最近在看有關webpack分包的知識,搜索了很多資料,感覺這一塊很是迷惑,網上的資料講的也迷迷糊糊,這里簡單總結分享一下,也當個筆記。 如有錯誤請指出。
為什么需要分包
我們知道,webpack的作用,是將各種類型的資源,統一轉換成瀏覽器可以直接識別的 Js Css Html 圖片 等等,正如其官網圖描述的一樣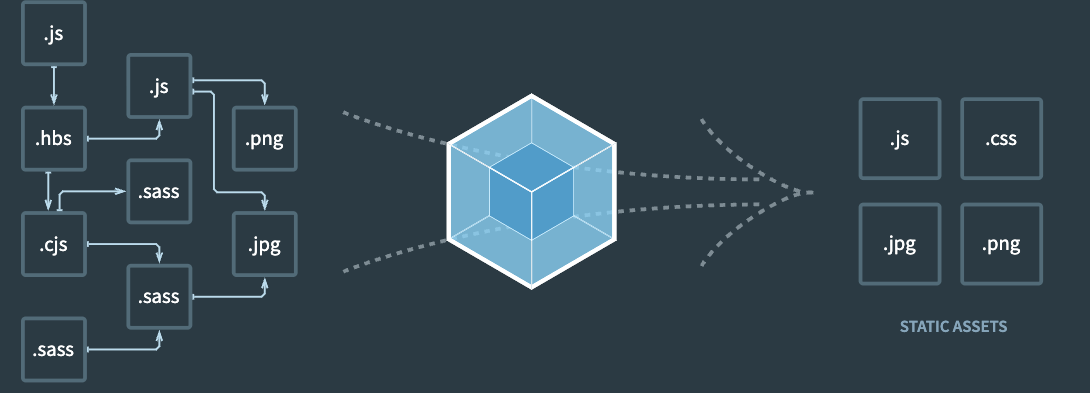
在這個過程中,webpack需要兼容各種模塊化標準 (CommonJs & ESModule),將各種模塊化標準實現的各個模塊,統一打包成一個bundle.js文件,這個文件可以直接被script標簽引用, 被瀏覽器直接識別。
?如果你了解webpack的實現原理,就可以知道,其打包結果本質上是一個自執行函數。 各個模塊被封裝成一個 路徑 => 代碼 的Map,通過入參傳入。 自執行函數內部,有一套邏輯可以讀取,執行這些模塊代碼,并且兼容統一了各種模塊化標準。
說了這么多,webpack給我們的印象是一個 多 歸 一 的構建工具,無論我們有多少的模塊,最后輸出的結果只有bundle.js一個。這就帶來一個問題,如果我們的模塊體積很大,其中可能還包含了圖片等信息,那么從服務端將其下載到本地就需要很大的開銷,可能導致用戶瀏覽器出現長時間白屏的現象。我們需要將邏輯上一個大的bundle.js拆散,根據用戶的需求,動態的下載,保證用戶的體驗。
完成這個拆分工作,就需要用到分包相關的技術。
分包的工作,通常由SplitChunksPlugin完成,其是webpack內部提供的一個插件,我們不需要額外的從NPM上下載這個插件,只需要在 optimization中配置splitChunks屬性即可。
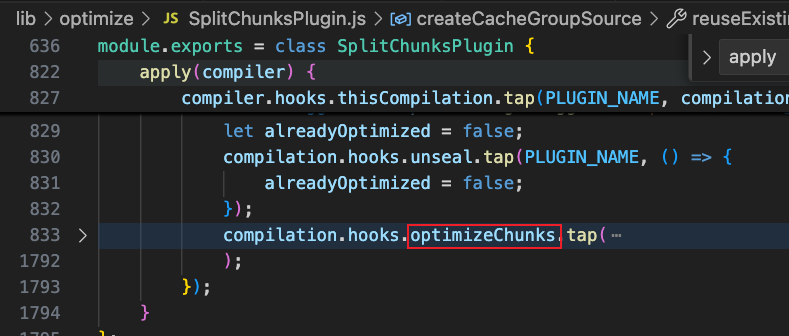
我們可以看到,SplitChunksPlugin是在optimize階段通過鉤入 optimizeChunks鉤子實現分包的
chunks屬性
很多介紹splitchunks的文章都是從 chunks開始介紹的,說這個屬性有三個值
?async(默認)| initial | all?
分別對應,拆分異步模塊,拆分同步模塊,拆分同步和異步模塊
由于默認值是 async 所以通過 import() 動態導入的模塊會被單獨拆分!
現象如此,但是這個理解完全是錯誤的!
webpack默認行為
首先你需要知道,webpack對異步模塊的拆分是webpack的默認行為,和splitChunks無關。
?我們很容易驗證,設置splitChunk: false 關閉拆包,對于如下例子:
webpack.config.js// 單一入口entry: {main: "./src/main.js",},main.js
// 通過 import動態導入add模塊
import("@utils/add").then((module) => {console.log(module.add(100, 200));
});add.js
// 導出一個簡單的 add 函數
export function add(x,y){return x + y
}入口main.js動態引入了一個 add函數,由于關閉了拆包優化,最后應該只有一個js文件被輸出,但是最終的結果為:

