LAS
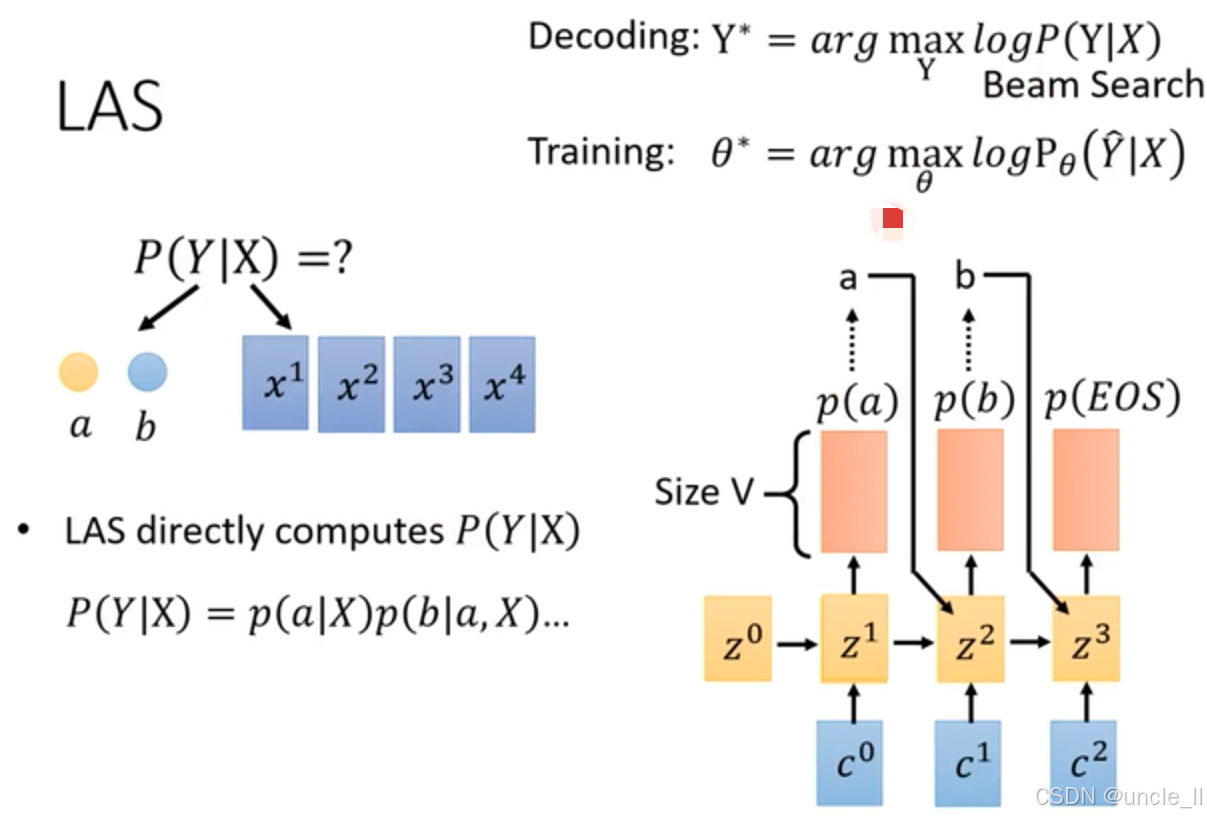
LAS(Listen, Attend and Spell )模型,在語音識別中的解碼和訓練過程,具體內容如下:
解碼(Decoding)
- 公式 Y ? = arg ? max ? Y log ? P ( Y ∣ X ) Y^* = \arg\max_Y \log P(Y|X) Y?=argmaxY?logP(Y∣X) 表示解碼階段的目標是找到使對數條件概率 log ? P ( Y ∣ X ) \log P(Y|X) logP(Y∣X) 最大的文本序列 Y ? Y^* Y?。這里使用束搜索(Beam Search)算法實現,該算法在每一步保留若干個概率最高的候選路徑,以平衡計算量和搜索效果,避免窮舉所有可能序列。
訓練(Training)
- 公式 θ ? = arg ? max ? θ log ? P θ ( Y ^ ∣ X ) \theta^* = \arg\max_{\theta} \log P_{\theta}(\hat{Y}|X) θ?=argmaxθ?logPθ?(Y^∣X) 表示訓練階段要找到最優的模型參數 θ ? \theta^* θ?,使模型在給定語音特征 X X X 時,預測文本序列 Y ^ \hat{Y} Y^ 的對數概率最大。通過最大化這個對數似然函數,調整模型參數以提升對語音 - 文本映射關系的學習能力。
模型計算
- 延續前文,再次強調 “LAS directly computes P ( Y ∣ X ) P(Y|X) P(Y∣X)” ,計算方式為 P ( Y ∣ X ) = p ( a ∣ X ) p ( b ∣ a , X ) ? P(Y|X) = p(a|X)p(b|a, X)\cdots P(Y∣X)=p(a∣X)p(b∣a,X)? ,即依次計算每個 token 基于語音特征和已生成 token 的條件概率。
