使用內存隊列來處理基于內存的【生產者-消費者】場景
思考和使用Disruptor
-
Disruptor可以實現單個或多個生產者生產消息,單個或多個消費者消息,且消費者之間可以存在消費消息的依賴關系
-
使用Disruptor需要結合業務特性,設計要靈活
-
什么業務場景適合使用Disruptor
-
Disruptor核心優勢在于極致的低延遲和極高吞吐量,且通信發生在單個JVM進程內部的場景
-
高頻交易系統 (HFT - High-Frequency Trading):
-
場景描述: 金融市場中的算法交易,需要在微秒甚至納秒級別對市場數據做出反應,并快速下單。延遲每降低一點,都可能帶來巨大的競爭優勢。
-
為何適合: Disruptor 最初就是為 LMAX 交易所設計的,用于處理海量的訂單和行情數據。其低延遲特性對于捕捉轉瞬即逝的交易機會至關重要。它可以用于訂單處理流水線、市場數據分發、風險控制計算等。
-
-
實時風控與反欺詐系統:
-
場景描述: 在支付、交易、登錄等關鍵操作發生時,需要實時分析用戶行為、交易模式等,快速識別潛在的風險或欺詐行為,并在毫秒級內做出決策(如阻止交易、要求額外驗證)。
-
為何適合: 需要處理高并發的事件流,并進行復雜的規則匹配和計算,同時對響應時間有極高要求。Disruptor 可以作為事件處理引擎的核心,確保快速處理和決策。
-
-
高性能日志處理框架:
-
場景描述: 應用程序產生大量日志,需要異步地、高效地將日志事件從業務線程傳遞給日志寫入線程,同時盡量減少對業務線程性能的影響。
-
為何適合: Log4j2 的 Async Loggers 就是基于 Disruptor 實現的。它可以顯著降低日志記錄操作對應用主線程的阻塞時間,提高應用的整體吞吐量。
-
-
游戲服務器事件處理:
-
場景描述: 大型多人在線游戲(MMO)服務器需要處理來自成千上萬玩家的并發操作(移動、攻擊、聊天等),并實時更新游戲世界狀態,廣播給其他相關玩家。