可以觀察到,無論開不開分包優化,webpack對于異步導入的模塊,都會將其單獨作為一個chunk拆分出去,這樣也確保了請求資源的時候不把異步模塊同主模塊一同加載進來,這個是默認行為
add.js
import './commonUtils'
export function add(x,y){return x + y
}我們改動一下,在add.js中同步引入 commonUtils模塊,打包結果如下:

可以發現,commonUtils模塊被打入了 add.js一起。
對于webpack來說,被異步模塊引入的模塊,如果這個模塊沒有被同步模塊引用過,那么在異步模塊中無論如何被引用,都是異步模塊。
如果我們在 main.js中同步引入 commonUtils
main.js
import '@utils/commonUtils'
import("@utils/add").then((module) => {console.log(module.add(100, 200));
});
可以看到,最終的打包結果中,commonUtils被和main這個同步模塊打包到一起了,如下:

?其實這也好理解,如果一個模塊都已經被同步載入過了,那么就沒必要再費網絡資源去異步請求了,直接復用即可。
雖然同步模塊和異步模塊在默認狀態下可以直接復用,但是這種復用僅僅存在于 同一入口的情況下,看下面例子: 我們增加一個app模塊,在app中異步引入commonUtils模塊,在main中同步引入commonUtils模塊?
webpack.config.jsentry: {app: "./src/app.js",main: "./src/main.js",},app.js
import("@utils/commonUtils").then((module) => {console.log(module);
});main.js
import '@utils/commonUtils'可以看到,在多入口的情況下,commonUtils被打包了兩次?

為什么多入口之間不能復用,因為webpack要保證每一個入口都是獨立可用的,對于main.js 其單獨使用的時候如果要獲取commonUtils.js 需要將整個main.js完整下載下來,無法保證每個入口的獨立性,所以會單獨打包一份出來。
我們把main.js中的同步引入commonUtils也改成異步,可以發現最終結果中只有一個commonUtils模塊,也就是說異步模塊在不同入口之間是可以復用的

這也符合邏輯,對于每個入口,由于對于commonUtils的載入都是異步的,在一開始載入的時候都不需要同步載入commonUtils,所以自然使用一個獨立模塊即可。?
?說完了這些,我們做個小總結 避免混亂
首先,這些都是在不進行任何分包優化下的情況,一定要明確前提
- webpack在默認情況下,會 并且 僅僅會對異步載入的模塊進行獨立分包處理
- 對于同步的模塊,webpack默認情況下都會打入主包中同步引入,不會獨立拆包
- 異步模塊中無論同步,還是異步的模塊引入 都算成是異步引入?
- 在相同入口的情況下,同步引入和異步引入會共享同步引入的模塊,不會單獨異步拆包
- 在不同入口下,同步和異步引入相對獨立,無法共用,會打兩份,但是異步模塊之間可以互相共用。
我認為,了解webpack默認行為會對后面的學習減少很多的"彎路",在理解分包現象的時候需要理解到底是splitChunk的優化結果,還是webpack的默認行為。
比方說chunks: async雖然是默認值,但是造成分包的并不是這個屬性的作用,屬于webpack的默認行為!
chunks屬性的真正含義
chunks屬性的真正含義如下
- async: 僅僅對異步導入的模塊進行splitChunks優化,同步導入的模塊會被忽略,也是chunks的默認值 (默認情況下,splitChunks只對webpack默認拆分出來的異步模塊生效)
- initial: initial即初始化的意思,瀏覽器初始化加載模塊的時候,會將引用的所有同步模塊都載入,所以initial的含義是,對于同步導入的模塊(即 初始化階段會被載入的模塊) 進行splitChunks優化,對于異步導入的模塊,會被忽略。 我們知道webpack的默認狀態下不會對同步模塊單獨拆包,所以initial就是用來增強其處理同步模塊的功能
瀏覽器初始化的時候,會將同步模塊一口氣都載入,那么分包的意義何在呢?
其實主要目的是對于打包多入口時,在默認情況下,如果兩個如果都引用了某個同步模塊, 為了保證兩個入口的獨立性,這個模塊會被重復兩次打包。initial的作用就是可以把這個共同引用的同步模塊拆分出來,減小打包文件的總體積。
- all: 對于同步,異步引入的模塊,都會進行splitChunks的優化,這個也是被官方推薦的方式。
很多教程中,說把chunks設置為 all 的作用是除了拆分async 還能拆分第三方vendor(即 node_modules)模塊 這個也是不對的,只是all很強大,開啟之后可以達到拆分第三方模塊的效果,但是絕對不是其作用就是為了拆分第三方模塊。 具體實現原理下面會說
我們看一些例子,如下,我們簡單的設置splitChunks的chunks: async 為了不影響我們觀察打包結果,我們先將minSize minChunks分別設置為 0 和 1 也就是讓拆包大小和引用chunks數不影響chunks本身的效果。
// webpack.config.jsentry: {app1: "./src/app1.js",app: "./src/app.js",main: "./src/main.js",},splitChunks: {chunks: "async",minSize: 0,minChunks: 1,}// app1.js
import"@utils/commonUtils"// app.js
import("@utils/commonUtils").then((module) => {console.log(module);
});// main.js
import"@utils/commonUtils"未開啟splitChunks優化