- 右側展示模型結構,黃色解碼器單元 z 0 ? z 3 z^0 - z^3 z0?z3結合藍色上下文向量 c 0 ? c 2 c^0 - c^2 c0?c2 輸出不同 token 概率(如 p ( a ) p(a) p(a)、 p ( b ) p(b) p(b)、 p ( E O S ) p(EOS) p(EOS)),用于生成文本序列。
CTC, RNN-T
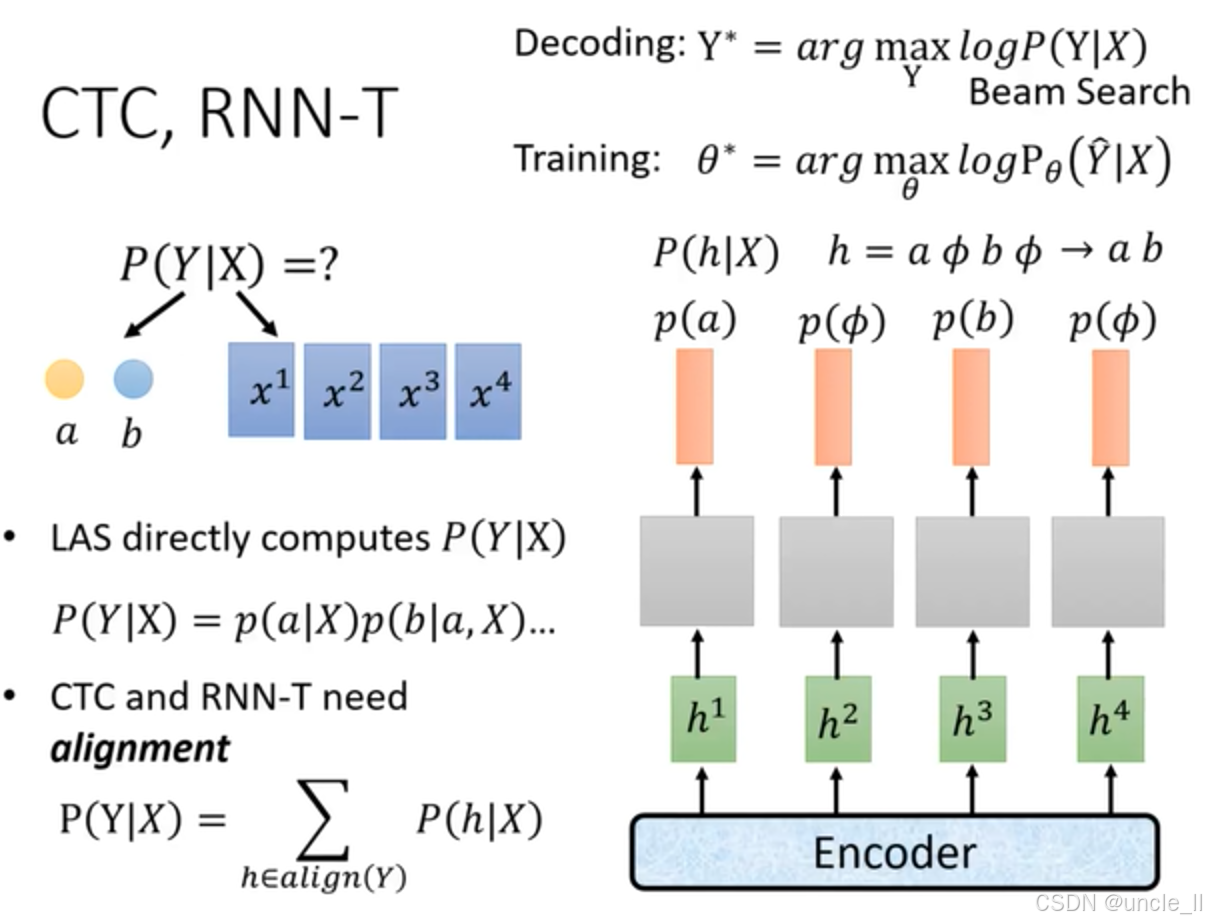
這張圖對比了LAS與CTC、RNN - T在語音識別中的原理,重點闡述了CTC和RNN - T的特性:
解碼與訓練基礎
- 解碼:公式 Y ? = arg ? max ? Y log ? P ( Y ∣ X ) Y^* = \arg\max_Y \log P(Y|X) Y?=argmaxY?logP(Y∣X) 表示解碼目標是找出使對數條件概率 log ? P ( Y ∣ X ) \log P(Y|X) logP(Y∣X) 最大的文本序列 Y ? Y^* Y?,通過束搜索(Beam Search)實現。
- 訓練:公式 θ ? = arg ? max ? θ log ? P θ ( Y ^ ∣ X ) \theta^* = \arg\max_{\theta} \log P_{\theta}(\hat{Y}|X) θ?=argmaxθ?logPθ?(Y^∣X) 意味著訓練時要找到最優參數 θ ? \theta^* θ?,最大化模型預測文本序列 Y ^ \hat{Y} Y^ 基于語音特征 X X X的對數概率。
LAS模型特點
