聚類算法
1.簡介
1.1 聚類概念
-
無監督學習:聚類是一種無監督學習算法,不需要預先標記的訓練數據
-
相似性分組:根據樣本之間的相似性自動將樣本歸到不同類別
-
相似度度量:常用歐式距離作為相似度計算方法
1.2 聚類vs分類
-
聚類:無監督,不知道類別數量或含義,基于相似性分組
-
分類:有監督,使用已標記數據訓練模型預測新數據類別
2. K-means聚類實現
2.1 API介紹
from sklearn.cluster import KMeans# 主要參數
KMeans(n_clusters=8) # n_clusters指定聚類中心數量# 常用方法
estimator.fit(x) # 訓練模型
estimator.predict(x) # 預測類別
estimator.fit_predict(x) # 訓練+預測2.2 代碼實現步驟
1.創建數據集from sklearn.datasets import make_blobs
import matplotlib.pyplot as pltX, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=9)# 可視化
plt.scatter(X[:,0], X[:,1], marker='o')
plt.show()2.聚類
from sklearn.cluster import KMeans# 嘗試不同聚類數量
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X)# 可視化結果
plt.scatter(X[:,0], X[:,1], c=y_pred)
plt.show()3.聚類評估from sklearn.metrics import calinski_harabasz_score# 使用Calinski-Harabasz指數評估
print(calinski_harabasz_score(X, y_pred))3.算法流程?
算法優化的是SSE,所以每一步都在把每個點分配到歐式距離最小的點。當然當優化的損失函數不同時,我們可以采取不同的距離。
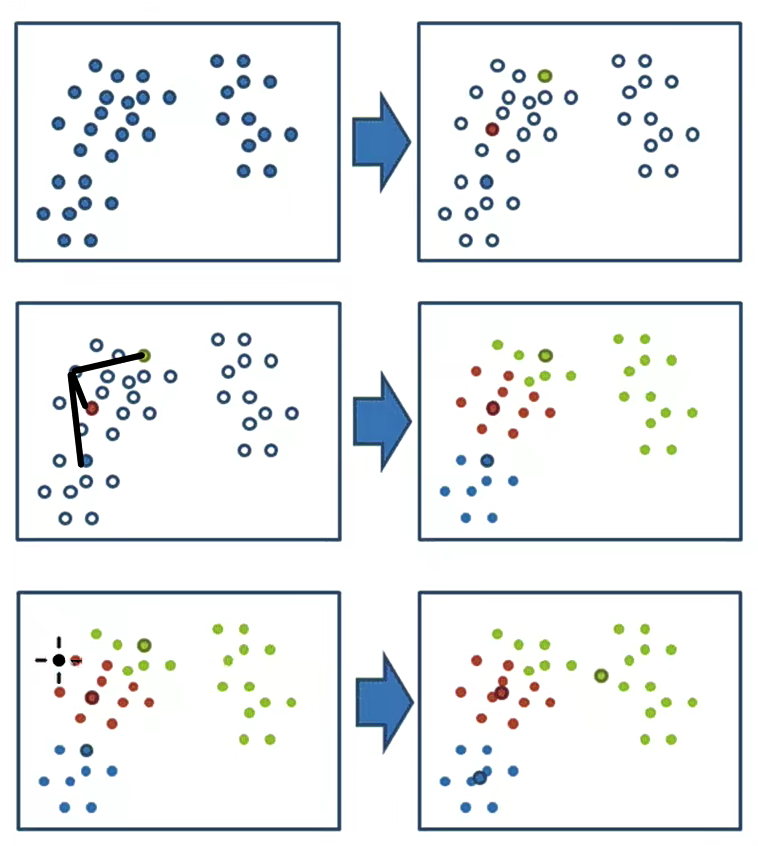
K-means聚類步驟詳解
-
初始化聚類中心
-
隨機選擇(有改進)K個數據點作為初始聚類中心
-
這些中心點位于特征空間內
-
-
分配數據點到最近中心
-
對于每個數據點,計算它與所有K個中心的距離
-
將該點分配到距離最近的聚類中心所屬的簇
-
常用距離度量:歐幾里得距離(歐式距離)
-
-
重新計算聚類中心
-
對每個簇,計算其中所有點的均值(每個特征維度的平均值)
-
將均值點作為新的聚類中心
-
-
判斷收斂
-
比較新舊中心點的位置變化
-
如果中心點不再移動(或移動小于閾值),算法終止
-
否則,返回步驟2繼續迭代
-
算法特點說明
-
需要預先指定K值:這是算法的主要限制之一
-
對初始中心敏感:不同的初始中心可能導致不同的最終結果
-
對異常點敏感:涉及到求平均,異常點會產生誤差很大。
-
迭代過程保證收斂:算法一定會收斂,但可能只是局部最優
-
適用于凸形數據分布:對非凸分布效果可能不佳
實際應用提示
-
可以通過多次運行取最優結果來緩解初始中心敏感問題
-
使用肘部法則(Elbow Method)或輪廓系數等方法幫助確定最佳K值
-
數據標準化很重要,因為K-means對特征的量綱敏感
4.算法評估:
4.1SSE(確定迭代次數)
 ?
