一.整體介紹
1.單變量 vs 多變量時序數據
單變量就是只根據時間預測,多變量還要考慮用戶
2.為什么不能用機器學習預測:
a.時間不是影響標簽的關鍵因素
b.時間與標簽之間的聯系過于弱/過于復雜,因此時序模型依賴于時間與時間的相關性來進行預測,但普通機器學習模型并不會考慮樣本之間的相關性。
c.機器學習模型無法處理“沒見過的特征值”,但時序預測中時間特征永遠是未曾在歷史數據中出現過的、未來的日期
3.如何預測:
多步預測:如下圖所示,我們將測試集上的時間分割為5段,假設t是當前的時間,我們先使用訓練好的模型預測出t+d時間段的結果,將該結果加入訓練集、構成全新的訓練數據。即是說,我們將預測的值作為真實值加入到訓練集中再對下一個單位時間進行預測,這樣累加可以讓訓練數據的時間點與測試數據的時間點盡量接近。

缺點:多步預測中可能會導致誤差累加
需要注意的是,多步預測、單步預測都只適用于時間線的預測、而不適用于時間點的預測(即大部分時候不適用于多變量時間序列數據)。多變量時間序列數據在樣本上可以被打亂,因此只要保證同一對象在訓練集和測試集中的時間差,即可使用普通機器學習方式進行訓練和預測。
4.時序模型不太實用交叉驗證
傳統時序模型大多是統計學模型/數學模型,這些模型在建模前需要經過層層檢驗以滿足各種各樣的先決條件,因此當這些先決條件被滿足時,模型在理論上已經擁有一定的泛化能力,因此在學術界持有一派觀點:統計學模型/數學模型不需要交叉驗證。
如果想做:
單變量時序數據有自己獨特的交叉驗證方式,一般稱之為時序交叉驗證:先把訓練集按日期順序排序后分割,在每次驗證完之后將驗證時使用的樣本加入訓練集。如下圖
圖!!!!!!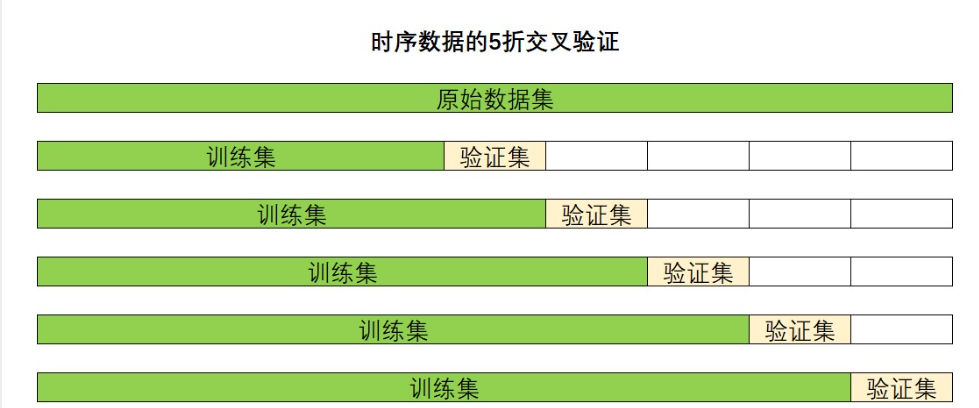
多變量時序數據由于沒有“不能打亂樣本順序”的鐵則,因此使用普通的交叉驗證也沒問題。
5.時間序列模型:
a.時序預測:我們使用規則+統計學模型來完成這類預測,但只要遵守“過去預測未來”的鐵律,我們也可以使用機器學習模型+多步預測等方式完成Forecasting。
b.時序有監督學習(重點):在多變量時間序列上,基于時間或時間相關的數據,完成回歸或分類任務。
它對樣本與樣本之間的時間順序、相關等都沒有要求、反而更關注特征之間的關系,因此這類任務要求:
數據中必須存在除時間之外的其他特征,且特征越多越好
如果有必要,可以完成“去時序化”處理,將時序數據徹底變為一般機器學習數據
我們使用規則+機器學習模型來完成這類預測。
二.當代時間序列算法群
派系1:ARIMA
四種方法:
AR:自回歸模型(AutoRegressive),是最典型的、最基礎的統計學時序模型之一,其基本思想就是根據歷史行為預測未來行為的模型。AR模型非常關注時間序列中的值與它之前和之后的值之間是否存在某種相關性,AR模型依賴于這種相關性運行。
