文章目錄
- 音頻處理技術及應用
- 音頻處理技術
- 音視頻摘要技術
- 音頻識別及應用
- 梅爾頻率倒譜系數音頻特征
- 爾頻率倒譜系數簡介及參數提取過程
- 音頻處理
- 快速傅里葉變換(FFT)
- 能量譜處理
- 離散余弦轉換
- 練習案例:音頻建模
- 加載音頻數據源
- 波形變換的類型
- 繪制波形頻譜圖
- 波形Mu-Law 編碼
- 對比前后波形的比較
- 練習案例:音頻相似度分析
- 案例說明
- 實現代碼
- 結果分析
音頻處理技術及應用
- 音頻信號具有采集設備簡單、存儲空間小、處理速度快等優勢,本節介紹其核心技術及應用場景。
音頻處理技術
-
音頻處理技術的商業化應用日益廣泛。例如,微軟于2021年收購智能語音公司Nuance,主要看中其在醫療領域的對話式AI和云端解決方案。Nuance的Dragon語音轉錄軟件采用深度學習技術,持續提升識別精度,該技術已應用于蘋果Siri等產品。
-
隨著移動設備的普及和算力提升,現代智能終端普遍配備聲音傳感器和高效處理器,使音頻處理技術廣泛應用于以下領域: 多媒體數據檢索 、環境檢測與自適應調整 、視覺輔助系統(在視線受阻或光照不足時提供補充信息)
-
關鍵技術突破包括:
- 環境類別識別:設備可通過音頻分析自動切換模式(如手機識別場景類型)
- 輔助功能增強:助聽器等設備整合環境識別功能,提升用戶體驗
- 場景感知:系統能通過聲音特征(如對話、背景音)判斷環境類型(如區分餐廳和車輛)
-
音頻場景建模主要解決兩個問題: 特定場所的聲學特征建模(如餐廳、車站) 場景內對象/事件的聲學特征檢測(如笑聲、鳴笛聲)。盡管已開發MFCC等特征提取方法,但由于聲音信號的復雜性,建模分析仍面臨挑戰。
音視頻摘要技術
該技術通過提取關鍵內容實現信息壓縮:
- 音頻摘要:識別重要轉折點,生成時間縮短但保留核心內容的版本
- 視頻摘要:濃縮長視頻的關鍵片段,特別適用于監控錄像分析
關鍵技術實現:
- 音頻興趣度量化:
- 分割音頻為等長片段
- 提取MFCC特征并計算協方差矩陣
- 通過特征空間映射評估興趣度(實驗證明可有效識別笑聲等特征音)
- 音視頻融合分析:場景轉換常伴隨聲音變化(如球賽進球時的歡呼聲),可輔助關鍵幀提取
音頻識別及應用
主要解決海量音頻數據的高效檢索問題,核心應用包括:
-
音頻分類: 四大類別:語音、音樂、環境音、靜音
- 處理流程: 靜音檢測(基于能量閾值) ,MFCC特征提取,基于MDL的高斯建模分割,分層分類(語音/音樂/環境音)
-
音樂情感分析: 情感模型:
- 類別模型(6種基礎情感)
- 維度模型(情感空間坐標)
- 應用價值:實現多媒體內容的情緒化索引和檢索
梅爾頻率倒譜系數音頻特征
- 在語音識別(SpeechRecognition)和說話者識別(SpeakerRecognition)方面,最常用到的語音特征就是梅爾頻率倒譜系數(MFCC)。
爾頻率倒譜系數簡介及參數提取過程
- 梅爾頻率倒譜系數(MFCC)是音頻處理中常用的特征提取方法。它的設計模仿了人耳對聲音的感知特點。
-
基本原理:人耳對低頻聲音更敏感(比如能更好地區分低音變化),高頻區域的區分能力相對較弱
-
計算過程:
- 先設置一組三角濾波器(低頻區域濾波器密集,高頻區域稀疏)
- 讓音頻信號通過這些濾波器
- 記錄每個濾波器輸出的能量值
- 對這些能量值做進一步處理得到最終特征
- 主要優勢:不受原始聲音內容影響(適用于各種聲音);抗噪能力強(在嘈雜環境中仍能準確提取特征);符合人耳聽覺特性(提取的特征更貼近實際聽感)
- 這種方法讓機器能像人耳一樣"聽懂"聲音的關鍵特征。
- MFCC參數的提取過程如圖
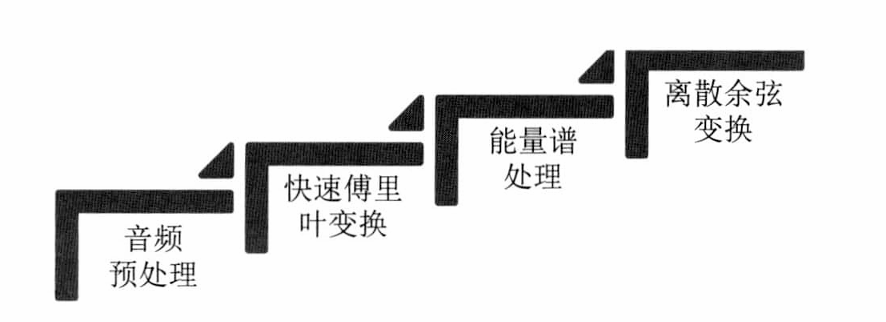
音頻處理