?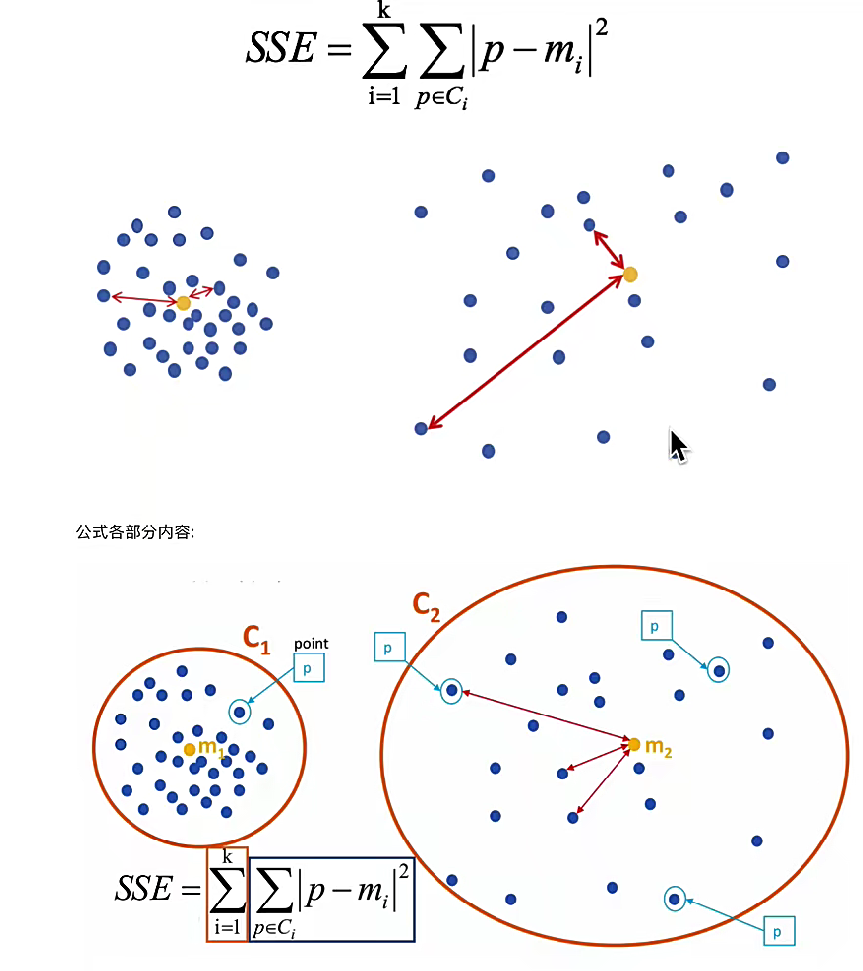
就是計算每個簇中,每個點到中心點的距離平方,很明顯當數據很多時,SSE計算會很計算量大、
4.2.肘方法(確定K)

4.3.輪廓系數(選擇K)

a就是凝聚度,b就是分離度,我們希望高凝聚,高分離,也就是a小b大,所以那個公式就是SC越為一越好。