- LAS直接計算 P ( Y ∣ X ) P(Y|X) P(Y∣X) ,計算方式為 P ( Y ∣ X ) = p ( a ∣ X ) p ( b ∣ a , X ) ? P(Y|X) = p(a|X)p(b|a, X)\cdots P(Y∣X)=p(a∣X)p(b∣a,X)?,依次計算每個token基于語音特征及已生成token的條件概率。
CTC和RNN - T模型特點
- 對齊需求:與LAS不同,CTC和RNN - T需要進行對齊(alignment)操作。模型通過編碼器得到隱藏狀態 h 1 ? h 4 h^1 - h^4 h1?h4,計算 P ( h ∣ X ) P(h|X) P(h∣X),其中 h h h 序列包含空白符 ? \phi ? (如 h = a ? b ? h = a \phi b \phi h=a?b?) 。
- 概率計算:CTC和RNN - T計算 P ( Y ∣ X ) P(Y|X) P(Y∣X) 時,需對所有與目標文本序列 Y Y Y 對齊的路徑 h h h求和,即 P ( Y ∣ X ) = ∑ h ∈ a l i g n ( Y ) P ( h ∣ X ) P(Y|X) = \sum_{h \in align(Y)} P(h|X) P(Y∣X)=∑h∈align(Y)?P(h∣X)。最終將含空白符的 h h h 序列映射為目標文本序列(如 a ? b ? → a b a \phi b \phi \to a b a?b?→ab ),解決語音與文本時間不對齊問題。
怎么窮舉所有的可能組合
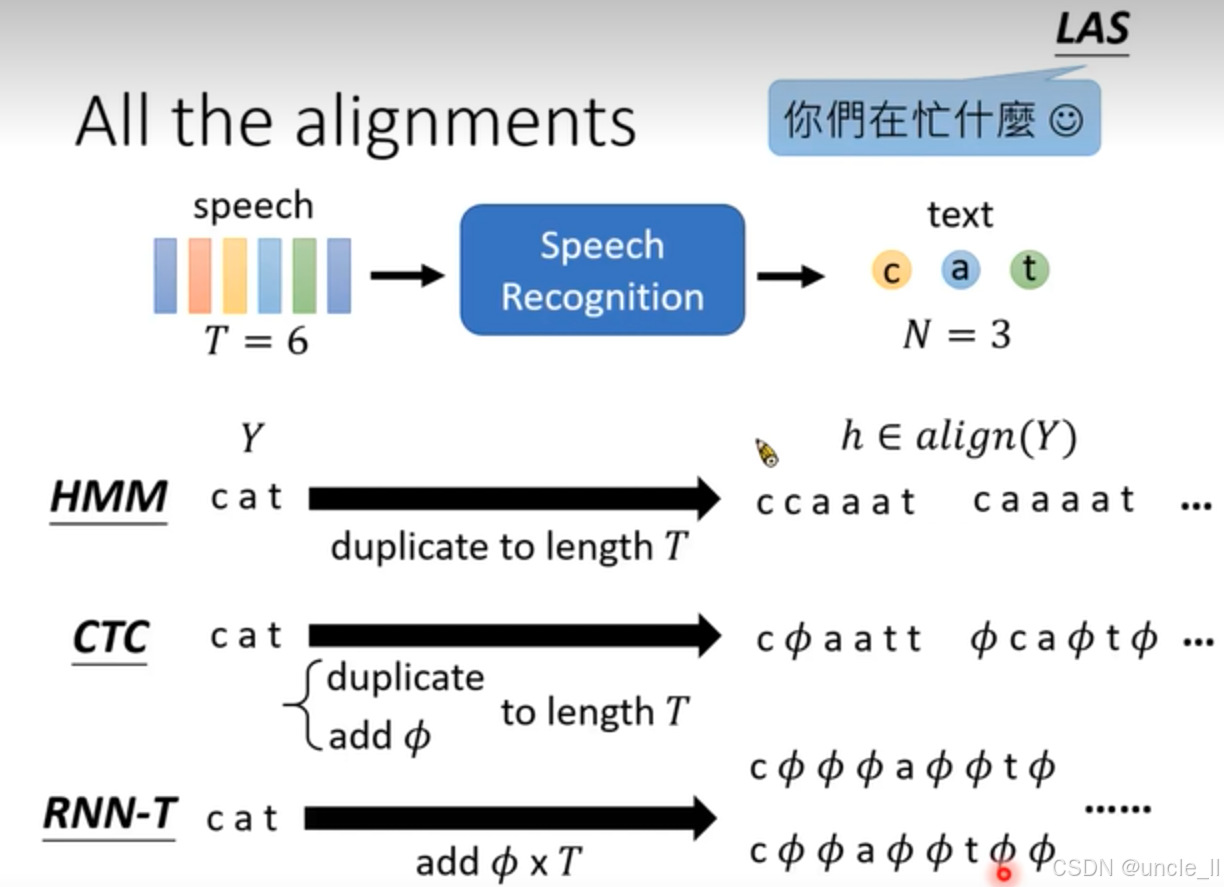
語音識別的對齊方式:
- 圖表中部從 “speech”(時長T = 6)到 “text”(字數N = 3)的流程,直觀呈現了語音識別從輸入語音信號到輸出文本的過程。這里時長T和字數N的標注,體現了語音和文本在長度上的對應關系,也是對齊操作需要解決的關鍵問題,即如何將時長為T的語音準確對應到字數為N的文本上。
