
????????這篇論文提出了 AnomalyGPT,一個基于大型視覺語言模型的工業異常檢測框架,首次將通用多模態對話能力引入工業視覺場景,通過引入圖像解碼器增強像素級感知,設計 Prompt 學習器實現任務自適應控制,并利用合成異常樣本解決異常數據稀缺問題,最終實現了無閾值、無額外后處理的異常檢測、定位與自然語言解釋一體化能力。
目錄
論文標題
核心問題:
創新方法:
論文講解:
局限分析:
兩個問題與回答
AnomalyGPT的實現原理
組件作用與配合關系說明
1. 總體架構概覽
2. 模塊詳解
(1)圖像編碼器(CLIP Vision Encoder)
(2)圖像解碼器(Image Decoder)
(3)Prompt Learner 模塊
(4)異常數據生成器(Synthetic Anomaly Generator)
3. 訓練任務設計
?任務1:圖像-文本匹配(ITM)
?任務2:異常分類任務(Anomaly Classification)
?任務3:異常定位任務(Anomaly Localization)
4. 推理過程(Inference Pipeline)
5. 核心優勢總結
名詞解釋
【1】大型視覺語言模型 LLaVA-1.5
LLaVA-1.5的核心組成部分
主要改進點
【2】IAD任務
IAD任務的關鍵要素
IAD當前存在的問題
【3】U-Net的解碼結構
解碼器(Decoder)結構
?
論文標題
AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models
AnomalyGPT:使用大型視覺語言模型檢測工業異常
核心問題:
????????本論文聚焦于工業異常檢測(Industrial Anomaly Detection, IAD)中的兩大難點:其一,當前主流的IAD方法僅提供異常分數,需手動設定閾值區分異常與正常樣本,限制其在實際工業場景中的實用性;其二,盡管大型視覺語言模型(Large Vision-Language Models, LVLMs)如MiniGPT-4和LLaVA在通用視覺理解任務中表現優異,但其對工業領域缺乏專業知識,且對物體局部細節理解能力較弱,無法有效檢測微小但關鍵的工業缺陷。論文提出的核心問題正是如何借助LVLM提升工業異常檢測的智能化和實用性。
創新方法:
????????作者提出了一種新穎的基于大型視覺語言模型的異常檢測框架——AnomalyGPT,其主要創新包括:
-
異常數據生成機制:通過模擬生成異常圖像并配套生成文本描述,構建多模態訓練數據,增強LVLM對工業異常概念的理解;
-
圖像解碼器集成:引入圖像解碼模塊以獲取圖像中細粒度的語義信息,提升模型的細節理解能力;
-
Prompt學習機制:設計專用Prompt Learner模塊,通過Prompt嵌入方式對LVLM進行微調,賦予其異常判斷能力;
-
端到端判斷能力:該方法無需閾值設定,可直接做出異常與否及其定位判斷,顯著提升實用性;
-
多輪對話與小樣本學習:具備對異常原因的多輪對話分析能力,以及顯著的in-context few-shot學習能力,僅需一個正常樣本即可達成SOTA性能。
? ? ? ? 該方法依賴于預訓練的大型視覺語言模型 LLaVA-1.5【1】,通過Prompt嵌入與圖像解碼模塊增強其工業異常判斷能力,適配專業領域需求。
論文講解:
-
問題背景與挑戰界定(第1節):
作者指出IAD任務【2】普遍面臨異常樣本稀缺、細節變化微小、模型依賴閾值設定等問題,并指出LVLM盡管具備強大的跨模態理解能力,但對細節敏感度不足,不適用于IAD任務。引出本文欲將LVLM適配至工業檢測場景的動機。 -
AnomalyGPT框架設計(第3節):
整個系統包括四個關鍵模塊:圖像預編碼器、圖像解碼器、Prompt Learner以及LVLM主體。訓練數據由正常樣本生成,通過仿真方式制作異常圖并配對文本描述,增強模型多模態理解能力。Prompt Learner負責根據不同任務學習任務嵌入,以增強模型的上下文推理能力。 -
數據與任務構建(第4節):
為解決真實異常樣本稀缺的問題,作者設計了一個模擬生成數據集機制,能夠在無異常樣本的前提下構建有效的訓練樣本。此外,還設計了三種任務:圖像-文本匹配、異常分類與異常定位,用于全面訓練模型的判斷與解釋能力。 -
實驗與結果分析(第5節):
在MVTec-AD數據集上,AnomalyGPT取得 圖像級AUC 94.1%、像素級AUC 95.3% 的成績,超越現有方法。尤其值得注意的是,AnomalyGPT僅需一個正常樣本就能在few-shot設定下達到SOTA性能,并支持多輪對話能力。表1系統對比了不同方法在異常得分、定位、判斷與交互方面的能力,突顯AnomalyGPT的全面性。
局限分析:
-
計算成本:AnomalyGPT基于大型預訓練視覺語言模型(如MiniGPT-4),其推理與訓練階段均具有較高計算開銷,特別是在多輪對話與圖像細節解碼部分,部署在資源受限設備上具有挑戰;
-
領域泛化能力:盡管通過模擬生成異常圖像與文本增強了泛化能力,但該策略在面對高度復雜或未知類別異常時仍可能出現識別盲區;
-
數據需求與依賴:該方法雖不依賴真實異常樣本,但其構造的訓練數據仍需依賴精確的仿真圖像生成與文本描述構造,對數據生成質量存在一定要求;
-
對LVLM的依賴:方法核心依賴于預訓練LVLM的通用視覺理解能力,其在特定工業子領域若存在圖像分布偏差,則可能面臨性能下降問題。
兩個問題與回答
? Why型:為什么該方法比傳統方案更優?
