文章目錄
- 引言
- 什么是監控
- 三大常見監控類型
- 1. 次數監控
- 2. 性能監控
- 3. 可用率監控
- 落地監控
- 1. 服務入口
- 2. 服務內部
- 3. 服務依賴
- 監控時間間隔的取舍
- 小結

引言
架構思維:通用架構模式_從設計到代碼構建穩如磐石的系統
架構思維:通用架構模式_穩如老狗的SDK設計最佳實踐
架構思維:通用架構模式_懷疑下游的設計思路與最佳實踐
我們以“防備上游、做好自己、懷疑下游”的準則,分別從系統設計、部署和代碼層面,介紹了如何構建高可用后臺系統。但再完善的防護也難保萬無一失,真正的挑戰在于在用戶感知之前,第一時間發現問題。
接下來我們將從監控的角度出發,教你如何設計微服務監控,幫助快速、自動地暴露故障,保障系統穩定運行。
什么是監控
監控是指對系統運行狀態數據持續審查,并設定閾值,對超出閾值的指標發出告警的機制。如下所示,監控數據通常以 時間(X 軸) 與 指標值(Y 軸) 的曲線圖形式展示:
X 軸:時間間隔(秒或分鐘)
Y 軸:該間隔內匯聚的指標(數量、平均值、最大值等)
三大常見監控類型
1. 次數監控
用于統計某個事件或方法的調用次數,比如接口被調用次數、某段邏輯執行次數。
圖 2:次數監控示例
Y 軸:指定間隔內總調用次數
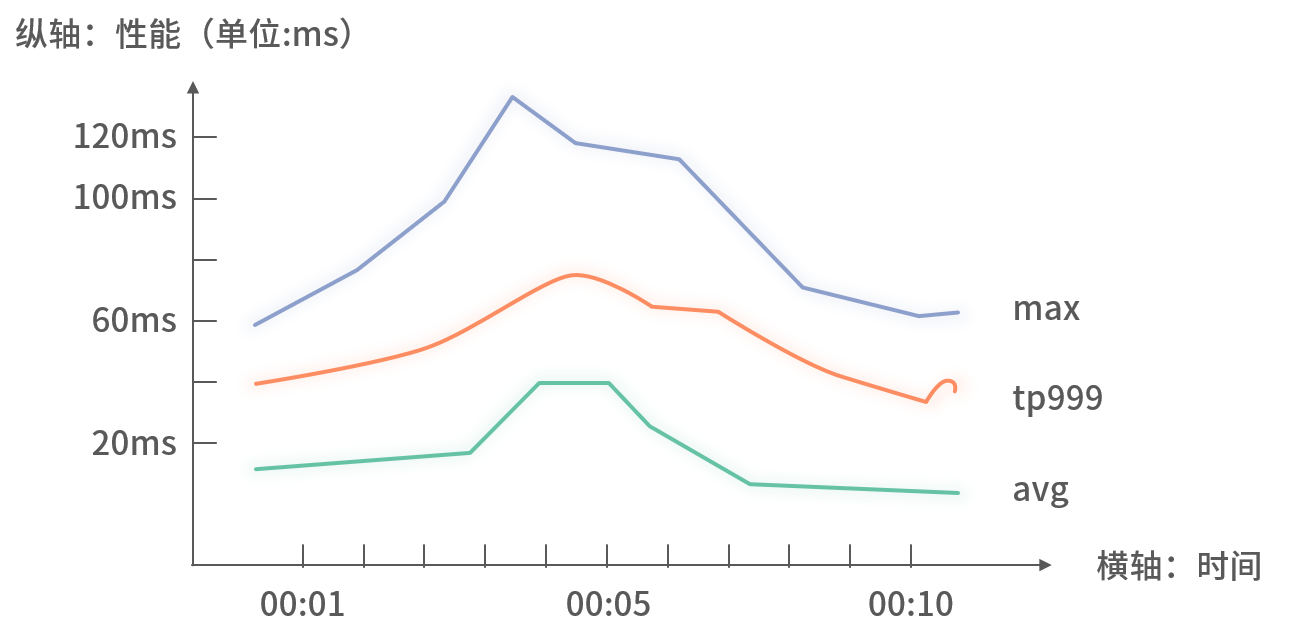
2. 性能監控
關注接口或依賴調用的延遲,常用指標有:
- 平均耗時(AVG) = 總耗時 / 調用次數
- 最大耗時(Max) = 區間內單次最長耗時
- TPn(如 TP999)= 排序后第 n‰ 位置的耗時值
通常將 Avg、Max、TP99X 三者合并展示:
3. 可用率監控
計算指定區間內業務執行成功的比例。
在可用率判斷中,要區分:
- 業務異常(如參數校驗失敗):不算失敗,不降可用率
- 非業務異常(如網絡超時、空指針):算失敗,需降可用率并報警
閾值設置需結合接口級別和 SLA,核心接口可設 100%,其他接口可適當放寬。