但是,SC越1越好嗎,我們在選擇K的時候需要考慮希望使得樣本不是很極端,比如
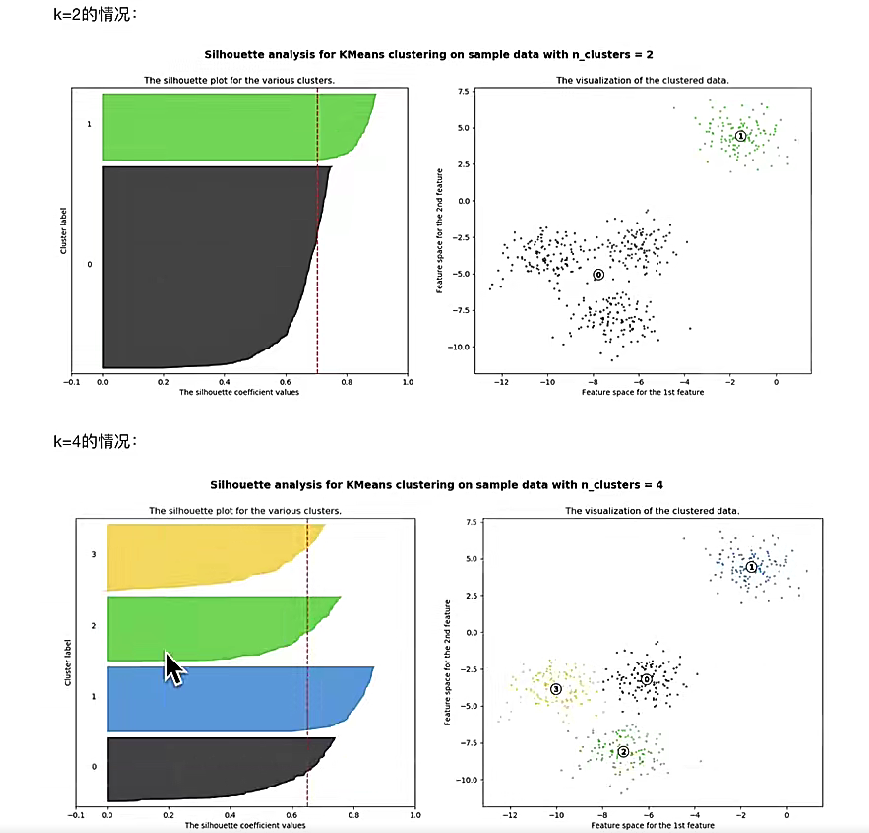 k=2的時候第一簇極度窄于第二簇,雖然它的SC小但是我們選擇k=4.
k=2的時候第一簇極度窄于第二簇,雖然它的SC小但是我們選擇k=4.