開啟 chunks: async? 優化異步模塊

可以看到,打包結果和不設置 splitChunk沒什么兩樣,但是這并不代表其未生效,我們來分析一下
首先,在進行拆包優化之前,由于在三個入口分別同步和異步引入了 commonUtils模塊。 由于在兩個不同入口中,同步異步引用無法復用,webpack的默認行為會把異步的commonUtils拆分出來,并且把同步引入的commonUtils合并到主包中。
優化開始,由于chunks: async 此時只對拆分出來的commonUtils進行拆分,忽略同步的commonUtils 所以此時沒什么可優化拆分的,splitChunks不會對打包結果有什么改變。
我們把chunks改成 initial 即 只對同步模塊進行優化, 可以看到,此時,兩個commonUtils被拆分出來了,由于有兩個入口同步引用了commonUtils,initial模式下,會把這個同步模塊單獨拆分進行復用。但是由于initial模式會忽略異步模塊,所以會導致異步的commonUtils和同步的commonUtils無法復用。

為了解決同步異步的commonUtils不能復用的問題,我們把chunks設置為 all 即 對同步引入和異步引入的模塊都開啟分包優化,此時的打包結果如下:

可以看到,由于對于同步異步的模塊splitChunk都會識別處理,所以commonUtils會被單獨拆分成一個chunk,供同步和異步的引入使用,這樣就達到了對commonUtils的最小化拆分。
再看一個例子,我們引入兩個入口,其中:
app1.js引入一個node_modules下的 lodash模塊
main中引入我們自己定義的 utils/commonUtils.js模塊
webpack.config.js
entry: {app1: "./src/app1.js",main: "./src/main.js",},chunks: all// app1.js
import "lodash";// main.js
import"@utils/commonUtils"打包結果如下:

你會發現,同樣是被一個入口引用1次,為什么lodash就被單獨拆分了,我們自己定義的包就沒被拆分,而我們已經設置了minSize: 0 也就是模塊大小不會影響拆包,那么為什么第三方模塊就被拆分了,我們自定義的模塊就不會? 這個就要引入我們下面要說的 cacheGroup 緩存組的概念了??
cacheGroups緩存組
緩存組用來定義哪些模塊被拆分成一組,拆分成一組的模塊可以被瀏覽器單獨的緩存,不用在每次更新的時候重新從服務器獲取。
cacheGroups需要配置一個對象,key未緩存組的名稱,value為一個配置對象,其中使用 test屬性匹配模塊的名稱,我們舉個例子:
splitChunks: {chunks: "all",minSize: 0,minChunks: 1,cacheGroups: {MyUtils: {test: /\/utils\//,minSize: 0,minChunks: 1,name: 'MyUtils'}}
}上述例子,我們設置一個MyUtils緩存組,其中test匹配路徑中包含 utils的模塊,并且設置其單獨分包名稱為 MyUtils。 其含義是,需要webpack對路徑中包含 utils的模塊單獨拆出來并且合并到一個包里,這個包的名稱為 MyUtils.
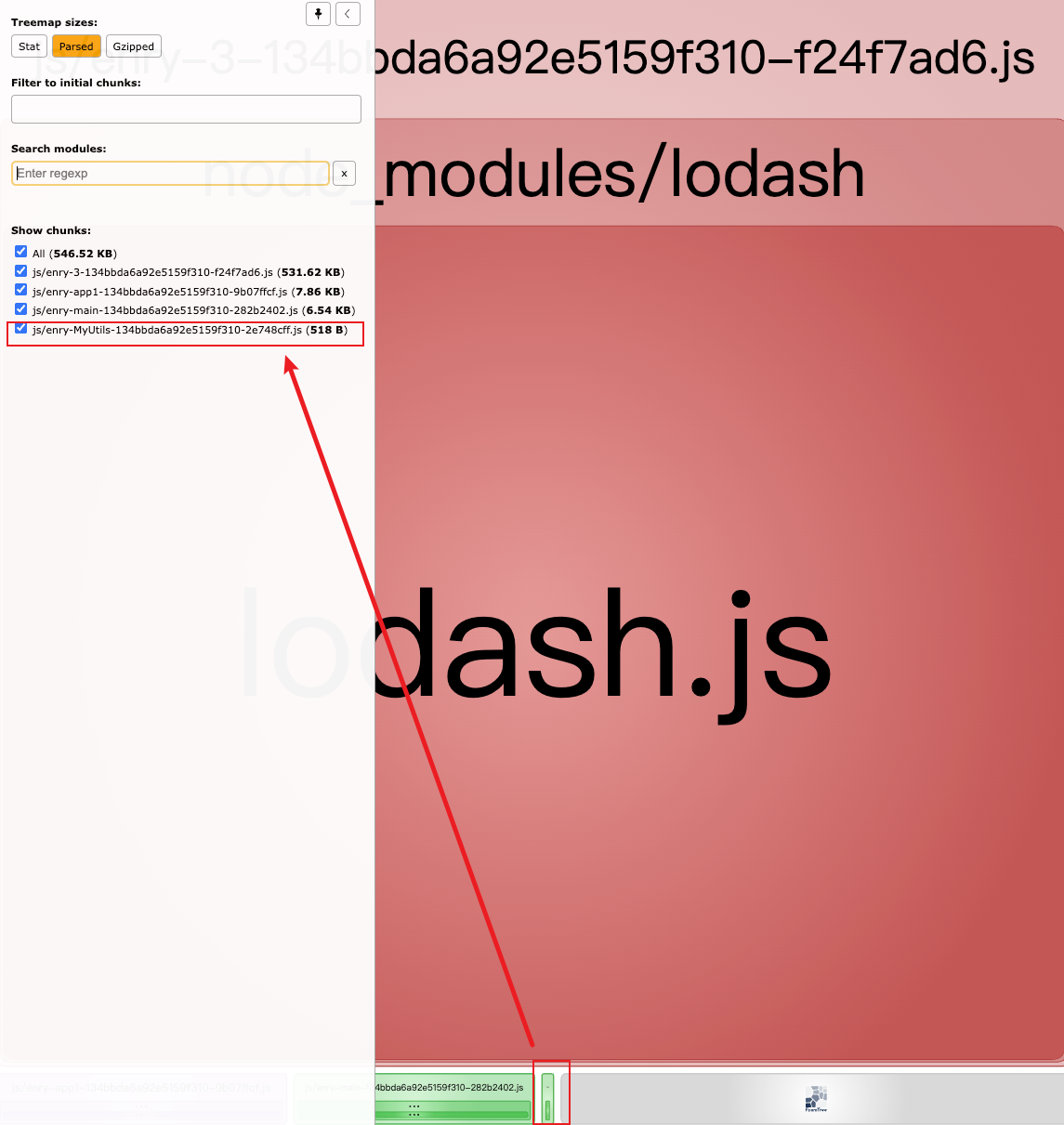
可以看到,這時我們自己定義的 utils/commonUtils.js被單獨打包了。
那么回到上面的問題,為什么node_modules的模塊就會被單獨拆分,我們自己寫的模塊就需要我們自定義一個緩存組才能實現拆分? 這是因為webpack內置了兩個 defaultVendors和default兩個緩存組 如下:
?
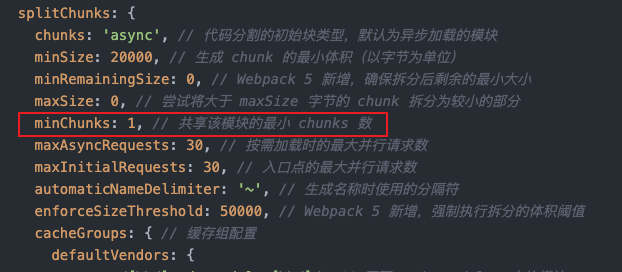
module.exports = {//...optimization: {splitChunks: {chunks: 'async', // 代碼分割的初始塊類型,默認為異步加載的模塊minSize: 20000, // 生成 chunk 的最小體積(以字節為單位)minRemainingSize: 0, // Webpack 5 新增,確保拆分后剩余的最小大小maxSize: 0, // 嘗試將大于 maxSize 字節的 chunk 拆分為較小的部分minChunks: 1, // 共享該模塊的最小 chunks 數maxAsyncRequests: 30, // 按需加載時的最大并行請求數maxInitialRequests: 30, // 入口點的最大并行請求數automaticNameDelimiter: '~', // 生成名稱時使用的分隔符enforceSizeThreshold: 50000, // Webpack 5 新增,強制執行拆分的體積閾值cacheGroups: { // 緩存組配置defaultVendors: {test: /[\\/]node_modules[\\/]/, // 匹配 node_modules 中的模塊priority: -10, // 優先級reuseExistingChunk: true // 如果當前 chunk 包含已從主 bundle 中拆分出的模塊,則重用該模塊},default: {minChunks: 2, // 被至少兩個 chunks 共享的模塊priority: -20, // 優先級低于 vendorsreuseExistingChunk: true // 重用已存在的 chunk}}}}
};可以看到,對于路徑包含 /node_modules/的模塊,splitChunks插件會默認將其分到一個緩存組中去,而對于default緩存組,其沒有設置test屬性,意味著沒有匹配到任何緩存組的模塊都會被default緩存組匹配,其優先級priority: -20 低于defaultVendors的-10 為最低優先級的緩存組,可以被當成是一組兜底的緩存策略。
這也就解釋了為什么我們自己定義的commonUtils模塊沒有被單獨拆包,雖然其匹配到了默認的default緩存組,但是由于其內部配置了 minChunks: 2 也就是說當前模塊必須被至少兩個chunk匹配到,才會單獨拆包,而上述例子commUtils只被引用了一次,所以沒有被單獨劃分。
你也許會問? lodash也只被匹配了一次啊? 為什么也被單獨拆包了? 這時因為defaultVendors緩存組沒有配置minChunks,那么會直接使用頂層的minChunks配置,也就是minChunks:1 任何模塊只要被一個chunk引用,就會被單獨拆包 (注意這里是chunks 不是 modules)
注意,cacheGroups這個名字很容易誤導人,其并不是把test匹配到的模塊都合并到一個chunk,還要考慮其中的 minSize minChunks name等等屬性的作用
你可以將其理解為 緩存規則組 把一組決定模塊是否緩存 如何緩存的規則 放到一個組里面,test匹配到某個group就使用這個group的規則。
?cacheGroups的作用原理 & 如何禁用cacheGroups
?回憶一下我們上面的例子,當我們設置cacheGroups時,如果cacheGroups的名稱和默認的 defaultVendors / default 不重復,那么不會覆蓋默認的cacheGroups配置
splitChunks: {chunks: "all",minSize: 0,minChunks: 1,cacheGroups: {MyUtils: {test: /\/utils\//,minSize: 0,minChunks: 1,name: 'MyUtils'}}
}等價于 splitChunks: {chunks: "all",minSize: 0,minChunks: 1,cacheGroups: {MyUtils: {test: /\/utils\//,minSize: 0,minChunks: 1,name: 'MyUtils'},defaultVendors: {test: /[\\/]node_modules[\\/]/,priority: -10,reuseExistingChunk: true },default: {minChunks: 2, priority: -20, reuseExistingChunk: true }}
}所以,如果我們不想使用默認配置,不能直接 cacheGroups: {} 而是需要
// 關閉默認cacheGroupscacheGroups: {default: false,defaultVendors: false}
禁用緩存組之后,我們再來看分包結果