MA:移動平均模型(Moving Average Model),同樣是非常經典的統計學模型之一,使用不同于自回歸模型的思路構建、也能夠得到很好的效果。相比起關注過去和未來的聯系,MA模型更在意每個時間點上的數值受到了外界偶然因素多大的影響。
ARIMA(最重要,綜合了前兩種):自回歸移動平均模型(ARIMA,Autoregressive Integrated Moving Average),是名聲最大、使用最廣泛時間序列預測方法之一。它結合了AR模型與MA模型的思想,即關系過去對未來的影響,也關心每個時間點上的數值受到外界偶然因素的影響,因此可以應對相對復雜的時間序列數據。
SARIMA:季節性自回歸綜合移動平均(SARIMA),這個模型擴展了ARIMA模型、在原本模型的基礎上允許ARIMA學習季節性模式,在按月、按季節或按年度呈現某種規律的數據上總是有很好的表現。
派系2:指數平滑
針對數據在較長一段時間內的趨勢性和季節性,因此指數平滑尤其擅長處理帶有系統性趨勢或季節性成分的數據。
派系3:Prophet
Prophet即沒有使用ARIMA一族、也沒有使用指數平滑的方法,而是使用Additive Model(加法模型)作為核心完成時序預測。
加法模型是一類與機器學習模型思路高度類似、但遵守時序預測規則的模型,它能夠支持非線性的時間序列趨勢、同時還能夠與年、周、月、季節等周期性的效應相匹配,因此非常適合用于受強烈季節性影響的時間序列。
在Facebook開發過程中,Prophet被設計成能夠處理節假日效應、能夠處理缺失值、能夠處理異常值、甚至能夠使用加法模型對非時序數據進行預測的“全能型時間序列庫”。可以說,Prophet是目前為止完成度較高的時間序列庫之一。
派系4:樹模型及其他高階機器學習模型:
只要對數據進行“去時序化”處理,或遵循“過去預測未來”的鐵則,我們就可以使用機器學習中任何高階有監督模型來對時間序列進行預測,例如XGBoost,LightGBM,CatBoost,DeepForest等等。(能夠使用機器學習模型的前提下,我們可能不會優先選擇時序模型,因為時序模型在建模過程中需要避開的陷阱實在是太多了。)
派系5:深度學習
RNN:循環神經網絡,本質是全連接網絡、但考慮了過去的信息,輸出不僅取決于當前輸入,還取決于之前的信息,因此可以被用于時間序列預測。循環神經網絡的輸出由之前的信息和此時的輸入共同決定,是深度學習領域最基礎的時序模型。
LSTM:長短期記憶網絡(Long Short-Term Memory Net)是循環神經網絡的變體,除了繼承循環神經網絡同時納入歷史和當前信息的能力之外,LSTM還可以學習序列中項目之間的順序依賴性和時間滯后性,這意味著LSTM可以處理不連續的時間,因此它非常適合基于時間序列數據進行分類、處理和預測。LSTM的開發是為了解決在訓練傳統RNN時可能遇到的梯度消失問題,而對斷裂的時間段相對不敏感是LSTM在眾多算法中優于RNN、隱馬爾可夫模型和其他序列學習方法的優勢。