4.4.C-H系數(選擇K)

5.kmeans優缺點

6.Canopy算法
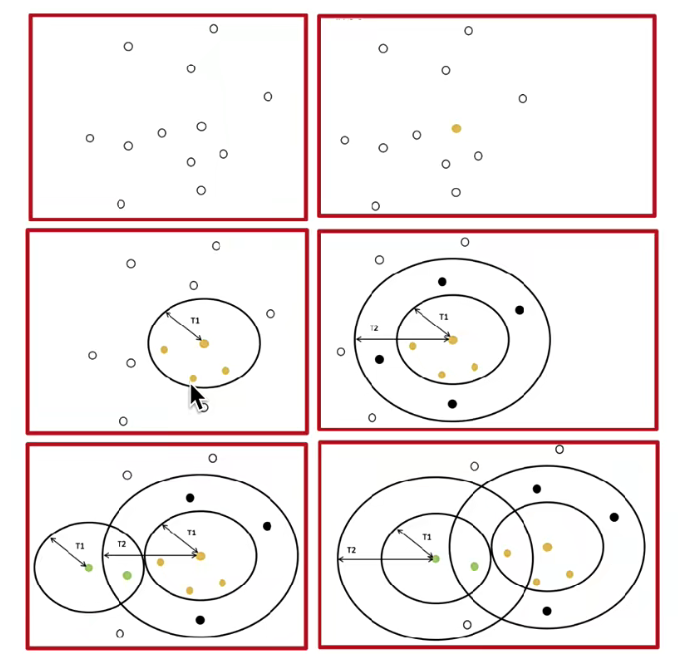
算法流程:

該算法之所以被稱為預聚類,因為它的結果和選取的起始點可以作為以后的參考。?算法簡而言之就是我先選一個點,在T1距離內視作這個類,在T2內我們不能再選出另一個起始點,然后選擇一個隨機點繼續進行以上步驟。
優點解讀
- 抗干擾能力提升:K - means 算法對噪聲敏感,離群點易使聚類中心偏移。Canopy 算法在預處理階段,通過設定距離閾值,可將包含少量樣本點(NumPoint 較小)的 Cluster 直接去除。這些小 Cluster 很可能是由噪聲或離群點形成的,去掉它們能減少噪聲對后續聚類的干擾,提升聚類結果的穩定性 。
- 聚類中心初始化優化:Canopy 算法在聚類過程中,會確定每個 Canopy 的中心點。將這些中心點作為 K - means 算法的初始聚類中心(K ),相較于 K - means 隨機選取初始中心,Canopy 算法得到的中心更具代表性,能使 K - means 更快收斂到更優解,提高聚類精度 。
- 計算量降低:Canopy 算法先將數據集劃分成若干個相互重疊的子集(Canopy) 。后續對每個 Canopy 內部進行 K - means 聚類,無需在整個數據集上進行相似性計算,極大減少了計算量,尤其適用于大規模數據集,能有效提高聚類效率 。
缺點解讀