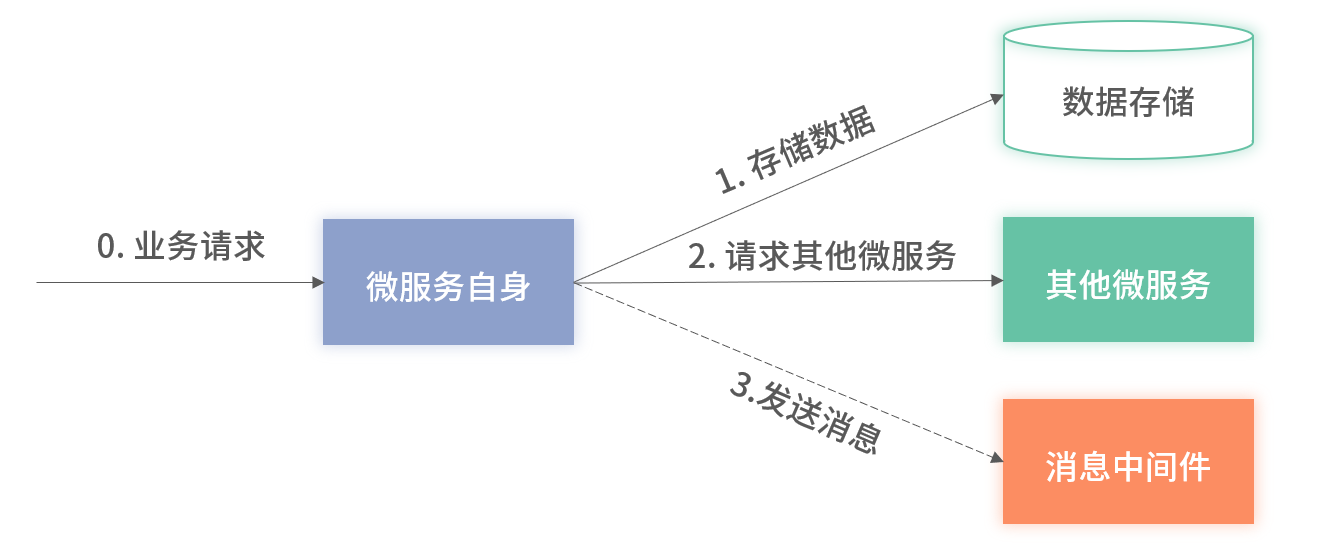
落地監控
業務
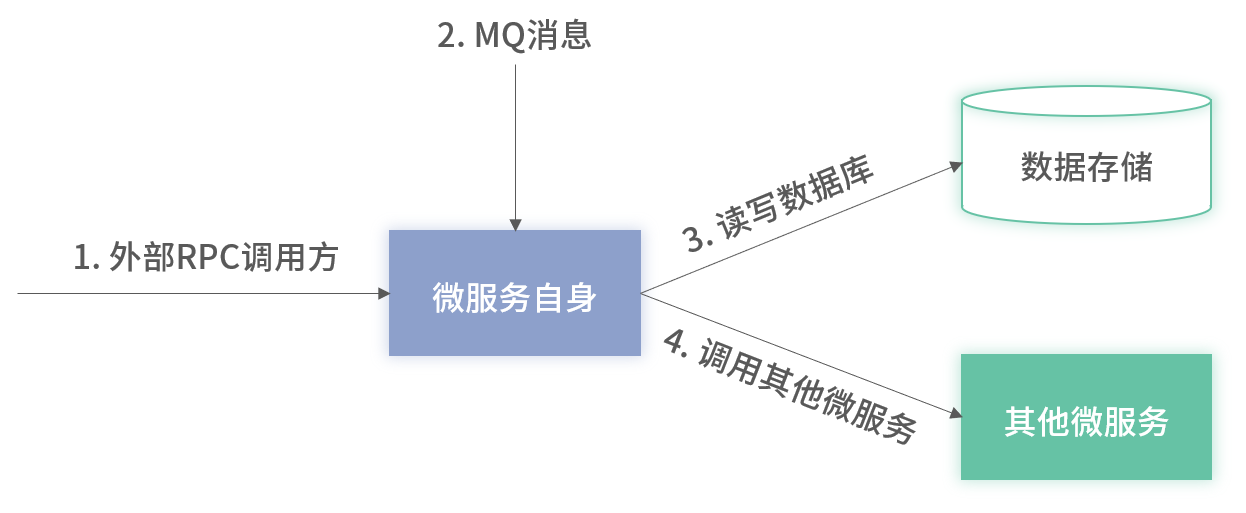
1. 服務入口
-
次數監控
- 基于壓測瓶頸設閾值告警,并配合限流
- 按調用方維度統計,快速定位流量異常來源
- 同環比監控,自動識別突增
-
性能監控
- 必要時只告警 Avg、Max、TP999(或 TP9999)
- 按調用方分層監控,排查使用差異
- 基于入參(如批量大小)分段監控,輔助優化策略
-
可用率監控
- 接口級與調用方級雙重告警
- 按業務/非業務異常判定成功與否
- 閾值分級:重要接口近乎 100%,普通接口可降至 95%
2. 服務內部
- 聚焦核心與可疑方法,避免監控點過多導致告警疲勞
- 監控 JVM(Young/Full GC、堆內存使用)、RPC 線程池剩余數、進程存活狀態
- 機器層面:CPU、內存使用率與負載(Load)監控
3. 服務依賴
- 對每個下游依賴統一埋點監控(可用率、性能、次數)
- 注意解析 RPCResult 等包裝返回,防止“隱性”失敗漏報
- Java 應用可通過 AOP 或框架攔截(如 MyBatis Interceptor)統一實現
監控時間間隔的取舍
- 秒級監控最優,能最快暴露故障
- 但存儲成本高(1s 數據量是 1min 的 60 倍)
- 若系統同時支持秒級和分鐘級,生產環境推薦秒級,測試或存儲受限時可降至分鐘級
小結
- 三大基礎指標:次數、性能、可用率
- 三層架構落地:入口、內部、依賴
- 補充監控:JVM、線程池、進程、機器資源
- 閾值與時序:結合 SLA、接口重要度,優先秒級

:深入剖析用戶生成內容(UGC)商業模式)
)




![[Java實戰]Spring Boot 整合 Redis(十八)](http://pic.xiahunao.cn/[Java實戰]Spring Boot 整合 Redis(十八))

)

 網絡服務配置(web))







)