????????AnomalyGPT摒棄了傳統IAD方法對異常分數與手動閾值設定的依賴,轉而直接基于自然語言生成與多模態對齊進行異常識別和定位,不僅提升了判斷的自動化程度,還通過Prompt調控支持個性化任務定義。同時,其few-shot學習能力在極低樣本條件下也能達到SOTA性能,極大拓展了方法的適用場景。
? How型:如何將該方法擴展到其他場景?
????????AnomalyGPT的框架具有高度的通用性,可以通過重構仿真圖像與文本描述體系,遷移到如醫療影像異常識別(如腫瘤檢測)、交通異常監控(如事故檢測)、航天產品檢測等其他異常檢測任務中。同時其多輪對話能力也可用于制造環節的人機協作、缺陷原因解釋等智能交互場景。
AnomalyGPT的實現原理
下圖來自論文原文。
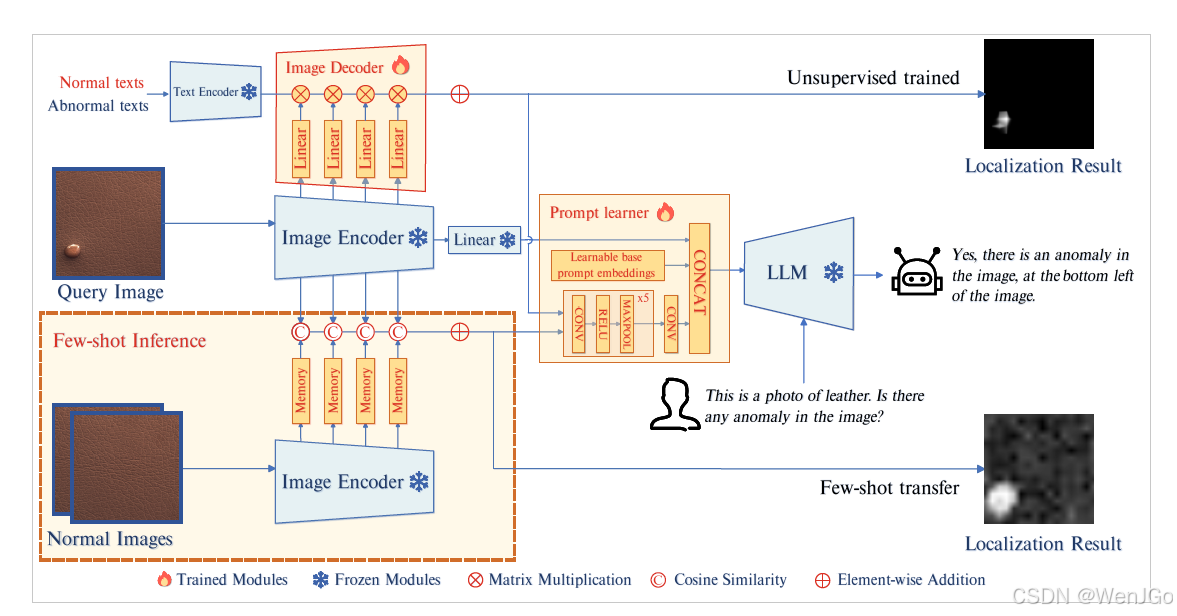
????????AnomalyGPT的架構。查詢圖像被傳遞給凍結的圖像編碼器,從中間層提取的塊級特征被輸入到圖像解碼器中以計算它們與正常和異常文本的相似度,從而獲得定位結果。由圖像編碼器提取的最終特征通過線性層處理后,連同定位結果一起傳遞給提示學習器。提示學習器將它們轉換成適合與用戶文本輸入一起輸入到大型語言模型(LLM)中的提示嵌入。在少樣本設置下,正常樣本的塊級特征存儲在記憶庫中,定位結果可以通過計算查詢塊與其在記憶庫中最相似的對應塊之間的距離來獲得。?