不同方法展示
- HMM:HMM(隱馬爾可夫模型)在語音識別中通過狀態轉移和發射概率來建模語音信號。這里展示將 “cat” 擴展到長度T的方式,反映了HMM如何將離散的文本單元對應到連續的語音片段上。其示例結果展示了HMM在對齊過程中的具體實現,可能是通過一系列狀態轉移來匹配語音的不同時段和文本的每個字符。
- CTC:CTC(Connectionist Temporal Classification)是一種用于解決序列對齊問題的方法。它通過引入空白符,允許模型在不需要預先知道語音和文本精確對齊關系的情況下進行訓練。圖中展示的將 “cat” 擴展到長度T的示例,體現了CTC在處理語音和文本對齊時的靈活性,它可以自動處理語音和文本之間的時間不對齊問題。
- RNN - T:RNN - T(RNN Transducer)也是一種處理序列到序列任務的模型。它結合了循環神經網絡和變換器的特點,能夠直接對語音和文本進行聯合建模。圖中展示的將 “cat” 擴展到長度T的示例,展示了RNN - T在語音識別對齊中的具體操作方式,它可能通過遞歸計算來逐步生成文本序列,同時考慮語音的上下文信息。
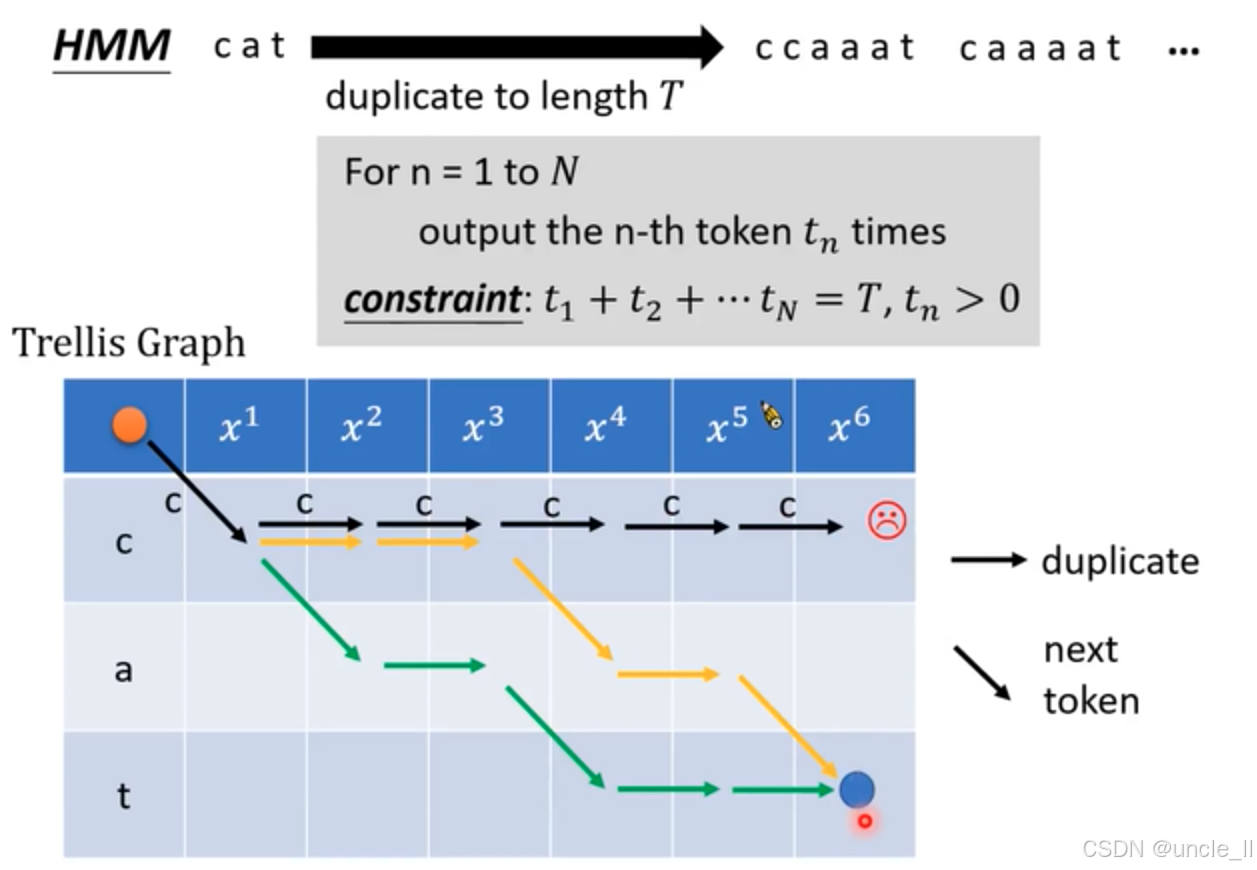
隱馬爾可夫模型(HMM)在語音識別中的對齊過程展開,詳細展示了將文本 “cat” 擴展到指定長度 T T T 的方法以及對應的網格圖表示,以下是詳細解釋:
文本擴展部分
- 擴展目標與方式:圖上方左側 “HMM” 標識表明這部分內容基于隱馬爾可夫模型。“cat” 通過向右的黑色粗箭頭指向 “ccaaat caaaat …” ,將 “cat” 中的每個字符重復若干次,以達到總長度為 T T T 的序列。
