交叉熵損失函數(Cross-Entropy Loss)
交叉熵損失函數,涉及兩個概念,一個是損失函數,一個是交叉熵。
首先,對于損失函數。在機器學習中,損失函數就是用來衡量我們模型的預測結果與真實結果之間“差距”的函數。這個差距越小,說明模型的表現越好;差距越大,說明模型表現越差。我們訓練模型的目標,就是通過不斷調整模型的參數,來最小化這個損失函數。以一個生活化的例子舉例,想象一下你在教一個孩子識別貓和狗。孩子每次猜對或猜錯,你都會給他一個“評分”。如果他猜對了,評分就很高(損失很小);如果他猜錯了,評分就可能很低(損失很大)。
在明白完損失函數后,就要理解交叉熵了,在理解交叉熵之前我們又要了解何為熵。熵在信息論中是衡量一個隨機變量不確定性(或者說信息量)的度量。不確定性越大,熵就越大。根據信息論中的香農定理,我們可以得出熵的計算公式為:
![]()
其中,P(xi)是事件xi發生的概率。- log(P(xi))?表示信息量,根據公式我們可以知道信息量大小與概率成負相關,概率越小的時間其信息量越大,如飛機失事;概率越大的時間其信息量越小,如太陽從東邊升起。
談完熵之后,我們來開始理解何為交叉熵?
交叉熵是衡量兩個概率分布之間“相似性”的度量。更準確地說,它衡量的是,當我們使用一個非真實的概率分布 Q 來表示一個真實的概率分布 P 時,所需要付出的“代價”或“信息量”。交叉熵的計算公式為:
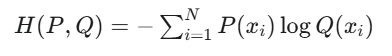
注意,這里的 P(xi?) 通常是one-hot編碼形式,即在分類問題中,只有真實類別對應的 P(xi?) 為1,其他為0。
二分類交叉熵
在二分類問題中,當你的模型需要判斷一個輸入是A類還是B類(比如是貓還是狗,是垃圾郵件還是正常郵件)時,你會使用二分類交叉熵。
- 真實標簽 (y): 通常用0或1表示。例如,貓是1,狗是0。
- 模型預測概率 (
): 模型輸出的屬于類別1的概率,通常通過Sigmoid激活函數得到,范圍在0到1之間。
二分類交叉熵公式為:
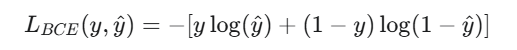
直觀理解:
- 如果真實標簽 y=1(比如是貓):損失函數變為 ?log(
- 如果真實標簽 y=0(比如是狗):損失函數變為 ?log(1?
多分類交叉熵
當你的模型需要判斷一個輸入是N個類別中的哪一個(比如是貓、狗、還是鳥)時,你會使用多分類交叉熵。
- 真實標簽 (y): 通常是one-hot編碼。例如,貓是 [1,0,0],狗是 [0,1,0],鳥是 [0,0,1]。
- 模型預測概率 (
多分類交叉熵的公式為:
![]()
其中,N 是類別的數量,yi? 是真實標簽中第 i 個類別的指示(0或1),?i? 是模型預測第 i 個類別的概率。
直觀理解:
- 由于真實標簽 y 是one-hot編碼,只有真實類別 k 對應的 yk? 是1,其他 yi? 都是0。所以,這個求和公式實際上只計算了真實類別對應的預測概率的負對數。
- 舉例:如果真實標簽是貓 [1,0,0],模型預測是 [0.8(貓),0.1(狗),0.1(鳥)]。 損失 =?(1?log(0.8)+0?log(0.1)+0?log(0.1))=?log(0.8)。 如果模型預測是 [0.1(貓),0.8(狗),0.1(鳥)]。 損失 =?(1?log(0.1)+0?log(0.8)+0?log(0.1))=?log(0.1)。 顯然,?log(0.1) 比 ?log(0.8) 要大很多,說明模型預測貓的概率很低時,損失會很大,這符合我們的直覺。
KL散度(Kullback-Leibler Divergence)
KL散度和交叉熵很像,只不過交叉熵是硬標簽,KL散度是軟標簽,因此KL散度也稱為相對熵,是衡量兩個概率分布 P 和 Q 之間差異的非對稱度量。它量化了當使用概率分布 Q 來近似概率分布 P 時所損失的信息量。KL散度主要用于拉近真實分布和近似分布的表達,去讓近似分布盡可能接近真實分布,因為越近似,其除法越近于1,log()越接近于0。其計算公式為:
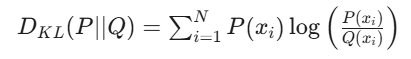
其中,P為真實分布?,Q為近似分布 。我們將其展開,可得到以下公式:
![]()
可以看到當P(xi)為1時,這時就變成交叉熵了。
KL散度特性
- 非負性(涉及數學的非負性證明):KL?(P∣∣Q)≥0(因為P和Q不相等的話,即P/Q>1),只有當 P 和 Q 是完全相同的分布時(此時P/Q = 1),KL?(P∣∣Q)=0。
- 非對稱性:KL?(P∣∣Q)?不等于?KL?(Q∣∣P) 。KL?(P∣∣Q)是懲罰 Q 在 P 概率高的地方給出低概率。KL?(Q∣∣P)懲罰 Q 在 P 概率低的地方給出高概率。
- 度量的是“信息損失”: 它衡量的是當你用 Q 來編碼 P 時,額外需要多少比特的信息。
交叉熵損失函數和KL散度總結
- 交叉熵損失函數適用于分類任務,基于硬標簽,目的是衡量模型預測的概率分布與真實標簽的概率分布之間的“距離”。它的目標是讓模型對真實類別的預測概率盡可能高。
- KL散度適用于衡量兩個概率分布之間的差異,是非對稱的,多用于概率模型,用于強制模型學習到的分布與某個先驗分布接近,或衡量兩個復雜分布之間的相似性。
)
















:Java的反射機制)