GRU:門控循環單元結構(Gated Recurrent Unit)是LSTM網絡的一種變體,結構更加簡單、參數更少、訓練速度更快、訓練效果更好,能夠解決RNN網絡中的長依賴問題也能夠降低過擬合風險。在大多數時候,GRU表現出的結果與LSTM類似,但它的整體模型比LSTM更輕量。
前沿模型:
DeepAR:由Amazon提出的一種針對大量相關時間序列統一建模的預測算法,該算法使用循環神經網絡 (RNN) 結合自回歸(AR)來預測標量時間序列,在大量時間序列上訓練自回歸遞歸網絡模型,并通過預測目標在序列每個時間步上取值的概率分布來完成預測任務。
CNN:卷積神經網絡。卷積神經網絡是著名的圖像、視頻處理的基礎網絡,但近年來CNN用于時序數據的研究也越發成熟。通常來說,CNN比較少被用于單變量時序數據,更多是被用于多變量時序數據上的時序有監督分類。
N-BEATS:N-BEATS 是一種定制的深度學習算法,它基于后向和前向殘差鏈接進行單變量時間序列點預測。
Temporal Fusion Transformer(Google):時序融合transformer,一種新穎的基于注意力的架構,它結合了高性能多水平預測和對時間動態的可解釋洞察力。
三:具體算法介紹
1.ARIMA
AR自回歸模型
兩個假設:
不同時間點的標簽值之間強相關(highly-correlated),位于時間點t的標簽值一定強烈地受到t之前的標簽值的影響。在數學上,這意味著兩個時間點的標簽值之間的相關系數會較大。
根據時間的基本屬性,兩個時間點之間相隔越遠,相互之間的影響越弱(例如,昨天是否下雨對今天是否下雨的影響很大,但三個月前的某天是否下雨,對明天是否下雨的影響就相對較小)
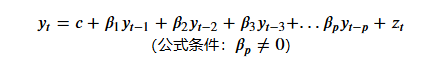
需要注意的是,該公式中包含兩個常數項: 𝑐 和 𝑧𝑡。其中,𝑐是線性方程中慣例存在的常數項(可以為0),而 𝑧𝑡則代表當前時間點下無法被捕捉到的某些影響,也就是白噪音(White Noise)。
很明顯,自回歸模型的公式與多元線性回歸相同,因此我們對自回歸模型的建模幾乎等同于對多元線性回歸的建模。但稍有區別的是,多元線性回歸中每個自變量都是一列數據,要求解的標簽也是一列數據,但在自回歸模型中每個自變量y都是一個樣本的數值,要求解的標簽y也是一個樣本的數值。?
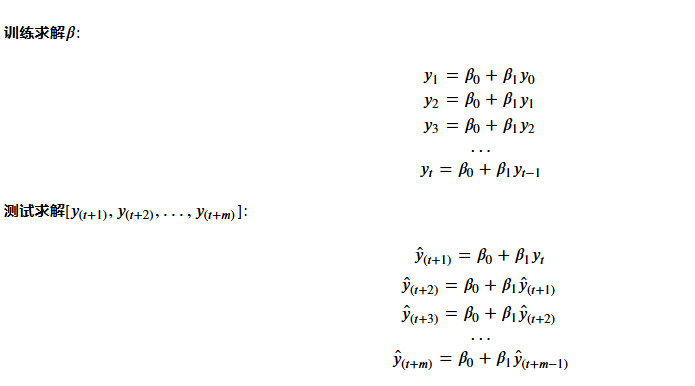
要用參數估計,根據t個方程來估計
問題:
1.p如何確定?
如果模型是AR(p),則需要保證要預測的第一個日期前面至少有p天的歷史記錄。可以通過ACF和PACF參數確定
?
2.MA模型:
思想是:大部分時候時間序列應當是相對穩定的。在穩定的基礎上,每個時間點上的標簽值受過去一段時間內、不可預料的各種偶然事件影響而波動。
該模型假設:
時間序列的(長期)趨勢與時間序列的(短期)波動受不同因素的影響。
不同時間點的標簽值之間是關聯的,但各種偶然事件在不同時間點上產生的影響之間卻是相互獨立的。
?