- 信號預處理過程包括預加重,分偵,加載。預加重的過程即使將語音信號通過一個高通濾波器得到新的信號,如語音信號 s ( n ) s(n) s(n)通過高通濾波器 H ( z ) = l ? α × ( z ? l ) H(z)=l-α×(z-l) H(z)=l?α×(z?l)預加重后得到的信號為 s 2 ( n ) = s ( n ) ? a × s ( n ? l ) s_2(n)=s(n)-a×s(n-l) s2?(n)=s(n)?a×s(n?l),其中,系數 a a a介于 0.9 0.9 0.9和 1.0 1.0 1.0之間。預加重的目的是補償音頻信號被隱藏的高頻部分,從而凸顯高頻的共振峰。
- 預處理過程的第二個步驟是分幀,語音信號分幀的目的是將若干個取樣點集合作為一個觀測單位,即處理單位,一般認為 10 ~ 30 m s 10~30ms 10~30ms的語音信號是穩定的,比如采樣率為 44.1 k H z 44.1kHz 44.1kHz的聲音信號,取20ms長度為一個幀長,那么一個幀長由 44100 × 0.02 = 882 44100×0.02=882 44100×0.02=882個取樣點組成。通常為了避免相鄰兩幀之間的變化過大,會在兩相鄰幀之間設置一段的重疊區域,重疊區域的長度一般是幀長的一半或 1 / 3 1/3 1/3。
- 在完成預加重和分幀之后,下一步是對每一幀應用漢明窗。通常,在處理語音信號時,“加窗”意味著一次只處理窗口內的數據。由于實際的語音信號往往很長,無法一次性全部處理。只需要每次分析一段數據即可。通過構造特定的函數實現,函數在處理區間內取非零值,在非處理區間內則為零。漢明窗就是這樣一種函數,任何信號與漢明窗,任何信號與漢明窗相乘后,結果的一部分將是非零值,其余部分則為零。處理完一個窗口內的數據后,需要移動窗口,通常移動的步長是幀長的一半或三分之一以產生重疊。
- 漢明窗函數的形式
w ( n , a ) = ( 1 ? a ) ? a × c o s ( 2 π × n N ? 1 ) 0 ≤ n ≤ N ? 1 w(n,a)=(1-a)-a\times cos(2\pi \times \frac{n}{N-1}) 0\leq n\leq N-1 w(n,a)=(1?a)?a×cos(2π×N?1n?)0≤n≤N?1 - N N N是處理數據點的個數(幀長),分幀是窗函數截取原音頻信號形成的,一般a取值為0.46,漢明窗函數還可以寫成如下形式:
KaTeX parse error: Undefined control sequence: \leqN at position 89: …{N-1}) 0\leq n \?l?e?q?N?\\ 0\quad \te… - 加漢明窗后的聲音信號如下:
s ( n ) = s ( n ) × w ( n ) n = 0 , 1 , . . . , N ? 1 s(n)=s(n)\times \qquad w(n) n=0,1,...,N-1 s(n)=s(n)×w(n)n=0,1,...,N?1
快速傅里葉變換(FFT)
- 快速傅里葉變換(FastFourierTransform,FFT)是一種高效計算離散傅里葉變換(DFT)的算法,在音頻處理中有著廣泛的應用。
- 原始音頻信號在時域上難以直觀體現特征,因此需要通過加漢明窗后進行快速傅里葉變換(FFT),將其轉換到頻域來觀察聲音的能量分布特征。
- FFT是對離散傅里葉變換(DiscreteFourierTransform,DFT)的改進算法,快速算法實現的基本思想是分析原有變換的計算特點以及某些子運算的特殊性,想辦法減少乘法和加法操作次數,換一種方式實現原變換的效果。
- 語音信號的離散傅里葉變換如下
S a ( k ) = ∑ n = 0 N ? 1 s ( n ) ? e ? j 2 π k / N 0 ≤ k ≤ N S_a(k)=\sum_{n=0}^{N-1}s(n)*e^{-j2\pi k/N} \qquad 0\leq k \leq N Sa?(k)=n=0∑N?1?s(n)?e?j2πk/N0≤k≤N - s ( n ) s(n) s(n)是加窗后的語音信號, N N N表示傅里葉變換的點數。
