Python繪制克利夫蘭點圖:從入門到實戰
引言
克利夫蘭點圖(Cleveland Dot Plot)是一種強大的數據可視化工具,由統計學家William Cleveland在1984年提出。這種圖表特別適合展示多個類別的數值比較,比傳統的條形圖更直觀、更精確。本文將詳細介紹如何使用Python創建克利夫蘭點圖,從基礎概念到實際應用。
什么是克利夫蘭點圖?
克利夫蘭點圖是一種簡潔而有效的數據可視化方式,它通過點和水平線的組合來展示數據。每個數據點都通過一條水平線連接到坐標軸,使得數據之間的比較更加直觀。
主要特點:
- 使用點和水平線展示數據
- 適合展示多個類別的數值比較
- 數據排序后更容易觀察趨勢
- 支持多數據系列的對比展示
環境準備
在開始之前,我們需要安裝必要的Python庫:
pip install matplotlib seaborn pandas numpy
代碼實現
讓我們通過實際的例子來學習如何創建克利夫蘭點圖。我們將使用matplotlib和seaborn來實現這個可視化效果。
1. 基礎設置
首先,我們需要導入必要的庫并設置中文字體支持:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
2. 準備數據
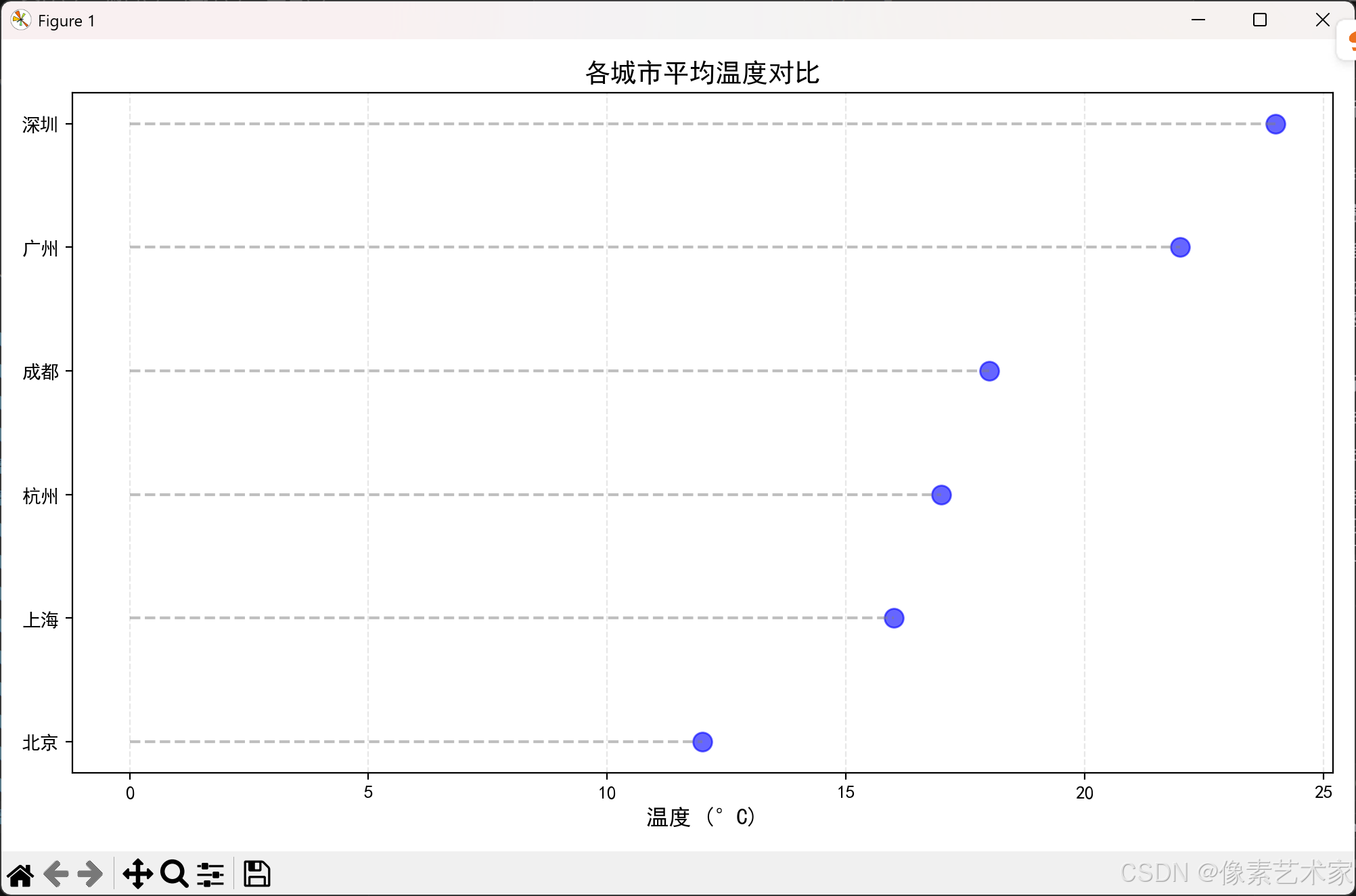
在我們的示例中,我們使用城市溫度數據來展示克利夫蘭點圖的效果:
# 示例數據:不同城市的平均溫度
cities = ['北京', '上海', '廣州', '深圳', '成都', '杭州']
temperatures = [12, 16, 22, 24, 18, 17]# 創建DataFrame
df = pd.DataFrame({'城市': cities,'溫度': temperatures
})# 按溫度排序
df = df.sort_values('溫度')
3. 創建基礎點圖
使用matplotlib創建基礎克利夫蘭點圖:
# 創建圖形
plt.figure(figsize=(10, 6))# 繪制點
plt.scatter(df['溫度'], range(len(df)), s=100, color='blue', alpha=0.6)# 添加水平線
for i, temp in enumerate(df['溫度']):plt.hlines(i, 0, temp, colors='gray', linestyles='--', alpha=0.5)# 設置y軸標簽
plt.yticks(range(len(df)), df['城市'])# 添加標題和標簽
plt.title('各城市平均溫度對比', fontsize=14)
plt.xlabel('溫度 (°C)', fontsize=12)# 添加網格線
plt.grid(True, axis='x', linestyle='--', alpha=0.3)
實際應用場景
克利夫蘭點圖在以下場景特別有用:
- 數據對比:比較不同類別之間的數值差異
- 趨勢分析:展示數據的變化趨勢
- 多維度分析:同時展示多個指標
- 時間序列對比:比較不同時間點的數據
進階技巧
1. 多數據系列對比
可以同時展示多個數據系列:
# 創建更復雜的示例數據
categories = ['產品A', '產品B', '產品C', '產品D', '產品E']