即均值+歷史偶然事件的加和
在理想條件下,MA模型規定 𝜖 應當服從均值為0、標準差為1的正態分布,但在實際計算時,MA模型規定 𝜖等同于模型的預測值𝑦^ 𝑡與真實標簽 𝑦𝑡之間的差值(Residuals),即:𝜖𝑡=𝑦𝑡?𝑦^ 𝑡
由于偶然事件是無法被預料的、偶然事件帶來的影響也是無法被預估的,因此MA模型使用預測標簽與真實標簽之間的差異就來代表“無法被預料、無法被估計、無法被模型捕捉的偶然事件的影響”。
訓練與預測:
?
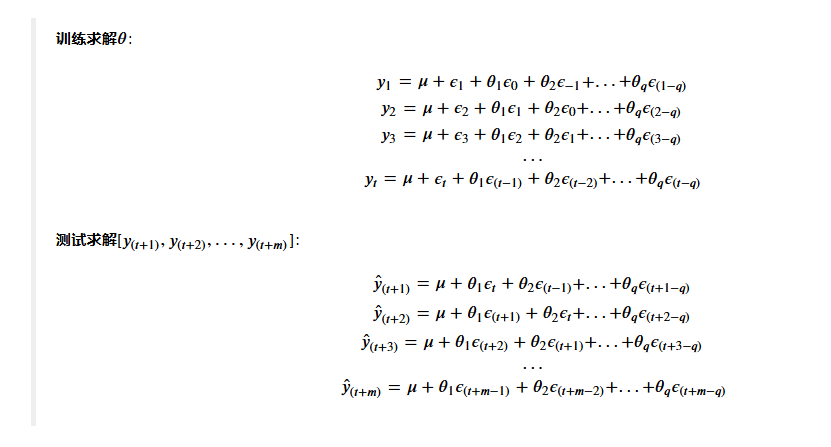
a.q是多少:一般都設置為[1,5]之內的正整數。
我們可以使用自相關系數ACF(Auto-correlation function)、偏相關系數PACF(Partial Auto-Correlation Function)或者相關的假設檢驗來幫助我們確定p、q等超參數的值,其中PACF用于確定AR模型的p值,ACF用于確定MA模型的q值,假設檢驗則可以同時用于兩種模型。
b.{ 𝜖1,𝜖2,𝜖3,...,𝜖𝑞 }分別是多少?{ 𝜇,𝜃1,𝜃2,...,𝜃𝑞 }分別是多少?
方法:使用帶迭代過程的參數估計辦法(如最小二乘、梯度下降等)對這些參數進行求解。先假設一組初始參數值(一般為隨機數),并在迭代過程中逐漸修正這些參數。因此我們可以假設最初的 𝜇和 𝜃1是任意隨機數。
9.ARIMA模型=MA+AR
a.公式:
?