- FFT是利用分治策略和對稱性來減少DFT計算中的冗余步驟,從而提高了計算效率。這種算法特別適合信號處理中的頻譜分析,因為它可以快速地從時域信號中提取出頻域信息。
能量譜處理
- 音頻預處理后,就需要計算能量譜,即求頻譜幅度的平方。其計算方法是,將能量譜輸入一組Mel頻率的三角帶通濾波器組,三角濾波器的中心頻率為 f ( m ) , m = 1 , 2 , . . . , M f(m),m=1,2,...,M f(m),m=1,2,...,M,f(m)的取值隨m取值的減小而縮小,隨著m取值的增大而變寬,Mel頻率代表的是一般人耳對于頻率的感受度,其與一般的頻率間的關系如下。
m e l ( f ) = 2595 ? l g ( 1 + f 700 ) mel(f)=2595*lg(1+\frac{f}{700}) \\ mel(f)=2595?lg(1+700f?) - 或者
m e l ( f ) = 1125 ? l g ( 1 + f 700 ) mel(f)=1125*lg(1+\frac{f}{700}) mel(f)=1125?lg(1+700f?) - 人耳對頻率的感受度是呈對數變化的,在高頻部分人耳對聲音的感受越來越粗糙,在低頻部分則相對敏感。三角濾波器引入的目的是平滑化頻譜,消除諧波的作用,并突出原始信號的共振峰,因此MFCC參數不能呈現原始語音的音調或音高,即提取聲音信號的MFCC特征時,不受語音音調的影響。三角濾波器的頻率響應定義如下所示,其中
∑ m = 0 M ? 1 H m ( k ) = 1 \sum_{m=0}^{M-1}H_m(k)=1 m=0∑M?1?Hm?(k)=1
H m ( k ) = { 0 k < f ( m ? 1 ) 2 ( k ? f ( m ? 1 ) ) ( f ( m + 1 ) ? f ( m ? 1 ) ) ( f ( m ) ? f ( m ? 1 ) ) f ( m ? 1 ) ? k ? f ( m ) 2 ( f ( m + 1 ) ? k ) ( f ( m + 1 ) ? f ( m ? 1 ) ) ( f ( m + 1 ) ? f ( m ) ) f ( m ) ? k ? f ( m ? 1 ) 0 k ? f ( m + 1 ) \begin{equation} H _ { m } ( k ) = \left\{ \begin{array} { l l } { 0 } & { k < f ( m - 1 ) } \\ { \cfrac { 2 ( k - f ( m - 1 ) ) } { ( f ( m + 1 ) - f ( m - 1 ) ) ( f ( m ) - f ( m - 1 ) ) } } & { f ( m - 1 ) \leqslant k \leqslant f ( m ) } \\ { \cfrac { 2 ( f ( m + 1 ) - k ) } { ( f ( m + 1 ) - f ( m - 1 ) ) ( f ( m + 1 ) - f ( m ) ) } } & { f ( m ) \leqslant k \leqslant f ( m - 1 ) } \\ { 0 } & { k \geqslant f ( m + 1 ) } \end{array} \right. \end{equation} Hm?(k)=? ? ??0(f(m+1)?f(m?1))(f(m)?f(m?1))2(k?f(m?1))?(f(m+1)?f(m?1))(f(m+1)?f(m))2(f(m+1)?k)?0?k<f(m?1)f(m?1)?k?f(m)f(m)?k?f(m?1)k?f(m+1)???