- 閾值確定難題:Canopy 算法依賴兩個距離閾值 T1 和 T2 ,合適的閾值能使算法有效劃分數據集。但實際應用中,很難事先確定最優的 T1 和 T2 值。若閾值設置不當,可能導致劃分的 Canopy 過于稀疏或過于密集,影響聚類效果。同時,即使使用 Canopy 算法進行預處理,后續基于 Canopy 的 K - means 聚類依舊可能陷入局部最優解,因為 K - means 本身的迭代優化特性容易受初始條件和數據分布影響 。
7.k-means++算法
K - means++ 是 K - means 算法的改進版本,主要改進在于初始聚類中心的選擇,目的是讓選擇的質心盡可能分散,以提升聚類效果,減少陷入局部最優的可能性
初始聚類中心選擇概率公式
- 公式原理:
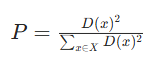 其中D(x)表示數據點x到最近已選聚類中心的距離 。該公式計算每個數據點被選為下一個聚類中心的概率,分子是單個數據點到最近已選中心距離的平方,分母是所有數據點到最近已選中心距離平方的總和。通過這種方式,距離已選中心遠的點有更大概率被選為新的聚類中心 。
其中D(x)表示數據點x到最近已選聚類中心的距離 。該公式計算每個數據點被選為下一個聚類中心的概率,分子是單個數據點到最近已選中心距離的平方,分母是所有數據點到最近已選中心距離平方的總和。通過這種方式,距離已選中心遠的點有更大概率被選為新的聚類中心 。 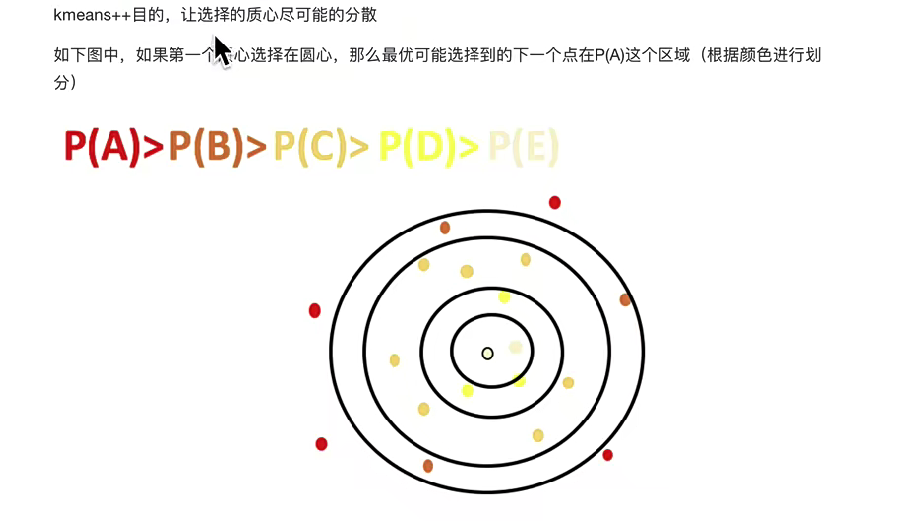
8.二分k-means算法
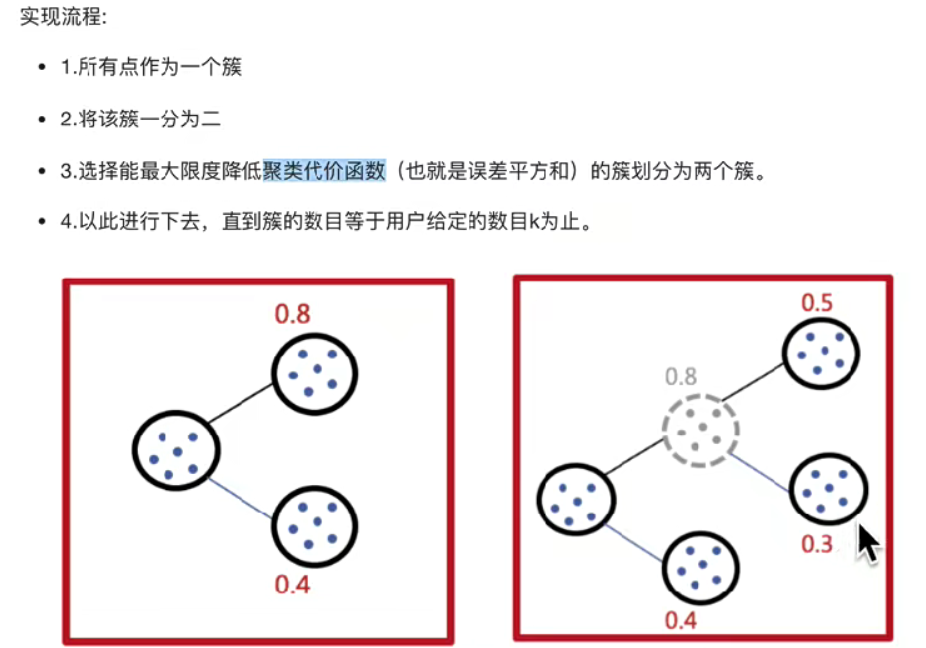 ?
?