![]()
以上模型被稱之為ARIMA(p,d,q)模型,其中p和q的含義與原始MA、AR模型中完全一致,且p和q可以被設置為不同的數值,而d是ARIMA模型需要的差分的階數
b.差分:未來時間點標簽值減去過去時間點標簽值
比如:

差分的階數:二階差分是兩次一階差分
差分的值滯后:往后移動幾格
差分的作用:消除時間序列中的季節性、周期性、節假日等影響。
推導可得:
𝑦″ =(𝑦𝑡?𝑦𝑡?1)?(𝑦𝑡?1?𝑦𝑡?2)=(1?𝐵)^2𝑦𝑡
在該公式中的 𝑑也正是ARIMA模型中的超參數 𝑑,𝐵𝑦𝑡=𝑦𝑡?1,B也稱為滯后運算
在實際使用中,我們經常將多步差分和高階差分混用,最典型的就是在ARIMA模型建模之前:一般我們會先使用多步差分令數據滿足ARIMA模型的基礎建模條件,再在ARIMA模型中使用低階的差分幫助模型更好地建模。例如,先對數據進行12步差分(相隔12步的值相減)、再在模型中進行1階差分,這樣可以令數據變得平穩的同時、又提取出數據中的周期性,極大地提升模型對數據的擬合精度。多步差分和高階差分可以混用。
誤區:只要數據具有趨勢性/周期性,我們就可以利用差分運算將其消除
差分運算的確可以被應用到大部分有趨勢性、周期性的時間序列數據上,但它不能解決所有時序數據的問題。首先,不是所有時序模型都要求數據是無趨勢性、無周期性的狀態,即便模型要求了,當差分運算不管用時,我們也可以使用其他方式消除數據的周期性和趨勢性。
比如如果數據存在季節性,我們可以從每個觀測值中減去當季所有觀測點的均值,如果數據是月度數據,我們則可以讓每月的觀測值減去當月的均值,以此類推。如果數據隨時間波動,形成類似于三角函數的波動,那我們可以讓每個觀測點除以周圍的波動率,以消除峰值。總之,我們需要具體情況具體分析,同時積累時序數據處理的經驗。
c.ARIMA對數據的基本要求:輸入ARIMA的時間序列數據必須是平穩的(stationary)數據。
平穩定義:在一段時間序列中,無論時間如何變化,該序列的標簽值的統計特性,
如均值、方差、協方差等屬性都保持不變,那這段時間序列就是平穩的。這樣過去才能預測未來。
怎么驗證平穩:
繪制折線圖/對時序數據進行統計并繪制直方圖/做統計檢驗
流程:用ADF單位根檢驗來完成平穩性的判斷——如果不平穩,則用差分運算消除數據中的趨勢(如果不行就用取對數,減均值等方法)——輸入ARIMA模型
ARIMA思考:ARIMA模型的假設與當代機器學習的假設一致:即時間并不是真正影響時序模型標簽值的因子。這為我們后續在單變量和多變量時間序列上進行去時序化提供了一定的理論基礎。
d.ACF與PACF:
自相關系數ACF衡量當前時間點上的觀測值與任意歷史時間點的觀測值之間的相關性大小(不關心是以什么方式相關),而偏自相關系數PACF衡量當前時間點上的觀測值與任意歷史時間點的觀測值之間的直接相關性的大小。
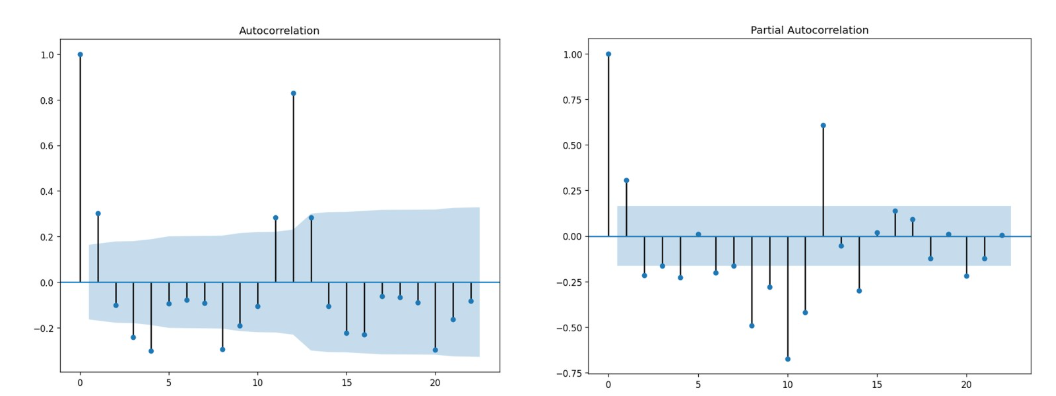
ACF圖和PACF圖的橫坐標相同,都是不同的滯后程度,而縱坐標是當前滯后程度下序列的ACF和PACF值。
藍色區域:當ACF/PACF值在藍色區域之外時,我們就認為當前滯后程度下的ACF/PACF是統計上顯著的值,即這個滯后程度下的序列之間的相關性很大程度上是信任的、不是巧合。
三種趨勢:拖尾(圖像呈現按規律衰減、自相關性呈現逐漸減弱的狀態)、截尾和既不拖尾也不截尾。
如何計算:ACF可以是任何能夠衡量兩個變量/兩個序列之間相關性的相關系數,最為常見的是直接使用皮爾遜相關系數。
e.用ACF、PACF進行超參數p、q、d的確定
對ARIMA模型來說,確定p和q的值有兩層含義:
1)確定要使用的具體模型是AR,MA還是ARIMA?(即,p和q中任意一個值為0嗎?)