可以看到,lodash和commonUtils都沒有被拆分。你也許會疑問了? 即便什么緩存組都沒匹配到 那頂層的默認配置不是還寫著 minChunks:1 呢么?
?
你可以簡單的理解為,cacheGroups是拆包的 “引擎” 只有匹配到了cacheGroups才會啟動分包流程,如果任何的緩存組都沒匹配到,光有頂層的那些配置是沒有任何意義的。
所以你需要記住,在沒有匹配到任何緩存組的情況下,splitChunk不會對模塊進行拆包優化!
所以,回到前面的問題,有些博客說,把chunks設置為all就開啟了對第三方模塊的分包優化 這是不嚴謹的,很可能讓人誤認為拆分第三方模塊是chunks all的效果,但是其實不是的。
由于我們引用第三方模塊大多是同步引入,而chunks默認值為 async,所以默認情況下,我們不會對同步引入的第三方模塊進行分包優化。
當開啟了all的時候,第三方模塊也會被納入分包優化的范圍,而splitChunks又內置了defaultVendors的緩存組,并且沒有設置其minChunks
所以才會拆分出第三方內容,設置chunks: all僅僅是整個拆分流程中的一個環節而已。
minSize
設置chunk的最小尺寸,單位字節(Byte),只有在模塊尺寸大于這個屬性值的時候,才會拆包
commonUtils的尺寸約為40B 當設置頂層minSize: 40 / 50 時,拆分結果如圖
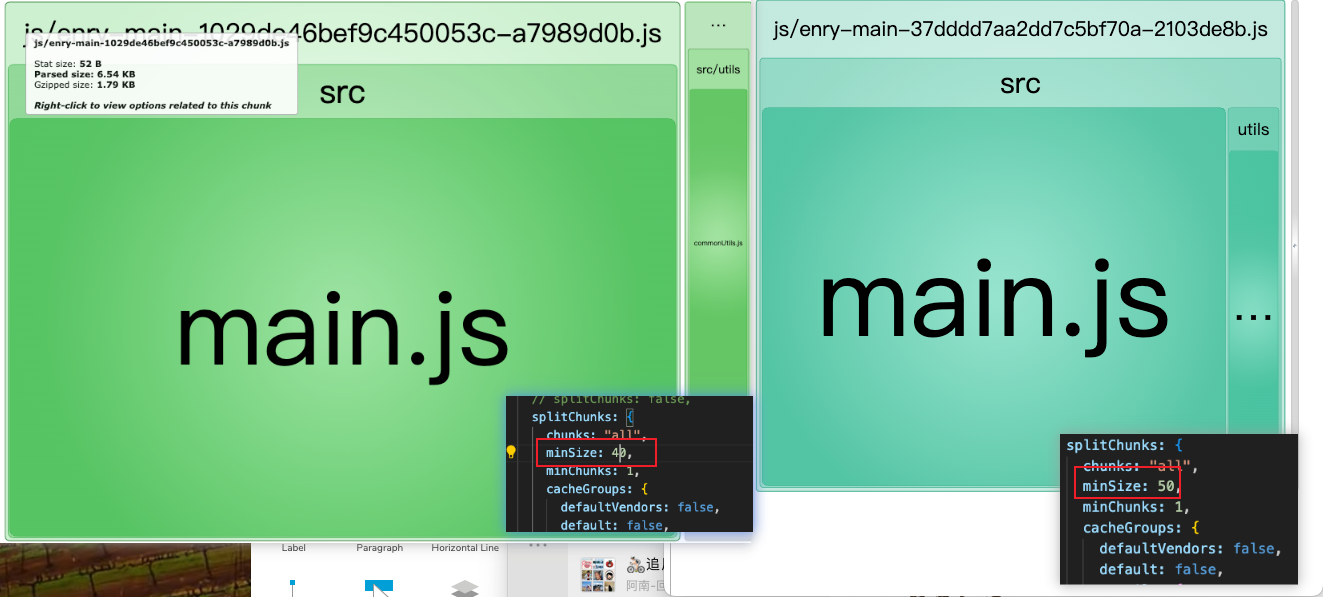
?同時,我們還可以在緩存組的內部設置minSize,其會覆蓋頂層的minSize配置