- 約束條件:灰色文本框內的公式 “For n = 1 to N output the n - th token t n t_n tn? times constraint: t 1 + t 2 + ? t N = T , t n > 0 t_1 + t_2+\cdots t_N = T, t_n > 0 t1?+t2?+?tN?=T,tn?>0” 給出了具體的約束條件。這里 N N N 是文本 “cat” 的字符數量( N = 3 N = 3 N=3), t n t_n tn? 表示第 n n n 個字符重復的次數,所有字符重復次數之和要等于 T T T,且每個字符至少重復一次。
- 網格圖標識:中間左側 “Trellis Graph” 表明這是一個網格圖,常用于表示序列對齊過程中的狀態轉移。
- 網格內容:第一行藍色方格內的 x 1 x^1 x1 到 x 6 x^6 x6 代表語音信號的不同時刻或特征,其中 x 5 x^5 x5 旁的火箭圖標和 x 6 x^6 x6旁的紅色表情圖標可能是用于特殊標記或強調。左側三行灰色方格內的 c、a、t 對應文本 “cat” 中的字符。
- 箭頭含義:黑色箭頭 “duplicate” 表示字符重復,即沿著同一行繼續選擇相同字符;黑色細箭頭 “next token” 表示切換到下一個字符。從左上角橙色圓點開始,不同顏色的箭頭代表不同的對齊路徑,最終都指向右下角藍色圓點,藍色圓點下的紅色亮點表示最終的結束狀態或目標狀態。

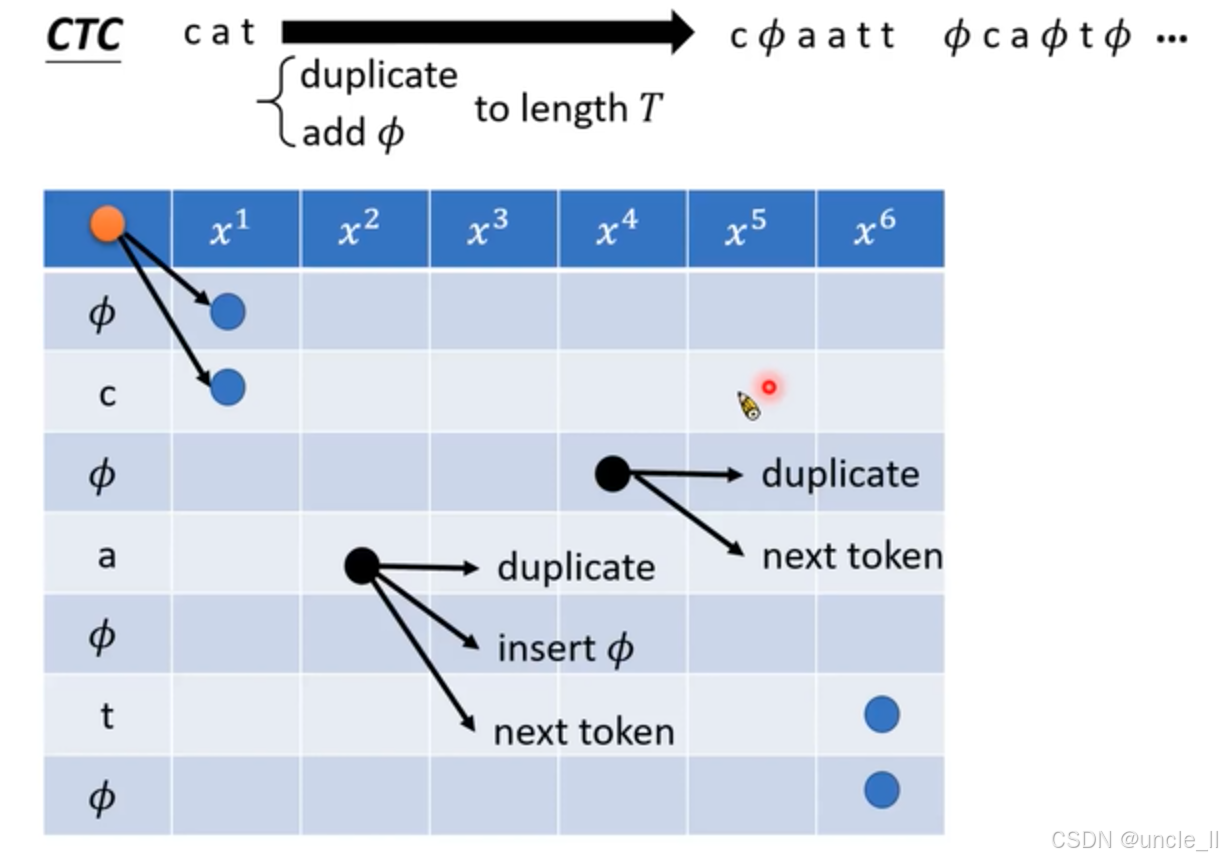
-
操作過程:圖中 “CTC” 字樣明確了主題。從 “cat” 出發,經過 “duplicate”(重復)和 “add ? \phi ?”(添加空白符)操作,得到諸如 “ c ? a a t t ? c a ? t ? ? c\phi aatt \phi ca\phi t\phi \cdots c?aatt?ca?t??” 這樣的序列。這體現了 CTC 允許在文本中插入空白符,以解決語音和文本在時間上的不對齊問題。