2)如果是AR模型,p的值是多少?如果是MA模型,q的值是多少?如果是ARIMA模型,p和q分別是多少?
分類:
當ACF圖像呈現拖尾、且PACF圖像呈現截尾狀態時,當前時間序列適用AR模型,且PACF截尾的滯后階數就是超參數p的理想值
當PACF圖像呈現拖尾、且ACF圖像呈現截尾狀態時,當前時間序列適用MA模型,且ACF截尾的滯后階數就是超參數q的理想值(如下圖所示,q=1)。
當ACF圖像和PACF圖像都呈現不呈現拖尾狀態時,無論圖像是否截尾,時間序列都適用于ARIMA模型,且此時ACF和PACF圖像無法幫助我們確定p和q的具體值,但能確認p和q一定都不為0。
方法:當確定使用AR模型時,我們用PACF決定p值。當確定使用MA模型時,我們用ACF決定q值。當確定使用ARIMA模型時,ACF和PACF是失效的,并無作用。
當確定要使用ARIMA模型時,傻瓜式嘗試確定p和q值。
d:從0 1 2 3 中選擇方差最小、差分后數據噪音程度較低的階數,盡量避免過差分。我們也可以對進行差分后的數據繪制ACF圖像,如果滯后為1時ACF為負數,那大概率說明此時的高階差分會導致過差分。
幾個問題:
1.是否會出現ACF和PACF都拖尾、不截尾的情況?
幾乎不會出現,如果是這樣的情況,可以嘗試先保證時間序列平穩后再繪制ACF和PACF。
2.如果ACF或PACF拖尾,但另一個指標不截尾(比如,沒有任何滯后對應的值顯著),無法選擇p或q的值怎么辦?
同樣的,嘗試令序列平穩后再繪制ACF和PACF。如果依然出現相同的情況,考慮使用[1,3]之間的正整數進行嘗試。如果嘗試失敗,則考慮直接升級為ARIMA模型。
3.如果ACF或PACF中出現多個顯著的值,如何選擇截斷處?
這種情況下往往選擇第一個截斷處作為p或q的值,當然你也可以嘗試其他顯著的點,但一般來說都是第一個截斷處效果最好。
f.時序模型的評估指標
常用赤池信息準則(Akaike Information Criterion,AIC)、貝葉斯信息準則(Bayesian Information Criterion,BIC)、漢南-奎因信息準則(Hannan–Quinn information criterion,HQIC)等
其中最常用的AIC:
𝐴𝐼𝐶=?2𝑙𝑛(𝐿)+2𝑘
𝐿可以被認為是當前模型的積極性評估指標(即模型越好、該評估指標越高),大部分情況下我們使用的是統計學模型的極大似然估計結果(MLE,Maximum Likelihood Estimation),𝑘
則代表該模型中需要被估計的參數量,而𝑙𝑛的底數為自然底數𝑒。AIC越小越好
其他指標:BIC與AIC非常相似,它對模型參數量的懲罰高于AIC,因此BIC也是越低越好,經常和AIC一起組合使用。HQIC平時使用不多,但同樣作為越低越好的指標,當模型的AIC和BIC高度相似時,我們可能會對比HQIC的值來評估模型。
注意:BIC與AIC非常相似,它對模型參數量的懲罰高于AIC,因此BIC也是越低越好,經常和AIC一起組合使用。HQIC平時使用不多,但同樣作為越低越好的指標,當模型的AIC和BIC高度相似時,我們可能會對比HQIC的值來評估模型。