sales_2022 = [120, 85, 150, 95, 110]
sales_2023 = [140, 95, 160, 105, 130]# 創建DataFrame
df = pd.DataFrame({'類別': categories,'2022年': sales_2022,'2023年': sales_2023
})
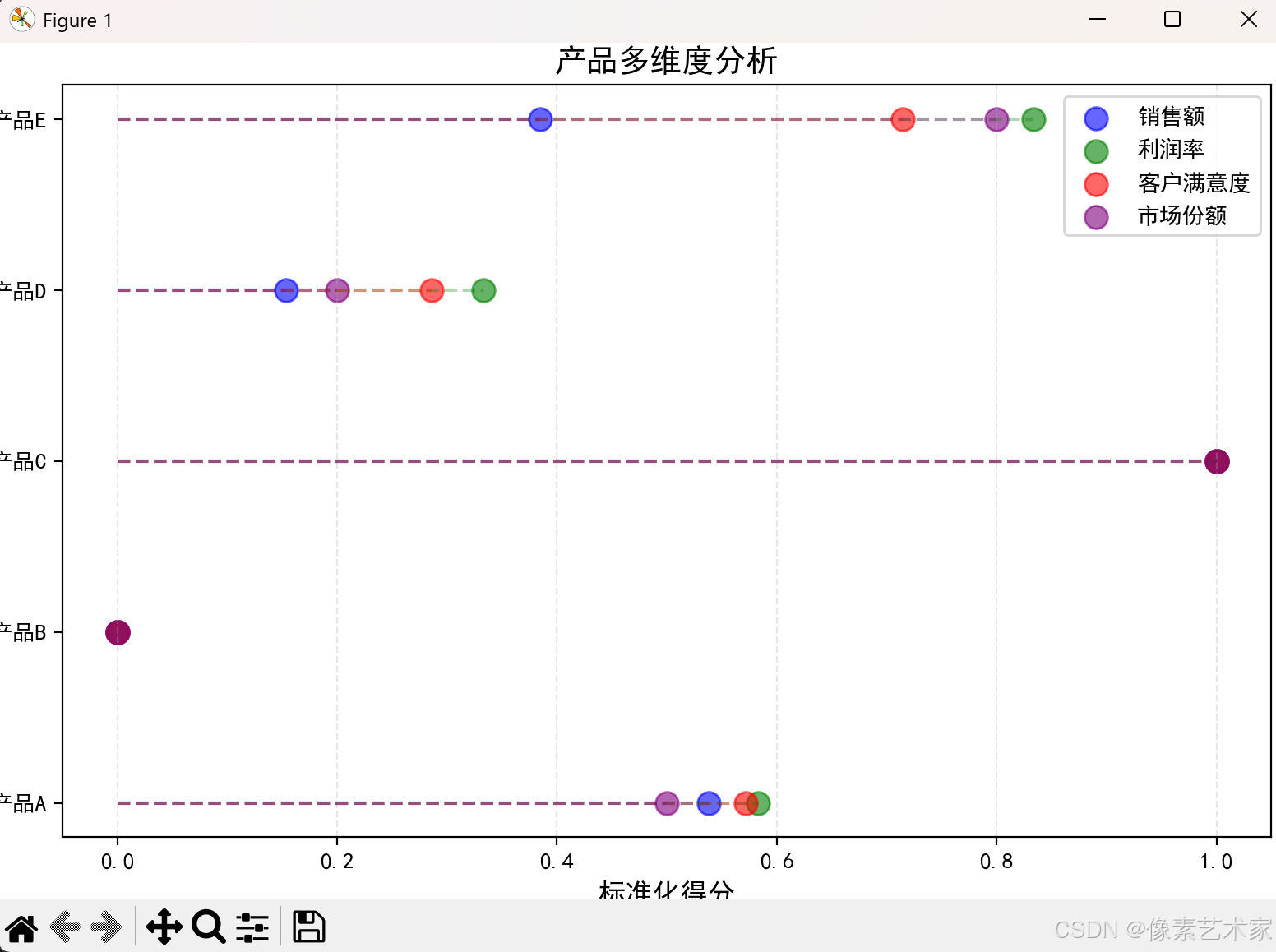
2. 多維度分析
展示產品的多個指標:
# 創建業務數據
products = ['產品A', '產品B', '產品C', '產品D', '產品E']
metrics = {'銷售額': [120, 85, 150, 95, 110],'利潤率': [25, 18, 30, 22, 28],'客戶滿意度': [4.2, 3.8, 4.5, 4.0, 4.3],'市場份額': [15, 10, 20, 12, 18]
}
3. 自定義樣式
可以通過修改各種參數來優化圖表外觀:
# 設置顏色
colors = ['blue', 'green', 'red', 'purple']# 設置透明度
alpha = 0.6# 設置點的大小
s = 100# 設置網格線樣式
plt.grid(True, axis='x', linestyle='--', alpha=0.3)
多數據序列演示
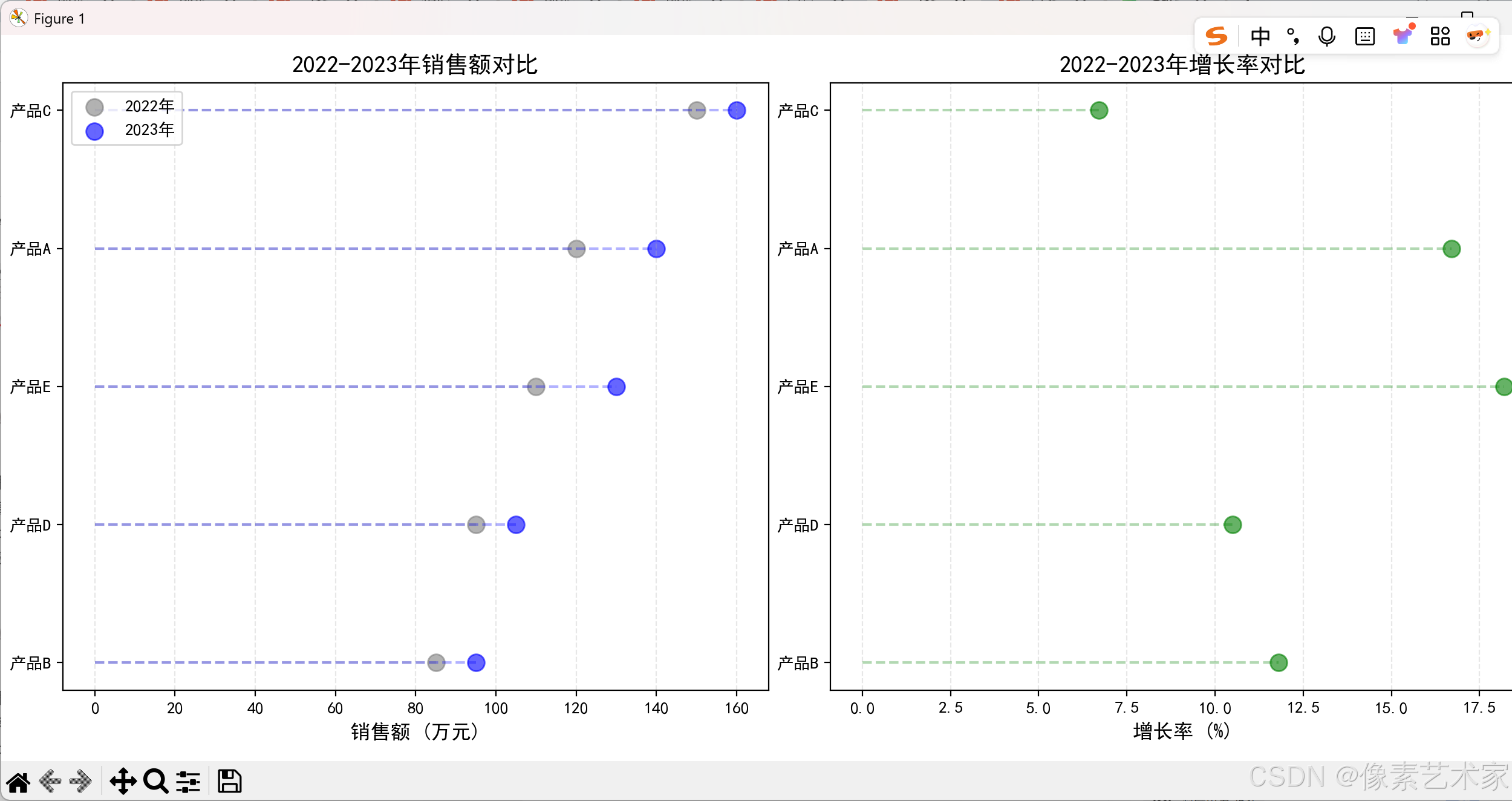
讓我們通過一個實際的例子來展示如何使用克利夫蘭點圖比較多個數據序列。這個例子將展示不同產品在2022年和2023年的銷售數據對比。
1. 數據準備
# 創建示例數據
categories = ['產品A', '產品B', '產品C', '產品D', '產品E']
sales_2022 = [120, 85, 150, 95, 110]
sales_2023 = [140, 95, 160, 105, 130]# 創建DataFrame
df = pd.DataFrame({'類別': categories,'2022年': sales_2022,'2023年': sales_2023
})# 計算增長率
df['增長率'] = ((df['2023年'] - df['2022年']) / df['2022年'] * 100).round(1)# 按2023年銷售額排序
df = df.sort_values('2023年')
2. 創建雙圖表對比
# 創建圖形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))# 繪制銷售額對比圖
for year, color in zip(['2022年', '2023年'], ['gray', 'blue']):ax1.scatter(df[year], range(len(df)), s=100, color=color, alpha=0.6, label=year)for i, value in enumerate(df[year]):ax1.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)ax1.set_yticks(range(len(df)))
ax1.set_yticklabels(df['類別'])
ax1.set_title('2022-2023年銷售額對比', fontsize=14)