離散余弦轉換
- 離散余弦轉換是一種在數字信號處理中非常有用的工具,它通過將信號轉換為頻域表示,幫助分析和處理信號,尤其在圖像和音頻編碼領域有著重要的應用。例如,我們對對數能量做離散余弦轉換(DCT),得到的 C ( n ) C(n) C(n) 即為 M M M 階的Mel倒譜參數,通常取前12個作為最終的MFCC特征。計算公式如下:
C ( n ) = ∑ m = 0 N ? 1 S ( m ) cos ? ( π n ( m ? 0.5 ) M ) 0 ≤ n < M C(n) = \sum_{m=0}^{N-1} S(m) \cos \left( \frac{\pi n (m - 0.5)}{M} \right) \quad 0 \leq n < M C(n)=m=0∑N?1?S(m)cos(Mπn(m?0.5)?)0≤n<M
- 上式得到的倒譜參數只能反映語音信號的靜態特性,如果要獲得語音信號的動態特性需采用靜態特性的差分譜描述,結合動態和靜態的特征能更有效地提高對信號的識別性能,計算差分參數的公式如下:
d t = { C t + 1 ? C t t < K ∑ k = 1 K k ( C t + k ? C t ? k ) 2 ∑ k = 1 K k 2 其他 C t ? C t ? 1 t ≥ Q ? K d_t = \begin{cases} C_{t+1} - C_t & t < K \\ \frac{\sum_{k=1}^{K} k (C_{t+k} - C_{t-k})}{\sqrt{2 \sum_{k=1}^{K} k^2}} & \text{其他} \\ C_t - C_{t-1} & t \geq Q - K \end{cases} dt?=? ? ??Ct+1??Ct?2∑k=1K?k2?∑k=1K?k(Ct+k??Ct?k?)?Ct??Ct?1??t<K其他t≥Q?K?
- 其中, Q Q Q 表示的是倒譜系數的階數, d t d_t dt? 表示第 t t t 個一階差分, C t C_t Ct? 表示第 t t t 個倒譜系數, K K K 表示的是一階導數的時間差,取1或2。
練習案例:音頻建模
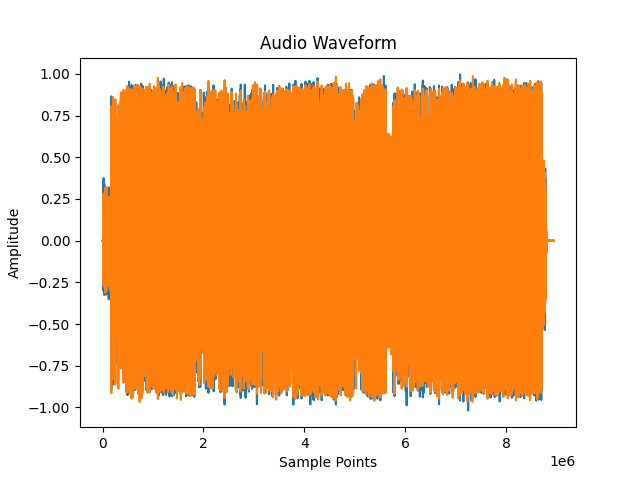
加載音頻數據源
import torchaudio
import matplotlib.pyplot as plt#加載聲音文件,原始音頻信號
filename = "恭喜發財.mp3"
# 加載音頻文件并獲取波形和采樣率
waveform,sample_rate = torchaudio.load(filename)
# 顯示波形
print("波形形狀:{}".format(waveform.size()))
# 顯示采樣率
print("波形采樣率:{}".format(sample_rate))
# 繪制波形圖并添加標題和坐標軸標簽
plt.figure()
plt.plot(waveform.t().numpy())
plt.title("Audio Waveform")
plt.xlabel("Sample Points")
plt.ylabel("Amplitude")
plt.show()
波形形狀:torch.Size([2, 8935836])