-
規則約束:下方灰色文本框內的代碼樣式文字給出了詳細的輸出規則和約束條件。它規定了先輸出若干次空白符 ? \phi ? ,然后依次輸出第 n n n個 token 若干次。約束等式和不等式確保了生成序列的長度和字符組合符合要求,如所有字符(包括空白符)出現次數之和要滿足一定條件,每個字符重復次數有相應的限制等。
-
文本擴展:“cat” 通過 “duplicate” 和 “add ? \phi ?” 操作轉換為 “ c ? a a t t ? c a ? t ? ? c\phi aatt \phi ca\phi t\phi \cdots c?aatt?ca?t??” 并延長到長度 T T T 。
-
網格圖表示:中間的藍色方格網格是核心部分。方格內標注的 x 1 x^{1} x1 到 $ x^{6}$ 代表語音信號的不同時刻或特征。方格內的不同顏色圓點、符號 ? \phi ?以及字母 “c”“a”“t” 表示不同的狀態。黑色箭頭和文字說明 “duplicate”(重復當前字符)、“next token”(切換到下一個字符)、“insert ? \phi ?”(插入空白符) 展示了狀態之間的轉移規則。帶有爆炸效果的小圖標可能是用于特殊標記或強調某個關鍵狀態或操作。
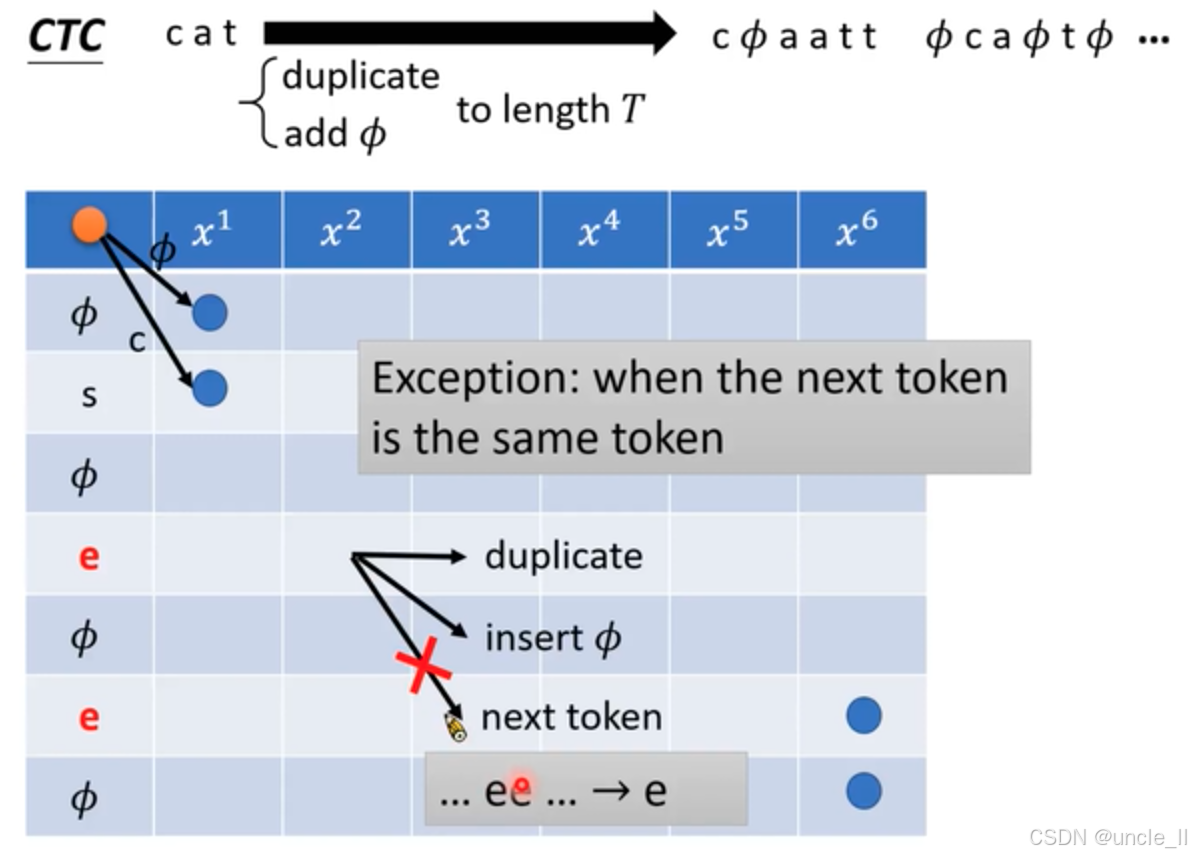
當下一個 token 和當前 token 相同時的處理規則是不能往下走。
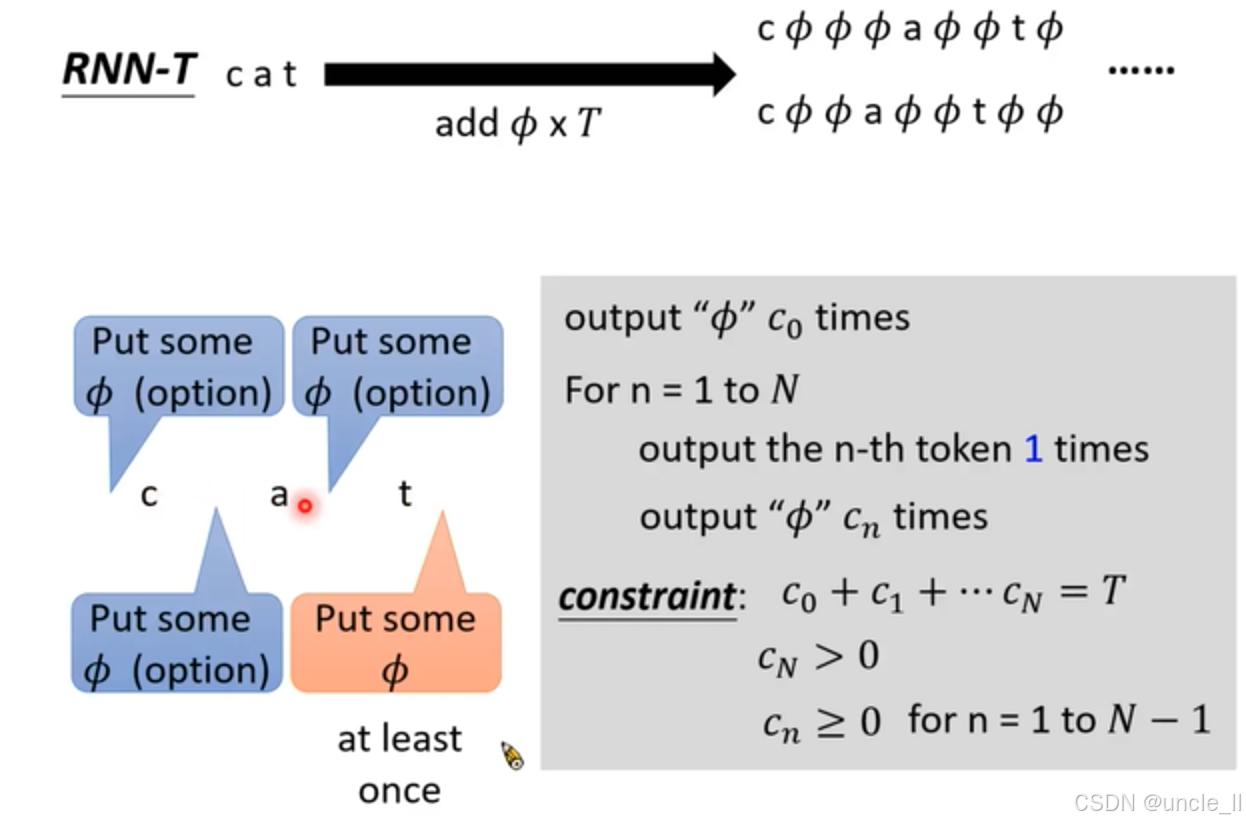
RNN - T(RNN Transducer)在語音識別中的文本處理規則:
文本擴展
