TTS聲學編解碼器的演進
- 1 引言:聲碼器/聲學編解碼器在現代TTS中的關鍵作用
- 2 奠定基石:從早期聲碼器到神經合成的曙光
- 3. HiFi-GAN: 革新高效高保真波形生成
- 4. 新的疆域:面向富語義TTS的先進聲學編解碼器
- 5. XCodec2.0: 統一聲學與語義信息
- 6.BiCodec: 為Spark-TTS打造可控的解耦令牌
- 7.總結
1 引言:聲碼器/聲學編解碼器在現代TTS中的關鍵作用
語音合成(Text-to-Speech, TTS)技術的核心目標之一是生成高度自然、富有表現力且與真人無異的語音。在這一追求中,聲碼器(Vocoder),或更廣義地說,聲學編解碼器(Acoustic Codec)/語音令牌化器(Speech Tokenizer),扮演著至關重要的角色。它的性能直接決定了合成語音的最終質量、自然度乃至可控性 。
回顧歷史,聲碼器的概念最早可追溯至貝爾實驗室的Homer Dudley,其初衷在于分析和合成人類語音,并用于節省電信帶寬 。早期的聲碼器,如通道聲碼器和后來的線性預測編碼(LPC) ,奠定了參數化語音合成的基礎。然而,這些傳統方法合成的語音往往帶有明顯的“機器味”,難以滿足日益增長的對自然度的高要求。
隨著深度學習的浪潮,神經聲碼器應運而生,徹底改變了TTS的面貌。它們不再局限于簡單的參數到波形的轉換,而是能夠從聲學特征(如梅爾頻譜)生成高質量的原始波形。近年來,隨著大型語言模型(LLM)在TTS領域的廣泛應用,聲學編解碼器的角色進一步擴展。它們不僅負責最終的波形生成,更重要的是,它們需要將連續的語音信號分析、壓縮并表示為離散的聲學令牌(acoustic tokens),這些令牌需要足夠豐富以捕捉聲音細節、說話人特征乃至語義信息,從而作為LLM的輸入或輸出 。
這種演變體現了“聲碼器”概念的擴展。傳統意義上的聲碼器,如在統計參數語音合成(SPSS) 或早期神經聲碼器中,主要承擔從相對固定的聲學特征(例如梅爾頻譜)到波形的轉換任務。HiFi-GAN便是一個典型的例子,它高效地將梅爾頻譜圖轉換為高質量波形 。
然而,XCodec2和BiCodec等新一代模型則更像是完整的“聲學編解碼器”或“語音令牌化器”。它們不僅包含將令牌解碼回波形的“合成”部分,更強調將原始音頻“分析”和“表示”為適合LLM處理的離散令牌序列,這些令牌往往承載了遠超基本聲學特征的韻律、情感、語義及說話人身份等信息 。這意味著聲學編解碼器不再僅僅是TTS流程末端的渲染模塊,而是深度融入LLM驅動的語音生成核心,負責構建一個更全面、更易于控制的語音表示。
2 奠定基石:從早期聲碼器到神經合成的曙光
在深入探討現代神經聲碼器之前,有必要回顧一下那些為語音合成技術奠定基礎的早期概念和系統。
-
歷史的足跡:基礎概念
- Homer Dudley的聲碼器 (1938年): 這項發明標志著聲碼器歷史的開端。Dudley在貝爾實驗室的工作旨在分析和合成人類語音,其原理是通過一組帶通濾波器(濾波器組)分析語音信號的頻譜包絡,并提取激勵信號(基頻和噪聲),然后在合成端利用這些參數重建語音 。這一發明不僅為語音合成提供了新思路,也為語音壓縮和加密通信(如二戰期間的SIGSALY系統)鋪平了道路 。
- Voder (1939年): 作為聲碼器解碼器部分的演示裝置,Voder在1939年的紐約世博會上向公眾展示了機器合成語音的能力。操作員通過鍵盤和踏板控制聲源和濾波器,模擬產生元音和輔音 。
- 線性預測編碼 (LPC): 20世紀60、70年代發展起來的LPC技術是語音編碼和合成領域的重大突破。LPC通過一個全極點濾波器來模擬聲道特性,用一組預測系數來描述頻譜包絡 。它比早期的通道聲碼器更為高效,并成為許多早期語音合成芯片(如著名的德州儀器Speak & Spell玩具)的核心技術 。