波形采樣率:44100
波形變換的類型
torchaudio庫支持的波形轉換類型如下。
| 功能名稱 | 描述 |
|---|---|
| 重采樣 (Resample) | 將波形重采樣為其他采樣率。 |
| 頻譜圖 (Spectrogram) | 從波形創建頻譜圖。 |
| GriffinLim | 使用Griffin-Lim轉換從線性比例幅度譜圖計算波形。 |
| ComputeDeltas | 計算張量(通常是聲譜圖)的增量系數。 |
| ComplexNorm | 計算復數張量的范數。 |
| MelScale | 使用轉換矩陣將正常STFT轉換為Mel頻率STFT。 |
| AmplitudeToDB | 將頻譜圖從功率/振幅標度變為分貝標度。 |
| MFCC | 根據波形創建梅爾頻率倒譜系數。 |
| MelSpectrogram | 使用PyTorch中的STFT功能從波形創建MEL頻譜圖。 |
| MuLawEncoding | 基于mu-law壓擴對波形進行編碼。 |
| MuLawDecoding | 解碼mu-law編碼的波形。 |
| TimeStretch | 在不更改給定速率的音高的情況下,及時拉伸頻譜圖。 |
| FrequencyMasking | 在頻域中屏蔽頻譜圖應用。 |
| TimeMasking | 在時域中屏蔽頻譜圖應用。 |
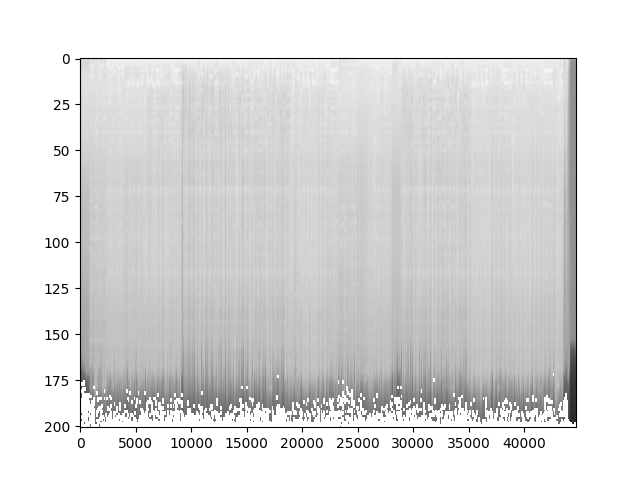
繪制波形頻譜圖
- 以對數刻度查看頻譜圖的對數。首先使用torchaudio庫中的Spectrogram函數將波形數據轉換為頻譜圖。然后打印出頻譜圖的形狀,并使用Matplotlib庫繪制并顯示頻譜圖。通過觀察頻譜圖,可以了解信號在不同頻率上的能量分布情況。
import torchaudio
import matplotlib.pyplot as plt
#加載聲音文件,原始音頻信號
filename = "恭喜發財.mp3"
# 加載音頻文件并獲取波形和采樣率
waveform,sample_rate = torchaudio.load(filename)
#對數刻度查看頻譜圖
spectrogram = torchaudio.transforms.Spectrogram()(waveform)
# 打印頻譜圖的形狀,即頻譜圖的尺寸
print("頻譜圖形狀:{}".format(spectrogram.size()))
plt.figure()
"""
# 顯示頻譜圖的對數變換結果spectrogram.log2()[0,:,:].numpy()表示取頻譜圖的對數變換結果,并將其轉換為NumPy 數組cmap='gray用于指定顏色映射為灰度色aspect="auto”表示自動調整圖像的縱橫比
"""
plt.imshow(spectrogram.log2()[0,:,:].numpy(),cmap='gray',aspect="auto")
plt.show()
頻譜圖形狀:torch.Size([2, 201, 44680])
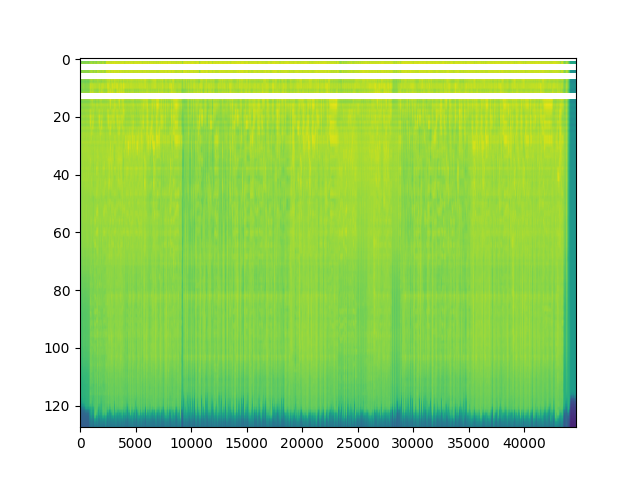