ax1.set_xlabel('銷售額 (萬元)', fontsize=12)
ax1.legend()
ax1.grid(True, axis='x', linestyle='--', alpha=0.3)# 繪制增長率圖
ax2.scatter(df['增長率'], range(len(df)), s=100, color='green', alpha=0.6)
for i, rate in enumerate(df['增長率']):ax2.hlines(i, 0, rate, colors='green', linestyles='--', alpha=0.3)ax2.set_yticks(range(len(df)))
ax2.set_yticklabels(df['類別'])
ax2.set_title('2022-2023年增長率對比', fontsize=14)
ax2.set_xlabel('增長率 (%)', fontsize=12)
ax2.grid(True, axis='x', linestyle='--', alpha=0.3)plt.tight_layout()
plt.show()
3. 圖表解讀
這個多數據序列的克利夫蘭點圖展示了:
-
銷售額對比:
- 左側圖表展示了2022年和2023年的銷售額對比
- 使用不同顏色區分不同年份
- 通過水平線連接點,便于比較同一產品在不同年份的表現
-
增長率分析:
- 右側圖表展示了各產品的年度增長率
- 使用綠色表示增長情況
- 可以直觀看出哪些產品增長最快
-
數據排序:
- 按2023年銷售額排序,便于觀察產品表現
- 清晰的標簽和圖例,提高可讀性
4. 完整的多數據序列代碼
def create_multi_series_cleveland_plot():# 創建示例數據categories = ['產品A', '產品B', '產品C', '產品D', '產品E']sales_2022 = [120, 85, 150, 95, 110]sales_2023 = [140, 95, 160, 105, 130]# 創建DataFramedf = pd.DataFrame({'類別': categories,'2022年': sales_2022,'2023年': sales_2023})# 計算增長率df['增長率'] = ((df['2023年'] - df['2022年']) / df['2022年'] * 100).round(1)# 按2023年銷售額排序df = df.sort_values('2023年')# 創建圖形fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))# 繪制銷售額對比圖for year, color in zip(['2022年', '2023年'], ['gray', 'blue']):ax1.scatter(df[year], range(len(df)), s=100, color=color, alpha=0.6, label=year)for i, value in enumerate(df[year]):ax1.