9.K-中心聚類算法

k - medoids 算法抗噪性優勢
- 原理:k - medoids 算法選擇實際數據點作為簇中心(medoids ,即中心點),通過最小化絕對誤差(如曼哈頓距離等)來確定簇中心。與 k - means 計算均值作為質心不同,它更關注數據點本身的代表性。
- 示例:樣本點(1,1)、(1,2)、(2,1)相對接近,屬于正常數據,而(1000,1000)是明顯噪聲點。k - means 會受噪聲影響,使質心偏向噪聲點方向;k - medoids 則在所有樣本點中選擇使簇絕對誤差最小的點作為中心,由于噪聲點會增大誤差,所以更可能在前三個正常樣本點中選中心,避免噪聲干擾,體現出對噪聲的魯棒性。
k - medoids 算法局限性
- 計算效率問題:k - medoids 算法計算量較大,隨著樣本數量增加,計算每個數據點作為中心點時的絕對誤差并進行比較的操作會耗費大量時間和資源,導致算法運行速度變慢。
- 與 k - means 對比:在大規模樣本情況下,k - means 雖然對噪聲敏感,但少量噪聲對其質心計算影響有限,且 k - means 計算簡單、效率高。所以綜合來看,k - means 在實際應用中更為廣泛,而 k - medoids 更適用于對噪聲敏感且樣本規模較小的場景。
數據降維
1.定義和主要方式
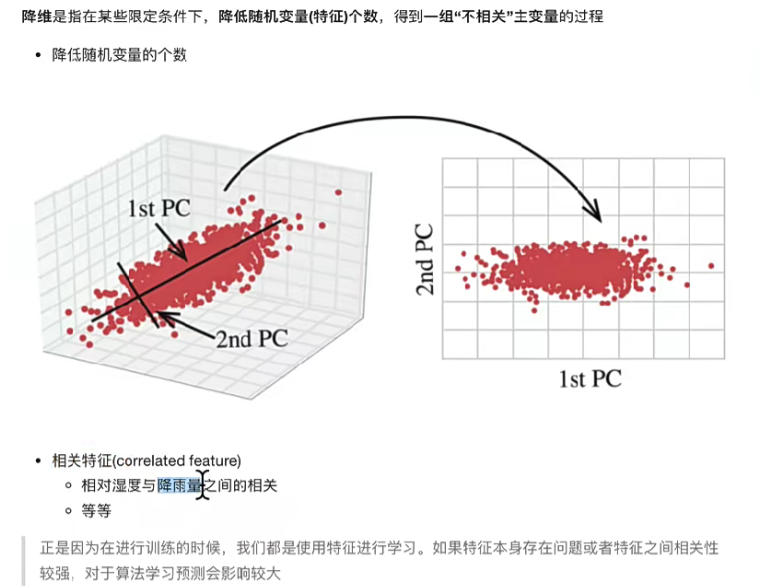
?方式主要是特征選擇和主成分分析(因子分析等)
2.特征選擇
2.1特征選擇定義
旨在從數據中包含的眾多特征(屬性、指標等)里,找出主要特征,剔除冗余或無關變量。例如分析鳥類相關數據時,羽毛顏色、眼睛寬度等都是可能的特征,需篩選出對研究目的(如區分鳥類種類等)有重要作用的特征 。
2.2特征選擇方法
- Filter(過濾式)也就是直接進行選擇:
- 方差選擇法:依據特征方差大小篩選。方差小意味著多數樣本在該特征上取值相近,對區分樣本作用小,可刪除。如
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)?,默認刪除所有樣本取值相同(方差為 0 )的特征,也可指定閾值,刪除方差低于該值的特征 。 - 相關系數:
- 皮爾遜相關系數:衡量兩變量線性相關程度,取值 [-1, 1] 。
r > 0?為正相關,r < 0?為負相關;|r| = 1?完全相關,r = 0?無相關;0 < |r| < 1?存在一定程度相關,|r|?越接近 1 線性關系越密切。可通過from scipy.stats import pearsonr?計算,返回相關系數和 p 值 。 - 斯皮爾曼相關系數:也是反映變量相關程度的統計指標,能表明變量相關方向,取值 [-1, 1] ,應用比皮爾遜相關系數更廣泛 ,計算使用
from scipy.stats import spearmanr?。
- 皮爾遜相關系數:衡量兩變量線性相關程度,取值 [-1, 1] 。
- 方差選擇法:依據特征方差大小篩選。方差小意味著多數樣本在該特征上取值相近,對區分樣本作用小,可刪除。如
- Embedded(嵌入式)也就是在某些算法中嵌入的:
- 決策樹:利用信息熵、信息增益等指標,在構建決策樹過程中自動選擇與目標值關聯緊密的特征 。
- 正則化:如 L1、L2 正則化,在模型訓練時通過約束參數,使部分特征系數趨近于 0 ,從而實現特征選擇 。
- 深度學習:如卷積神經網絡等,在訓練過程中自動學習數據特征,隱式進行特征選擇 。
2.3低方差特征過濾
- 原理:方差用于衡量數據的離散程度。在特征選擇中,若某個特征的方差很小,說明該特征在不同樣本間取值差異不大,對樣本區分能力弱,可視為冗余特征進行刪除。例如,在一個關于學生成績的數據集里,如果 “學生姓名筆畫數” 這個特征方差極小,說明該特征對區分學生成績好壞沒什么作用,就可考慮刪除。
- API 使用示例
import pandas as pd
from sklearn.feature_selection import VarianceThresholddef variance_demo():"""刪除低方差特征——特征選擇:return: None"""data = pd.read_csv("factor_returns.csv")print(data)# 1、實例化一個轉換器類,指定閾值方差為1transfer = VarianceThreshold(threshold=1)# 2、調用fit_transform進行轉換,這里選取data.iloc[:, 1:10]部分數據data = transfer.fit_transform(data.iloc[:, 1:10])print("刪除低方差特征的結果: \n", data)print("形狀: \n", data.shape)return None