- 統計參數語音合成 (SPSS): 在深度學習興起之前,SPSS是主流的語音合成范式。它通常包括文本分析、聲學參數預測(如基頻F0、頻譜參數如梅爾倒譜系數MGC、帶非周期性參數BAP)和波形合成三個階段。其中,波形合成階段依賴于參數聲碼器,如STRAIGHT和WORLD,它們根據預測出的聲學參數重建語音波形 。盡管SPSS在可懂度和可控性上有所進步,但合成語音往往帶有明顯的“蜂鳴聲”或“機器味”,自然度欠佳。
-
神經革命的號角:
- WaveNet (DeepMind, 2016年): WaveNet的出現標志著語音合成領域的一次范式革命。它是一個自回歸的深度生成模型,使用帶孔洞的因果卷積直接在原始音頻波形上逐樣本點進行預測 。
- 重大意義: WaveNet生成的語音在自然度和音質上達到了前所未有的水平,顯著超越了傳統的SPSS聲碼器。
- 嚴峻挑戰: 由于其逐樣本點的自回歸特性,WaveNet的合成速度非常緩慢,難以滿足實時應用的需求。
- WaveRNN (2018年) 及類似的基于RNN的方法: 為了解決WaveNet的效率問題,研究者們提出了WaveRNN等模型。它們通常采用更緊湊的循環神經網絡(RNN)結構,在保持較高音質的同時,試圖提升合成效率 。
- 向非自回歸模型的邁進: 自回歸模型的計算瓶頸催生了對并行波形生成方法的研究。這直接導致了基于生成對抗網絡(GAN)、流模型(Flow-based)以及后來的擴散模型(Diffusion-based)的非自回歸聲碼器的興起 。
- WaveNet (DeepMind, 2016年): WaveNet的出現標志著語音合成領域的一次范式革命。它是一個自回歸的深度生成模型,使用帶孔洞的因果卷積直接在原始音頻波形上逐樣本點進行預測 。
在聲碼器的發展歷程中,對更高感知質量和更快合成速度的追求始終是一對核心矛盾和主要驅動力。SPSS聲碼器雖然相對較快,但音質不盡如人意 。WaveNet通過逐樣本點的自回歸生成方式,實現了極高的音質,但犧牲了合成速度 。隨后,WaveRNN等工作試圖在自回歸框架內優化速度 。真正的速度飛躍來自于非自回歸模型,它們旨在達到與WaveNet相媲美的音質,同時實現并行生成,HiFi-GAN便是成功平衡這一矛盾的典范 。即便是HiFi-GAN本身,其不同版本也在模型大小、速度和質量之間提供了不同的權衡方案 。這種持續的平衡探索,極大地推動了模型架構、訓練技術和損失函數設計的創新,不斷拓展著實時高保真語音合成的可能性邊界。
3. HiFi-GAN: 革新高效高保真波形生成
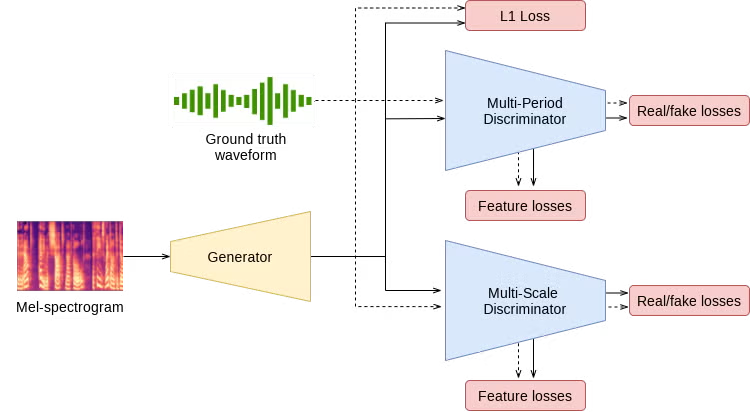
HiFi-GAN (High-Fidelity Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis) 的提出,旨在解決先前GAN聲碼器在音質上難以匹敵自回歸模型,同時保持高效性的難題 。其核心理念在于,對語音信號中存在的周期性模式進行建模,對于提升合成樣本的質量至關重要 。
-
架構深度解析:
- 生成器 (Generator, G):
- 采用全卷積神經網絡結構,輸入為梅爾頻譜圖。
- 通過一系列轉置卷積(transposed convolutions)進行上采樣,以匹配原始波形的時間分辨率。
- 多感受野融合模塊 (Multi-Receptive Field Fusion, MRF): 這是HiFi-GAN的一項核心創新。MRF模塊將多個殘差塊(residual blocks)的輸出相加,每個殘差塊具有不同的卷積核尺寸和空洞率(dilation rates)。這種設計使得生成器能夠并行地觀察不同長度的模式,從而增強其對復雜音頻結構的建模能力 。
- 判別器 (Discriminators, D): HiFi-GAN巧妙地設計了兩種判別器,從不同角度評估生成的音頻。
- 多周期判別器 (Multi-Period Discriminator, MPD):