- 使用對數刻度查看梅爾頻譜圖。將波形數據轉換為梅爾頻譜圖,并將其可視化顯示出來,以便觀察信號在梅爾頻率尺度上的能量分布情況。使用MelSpectrogram函數來生成梅爾頻譜圖。梅爾頻譜圖是一種特殊的頻譜表示,它基于梅爾頻率尺度,常用于語音處理等領域。
import torchaudio
import matplotlib.pyplot as plt
#加載聲音文件,原始音頻信號
filename = "恭喜發財.mp3"
# 加載音頻文件并獲取波形和采樣率
waveform,sample_rate = torchaudio.load(filename)
#對數刻度查看梅爾光譜圖
spectrogram = torchaudio.transforms.MelSpectrogram()(waveform)
print("梅爾頻譜圖形狀:{}".format(spectrogram.size()))
plt.figure()
# 顯示梅爾頻譜圖的對數變換結果
p = plt.imshow(spectrogram.log2()[0,:,:].detach().numpy(),cmap='viridis',aspect="auto")
plt.show()
梅爾頻譜圖形狀:torch.Size([2, 128, 44680])
- 重新采樣波形,一次一個通道。重采樣常用于改變波形的采樣率,以便適應不同的需求或處理。
import torchaudio
import matplotlib.pyplot as plt
#加載聲音文件,原始音頻信號
filename = "恭喜發財.mp3"
# 加載音頻文件并獲取波形和采樣率
waveform,sample_rate = torchaudio.load(filename)
# 計算新的采樣率,將原始采樣率除以15
new_sample_rate = sample_rate/15
# 選擇要處理的通道,設置為0
channel = 0
# 使用Resample函數對波形進行重采樣將原始采樣率和新的采樣率作為參數傳遞給函數,并將波形數據的指定通道轉換為一維張量
transformed = torchaudio.transforms.Resample(sample_rate,new_sample_rate)(waveform[channel,:].view(1,-1))
# 打印變換后波形的形狀,即尺寸信息
print("變換后波形形狀:{}".format(transformed.size()))
plt.figure()
# 繪制變換后的波形 transformed[O,:]表示取變換后波形的第一個樣本,并將其轉換為NumPy數組進行繪圖
plt.plot(transformed[0,:].numpy())
plt.show()
變換后波形形狀:torch.Size([1, 595723])
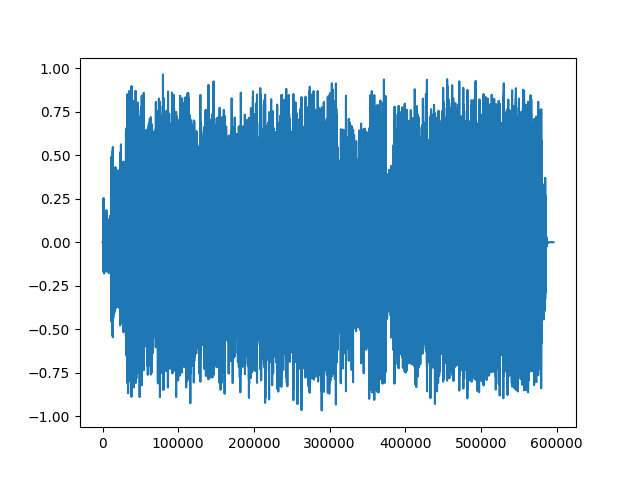
波形Mu-Law 編碼
- 基于Mu-Law編碼對信號進行編碼,需要信號在-1和1之間。由于張量只是一個常規的PyTorch張量,因此可以在其上應用標準運算符。
print("波形最小值:{}\n波形最大值:{}\n波形平均值:{}".format(waveform_.min(),waveform_.max(),waveform_.mean()))