????????文字結構描述。
【AnomalyGPT】
? ?↓
【Image Encoder】→ 提取圖像特征 ?
? ?↓ ?
【Prompt Learner】←→【Task Queries】←【Image Decoder】
? ?↓ ? ? ? ? ? ? ? ? ? ? ↓
【Prompt】 ? ? ? ? 【Fine-grained Features】 ?
? ?↓ ? ? ? ? ? ? ? ? ? ? ↓ ?
? ? ? ? ?←←←←←←【融合】→→→→→ ?
? ? ? ? ? ? ? ? ? ?↓
? ? ? ? ? ? ? ? 【Output】
?
組件作用與配合關系說明
-
Image Encoder(圖像編碼器)
-
作用:將輸入的工業圖像編碼為視覺特征表示。
-
輸出:為 Prompt Learner 提供基礎視覺特征。
-
-
Prompt Learner(提示詞學習器)
-
作用:根據圖像編碼器的輸出,學習任務相關的 Prompt(任務描述/控制信號)。
-
配合:
-
接收 Image Encoder 輸出;
-
將學習到的 Prompt 與 Decoder 側的 Task Queries 對齊;
-
將 Prompt 輸出給后續模塊用于融合生成最終預測。
-
-
-
Image Decoder(圖像解碼器)
-
作用:用于圖像重建,捕捉圖像中更細粒度的特征。
-
配合:
-
解碼圖像以生成用于下游任務的 Query(任務查詢);
-
這些查詢進一步輸入 Task Queries 模塊。
-
-
-
Task Queries(任務查詢)
-
作用:將圖像解碼結果組織成任務特定的查詢(例如檢測、定位等)。
-
配合:
-
接收來自 Image Decoder 的解碼結果;
-
與 Prompt Learner 對齊,結合生成 Prompt 所需的任務理解。
-
-
-
Fine-grained Features(細粒度特征)
-
作用:由任務查詢進一步提取的關鍵特征,用于判斷圖像中是否存在異常區域。
-
輸出:與 Prompt 一起融合,構成最終模型決策依據。
-
-
Prompt(提示)
-
作用:作為語言形式的提示,控制模型的任務行為(如是否檢測、是否定位)。
-
來源:由 Prompt Learner 生成。
-
-
Output(最終輸出)
-
作用:融合 Prompt 與 Fine-grained Features 的信息,生成包括:
-
異常檢測結果;
-
異常區域定位;
-
自然語言描述(多模態輸出)。
-
-
1. 總體架構概覽
????????AnomalyGPT 是一個基于大型視覺語言模型(LLaVA-1.5)構建的工業異常檢測系統,其整體目標是實現:
-
圖像級異常判斷(是否異常)
-
像素級異常定位(哪里異常)
-
異常原因描述(為什么異常)
-
多輪問答分析能力(與用戶交互式追問)
為達成上述目標,AnomalyGPT 在 LLaVA 的基礎上,加入了三大關鍵模塊:
-
圖像解碼器(Image Decoder)
-
Prompt學習模塊(Prompt Learner)
-
異常生成數據機制(Synthetic Anomaly Generator)
并圍繞這些模塊設計了三類任務,使模型能夠完成從檢測、定位到交互解釋的全過程。
2. 模塊詳解
(1)圖像編碼器(CLIP Vision Encoder)
-
輸入:工業圖像(正常或模擬異常圖像)
-
輸出:圖像的高層視覺特征
-
模型結構:使用 CLIP 的視覺編碼器(如 ViT-L/14)作為圖像特征提取主干
-
作用:為 LLaVA 模型提供圖像語義表示輸入
注意:此部分與標準 LLaVA 保持一致,是其視覺感知部分。
(2)圖像解碼器(Image Decoder)
-
目的:補強 LLaVA 在小尺度、細粒度異常上的感知能力
-
結構:加入一個輕量的 UNet 解碼結構【3】,對 CLIP 提取的中間圖層特征進行上采樣
-
輸出:像素級特征圖,用于異常定位任務
-
用法:特征圖可視化后與異常熱圖對齊,用于訓練中的定位監督或推理時可解釋性輸出
(3)Prompt Learner 模塊
-
功能:為不同任務動態生成文字 Prompt 向量,引導 LLaVA 正確理解任務
-
形式:
-
對每個任務(如判斷異常、定位異常、問原因)學習一個 Prompt 向量嵌入
-
該 Prompt 與文本輸入拼接,作為 LLM 的初始上下文
-
-
目的:讓模型具備“條件理解能力”,不同 Prompt 引導不同任務模式
例如:
Prompt 1:這個圖像中是否存在異常?