- 由多個子判別器組成,每個子判別器負責處理音頻信號在不同周期性間隔上的特征(例如,通過觀察每隔p個樣本點的數據) 。
- 這一設計對于捕捉語音信號中固有的、多樣的周期性模式至關重要,而這些模式往往被以往的模型所忽略,從而顯著提升了合成語音的真實感 。
- 輸入音頻被重塑為二維數據,以便應用二維卷積,確保梯度能夠有效地傳播。
- 多尺度判別器 (Multi-Scale Discriminator, MSD):
- 借鑒自MelGAN,MSD在不同尺度(原始音頻、下采樣后的音頻)上評估音頻樣本 。
- 這有助于捕捉音頻的短期和長期依賴關系,以及整體波形結構。
- MSD采用帶步長的分組卷積。為保證訓練穩定性,除處理原始音頻的子判別器外,其他子判別器采用權重歸一化,而前者采用譜歸一化。
- 多周期判別器 (Multi-Period Discriminator, MPD):
- 判別器的替代設計: 曾有研究提出使用Wave-U-Net判別器作為MPD/MSD集成判別器的替代方案。這種單一但表達能力強的判別器采用Wave-U-Net架構,能夠以與輸入信號相同的分辨率逐樣本點評估波形,并通過帶有跳躍連接的編碼器和解碼器提取多層次特征。實驗表明,這種設計可以在判別器更輕量、更快的情況下達到相當的語音質量 。
- 生成器 (Generator, G):
-
訓練范式:
- 對抗損失 (Adversarial Loss): 采用LSGAN (Least Squares GAN) 的損失函數,以實現更穩定的訓練。MPD和MSD的輸出共同構成了對抗損失。
- 特征匹配損失 (Feature Matching Loss, LFM): 計算真實樣本和生成樣本在判別器中間層特征之間的L1距離。這有助于引導生成器產生與真實音頻特征相似的輸出,從而穩定訓練過程并提升音質。
- 梅爾頻譜損失 (Mel-Spectrogram Loss, LMel): 計算生成波形的梅爾頻譜與真實梅爾頻譜之間的L1距離。這是一個輔助損失,尤其在訓練初期,能夠有效地指導生成器的學習方向。
-
性能與深遠影響:
- 高保真度: 在MOS(平均意見分)評估中,HiFi-GAN的得分不僅顯著優于先前的GAN聲碼器,甚至超越了如WaveGlow等一些自回歸模型,達到了接近真人的音質水平 。
- 高效率: HiFi-GAN在GPU上實現了遠超實時的合成速度,其輕量級版本甚至能在CPU上達到實時合成 。
- 泛化能力: HiFi-GAN在未見過說話人的梅爾頻譜轉換以及端到端TTS任務中均表現出良好的性能 。
- 廣泛應用: 由于其在音質和速度上的出色平衡,HiFi-GAN迅速成為后續眾多TTS系統和研究中廣泛采用的基礎聲碼器 ,例如在先進的CosyVoice2.0系統中也得到了應用 。
表1: HiFi-GAN 性能總結 (基于LJSpeech數據集的原始論文結果)
| 模型 | MOS (±置信區間) | GPU合成速度 (kHz / 倍于實時) | CPU合成速度 (kHz / 倍于實時) | 參數量 (百萬) |
|---|---|---|---|---|
| Ground Truth | 4.45 (±0.06) | - | - | - |
| WaveNet (MoL) | 4.02 (±0.08) | 0.07 / ×0.003 | - | 24.73 |
| WaveGlow | 3.81 (±0.08) | 501 / ×22.75 | 4.72 / ×0.21 | 87.73 |
| MelGAN | 3.79 (±0.09) | 14,238 / ×645.73 | 145.52 / ×6.59 | 4.26 |
| HiFi-GAN V1 | 4.36 (±0.07) | 3,701 / ×167.86 | 31.74 / ×1.43 | 13.92 |
| HiFi-GAN V2 | 4.23 (±0.07) | 16,863 / ×764.80 | 214.97 / ×9.74 | 0.92 |