波形最小值:-1.0179462432861328
波形最大值:0.9967186450958252
波形平均值:-1.8553495465312153e-05
- 對波形進行歸一化,使其處于-1到1之間。
#波形的歸一化
def normalize(tensor):tensor_minusmean = tensor - tensor.mean()return tensor_minusmean/tensor_minusmean.abs().max()waveform_normalize = normalize(waveform)print("波形最小值:{}\n波形最大值:{}\n波形平均值:{}".format(waveform_normalize.min(),waveform_normalize.max(),waveform_normalize.mean()))
波形最小值:-1.0
波形最大值:0.9791827201843262
波形平均值:1.3822981648203836e-09
- 應用編碼波形,繪制波形圖幫助理解變換后的波形特征。
#新波形Mu-Law編碼
transformed = torchaudio.transforms.MuLawEncoding()(waveform_normalize)
print("變換后波形形狀: {}".format(transformed.size()))plt.figure()
plt.plot(transformed[0,:].numpy())
plt.show()
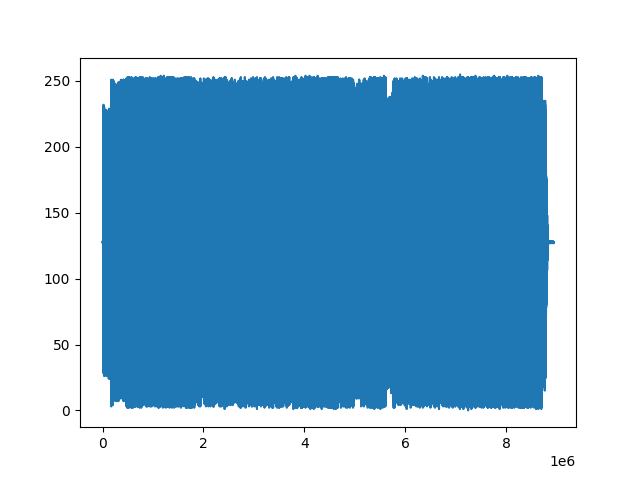
- 解碼并觀察到解碼后新波形的形狀和特征。Mu-Law編碼是Mu-Law編碼的逆操作,用于將編碼后的波形還原為原始波形的近似。繪制波形圖可以幫助直觀地理解解碼后的波形特征。
#對新波形解碼
reconstructed = torchaudio.transforms.MuLawDecoding()(transformed)
print("新波形形狀: {}".format(reconstructed.size()))plt.figure()
plt.plot(reconstructed[0,:].numpy())
plt.show()
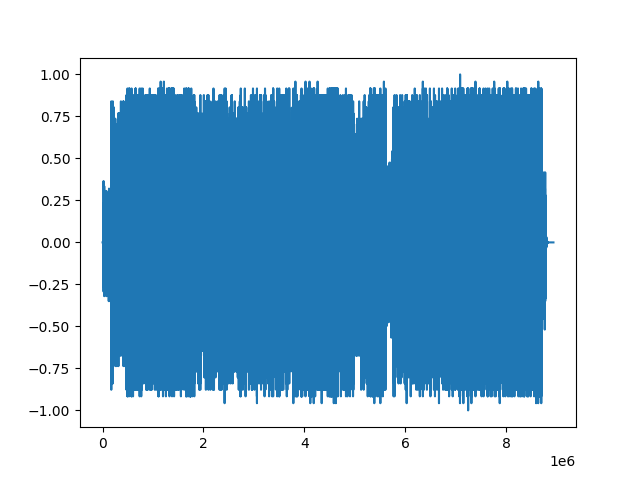
對比前后波形的比較
- 分析波形變換前后是否存在較大差異,可以將原始波形與歸一化和Mu-Law變換后的波形進行比較。評估原始波形和重構波形之間的相似度或差異程度。
#比較原始波形與新波形
epsilon = 1e-8
err = ((waveform - reconstructed).abs() / (waveform.abs() + epsilon)).mean()
print("原始信號和重構信號之間的差異: {:.2%}".format(err))
原始信號和重構信號之間的差異: 27.08%
練習案例:音頻相似度分析
案例說明
- 通過使用torchaudio庫和余弦相似度研究兩個音頻之間的相似程度,從而根據用戶喜歡的音頻信號進行音樂等方面的推薦。
實現代碼
import torch
import torchaudio
import soundfile