-
為何適合: 游戲服務器對延遲非常敏感,任何卡頓都會嚴重影響玩家體驗。Disruptor 可以用來構建高效的事件處理循環,快速響應玩家輸入并分發狀態更新。
-
-
實時數據分析與復雜事件處理 (CEP - Complex Event Processing):
-
場景描述: 從各種數據源(如傳感器、網絡流量、用戶行為日志)接收高速數據流,實時識別特定模式、趨勢或異常,并觸發相應動作。
-
為何適合: 需要在大量數據涌入時,以極低的延遲進行匹配和分析。Disruptor 可以作為CEP引擎內部事件排隊和分發的骨干。
-
-
網絡數據包處理/高性能網絡應用:
-
場景描述: 構建需要處理大量并發連接和高速網絡數據包的服務器應用,如自定義的應用層網關、高性能代理服務器等。
-
為何適合: 當網絡 I/O 線程接收到數據包后,需要快速地將這些數據包(或解析后的事件)分發給工作線程進行處理。Disruptor 可以作為 I/O 線程和業務邏輯處理線程之間的高效橋梁。
-
-
任務調度與并行計算的內部協調:
-
場景描述: 在一個復雜的計算任務中,可以將任務分解為多個階段,由不同的線程組處理。階段之間的數據傳遞需要高效且低延遲。
-
為何適合: 如果這些階段都在同一個JVM內部,并且對性能要求極高,Disruptor 可以作為這些并行處理單元之間的數據交換通道,避免傳統隊列的鎖競爭開銷。
-
-
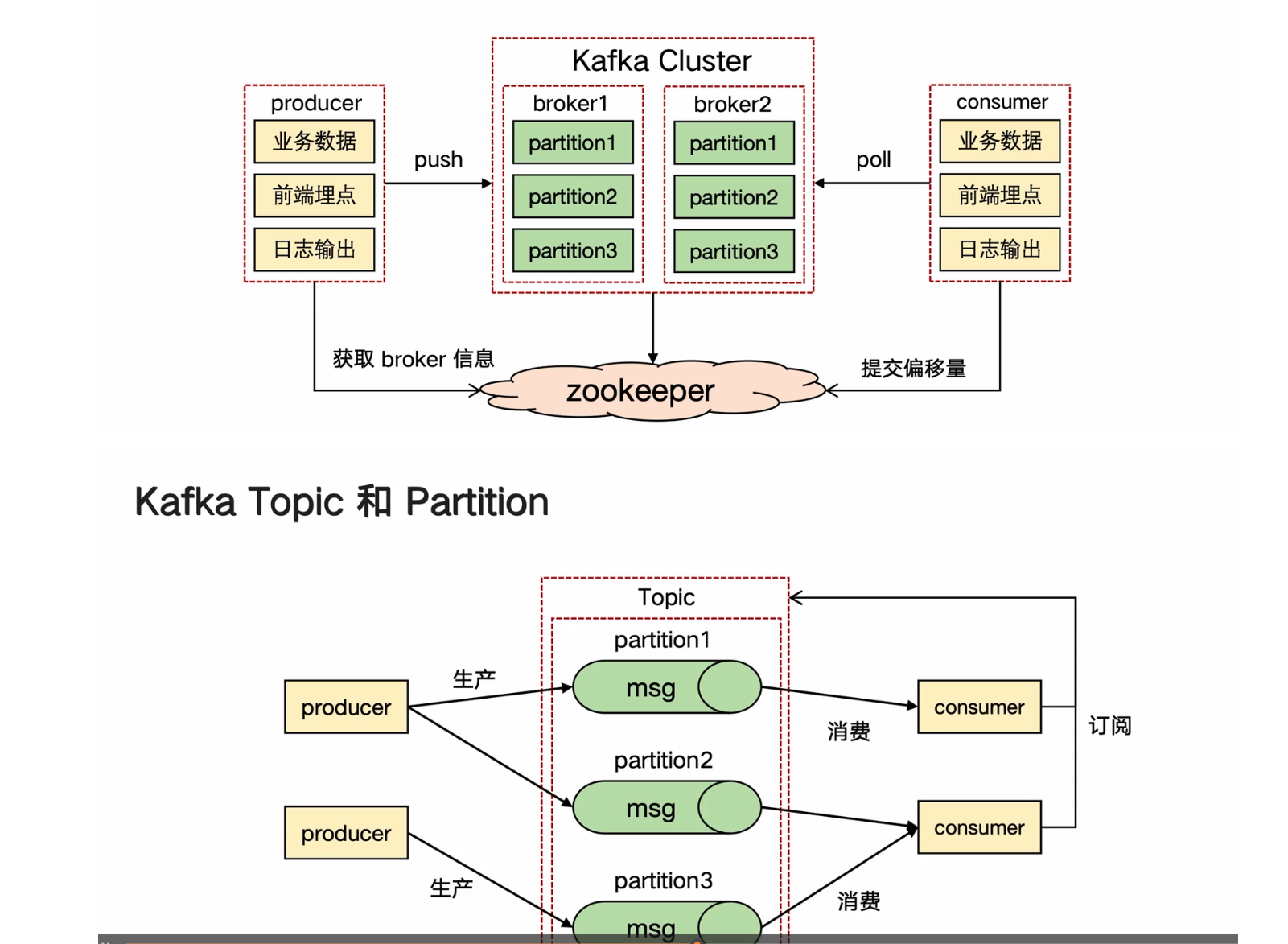
Kafka
消息隊列的設計意圖
當消費不均衡(生產者生產的過快或消費者消費的過快)時,就在生產者和消費者中間加一個緩沖層,這個緩沖層就是消息隊列
消息隊列是分布式系統中的重要組件
消息隊列的作用
-
異步:提升吞吐量
-
解耦:減少依賴,生產者和消費者之間沒有直接的依賴,一個系統的故障不會影響另一個系統,保證系統的穩定性和健壯性
-