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)ax1.set_yticks(range(len(df)))ax1.set_yticklabels(df['類別'])ax1.set_title('2022-2023年銷售額對比', fontsize=14)ax1.set_xlabel('銷售額 (萬元)', fontsize=12)ax1.legend()ax1.grid(True, axis='x', linestyle='--', alpha=0.3)# 繪制增長率圖ax2.scatter(df['增長率'], range(len(df)), s=100, color='green', alpha=0.6)for i, rate in enumerate(df['增長率']):ax2.hlines(i, 0, rate, colors='green', linestyles='--', alpha=0.3)ax2.set_yticks(range(len(df)))ax2.set_yticklabels(df['類別'])ax2.set_title('2022-2023年增長率對比', fontsize=14)ax2.set_xlabel('增長率 (%)', fontsize=12)ax2.grid(True, axis='x', linestyle='--', alpha=0.3)plt.tight_layout()plt.show()if __name__ == '__main__':create_multi_series_cleveland_plot()
注意事項
- 數據量不宜過多,建議控制在10-15個類別以內
- 確保數據之間的差異足夠明顯
- 選擇合適的顏色方案,避免使用過于相似的顏色
- 添加適當的圖例和標簽
- 注意中文字體的顯示問題,確保系統安裝了所需的中文字體
總結
克利夫蘭點圖是一種強大的數據可視化工具,特別適合展示多個類別的數值比較。通過Python和matplotlib,我們可以輕松創建美觀且功能豐富的克利夫蘭點圖。在實際應用中,要根據具體需求選擇合適的展示方式,并注意數據的可讀性和美觀性。
完整代碼
完整的代碼實現如下,包含基礎示例和多數據序列示例:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef create_basic_cleveland_plot():"""創建基礎克利夫蘭點圖"""# 示例數據cities = ['北京', '上海', '廣州', '深圳', '成都', '杭州']temperatures = [12, 16, 22, 24, 18, 17]# 創建DataFramedf = pd.DataFrame({'城市': cities,'溫度': temperatures})# 按溫度排序df = df.sort_values('溫度')# 創建圖形plt.figure(figsize=(10, 6))# 繪制點plt.scatter(df['溫度'], range(len(df)), s=100, color='blue', alpha=0.6)# 添加水平線for i, temp in enumerate(df['溫度']):plt.hlines(i, 0, temp, colors='gray', linestyles='--', alpha=0.5)# 設置y軸標簽plt.yticks(range(len(df)), df['城市'])# 