import matplotlib.pyplot as plt
# 支持中文的字體
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑體
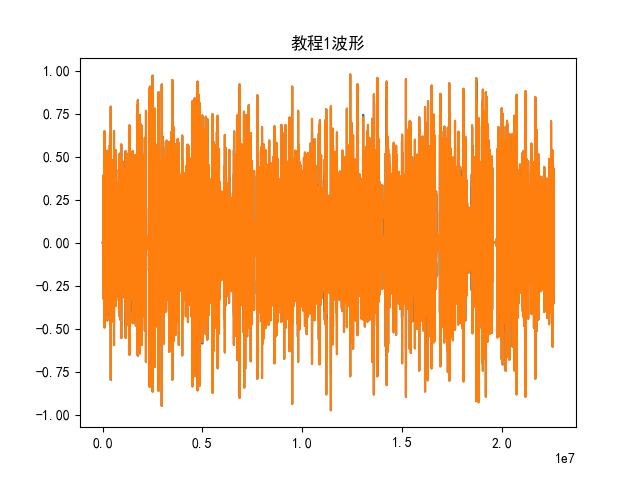
plt.rcParams['axes.unicode_minus'] = False # 解決負號 '-' 顯示為方塊的問題filename1 = "教程1.wav"
waveform1,sample_rate1 = torchaudio.load(filename1)
print("Shape of waveform:{}".format(waveform1.size())) #音頻大小
print("sample rate of waveform:{}".format(sample_rate1))#采樣率
plt.figure()
plt.plot(waveform1.t().numpy())
plt.title("教程1波形")
plt.show()filename2 = "教程2.wav"
waveform2,sample_rate2 = torchaudio.load(filename2)
print("Shape of waveform:{}".format(waveform2.size())) #音頻大小print("sample rate of waveform:{}".format(sample_rate2))#采樣率
plt.figure()
plt.plot(waveform2.t().numpy())
plt.title("教程2波形")
plt.show()similarity = torch.cosine_similarity(waveform1, waveform2, dim=0)
print('similarity', similarity)
# 輸出平均差異值
print(similarity.mean())
# 輸出中位數
print(similarity.median())
結果分析
Shape of waveform:torch.Size([2, 22601250])
sample rate of waveform:44100
Shape of waveform:torch.Size([2, 22601250])
sample rate of waveform:44100
similarity tensor([0.0000, 0.0000, 0.0000, ..., 0.9701, 1.0000, 0.9487])
tensor(-6.3115e-05)
tensor(0.)
- 余弦相似度是一種常用的相似性度量,用于衡量兩個向量之間的相似程度。這里用于比較兩個波形之間的相似度運行結果為
similarity tensor([0.0000, 0.0000, 0.0000, ..., 0.9701, 1.0000, 0.9487]) - 相似度矩陣的均值
similarity.mean()計算相似度矩陣的均值。 - 相似度矩陣的中位數
similarity.median()接近于0,說明兩個音頻不相思。










——延遲巨低的項目+雙屏顯示)








)