削峰填谷:消除短時負載過高
-
削峰:生產者的速度非常的高,并發流量非常的大,此時可以增加消費者線程,提高并發處理能力,來達到生產和消費的平衡
-
填谷:生產的頻率降低,流量變小,此時可以減少一些消費者線程,來達到生產和消費的平衡
-
-
順序性保證
-
可靠性保證:數據持久化
從整體的角度來看Kafka
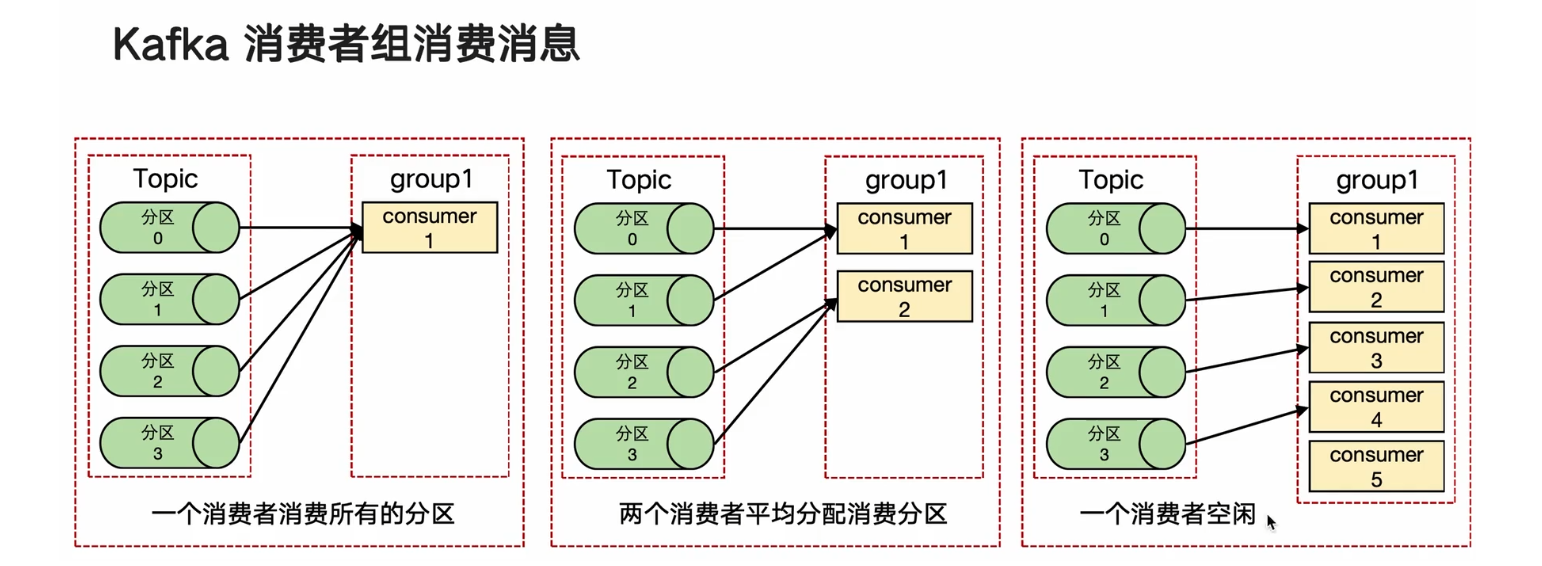
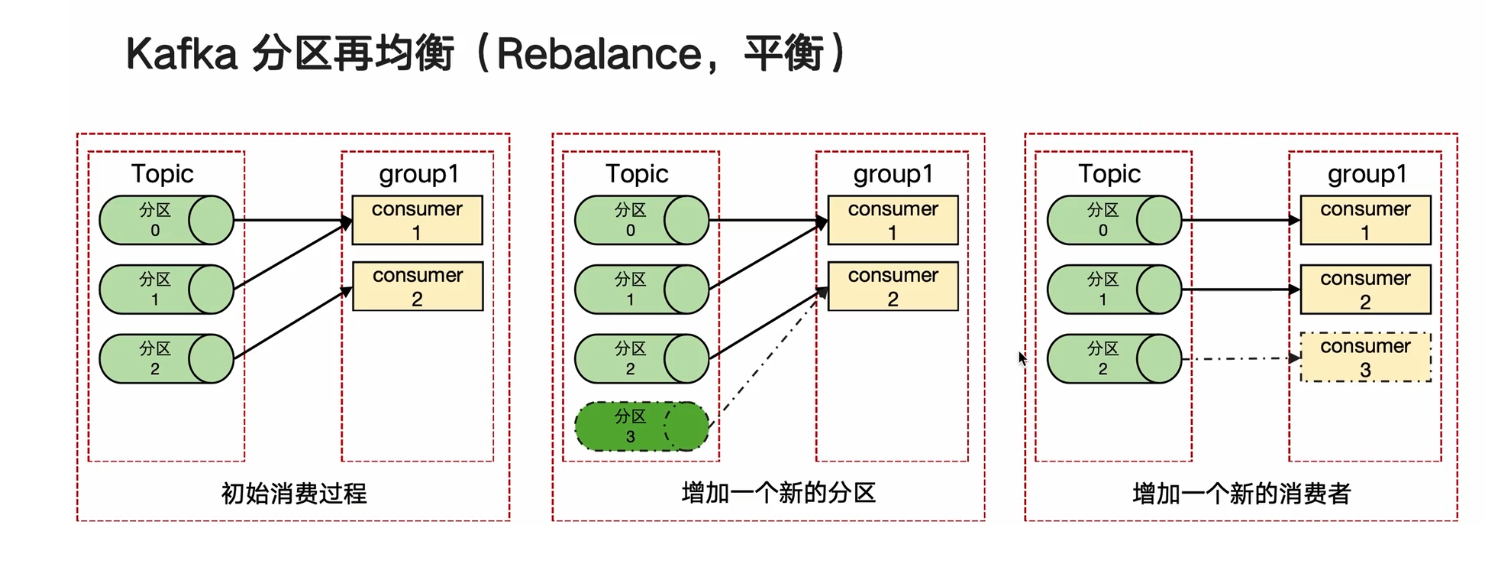
Kafka分區再均衡(Rebalance, 平衡)
Kafka數據存儲
-
日志文件消息格式

消息丟失和重復消費
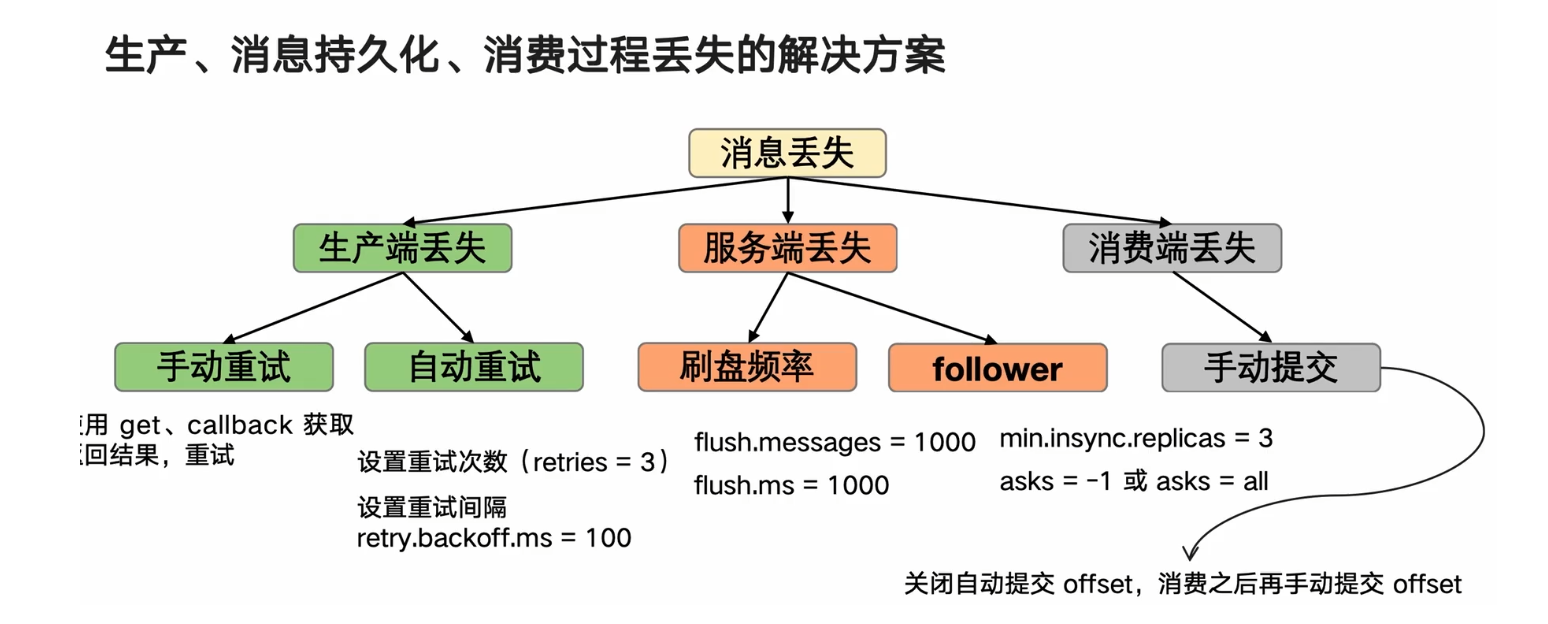
Kafka消息丟失
從Kafka生產,消息持久化,消費過程看消息丟失
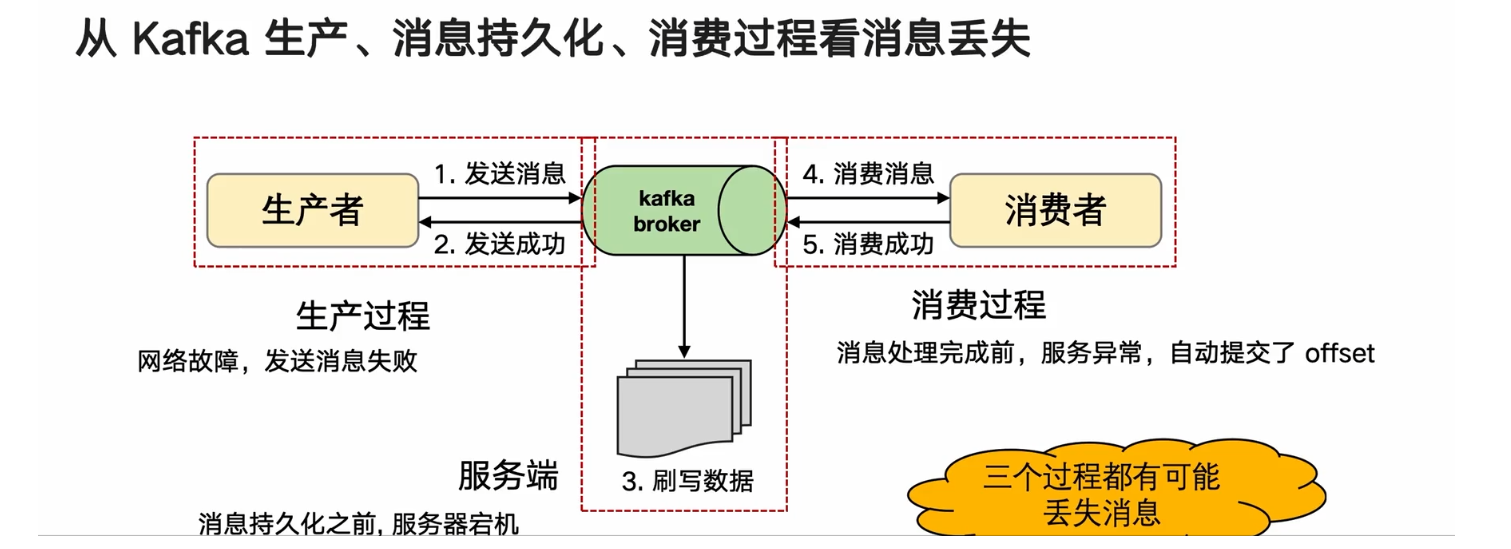
生產,消息持久化,消費過程丟失的解決方案