minChunks?
minChunks限制了模塊的最小chunks引用數,也就是模塊被至少 minChunks 個chunk引用,才會被分割出去。
這里的chunk計數,取決于chunks的配置,如果chunks配置為 async 那么只有異步模塊會進來匹配這個minChunks 如果是inital 那么只有同步模塊會被計算進chunks 如果是all則都被計算。我們看例子
webpack.config.jssplitChunks: {chunks: "initial",minSize: 0,minChunks: 1,cacheGroups: {// 關閉默認緩存組defaultVendors: false,default: false,utils: {test: /\/utils\/commonUtils.js/,minChunks: 3,name: 'MY_UTILS'}}
}entry: {app1: "./src/app1.js",app: "./src/app.js",main: "./src/main.js",},// main.js
import"@utils/commonUtils"//app.js
import("@utils/commonUtils").then((module) => {console.log(module);
});// app1.js
import"@utils/commonUtils"
main和app1 同步引用了commonUtils模塊,app異步引入commonUtils
我們設置commonUtils的緩存組minChunks: 3 chunks: initial 此時打包如下

可以看到 commonUtils被打包了3份 為什么?
1. webpack默認情況下,會把異步app.js中的common模塊單獨拆分
2. 由于chunks為initial 所以只會統計同步引入common模塊的chunks數 只有app和main兩個,所以不滿足minChunks: 3的配置,不分包,會對app1 main 兩個chunk都生成一份commonUtils
當我們設置minChunks: 2

可以看到,main和app1中的common模塊被抽取出來了,但是由于chunks為initial 沒有app中異步分離出來的commonUtils復用。 由于異步模塊會被忽略,splitChunks不知道有一份可以被復用的commonUtils已經被生成了。
為了解決,我們設置chunks為all,并且設置minChunks:3 如下:
splitChunks: {chunks: "all",minSize: 0,minChunks: 1,cacheGroups: {defaultVendors: false,default: false,utils: {test: /\/utils\/commonUtils.js/,minChunks: 3,},},}此時,只有一份common被抽取,如下:

其過程為
1. webpack默認抽取app中的異步common模塊
2. 分包優化的時候 由于同步異步模塊都會被記入minChunks統計,滿足minChunks: 3的條件 所以commonUtils會被單獨拆包,但是發現webpack默認已經拆了一份common出來 就直接復用即可。
而對于chunks initial的情況下,由于忽略了異步的common模塊,所以無法對已經拆出來的模塊進行復用。
enforce 強制拆分
enforce通常用在緩存組內,如果某個緩存組內設置了enforce: true 那么這個緩存組會忽略全局的 minSize minChunks等等這些限制,僅以緩存組內部的配置為準
?
需要注意的是 enforce是用來忽略全局的配置的,無法忽略緩存組內部的配置
看以下例子
// webpack.config.jssplitChunks: {chunks: "all",minSize: 999999,minChunks: 999999,cacheGroups: {defaultVendors: false,default: false,utils: {test: /\/utils\/commonUtils.js/,},},
}// 入口
import"@utils/commonUtils"
由于外層的 minChunks minSize設置的非常大,所以打包出來的結果是不進行任何拆分?

此時,如果我們設置了enforce: true 如下
splitChunks: {chunks: "all",minSize: 999999,minChunks: 999999999,cacheGroups: {defaultVendors: false,default: false,utils: {test: /\/utils\/commonUtils.js/,enforce: true,},},?外層的配置將會被直接忽略,可以看到 common模塊還是被正常分離出來了。這就是enforce直接忽略了外層的配置。?

但是,如果我們對緩存組內部設置minChunks: 2 此時enforce就無法對內部的限制產生效果了。
所以,當你想忽略掉頂層配置強制拆分某個模塊的時候,可以嘗試使用enforce屬性!?
maxInitialRequests
maxInitialRequest代表最大同步并發數量,也就是限制了單個entry下加載的最大initial chunk數量
需要注意 maxInitialRequests 默認包含入口chunk,當對某個緩存組做更精細化的配置時,要減去1
在看例子之前,需要先將全局的 enforceSizeThreshold設置為0,即沒有強制尺寸分包上限,方便我們觀察
?
webpack.config.jssplitChunks: {chunks: "all",minSize: 0,minChunks: 1,maxInitialRequests: 1,enforceSizeThreshold: 0,cacheGroups: {defaultVendors: false,default: false,react: {test: /react/,minSize: 0,minChunks: 1,}}// 入口
import react from 'react'maxInitialRequest默認包含了入口chunk,所以在某個緩存組內分析時要先減去入口chunk?
比如對于react緩存組,其沒設置maxInitialRequests 所以繼承全局的為 1 也就是說,對于react緩存組,其最多可以分出 maxInitialRequest - 入口chunk(1) = 0 個chunk,也就是說react不能被單獨分包,哪怕滿足minSize minChunks這些, 最終分包結果如下:

可以看到,react收到maxInitialRequests的限制,被合并到了入口chunk中。
若修改react緩存組內的maxInitialRequests: 2 那么其會覆蓋全局的配置,將react單獨分包 如下:
 ?
?
如果無法滿足 maxInitialRequest的要求,那么會盡可能把大的模塊拆分出來,小的合并,看下面例子
?
// webpack.config.jssplitChunks: {chunks: "all",minSize: 0,minChunks: 1,maxInitialRequests: 2,enforceSizeThreshold: 0,
}entry: {app1: "./src/app1.js",app: "./src/app.js",main: "./src/main.js",
}// app.js
import 'lodash'// app1.js
import 'lodash'
import 'react'//main.js
import"react"其引用關系如下圖:
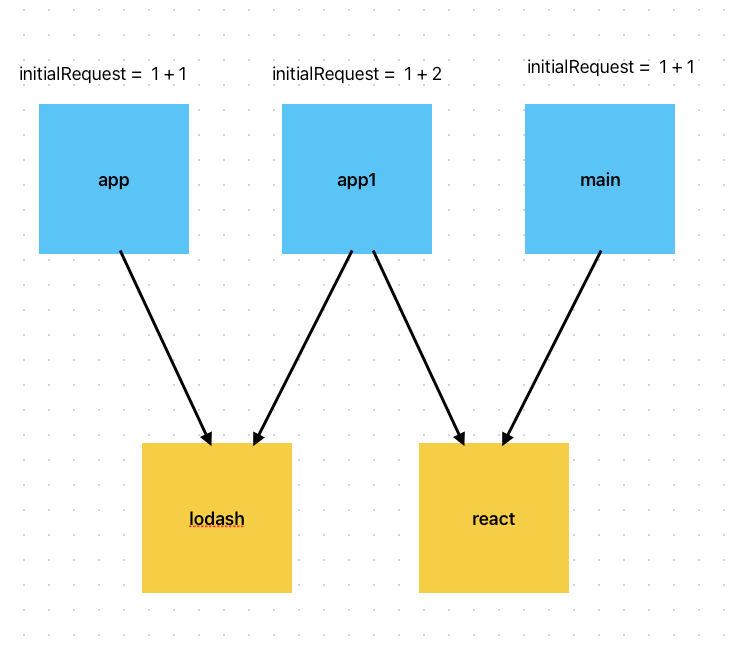
可以看到,app1模塊的initialRequest為 = app1入口chunk + lodash + react = 3 不滿足 maxInitialRequest = 2
webpack會把其中更大的lodash模塊拆分出來,更小的react模塊合并到入口chunk內, 如下
可以看到,對于 app 和 main 由于只引用了一個模塊 滿足maxInitialRequest: 2
但是對于 app1 更大的lodash被拆出來共用 ,更小的react被合并進app入口了。

?
注意!在
webpack中,runtimeChunk: true并不包含在maxInitialRequests的限制內。?
maxAsyncRequest
maxAsyncRequest和maxInitialRequest類似,區別在于,其限制的是 對于每個 import() 動態導入 最大并發的可以下載的模塊數, 其中 import() 本身算一個并行請求
有點繞,舉個例子
我們在入口動態引入一個 testModule.js 其中同步引入add sub兩個模塊 如下
// main.js
import ('@utils/testModule')// testModule.js
import "./add";
import "./sub";// add.js
export function add(x,y){return x + y
}//sub.js
export function sub(x,y){return x - y
}其依賴圖為
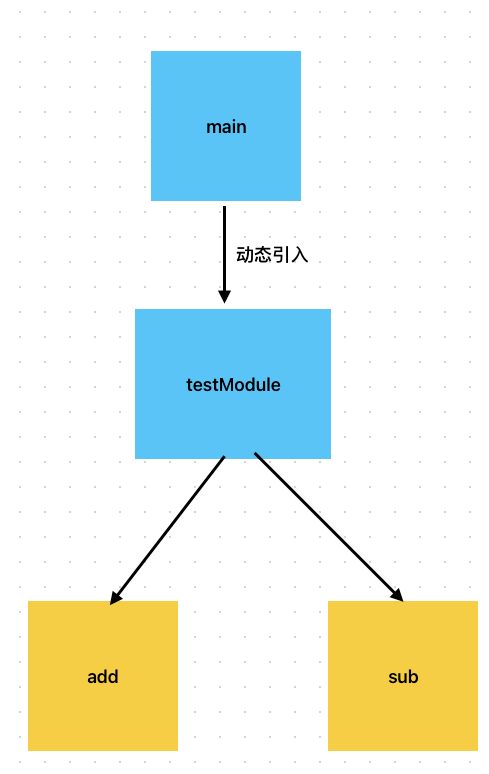
我們設置緩存組,讓各個模塊之間都相互獨立
splitChunks: {chunks: "all",minSize: 0,minChunks: 1,enforceSizeThreshold: 0,cacheGroups: {utils: {test: /\/utils\//,minChunks: 1,minSize: 0,priority: 10,name: ()=>'UTILS'+Math.random()},},?打包結果如下

全局設置?maxAsyncRequests: 1? 結果如下:

為什么三個模塊被打包到一起了? 因為在main中動態引入testModule 由于需要滿足maxAsyncRequest 此時 如果把add sub單獨拆分,那么asyncRequest = 動態導入testModule + add + sub? = 3 不滿足限制。
maxAsyncRequest設置為 2 可以看到打包結果為

add和sub被單獨拆分,和testModule分離,此時的asyncRequest剛好為 2
設置maxAsyncRequests = 3 可以看到三個模塊都被獨立分割了
 ??
??
我們修改 testModule 動態引入add 并且設置maxAsyncRequests為1
// testModule.js
import("./add");
import "./sub";splitChunks: {chunks: "all",minSize: 0,minChunks: 1,maxAsyncRequests: 1,enforceSizeThreshold: 0,cacheGroups: {utils: {test: /\/utils\//,minChunks: 1,minSize: 0,priority: 10,name: ()=>'UTILS'+Math.random()},},
此時可以看到,結果為