2.4相關系數 - 皮爾遜相關系數
- 原理:皮爾遜相關系數衡量兩個變量之間的線性相關程度(皮爾遜低說明的是線性關系弱,并不代表相關性弱,可能還有非線性關系)。它基于變量的均值、標準差等統計量計算。當兩個變量的變化趨勢呈現同向線性關系時,相關系數為正;反向線性關系時,相關系數為負;若不存在線性關系,相關系數接近 0 。比如研究身高和體重的關系,若身高增加時體重也傾向于增加,皮爾遜相關系數為正。
- API 及案例
from scipy.stats import pearsonrx1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9]
x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5]
result = pearsonr(x1, x2)
print(result)
代碼中,從scipy.stats導入pearsonr函數,定義兩個數據列表x1和x2?,調用pearsonr計算二者的皮爾遜相關系數和 p 值,打印結果。這里得到的相關系數接近 0.994 ,說明x1和x2之間存在高度線性正相關關系,p 值極小表明這種相關性在統計上非常顯著。
2.5相關系數 - 斯皮爾曼相關系數
- 原理:斯皮爾曼相關系數是一種非參數統計量,它基于變量的秩次(排序位置)計算,反映變量之間的單調相關關系,不局限于線性關系。例如,研究學生考試成績排名和平時作業完成質量排名之間的關系,斯皮爾曼相關系數能有效衡量二者關聯程度。
- API 及案例
from scipy.stats import spearmanrx1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9]
x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5]
result = spearmanr(x1, x2)
print(result)
3.主成分分析(這里只將實現,具體原理參考李航機器學習)
PCA(主成分分析)API?
- 類定義:
sklearn.decomposition.PCA(n_components=None)?是用于主成分分析的類,主成分分析是一種常用的數據降維技術,目的是將高維數據轉換到較低維數空間,同時盡可能保留數據的關鍵信息。 - 參數
n_components?:- 小數形式:表示要保留數據信息的比例。例如
n_components = 0.9?,意味著 PCA 會自動確定一個合適的低維空間維度,使得轉換后的數據能夠保留原始數據 90% 的信息 。 - 整數形式:直接指定降維后數據的特征維度。如
n_components = 3?,就是將數據降到 3 維 。
- 小數形式:表示要保留數據信息的比例。例如
- 方法
fit_transform(X)?:X需是numpy array格式,形狀為[n_samples, n_features]?(n_samples是樣本數量,n_features是特征數量) 。該方法先對數據進行擬合(學習數據的分布特征等),再進行轉換(降維操作),返回降維后指定維度的數組 。
PCA 代碼示例
from sklearn.decomposition import PCAdef pca_demo():"""對數據進行PCA降維:return: None"""data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、實例化PCA,小數——保留多少信息transfer = PCA(n_components=0.9)# 2、調用fit_transformdata1 = transfer.fit_transform(data)print("保留90%的信息,降維結果為: \n", data1)# 1、實例化PCA,整數——指定降維到的維數transfer2 = PCA(n_components=3)# 2、調用fit_transformdata2 = transfer2.fit_transform(data)print("降維到3維的結果: \n", data2)return None









,實現多臺電腦共享鼠標和鍵盤(支持window系統))




初識 docker)