- 文本擴展操作:“cat” 通過黑色粗箭頭指向右側形如 “ ? a ? t ? ? \phi a\phi t\phi \cdots ?a?t??” 的序列,箭頭下方 “add ? \phi ?x T” 說明操作是向 “cat” 中添加 ? \phi ? (空白符),且添加的總次數與參數 T T T 相關。這一操作體現了 RNN - T 在處理語音和文本對齊時,通過引入空白符來增強模型靈活性和處理能力。
- 對話框內容:圖片下方左側的藍色和橙色對話框包含了重要的規則說明。藍色對話框 “Put some ? \phi ?(option)” 表示可以選擇添加一些空白符,這給予了模型在處理過程中的一定靈活性。橙色對話框 “Put the n - th token t n t_n tn? times” 表示要將第 n n n 個 token 輸出 t n t_n tn?次,且 “at least once” 強調每個 token 至少要出現一次。
- 規則闡述:右側灰色方框內的數學相關文字進一步闡述了輸出規則和約束條件。它詳細說明了輸出 ? \phi ? 的次數規則,例如先輸出若干次 ? \phi ? ,然后依次輸出每個 token 若干次。同時,給出了嚴格的約束等式和不等式,確保生成序列的長度和字符組合符合要求,如所有字符(包括空白符)出現次數之和要滿足一定條件,每個 token 重復次數有相應的下限等。
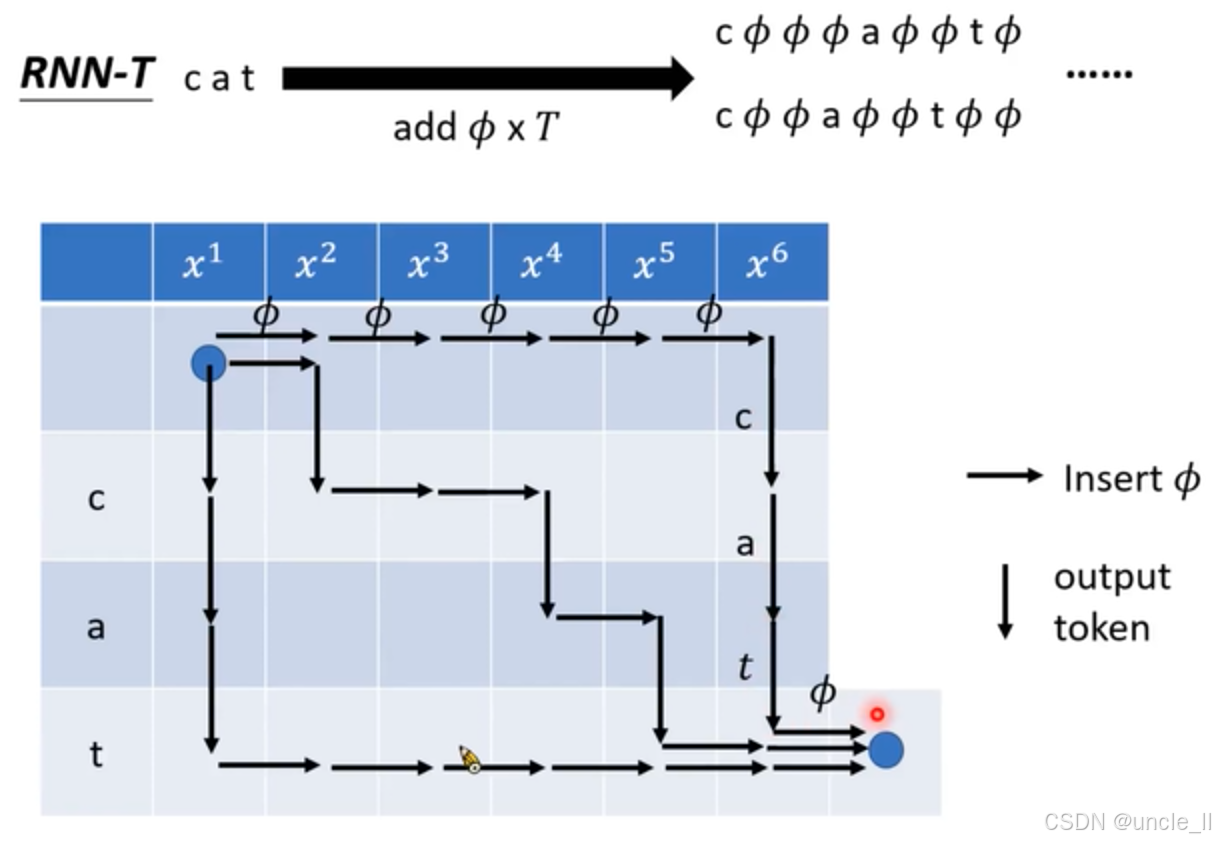
橫著走插入的是空,往下走是預測下一個token
- 核心操作:從 “cat” 出發,通過箭頭 “add ? \phi ? x T” 指向添加了多個空白符號 “ ? \phi ?” 的序列,這表明 RNN - T 在處理文本時,會向原始文本中添加一定數量的空白符,以增強模型在處理語音和文本對齊時的靈活性。