添加標題和標簽plt.title('各城市平均溫度對比', fontsize=14)plt.xlabel('溫度 (°C)', fontsize=12)# 添加網格線plt.grid(True, axis='x', linestyle='--', alpha=0.3)plt.tight_layout()plt.show()def create_multi_series_cleveland_plot():"""創建多數據序列克利夫蘭點圖"""# 創建示例數據categories = ['產品A', '產品B', '產品C', '產品D', '產品E']sales_2022 = [120, 85, 150, 95, 110]sales_2023 = [140, 95, 160, 105, 130]# 創建DataFramedf = pd.DataFrame({'類別': categories,'2022年': sales_2022,'2023年': sales_2023})# 計算增長率df['增長率'] = ((df['2023年'] - df['2022年']) / df['2022年'] * 100).round(1)# 按2023年銷售額排序df = df.sort_values('2023年')# 創建圖形fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))# 繪制銷售額對比圖for year, color in zip(['2022年', '2023年'], ['gray', 'blue']):ax1.scatter(df[year], range(len(df)), s=100, color=color, alpha=0.6, label=year)for i, value in enumerate(df[year]):ax1.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)ax1.set_yticks(range(len(df)))ax1.set_yticklabels(df['類別'])ax1.set_title('2022-2023年銷售額對比', fontsize=14)ax1.set_xlabel('銷售額 (萬元)', fontsize=12)ax1.legend()ax1.grid(True, axis='x', linestyle='--', alpha=0.3)# 繪制增長率圖ax2.scatter(df['增長率'], range(len(df)), s=100, color='green', alpha=0.6)for i, rate in enumerate(df['增長率']):ax2.hlines(i, 0, rate, colors='green', linestyles='--', alpha=0.3)ax2.set_yticks(range(len(df)))ax2.set_yticklabels(df['類別'])ax2.set_title('2022-2023年增長率對比', fontsize=14)ax2.set_xlabel('增長率 (%)', fontsize=12)ax2.grid(True, axis='x', linestyle='--', alpha=0.3)plt.tight_layout()plt.show()def