| HiFi-GAN V3 | 4.05 (±0.08) | 26,169 / ×1,186.80 | 296.38 / ×13.44 | 1.46 |
HiFi-GAN的成功,特別是其相較于先前GAN聲碼器在音質上的顯著提升,很大程度上歸功于其判別器的創新設計。GAN的訓練依賴于生成器和判別器之間的博弈,判別器向生成器提供有意義的梯度至關重要。早期的GAN聲碼器(如MelGAN)雖然也使用了多尺度判別器(MSD),但在捕捉所有語音真實感方面仍有不足 。HiFi-GAN的論文明確指出,對周期性模式的建模是提升音質的關鍵 。為此,多周期判別器(MPD)被專門設計出來,通過多個子判別器分別關注音頻的不同周期成分 。HiFi-GAN論文中的消融實驗以及后續一些關于判別器設計的研究(如 中提出的單一判別器替代方案)都強調了判別器架構的重要性;移除MPD會顯著降低合成語音的質量 。這突出表明,對于基于GAN的語音合成而言,僅僅擁有一個強大的生成器是不夠的。判別器能否有效感知并懲罰各種細微的聲學瑕疵(如周期性、不同尺度下的時間結構等),對于最終實現高保真度至關重要。
4. 新的疆域:面向富語義TTS的先進聲學編解碼器
盡管HiFi-GAN在梅爾頻譜到波形的轉換任務上表現卓越,但隨著大型語言模型(LLM)在TTS領域的崛起,對聲學表示(即聲學令牌)提出了新的、更高的要求:
- 離散化與高壓縮: LLM通常處理離散的令牌序列,因此聲學表示需要被有效地離散化,并且為了處理效率和存儲,需要達到一定的壓縮率。
- 語義感知: 新一代的聲學令牌不僅要捕捉聲音細節,還應包含語言內容信息,使得LLM能夠更好地理解和生成語音的語義層面 。
- 可控性: 為了生成更具表現力的語音,聲學表示應支持對說話人身份、風格、情感等屬性的精細控制 。
- 高效率: 低比特率的聲學令牌有助于加快LLM的處理速度并減少數據傳輸和存儲的開銷。
現有的純聲學編解碼器(如Encodec,僅關注重建質量,難以讓LLM預測音頻的“低層波動”)和純語義編解碼器(如Hubert,忽略聲學細節,常導致兩階段建模)都難以完全滿足這些新需求 。因此,研究重點開始從單純的“聲碼器”(mel-to-wave)轉向功能更全面的“聲學編解碼器/令牌化器”(audio-to-tokens-to-audio)。這些新模型不僅負責最終的波形合成,更承擔了將語音分析、編碼為富含多維度信息的離散令牌序列的關鍵任務。
5. XCodec2.0: 統一聲學與語義信息
XCodec系列代表了在LLM時代下,為滿足富語義TTS需求而設計的新一代聲學編解碼器。
-
XCodec的演進:
- 初代XCodec: 其目標是在碼本的各個層級(最初基于RVQ)融合聲學和語義信息,以支持單階段流式生成,并簡化LLM的建模復雜度 。
- XCodec2.0的改進: XCodec2.0在前代基礎上進行了顯著優化,包括:
- 降低TPS (Tokens Per Second): 意味著更高的壓縮率或處理效率。
- 支持單碼本: 簡化了令牌結構。
- 提升重建質量。
- 增加多語言語音語義支持 。 其最終目標是使該令牌化器更加實用,成為音頻LLM的標準構建模塊 。
-
XCodec2.0架構剖析:
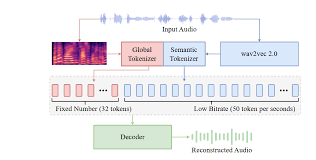
- 單層設計: 從多層殘差矢量量化(RVQ)轉向單層矢量量化(VQ)或有限標量量化(Finite Scalar Quantization, FSQ) 。一篇討論指出其從RVQ演進為單個VQ 。
- 語義特征融入: 在量化階段之前,XCodec2.0會整合來自預訓練語義編碼器(例如,從Wav2Vec 2.0或Hubert等語音表示模型中提取)的語義特征 。
- 語義重建損失: 在RVQ(或單VQ)之后應用一項語義重建損失,以確保量化后的表示仍能保持語義的完整性 。
- 幀率: 以50Hz的幀率運行,即每秒產生50個聲學令牌 。