Kafka重復消費
-
重復消費的根本原因在于:已經消費了數據,但是offset沒有成功提交,很大一部分原因是再均衡
-
消費者宕機,重啟,消費了消息但是沒有提交offset
-
還沒有提交offset時,發生了rebalance
-
消息處理耗時太大,超過了(max.poll.interval.ms),發生了rebalance
-
-
重復消費的解決方案
-
最根本的解決方案是消費消息保證冪等性
-
記錄消息表,使用唯一索引
-
緩存消費過的消息id(位圖)
-
-
使用好Kafka
集成使用Kafka
常見的兩種方法使用Kafka
-
使用@KafkaListener把消費過程(poll和提交offset)交給框架
-
自己管理消息的拉取(poll)和消息偏移量(offset)的提交
生產者發送消息有三種方式
-
發送之后什么都不管
-
同步發送
-
異步發送
消費者消費消息
-
消費者主動拉取消息消費
-
通過注解實現消息的監聽消費(@KafkaListener)
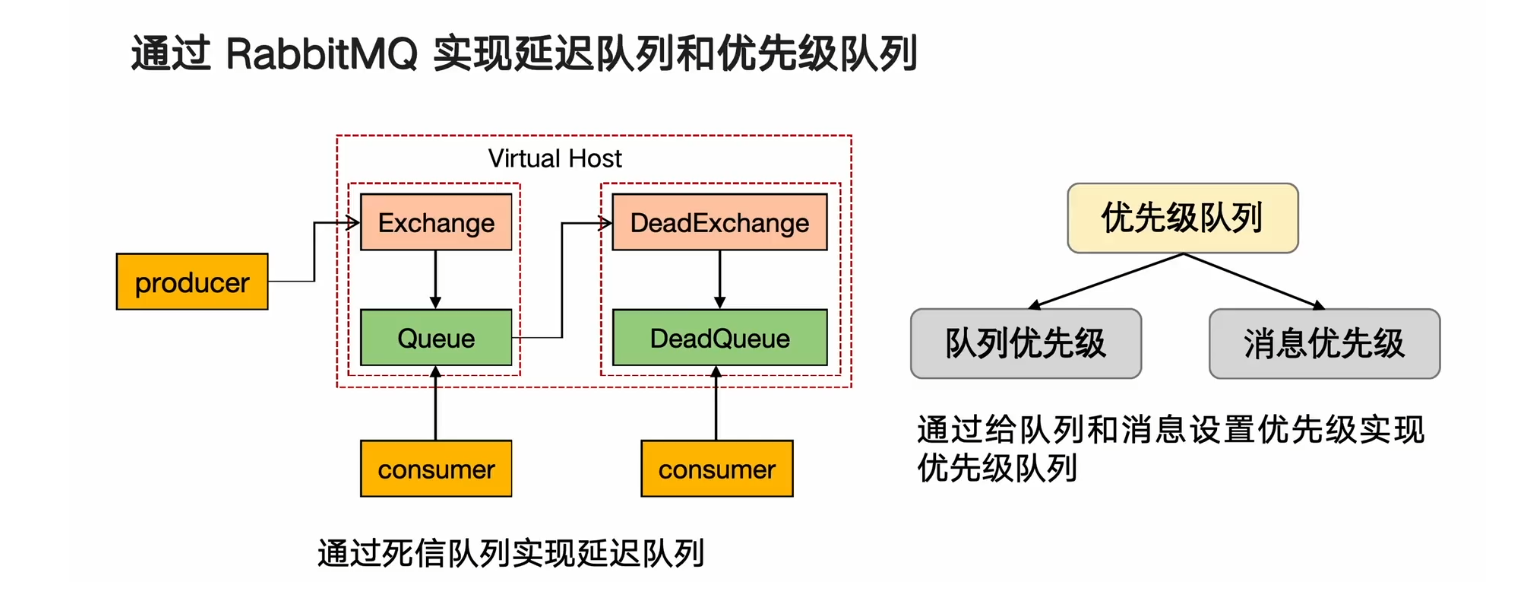
延遲隊列和優先級隊列
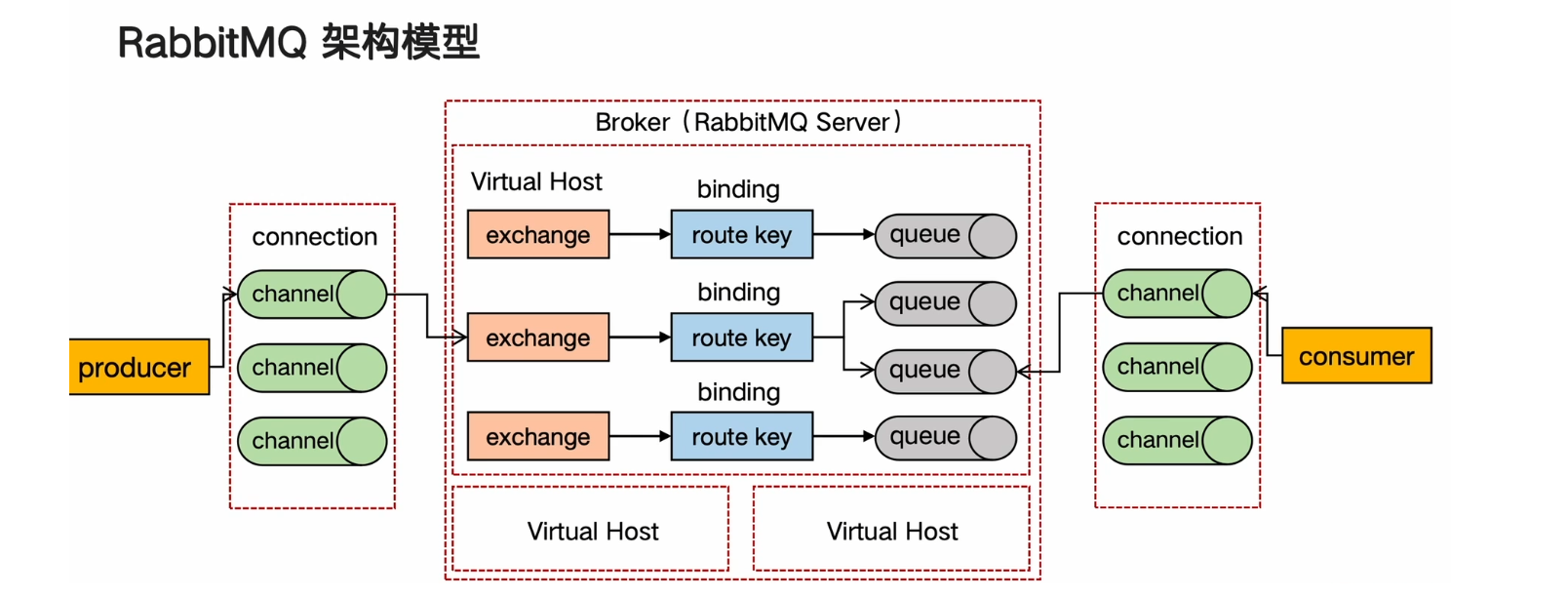
RabbitMQ架構模型
通過RabbitMQ實現延遲隊列和優先級隊列
死信隊列:
死信:如果隊列中消息出現以下兩種情況,則消息變為死信狀態
-
如果消息在隊列中的時間超過了我設置的ttl(過期時間)
-
消息隊列的消息數量超過了最大的隊列長度
優先級隊列:最大值是255,最小值是0,值越大,優先級越高



SVIn2聲吶模塊分析)




![[特殊字符] 使用增量同步+MQ機制將用戶數據同步到Elasticsearch](http://pic.xiahunao.cn/[特殊字符] 使用增量同步+MQ機制將用戶數據同步到Elasticsearch)










