? ? ? ? 之前的版本是個意思意思,驗證商店發布的(其實是我以前自己用的工具),這次把格式檢查和轉換都做上了,功能應該差不多了,還有一些需要小改進的地方。
? ? ? ? 因為還沒什么用戶嘛,還是保持全功能免費試用。(真的是為了交個朋友)
目錄
一、從Microsoft Store安裝
二、從github獲取源碼
三、運行
四、新增功能
4.1 預覽和編碼選擇
4.2 輸出格式選擇
4.3 編碼保存
五、關于文本格式的知識
5.1 行結束符
5.2 字符編碼
5.3 字符格式
5.4 BOM
5.5 代碼頁
一、從Microsoft Store安裝

? ? ? ? Microsoft Store下載鏈接:ctDos2Unix - Download and install on Windows | Microsoft Store
? ? ? ? 打開此網頁,從這里進入商店,可以免費安裝試用版(網頁里可能不會顯示“免費試用”),試用版沒有期限并且和正式版沒有區別(不理解是吧,這是我用來做應用上架練習的。)
二、從github獲取源碼
codetoys/Dos2Unix: txt tools ,Encoding conversion
https://github.com/codetoys/Dos2Unix?
? ? ? ? 當然,此源碼不包含用來打包MSIX的項目,僅包含程序本身的源碼。
? ? ? ? 簡單程序,只有一個exe文件,依賴.net framework 4.8,應該不用額外安裝。
? ? ? ? 程序僅保存一個屬性,具體保存在哪里你要看Properties.Settings.Default.Save()怎么回事了(一般在AppData的Local下面)。
? ? ? ? 用visual studio 2022打開sln文件即可。
三、運行
????????安裝后會有個開始菜單項(Microsoft Store的標準行為),直接編譯源代碼就是直接運行就行了。
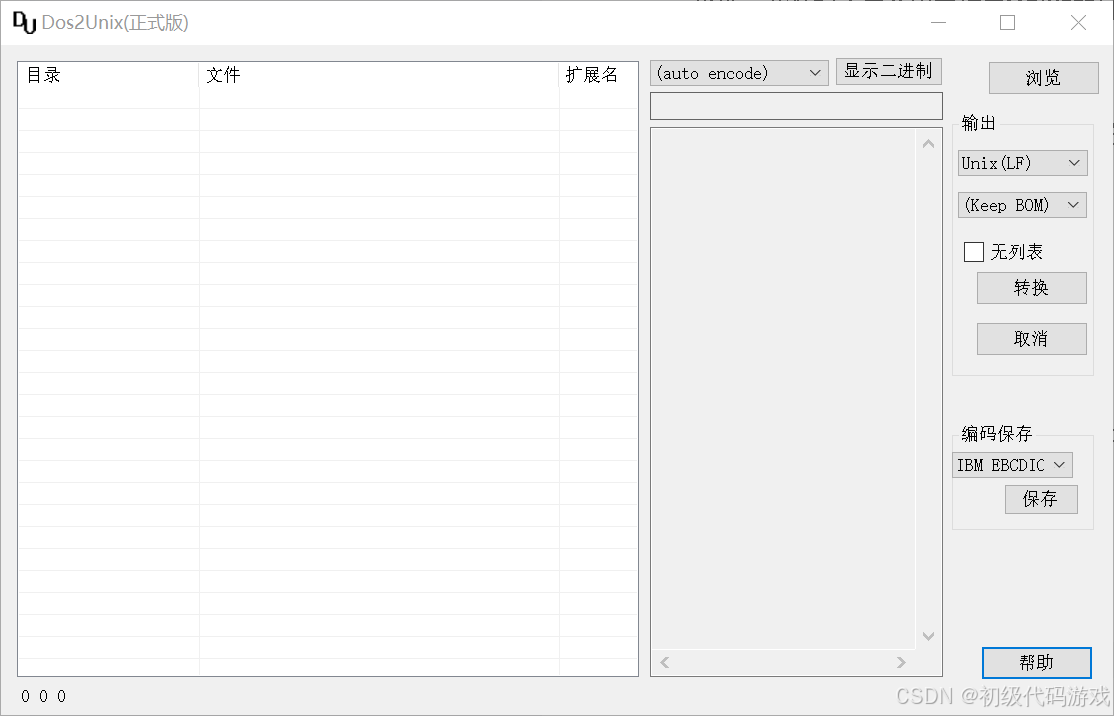
? ? ? ? 試用版和正式版唯一的區別是標題欄上顯示的是“試用版”。
四、新增功能
4.1 預覽和編碼選擇
? ? ? ? 界面分三部分:列表顯示區、預覽區、按鈕區。
????????點擊按鈕“瀏覽”選擇一個目錄,會把目錄里的所有文件都顯示在左邊列表中,列表的選中項在中間的預覽區自動顯示預覽。
????????默認根據檢測到的編碼顯示,如果有亂碼(有些編碼無法自動檢測),可以手動指定編碼。
????????也可以顯示二進制。二進制顯示盡量根據檢測到的編碼來處理回車換行,要注意回車和換行都會導致換行顯示,這一點與文本顯示方式不同。
4.2 輸出格式選擇
? ? ? ? 可以選擇DOS/UNIX/MAC行尾格式,可以選擇添加BOM或刪除BOM,這兩個選項都可以選擇“保持原樣”,不做改變。
4.3 編碼保存
? ? ? ? 使用指定的編碼直接保存。注意這個功能現在是沒有自動備份的,我下個版本加上。
五、關于文本格式的知識
5.1 行結束符
? ? ? ? DOS(Windows)在內存中使用一個“\n”表示換行,存儲到文件則為“\r\n”。UNIX(Linux)則為“\n”,Mac(蘋果電腦)卻是“\r”,真是想不通。
? ? ? ? 因為這種區別,ftp工具一般都有指定那些文件后綴名是文本文件的設置,以此來自動識別文件文件,供傳輸時做格式轉換。當然ftp工具也有強制使用二進制或文本模式的功能。
? ? ? ? 一般我們自己寫程序讀文件這幾種行結束符都兼容,因為多了判斷,效率稍低。