- 網格含義:網格圖由上下兩部分組成,上方藍色方格標注的 x 1 x^{1} x1 到 x 6 x^{6} x6 代表語音信號的不同時刻或特征;下方淺藍色方格中字母 “c”“a”“t” 重復排列,代表文本中的字符。
- 路徑規則:黑色箭頭表示不同的操作,“Insert ? \phi ?” 表示插入空白符,“output token” 表示輸出當前字符。路徑的起始和結束點用藍色圓點標記,清晰地展示了整個操作流程的開始和結束。
- 特殊標記:路徑中的紅色圓點標記在 “t” 處,可能是為了突出某個關鍵步驟或狀態;鉛筆圖標標記可能表示需要進一步處理或注意的節點。
總結
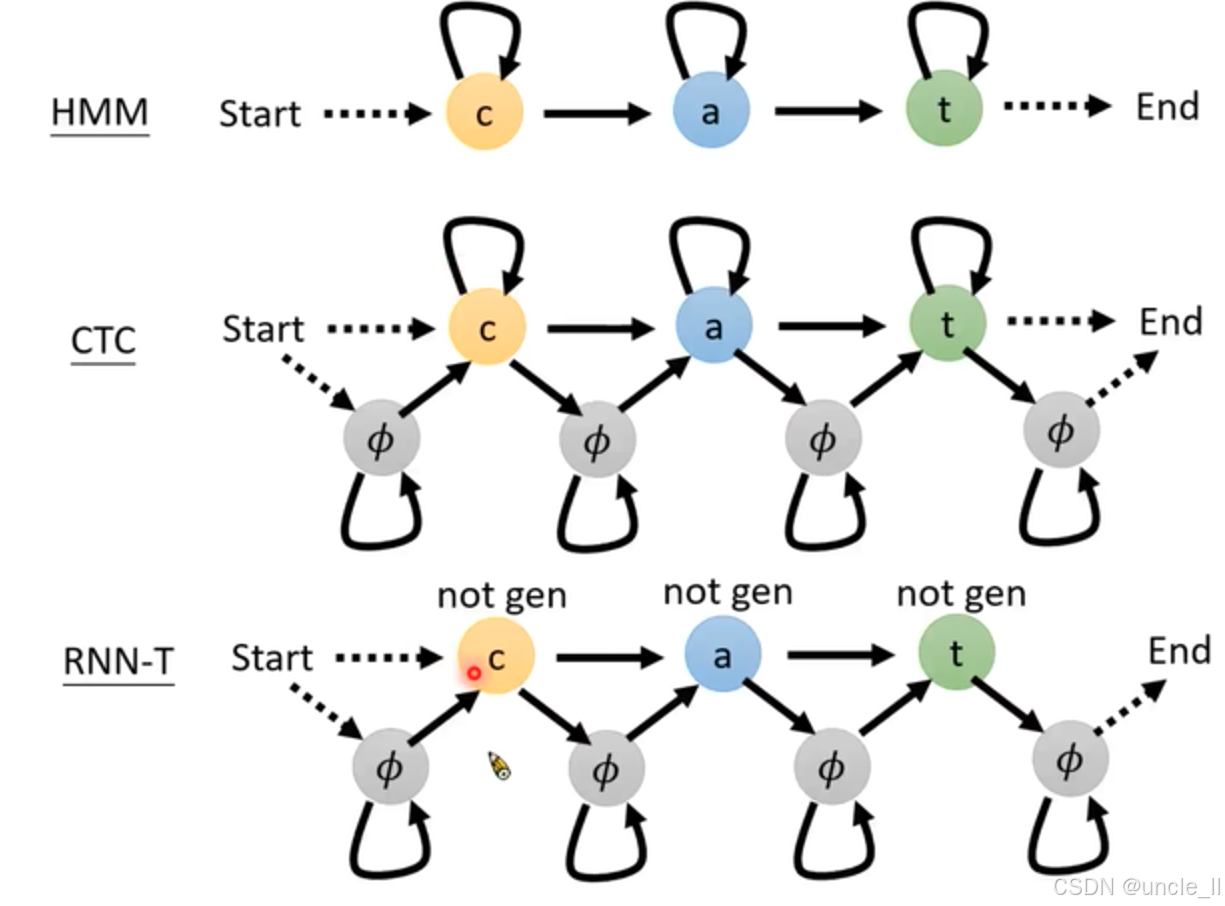
- HMM(隱馬爾可夫模型):由一系列帶有字母(如 “c”“a”“t”)的圓圈表示狀態,圓圈之間的箭頭體現了狀態轉移關系。HMM通過狀態轉移概率和發射概率來描述序列的生成過程,在語音識別中,這些狀態和轉移可能對應著語音的不同音素或發音狀態的變化。
- CTC(Connectionist Temporal Classification):同樣由帶字母和符號(如 “c”“a”“t”“( \phi )”)的圓圈和箭頭構成狀態轉移圖。CTC引入了空白符 ? \phi ?,用于處理語音和文本之間的時間不對齊問題。它允許模型在不需要預先知道語音和文本精確對齊關系的情況下進行訓練,增強了模型的靈活性。
- RNN - T(RNN Transducer):除了字母和符號的圓圈及箭頭外,部分狀態上方標注了 “not gen”,可能表示這些狀態在特定條件下不進行生成操作。RNN - T結合了循環神經網絡和變換器的特點,能夠直接對語音和文本進行聯合建模,其狀態轉移反映了模型在處理語音序列時逐步生成文本的過程。





)









)