Prompt 2:異常出現在哪個位置?
Prompt 3:是什么導致了異常?
(4)異常數據生成器(Synthetic Anomaly Generator)
-
問題:真實工業異常樣本極度稀缺
-
解決方案:從僅有的正常樣本中自動構造異常數據(圖像+描述文本)
-
方法:
-
在正常圖像中加入擾動/偽造異常區域(如局部顏色變化、缺陷模擬)
-
同時生成對應的異常描述文本,如“圖像左下角存在劃痕”
-
-
用途:
-
構造訓練樣本(圖像 + 文本)
-
提高模型對異常的對齊理解能力
-
3. 訓練任務設計
論文中引入了三個訓練任務,用于全面訓練模型的不同能力:
?任務1:圖像-文本匹配(ITM)
-
目標:判斷圖像和文本描述是否匹配(是否為異常)
-
監督信號:二分類標簽(匹配 / 不匹配)
?任務2:異常分類任務(Anomaly Classification)
-
目標:多分類判斷異常類型(如劃痕、斷裂、污染等)
-
監督信號:異常類別標簽
?任務3:異常定位任務(Anomaly Localization)
-
目標:輸出異常的像素位置(分割圖)
-
監督信號:異常熱圖(通過偽標簽或圖像解碼器監督)
這三類任務共同訓練,使模型具備“判斷 + 解釋 + 定位”全鏈能力。
4. 推理過程(Inference Pipeline)
推理階段使用標準的多輪對話形式實現以下功能:
輸入:工業圖像(無標簽)流程: 1. 用戶輸入問題(或系統自動觸發):"這張圖像有沒有異常?" 2. 模型根據 Prompt + 圖像特征回答:有/沒有 3. 若有異常,用戶繼續追問:"異常在哪里?",模型輸出熱圖或文字定位 4. 用戶進一步追問:"為什么出現這個異常?",模型基于上下文輸出可能原因描述
整個過程無需閾值,無需手工后處理,支持交互式可解釋分析。
5. 核心優勢總結
| 能力 | 實現方式 | 優勢 |
|---|---|---|
| 圖像判斷 | ITM + Prompt | 無需閾值,直接 Yes/No |
| 像素定位 | 解碼器 + 熱圖訓練 | 可視化區域定位 |
| 原因解釋 | 多輪VQA | 增強可解釋性 |
| 小樣本學習 | In-context Few-shot | 僅需1張正常圖即可工作 |
?