? ? ? ? 而系統提供的行讀取函數則不兼容不同的行結束符,因此可能會導致錯誤。
? ? ? ? 像我們程序員經常在網上復制粘貼代碼的,文件里行結束符不一致的情況也很多,這都可能出問題。
? ? ? ? 所以批量檢測、轉換文件格式是很重要的。
5.2 字符編碼
? ? ? ? 字符編碼最初是面向硬件的啊!一個編碼輸出給一個硬件,硬件就顯示一個字符給你看,所以一種編碼其實是對統一標準的硬件的。后來ASCII碼成了英文字符的主流。最初沒有中文啊。
? ? ? ? 后來就有了中文顯示了,因為ASCII只用了每個字節的低七位,最高位總是0,所以中文等語言選擇使用最高位為1來編碼,用連續兩個字節表達一個本地字符。這樣就兼容ASCII碼,純ASCII文件可以正常顯示,含有本地編碼字符的文件在純英文系統上會亂碼。
? ? ? ? 這種本地編碼大家都選擇了類似的方式,雖然方便但是本地編碼之間互相交流成了問題。因為編碼規則一樣嘛,但是同一個本地編碼(兩個高位為1的字節)含義完全不相干,顯示為亂碼的時候你只能瞎猜,一個一個試過去,湊巧對了就不亂碼了(但是你不認識的語言也容易猜測是不是對了)。
? ? ? ? 中文分為國標和大五兩個系列,GB后面數字大的是較新的版本,兼容數字小的。GB2312已經過時了,但是大家還是習慣叫這個。
? ? ? ? 本地編碼非常不利于國際交流嘛,所以大家坐到一起商量了一下,搞了個大一統的UNICODE,宇宙字符集。宇宙字符集把所有現有字符都納入了,而且可以無限擴充。
5.3 字符格式
? ? ? ? 在unicode出現以前,字符都是單字節,本地編碼用兩個連續字符表示一個字符(所以支持的字符數是有限的),計算字符數(不是字節數)需要一個字節一個字節判斷,比較麻煩。
? ? ? ? unicode出現以后情況有所不同,因為大部分UNICODE字符兩字節就可以表達,于是就想啊,用unsigned short int來表達字符會不會簡單啊,這樣基本上一個unsigned short int就是一個字符,計算比較簡單(雖然不是絕對,但應付大部分情形是沒問題的),這個就是UTF-16,windows內核表達方法。
? ? ? ? unicode其實有多種字符格式。
????????utf-7只用每個字節的低七位,要連續多個字節來表達一個字符,這種格式現在很少見到了。
? ? ? ? utf-8與本地編碼類似,兼容ASCII,但是又容易和本地編碼混。不過utf-8每個字節前幾位是有規定的,指示了字符包含幾個字節,這樣比較容易檢測(本地編碼除了最高位為1沒有別的標志)。
? ? ? ? utf-32用unsigned int來表達字符,基本上現有的字符都是一個unsigned int,太完美了。但是要多用很多字節啊。
5.4 BOM
? ? ? ? BOM就是文件最前面用來指示格式的特殊標記。
? ? ? ? 為什么要有這個呢?因為對于utf-16和utf-32,使用short 和int來表示字符,同一個short或int在不同字節順序的機器上是不一樣的,所以需要有一個標記來指示。
? ? ? ? 因為這個東西沒有統一規范,windows有,unix沒有,混亂就這樣形成了。
? ? ? ? windows還給utf-8也弄了一個BOM。憑良心說呢,大家都有BOM的話,確實減少很多混亂。但是沒法子,現實無比混亂啊。
5.5 代碼頁
? ? ? ? 代碼頁就是上面說的字符編碼和字符格式的組合(各種本地編碼和不同格式的unicode),但是不包含是否包含BOM(也就是說windows上默認都是帶的)。
(這里是文檔結束)



)