create_multi_metrics_cleveland_plot():"""創建多維度指標克利夫蘭點圖"""# 創建業務數據products = ['產品A', '產品B', '產品C', '產品D', '產品E']metrics = {'銷售額': [120, 85, 150, 95, 110],'利潤率': [25, 18, 30, 22, 28],'客戶滿意度': [4.2, 3.8, 4.5, 4.0, 4.3],'市場份額': [15, 10, 20, 12, 18]}# 創建DataFramedf = pd.DataFrame(metrics, index=products)# 標準化數據df_normalized = (df - df.min()) / (df.max() - df.min())# 創建圖形plt.figure(figsize=(12, 8))# 為每個指標繪制點colors = ['blue', 'green', 'red', 'purple']for (metric, color) in zip(metrics.keys(), colors):plt.scatter(df_normalized[metric], range(len(products)), s=100, color=color, alpha=0.6, label=metric)for i, value in enumerate(df_normalized[metric]):plt.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)plt.yticks(range(len(products)), products)plt.title('產品多維度分析', fontsize=14)plt.xlabel('標準化得分', fontsize=12)plt.legend()plt.grid(True, axis='x', linestyle='--', alpha=0.3)plt.tight_layout()plt.show()if __name__ == '__main__':print("運行基礎克利夫蘭點圖示例...")create_basic_cleveland_plot()print("\n運行多數據序列克利夫蘭點圖示例...")create_multi_series_cleveland_plot()print("\n運行多維度指標克利夫蘭點圖示例...")create_multi_metrics_cleveland_plot()
這個完整的代碼包含了三個主要函數:
create_basic_cleveland_plot(): 創建基礎克利夫蘭點圖create_multi_series_cleveland_plot(): 創建多數據序列克利夫蘭點圖create_multi_metrics_cleveland_plot(): 創建多維度指標克利夫蘭點圖
運行代碼時會依次展示這三種不同類型的克利夫蘭點圖,幫助讀者理解不同場景下的應用。
參考資料
- Matplotlib官方文檔
- 數據可視化最佳實踐指南
- Cleveland Dot Plot的歷史與應用
希望這篇文章能幫助你理解并掌握克利夫蘭點圖的創建方法。如果你有任何問題或建議,歡迎在評論區留言討論。













)