四.多變量時序模型:
1.多變量時間序列要做變形,如圖:
圖!!!!!!!!!!!!!!!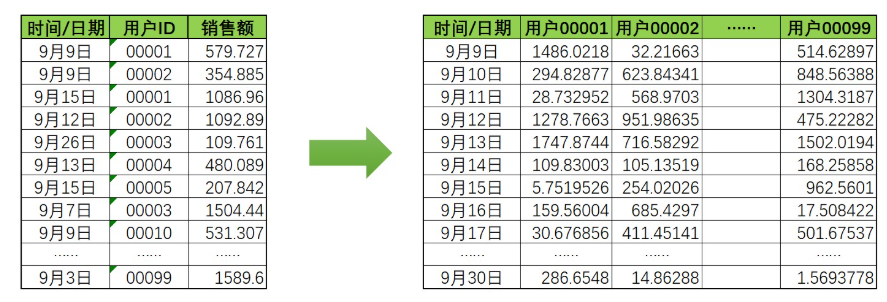
在多變量時間序列中,一個時間點下會需要求解多個值。并且,不同變量之間的值應該是會互相影響的,否則沒有必要強行組成多變量時序數據,但單變量時序模型只能處理一個變量和自己歷史數據的關系,卻不能處理變量與變量之間的聯系。
多變量時序模型的預測思路:所有變量的歷史數據共同影響一個變量的未來。
解決思路:拓展ARIMA系列模型的假設,直接跨變量建立當前時間點上的值與所有歷史時間點上的值的關聯。
如下圖所示,ARIMA模型假設一個變量的未來是由該變量的歷史決定的,而我們可以將該假設拓展至所有變量:一個變量的未來是由該變量自己和所有其他變量的歷史共同決定的。只要我們求解出未來的值和多個變量上的歷史值之間的系數,就可以擬合變量與自身關系的同時、也擬合出變量之間的關系。大部分統計學模型使用了這樣的思路。
2.VAR與VARMA
分別是在AR模型和ARIMA基礎上把變量改為向量組得到
?
二.機器學習中的時序模型:用pmdarima實現
pmd自動化建模:僅考慮AIC最小的模型,不考慮其它穩定性等因素
# 自動化建模,只支持SARIMAX混合模型,不支持VARMAX系列模型
arima = pm.auto_arima(train, trace=True, #訓練數據,是否打印訓練過程?
? ? ? ? ? ? ? ? ? ? ? error_action='ignore', suppress_warnings=True, #無視警告和錯誤
? ? ? ? ? ? ? ? ? ? ? maxiter=5, #允許的最大迭代次數
? ? ? ? ? ? ? ? ? ? ? seasonal=True, m=12 #是否使用季節性因子?如果使用的話,多步預測的步數是多少?
? ? ? ? ? ? ? ? ? ? ?)
存在的問題:它會遍歷所有pqd找到最佳模型,但這個結果往往無法滿足統計學上的各類檢驗要求
同時我們也很容易發現,由于數據集分割的緣故,autoarima選擇出的最佳模型可能無法被復現
交叉驗證:
因為時間序列數據必須遵守“過去預測未來”、“訓練中時間順序不能打亂”等基本原則,因此傳統機器學習中的k折交叉驗證肯定無法使用。
在時間序列的世界中,有以下兩種常見的交叉驗證方式:滾動交叉驗證(RollingForecastCV)和滑窗交叉驗證(SlidingWindowForecastCV),當我們提到“時序交叉驗證”時,一般特指滾動交叉驗證。我們具體來看一下兩種交叉驗證的操作:
1.滾動交叉驗證(RollingForecastCV)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
results = cross_validate(reg,Xtrain,Ytrain,cv=cv)
圖!!!!!!!!!!!!!!!!