- 輸出: 生成單流的離散聲學令牌。
-
設計理念:
- 為基于LLM的音頻生成而優化: 通過提供包含豐富語義信息的單流聲學令牌,XCodec2.0簡化了LLM的預測任務,相比于傳統RVQ產生的多碼本或解耦表示更為直接 。
- 提升語義完整性: 通過顯式地用語義信息指導編解碼過程,旨在減少合成語音中的內容錯誤(例如,降低詞錯誤率WER) 。
- 兼顧壓縮與質量: 在保證較高重建質量的同時,力求達到實用的壓縮水平(如較低的TPS) 。
-
應用與性能:
- 可與codec-bpe等工具集成,用于音頻語言建模 。
- 實驗表明,在TTS任務中,與基線聲學編解碼器相比,XCodec2.0能夠改善WER,這支持了“整合語義信息有助于LLM更好地理解內容”的假設 。
- 相較于SpeechTokenizer,XCodec在WER以及說話人相似度(Sim-O, UTMOS)方面表現更優,表明其能更有效地整合語義和聲學信息 。
在先進聲學編解碼器的設計中,一個關鍵的考量點在于如何將語義信息與聲學信號處理路徑相融合,這可以稱之為“語義接合點”(Semantic Seam)。XCodec2.0的策略是在量化之前顯式地注入語義特征,并在量化之后使用特定的損失函數來強化語義信息的保留。傳統的純聲學編解碼器可能在壓縮過程中丟失語義的細微差別,而純語義編解碼器則犧牲了聲學細節 。像SpeechTokenizer這樣的早期嘗試采用了兩階段方法,試圖在不同層級分別處理語義和聲學信息 。
XCodec2.0則采取了“早期融合”的思路,從預訓練的語義編碼器獲取特征 ,并將其置于VQ瓶頸層之前。這樣做使得VQ學習過程能夠兼顧并保留這種融合后的信息。同時,在VQ之后施加語義重建損失,進一步確保最終選擇的離散碼字在語義上是準確且有意義的 。這種策略旨在創建一個更整體化的離散表示。其成功(例如,在WER上的改進 )表明,用語義信息來影響量化過程,可能比后續再嘗試添加語義或將兩者完全分離(如果目標是為LLM生成單一、統一的令牌流)更為有效。這與BiCodec所采用的顯式解耦策略形成了對比。
6.BiCodec: 為Spark-TTS打造可控的解耦令牌
BiCodec是專為Spark-TTS系統設計的一款聲學編解碼器,其核心在于通過解耦的聲學令牌實現富有表現力且可精細控制的語音合成。
-
設計原則 (針對Spark-TTS):
- 單流解耦令牌: BiCodec將語音分解為兩種互補的令牌類型,并整合在單一的令牌流中:
- 低比特率語義令牌 (Low-bitrate Semantic Tokens): 負責捕捉語言學內容,即“說什么”。
- 定長全局令牌 (Fixed-length Global Tokens): 用于表示說話人屬性以及其他副語言學特征(如音色、風格、情感),即“怎么說”。
- 核心目標: 實現對語音屬性(如性別、音高、語速、情感)的細粒度控制,達成高質量的零樣本(zero-shot)聲音克隆,同時為基于LLM的TTS保持高效率。
- 單流解耦令牌: BiCodec將語音分解為兩種互補的令牌類型,并整合在單一的令牌流中:
-
BiCodec模型內部機制:
- 編碼器 (Encoder): 處理輸入音頻以提取初始特征。
- 語義令牌量化: 可能采用標準的VQ方法對時變的語義內容進行量化。
- 全局嵌入量化創新:
- 采用有限標量量化 (FSQ)。
- 利用可學習查詢 (learnable queries) 和 交叉注意力機制 (cross-attention mechanism) 來推導全局嵌入。與簡單的平均池化或其他全局屬性提取方法相比,這是一種新穎的途徑,能夠為全局特征(如說話人音色)生成更具表現力和靈活性的表示 (雖然在對比TiCodec時提及此方法,但暗示了BiCodec采用了類似或更優的機制)。
- 解碼器 (Decoder): 從語義令牌和全局令牌的組合流中重建語音波形。
-
訓練策略:
- GAN方法論: 采用端到端的對抗訓練框架。
- 判別器: 使用多周期判別器 (MPD) 和多頻帶多尺度短時傅里葉變換 (STFT) 判別器,分別用于波形域和頻域的判別 (這與HiFi-GAN及其他現代編解碼器的做法類似)。
- 重建損失: 在多尺度梅爾頻譜圖上計算L1損失。
- L1特征匹配損失: 通過判別器的中間層特征計算。
- VQ碼本學習: 包含碼本損失(編碼器輸出與量化結果之間的L1損失,使用停止梯度)和承諾損失 (commitment loss)。使用直通估計器 (Straight-Through Estimator, STE) 進行梯度反向傳播。
- Wav2Vec 2.0重建損失: 在量化之后應用,以增強語義相關性 (借鑒了X-Codec的做法) 。
- 全局嵌入訓練穩定性: 在訓練初期,解碼器使用的全局嵌入直接從編碼器輸出的未量化特征池化得到(教師信號),同時全局令牌的FSQ碼本通過L1損失向該教師信號學習。這種教師強制策略在訓練穩定后會被移除。
- GAN方法論: 采用端到端的對抗訓練框架。
-
解決的問題與影響:
- 解決了現有LLM-based TTS中,因預測多個碼本而導致的多階段處理或復雜架構的局限性 。
- 通過單一的編解碼器LLM,提供了一個統一的零樣本TTS系統,并具備全面的屬性控制能力 。
- 這種解耦表示在保留語義令牌效率的同時,實現了對音色的細粒度控制 。
-
性能表現:
- 據稱在零樣本聲音克隆方面達到SOTA水平,并能生成高度可定制化的聲音 。
- BiCodec本身的重建質量是Spark-TTS整體評估的一部分,具體指標可參考其論文中的重建實驗結果 [ (Table 2, 3 for reconstruction)]。
表2: BiCodec 架構與訓練亮點
| 方面 | 描述 |
|---|---|
| 核心理念 | 解耦的語義令牌與全局令牌,實現單流輸出 |
| 語義令牌類型 | 低比特率 |
| 全局令牌類型 | 定長,基于FSQ |
| 全局屬性提取 | 可學習查詢 (Learnable queries) 與交叉注意力 (Cross-attention) |
| 關鍵訓練目標 | GAN對抗損失, L1梅爾頻譜重建損失, L1特征匹配損失, VQ碼本損失 (codebook & commitment), Wav2Vec 2.0重建損失 (語義相關性) |
BiCodec將語義內容和說話人屬性顯式分離為不同類型的令牌,這是一種深思熟慮的設計選擇,旨在增強可控性并簡化下游LLM(在Spark-TTS中)的任務。對于LLM而言,從一個整體的、糾纏的表示中控制特定的語音屬性(如音色、情感、音高)可能相當具有挑戰性。以往的系統可能需要復雜的多階段生成或精巧的提示工程才能實現此類控制 。
BiCodec則提出了一種“因子分解”的語音表示方法:語義令牌承載“說什么”的信息,而全局令牌承載“怎么說”(如說話人身份、整體風格)的信息 。這使得Spark-TTS中的LLM有可能更獨立地學習和操縱這些方面。例如,它可以將給定文本的語義令牌與參考說話人的全局令牌相結合,以實現聲音克隆。同時,低比特率語義令牌的使用也保證了效率 。這種解耦策略代表了構建更直觀、更強大的合成語音控制接口的重要一步。它與LLM的模塊化特性非常契合,允許LLM專注于生成或操縱由這些解耦令牌類型所代表的語音信號的特定方面。這與XCodec2.0所追求的統一令牌流形成了不同的設計哲學。
7.總結
從HiFi-GAN在波形合成效率與保真度上取得的突破,到XCodec2.0和BiCodec在語義豐富性與可控性方面的探索,TTS聲學編解碼技術在過去數年中取得了令人矚目的進展。
當前聲碼器的設計趨勢:
- GAN的基石地位: 生成對抗網絡(GAN)仍然是訓練高保真聲碼器和編解碼器的核心技術之一,盡管通常會輔以感知損失和特征匹配損失來進一步提升效果 。