名詞解釋
【1】大型視覺語言模型 LLaVA-1.5
????????LLaVA-1.5(Large Language-and-Vision Assistant 1.5)是一個多模態的大型預訓練模型,由微軟研究院、威斯康星大學麥迪遜分校以及哥倫比亞大學的研究人員共同開發。它是在LLaVA的基礎上進行改進和發展而來的一個版本,旨在提升多模態理解和生成能力。
LLaVA-1.5的核心組成部分
-
視覺模型:使用了在大規模數據上預先訓練好的CLIP ViT-L/336px視覺模型,用于提取圖像的特征表示。這使得模型能夠理解并處理圖像內容。
-
大語言模型:采用了擁有130億參數的Vicuna v1.5作為語言模型部分,負責理解用戶輸入的文本內容,并具備強大的推理和生成能力。
-
視覺語言連接器:采用了一個雙層的MLP(多層感知機)連接器來替代之前的線性投影,這樣可以更有效地將視覺編碼器輸出的圖像特征映射到大語言模型的詞向量空間中,從而實現跨模態的信息融合。
主要改進點
- MLP cross-modal connector:增強了視覺與語言之間的信息傳遞效率。
- 結合學術相關的任務數據集:例如VQA(視覺問答),以增強模型在特定任務上的表現。
- 響應格式提示優化:解決了短文本回答與長文本回答之間的兼容問題,提高了指令跟隨的表現。
【2】IAD任務
????????IAD任務,即工業異常檢測(Industrial Anomaly Detection),是指在工業環境中識別產品或生產過程中出現的異常情況的任務。這種異常可能包括但不限于表面缺陷、結構損傷、功能失效等。IAD的目標是通過自動化的方法及時發現這些異常,以確保產品質量,提高生產效率,并減少因故障導致的成本和風險。
IAD任務的關鍵要素
-
數據收集:通常涉及到從生產線上的傳感器、攝像頭或其他監測設備中收集大量數據。這些數據可以是圖像、視頻流、聲學信號、溫度讀數等多種形式。
-
特征提取與選擇:從原始數據中提取有用的特征,以便后續分析使用。這一步驟對于區分正常與異常樣本至關重要。例如,在圖像處理中,可能會提取邊緣、紋理或者顏色信息作為特征。
-
模型訓練:利用歷史數據集來訓練模型,使其能夠學習到正常狀態下的模式以及如何區分異常。常用的模型包括傳統的機器學習算法如支持向量機(SVM)、隨機森林(RF),以及深度學習方法如卷積神經網絡(CNN)。
-
異常檢測:基于訓練好的模型對新數據進行實時監控,判斷是否存在異常。常見的做法是為每個樣本計算一個異常分數,如果分數超過預設閾值,則認為該樣本存在異常。
-
結果解釋與可視化:為了便于理解和采取行動,還需要將檢測結果以直觀的方式呈現出來,比如標注出圖像中的具體異常位置,給出詳細的描述等。
-
反饋機制:建立有效的反饋回路,讓系統能夠根據實際操作中的反饋不斷改進自身的性能。
IAD當前存在的問題
- 復雜性與多樣性:工業環境中的異常種類繁多且形態各異,增加了準確檢測的難度。
- 數據不平衡問題:正常樣本往往遠多于異常樣本,這對訓練模型提出了額外的要求(個人認為最難攻克的問題,當前看了十多篇論文,一半是在這里下功夫)。
- 實時性要求高:特別是在高速流水線作業中,需要快速響應以避免大規模損失。
- 成本控制:既要保證高精度,又要考慮部署成本,尋找性價比最優的解決方案。
【3】U-Net的解碼結構
????????U-Net的解碼結構與編碼結構對稱,用于逐步恢復特征圖的空間分辨率,同時結合來自編碼器的高分辨率特征信息來生成精確的分割結果。
解碼器(Decoder)結構
-
上采樣層(Upsampling Layer):
- 在每個解碼階段開始時,通過轉置卷積(也稱為反卷積或deconvolution)或最近鄰插值等方法進行上采樣操作,將特征圖的尺寸翻倍。
- 上采樣的目的是逐漸恢復原始輸入圖像的空間分辨率。
-
跳躍連接(Skip Connections):
- U-Net的一個關鍵創新就是引入了跳躍連接,這些連接將編碼器中對應層級的特征圖直接傳遞給解碼器中的相應層級。
- 這些連接允許解碼器利用編碼器中保留的高分辨率細節信息,從而有助于提高分割精度,特別是在邊界區域。
-
特征拼接(Concatenation of Features):
- 上采樣后的特征圖會與編碼器中對應層的特征圖在通道維度上進行拼接(而不是相加),這增加了特征的豐富性,并幫助模型更好地定位目標對象。
- 拼接后的特征圖包含了更豐富的空間信息,有助于細化分割結果。
-
雙卷積層(Double Convolution Layers):
- 在完成特征拼接后,通常會應用兩個連續的3x3卷積層(每次卷積后跟一個ReLU激活函數),進一步處理和提取組合后的特征圖的信息。
- 這些卷積層有助于捕捉更高層次的語義信息,并減少可能的偽影(artifacts)。
-
輸出層(Output Layer):
- 最終,在解碼器的最后一層,使用1x1卷積層將特征圖映射到所需的類別數目的通道數,以得到最終的分割掩碼。
- 根據任務的不同,可以使用Sigmoid激活函數(對于二分類問題)或者Softmax激活函數(對于多分類問題)來獲得每個像素點屬于各個類別的概率分布。
?
?





--- SpringBoot基礎(http協議、分層解耦))









Java集合框架深度解析:從基礎到高級應用)