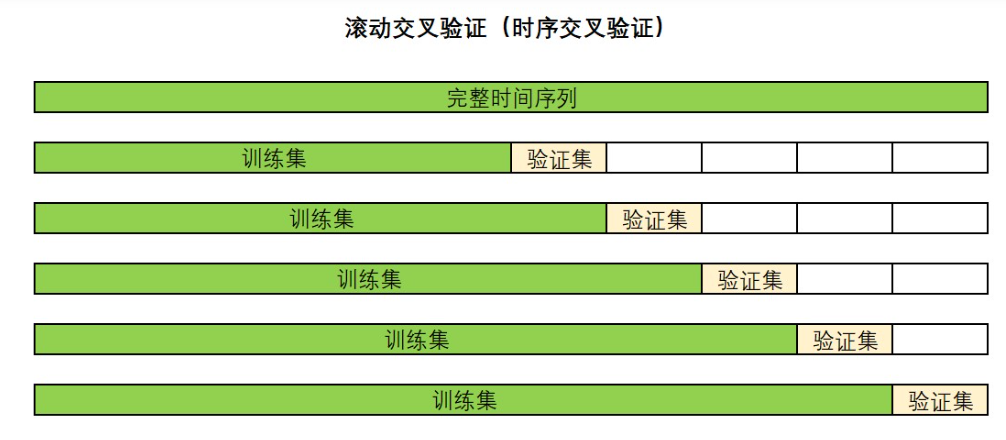 注意:普通K折交叉驗證是由折數來控制的,但時序交叉驗證其實是以單個樣本為單位的。一般來說,時序交叉驗證的驗證集可以是多個時間點,也可以為單個時間點。
注意:普通K折交叉驗證是由折數來控制的,但時序交叉驗證其實是以單個樣本為單位的。一般來說,時序交叉驗證的驗證集可以是多個時間點,也可以為單個時間點。
pmdarima.model_selection.RollingForecastCV(h=1, step=1, initial=None)
其中參數:
h:驗證集中的樣本數量,可以輸入[1, n_samples]的整數。
step:訓練集中每次增加的樣本數量,必須為大于等于1的正整數。
initial:第一次交叉驗證時的訓練集樣本量,如果不填寫則按1/3處理。
注意:驗證集不一定要完全放入訓練集
存在的問題:前幾次訓練分數較差,不清楚到底是模型泛化能力不行導致的過擬合還是訓練數據不夠導致的欠擬合
因此希望讓訓練集和驗證集樣本大小都保持不變:滑窗交叉驗證
2.滑窗交叉驗證
pmdarima.model_selection.SlidingWindowForecastCV(h=1, step=1, window_size=None)

h:驗證集中的樣本數量,可以輸入[1, n_samples]的整數。
step:每次向未來滑窗的樣本數量,必須為大于等于1的正整數。
window_size:滑窗的尺寸大小,如果填寫None則按照樣本量整除5得到的數來決定。
#使用pm自帶的數據集進行嘗試
cv = model_selection.SlidingWindowForecastCV(h=1, step=1, window_size = 10)
cv_generator = cv.split(data)
next(cv_generator) #首次進行交叉驗證時的數據分割狀況
next(cv_generator) #第二次進行交叉驗證時的數據分割狀況
時序交叉驗證不會返回訓練集上的分數,同時pmdarima的預測功能predict中也不接受對過去進行預測。通常來說我們判斷過擬合的標準是訓練集上的結果遠遠好于測試集,但時序交叉驗證卻不返回訓練集分數,因此時間序列數據無法通過對比訓練集和測試集結果來判斷是否過擬合。通常來說,驗證集上的分數最佳的模型過擬合風險往往最小,因為當一個模型學習能夠足夠強、且既不過擬合又不欠擬合的時候,模型的訓練集和驗證集分數應該是高度接近的,所以驗證集分數越好,驗證集的分數就越可能更接近訓練集上的分數。
?











)
)
)

)


 函數詳解)