- FSQ的興起: 有限標量量化(FSQ)正逐漸成為新一代編解碼器中(XCodec2.0中通過“單一VQ”間接體現,BiCodec,CosyVoice2.0均采用)替代傳統RVQ的首選方法,因為它在每幀生成較少令牌序列方面具有簡單性和效率優勢 。
- 以LLM為中心的設計: 聲學編解碼器的設計越來越傾向于產生為LLM處理而優化的令牌流,這催生了那些優先考慮語義豐富性、可控性以及適當壓縮級別的架構 。
- 語義引導的重要性: 在編解碼器中顯式地整合語義信息(例如XCodec2.0中輸入語義編碼器特征,BiCodec中應用wav2vec2.0損失)已成為一種普遍做法,旨在提高內容準確性和自然度 。
表3: 現代聲碼器/聲學編解碼器特性對比
| 特性 | HiFi-GAN | XCodec2.0 | BiCodec (in Spark-TTS) | CosyVoice2.0 (聲學部分) |
|---|---|---|---|---|
| 主要目標 | 波形保真度與效率 | 統一的語義-聲學令牌,簡化LLM處理 | 解耦的可控令牌 (語義 vs. 全局屬性) | 系統集成,流式,高表現力 |
| 編解碼器輸入 | 梅爾頻譜圖 | 原始音頻 | 原始音頻 | 語義語音令牌 (來自LLM) |
| 編解碼器輸出 | 波形 | 單流離散聲學令牌 | 單流離散令牌 (語義+全局) | 梅爾頻譜圖 (送入HiFi-GAN聲碼器) |
| 關鍵架構元素 | MRF, MPD, MSD | 語義編碼器 + 單層VQ/FSQ, 對抗判別器 | 編碼器, 解耦量化器 (語義VQ + 全局FSQ含注意力機制), 解碼器, 對抗判別器 | FSQ (令牌化), 流匹配模型 (令牌到梅爾), HiFi-GAN (梅爾到波形) |
| 量化策略 | (不適用,為聲碼器) | 單層VQ/FSQ | 語義VQ + 全局FSQ | FSQ |
| 語義處理 | 間接 (依賴輸入梅爾頻譜的語義質量) | 量化前融入語義特征,量化后施加語義損失 | 解耦為語義令牌,應用Wav2Vec2.0損失 | LLM負責主要語義處理,輸出語義令牌 |
| 主要優勢 | 高保真、高效率波形合成 | 統一令牌簡化LLM,提升語義完整性 | 細粒度語音屬性控制,零樣本聲音克隆 | 低延遲流式合成,高自然度與表現力,多語言支持 |
在如何將聲學信息有效地提供給LLM以用于TTS任務方面,似乎出現了兩種主要的設計哲學:一種是如XCodec2.0所倡導的統一令牌流,另一種則是如BiCodec所采用的解耦令牌流。LLM擅長序列建模,關鍵問題在于哪種類型的序列能夠最好地表示語音以用于生成。XCodec2.0主張采用單一的令牌流,其中聲學和語義信息被融合在一起 。這或許能簡化LLM的輸入結構,因為它只需要處理一種類型的令牌。其挑戰在于確保LLM能夠從這種融合的表示中隱式地學習控制不同的語音屬性。相比之下,BiCodec則主張將語義內容和全局說話人屬性顯式地解耦開來 。這可能使LLM通過操縱這些不同類型的令牌來更容易地施加細粒度的控制。其挑戰則在于如何在LLM內部有效地管理這些不同類型的令牌。
這兩種方法都旨在改進以往如多流RVQ輸出或缺乏明確語義/說話人信息的純聲學令牌序列等舊方法。目前,該領域正在積極探索連接連續語音世界和離散LLM處理的最佳接口。這些不同方法能否成功,將取決于它們在表示能力、可控性以及LLM學習使用這些令牌的難易程度之間所達成的平衡。尚不清楚哪種范式會在所有用例中最終勝出。
- 未來展望:
- 在保持高質量的同時進一步提升壓縮率。
- 實現對表現力屬性的更細粒度、更直觀的控制。
- LLM與聲學編解碼器的端到端聯合訓練,以實現更緊密的集成。
- 能夠以最少的數據穩健處理多樣化聲學條件和未見過說話人的編解碼器。
- 在編解碼器架構本身中探索擴散模型的應用,而不僅僅是作為最終的聲碼器階段 (例如SpecDiff-GAN在HiFi-GAN基礎上引入擴散過程)。

)





)