為什么add被單獨拆分了? 這是不是不滿足maxAsyncRequest: 1 的限制了? 其實不是
我們前面說了,splitChunks無法改變webpack的默認行為,由于add模塊屬于異步引入,對其拆分成一個單獨的模塊屬于webpack的默認行為,所以splitChunks只能在add被拆分的基礎上進行限制。
但是請你仔細考慮,maxAsyncRequests本身是不是就不包括異步引入的模塊呢?
對于一個import動態引入的模塊 其形式為?
import SyncModuleA. // 預解析 import SyncModuleB // 預解析 import (AsyncModuleC) // 運行時對于同步引入的SyncModuleA & B 在整個模塊被import的時候就會同步的下載這兩個模塊,但是對于動態引入的ModuleC 只有在運行到此的時候才會真正去加載,由此可見,異步引入模塊是不包含在maxAsyncRequest中的 其本意是 在動態引入一個模塊時,同步加載進來的模塊數量,而其中的異步模塊,并不屬于 "同步加載進來的"??
我們繼續修改maxAsyncRequest = 2 你可以猜到打包結果了
 ?其中,add.js是webpack默認行為拆分的,不包含在maxAsyncRequests的計算中,所以maxAsyncRequests = import(TestModule) + import 'add.js' = 2 滿足約束
?其中,add.js是webpack默認行為拆分的,不包含在maxAsyncRequests的計算中,所以maxAsyncRequests = import(TestModule) + import 'add.js' = 2 滿足約束
優化建議maxSize
maxSize表示,拆分的chunk最大值,當拆分出的chunk超過這個值的時候,webpack會嘗試將其拆分成更小的chunks
maxSize是個 "建議性質"的限制,也就是webpack如果沒有找到合適的切分點,maxSize將不起作用, 官方描述如下

maxSize的優先級 高于maxAsyncRequest / maxInitialRequest
看一個例子,
// main.js
import'react'//webpack.config.js
optimization: {runtimeChunk: true,// splitChunks: false,splitChunks: {chunks: "all",minSize: 0,minChunks: 1,maxInitialRequests: 1,maxSize: 200,enforceSizeThreshold: 0,
}}此時,react依舊會被拆分成小塊,即便不滿足maxInitialRequests,如下:
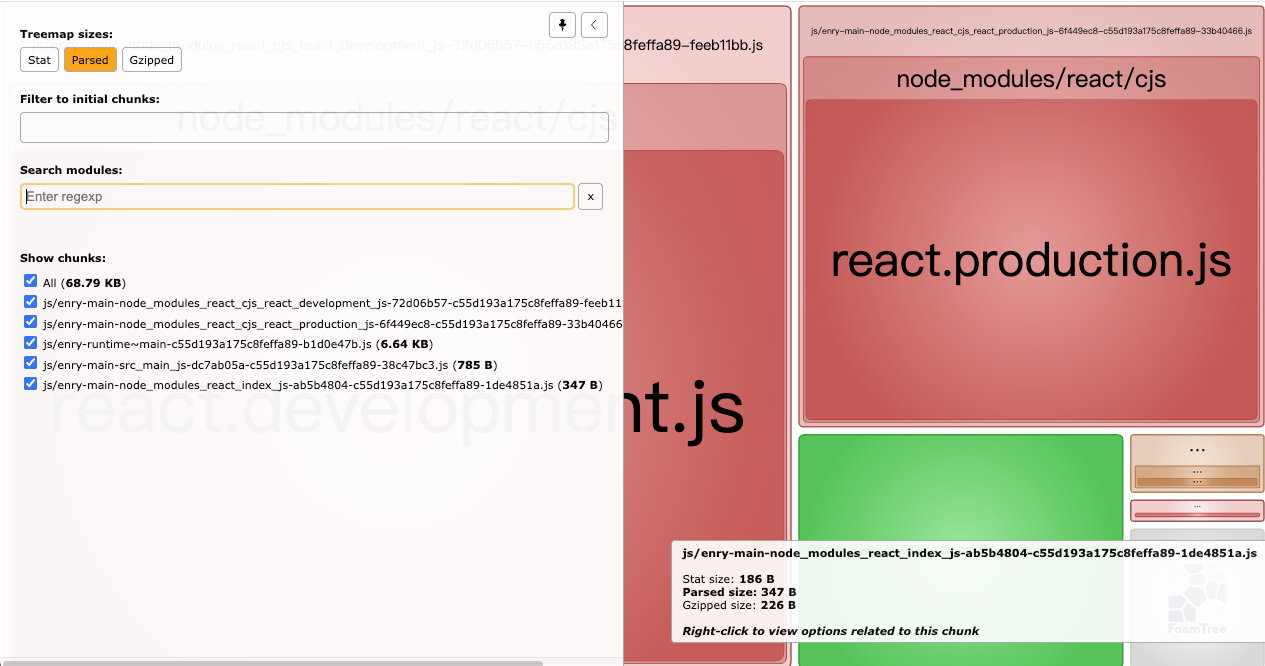
?








)



:Redis + Lua為什么可以實現原子性)






