in?RESERVED_KEYWORDS:? ? ? ??return?f'"{sanitized_name}"'? ??return?sanitized_name# 創建 openGauss 表def?create_table_in_opengauss(es_url, es_index, table_name):? ? columns_definition = ['id VARCHAR PRIMARY KEY'] ?# 增加 id 主鍵字段? ? seen_fields =?set() ?# 用于記錄已經處理過的字段名? ??# 獲取 properties 字段? ? properties = fetch_mapping(es_url, es_index).get(es_index, {}).get('mappings', {}).get('properties', {})? ??# 遍歷每個字段? ??for?field, field_info?in?properties.items():? ? ? ??# 如果該字段已經處理過,跳過? ? ? ??if?field?in?seen_fields:? ? ? ? ? ??continue? ? ? ??# 獲取字段的類型? ? ? ? es_type = field_info.get('type',?'text')? ? ? ? dim = field_info.get('dims',?0)?if?isinstance(field_info,?dict)?else?0? ? ? ? field_type = map_to_opengauss_type(es_type, dim)? ? ? ? sanitized_field_name = sanitize_name(field)? ? ? ? seen_fields.add(field)? ? ? ? columns_definition.append(f"{sanitized_field_name}?{field_type}")? ??# 生成表創建 SQL? ? columns_str =?", ".join(columns_definition)? ? create_table_sql =?f"DROP TABLE IF EXISTS?{sanitize_name(table_name)}; CREATE TABLE?{sanitize_name(table_name)}?({columns_str});"? ??try:? ? ? ??# 建立數據庫連接并執行創建表 SQL? ? ? ? connection = psycopg2.connect(? ? ? ? ? ? host=db_host,? ? ? ? ? ? port=db_port,? ? ? ? ? ? dbname=db_name,? ? ? ? ? ? user=db_user,? ? ? ? ? ? password=db_password? ? ? ? )? ? ? ? cursor = connection.cursor()? ? ? ? cursor.execute(create_table_sql)? ? ? ? connection.commit()? ? ? ??print(f"Table?{sanitize_name(table_name)}?created successfully.")? ??except?Exception?as?e:? ? ? ??print(f"Error while creating table?{sanitize_name(table_name)}:?{e}")? ??finally:? ? ? ??if?connection:? ? ? ? ? ? cursor.close()? ? ? ? ? ? connection.close()# 將數據插入到 openGauss 表中def?insert_data_to_opengauss(table_name, es_source, es_id):? ??try:? ? ? ??# 建立數據庫連接? ? ? ? connection = psycopg2.connect(? ? ? ? ? ? host=db_host,? ? ? ? ? ? port=db_port,? ? ? ? ? ? dbname=db_name,? ? ? ? ? ? user=db_user,? ? ? ? ? ? password=db_password? ? ? ? )? ? ? ? cursor = connection.cursor()? ? ? ??# 動態生成插入 SQL 語句? ? ? ? sanitized_columns = ['id'] + [sanitize_name(col)?for?col?in?es_source.keys()] ?# 清理列名? ? ? ? values = [es_id]? ? ? ??# 處理每一列的數據類型,必要時進行轉換? ? ? ??for?column?in?es_source:? ? ? ? ? ? value = es_source[column]? ? ? ? ? ??if?isinstance(value, (dict,?list)):? ? ? ? ? ? ? ??# 如果是字典類型,轉換為 JSONB? ? ? ? ? ? ? ? value = convert_dict_to_jsonb(value)? ? ? ? ? ? values.append(value)? ? ? ? columns_str =?', '.join(sanitized_columns)? ? ? ? values_str =?', '.join(['%s'] *?len(values))? ? ? ? insert_sql =?f"INSERT INTO?{sanitize_name(table_name)}?({columns_str}) VALUES ({values_str})"? ? ? ? cursor.execute(insert_sql, values)? ? ? ??# 提交事務? ? ? ? connection.commit()? ??except?Exception?as?e:? ? ? ??print(f"Error while inserting data into?{table_name}:?{e}")? ??finally:? ? ? ??if?connection:? ? ? ? ? ? cursor.close()? ? ? ? ? ? connection.close()# 主函數def?main():? ??try:? ? ? ? es_data = fetch_data_from_es()? ? ? ? table_name = es_index ?# 可以使用索引名作為表名? ? ? ? create_table_in_opengauss(es_url, es_index, table_name)? ? ? ??for?record?in?es_data:? ? ? ? ? ? es_source = record['_source'] ?# 獲取 Elasticsearch 文檔中的數據? ? ? ? ? ? es_id = record['_id']? ? ? ? ? ? insert_data_to_opengauss(table_name, es_source, es_id)? ? ? ??print(f"Successfully inserted data into table?{table_name}.")? ??except?Exception?as?e:? ? ? ??print(f"Migration failed:?{e}")if?__name__ ==?"__main__":? ? main()
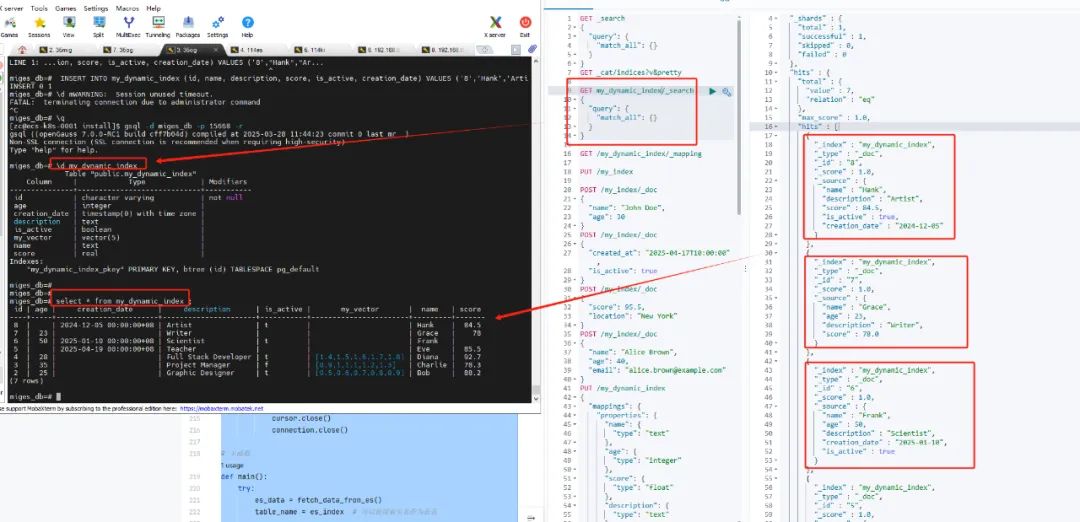
2、執行腳本
python3 ./elasticsearchToOpenGauss.py3、openGauss端查看數據???????
#切換到遷移目標數據庫openGauss=# \c es_to_og#查看遷移的表es_to_og=# \d#查看表結構es_to_og=# \d my_dynamic_index#查看表數據es_to_og=# select c
-END-
?
)







pytest簡介和環境準備)
第5章析因設計引導5.7節思考題5.5 R語言解題)
)
)

)


)


