1 特征工程概念
特征工程:就是對特征進行相關的處理
一般使用pandas來進行數據清洗和數據處理、使用sklearn來進行特征工程
特征工程是將任意數據(如文本或圖像)轉換為可用于機器學習的數字特征,比如:字典特征提取(特征離散化)、文本特征提取、圖像特征提取。
特征工程步驟為:
-
特征提取, 如果不是像dataframe那樣的數據,要進行特征提取,比如字典特征提取,文本特征提取
-
無量綱化(預處理)
-
歸一化
-
標準化
-
-
降維
-
底方差過濾特征選擇
-
主成分分析-PCA降維
-
2 特征工程API
-
實例化轉換器對象,轉換器類有很多,都是Transformer的子類, 常用的子類有:
DictVectorizer 字典特征提取 CountVectorizer 文本特征提取 TfidfVectorizer TF-IDF文本特征詞的重要程度特征提取 MinMaxScaler 歸一化 StandardScaler 標準化 VarianceThreshold 底方差過濾降維 PCA 主成分分析降維
-
轉換器對象調用fit_transform()進行轉換, 其中fit用于計算數據,transform進行最終轉換
fit_transform()可以使用fit()和transform()代替
data_new = transfer.fit_transform(data) 可寫成 transfer.fit(data) data_new = transfer.transform(data)
3 DictVectorizer 字典列表特征提取
稀疏矩陣
稀疏矩陣是指一個矩陣中大部分元素為零,只有少數元素是非零的矩陣。在數學和計算機科學中,當一個矩陣的非零元素數量遠小于總的元素數量,且非零元素分布沒有明顯的規律時,這樣的矩陣就被認為是稀疏矩陣。例如,在一個1000 x 1000的矩陣中,如果只有1000個非零元素,那么這個矩陣就是稀疏的。
由于稀疏矩陣中零元素非常多,存儲和處理稀疏矩陣時,通常會采用特殊的存儲格式,以節省內存空間并提高計算效率。
三元組表 (Coordinate List, COO):三元組表就是一種稀疏矩陣類型數據,存儲非零元素的行索引、列索引和值:
(行,列) 數據
(0,0) 10
(0,1) 20
(2,0) 90
(2,20) 8
(8,0) 70
表示除了列出的有值, 其余全是0
from sklearn.feature_extraction import DictVectorizerdata = [{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]
# 創建一個字典列表特征提取工具
tool = DictVectorizer(sparse=False)
# 字典列表特征提取
data = tool.fit_transform(data)
print(data)
print(tool.feature_names_)
非稀疏矩陣(稠密矩陣)
非稀疏矩陣,或稱稠密矩陣,是指矩陣中非零元素的數量與總元素數量相比接近或相等,也就是說矩陣中的大部分元素都是非零的。在這種情況下,矩陣的存儲通常采用標準的二維數組形式,因為非零元素密集分布,不需要特殊的壓縮或優化存儲策略。
-
存儲:稀疏矩陣使用特定的存儲格式來節省空間,而稠密矩陣使用常規的數組存儲所有元素,無論其是否為零。
-
計算:稀疏矩陣在進行計算時可以利用零元素的特性跳過不必要的計算,從而提高效率。而稠密矩陣在計算時需要處理所有元素,包括零元素。
-
應用領域:稀疏矩陣常見于大規模數據分析、圖形學、自然語言處理、機器學習等領域,而稠密矩陣在數學計算、線性代數等通用計算領域更為常見。
在實際應用中,選擇使用稀疏矩陣還是稠密矩陣取決于具體的問題場景和數據特性。
(1) api
-
創建轉換器對象:
sklearn.feature_extraction.DictVectorizer(sparse=True)
參數:
sparse=True返回類型為csr_matrix的稀疏矩陣
sparse=False表示返回的是數組,數組可以調用.toarray()方法將稀疏矩陣轉換為數組
-
轉換器對象:
轉換器對象調用fit_transform(data)函數,參數data為一維字典數組或一維字典列表,返回轉化后的矩陣或數組
轉換器對象get_feature_names_out()方法獲取特征名
(2)示例1 提取為稀疏矩陣對應的數組
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重慶','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
#創建DictVectorizer對象
transfer = DictVectorizer(sparse=False)
data_new = transfer.fit_transform(data)
# data_new的類型為ndarray
#特征數據
print("data_new:\n", data_new)
#特征名字
print("特征名字:\n", transfer.get_feature_names_out())
data_new:[[ 30. ? 0. ? 1. ? 0. 200.][ 33. ? 0. ? 0. ? 1. 60.][ 42. ? 1. ? 0. ? 0. 80.]] 特征名字:['age' 'city=北京' 'city=成都' 'city=重慶' 'temperature']
import pandas pandas.DataFrame(data_new, columns=transfer.get_feature_names_out())
(3)示例2 提取為稀疏矩陣
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重慶','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
#創建DictVectorizer對象
transfer = DictVectorizer(sparse=True)
data_new = transfer.fit_transform(data)
#data_new的類型為<class 'scipy.sparse._csr.csr_matrix'>
print("data_new:\n", data_new)
#得到特征
print("特征名字:\n", transfer.get_feature_names_out())
其中(row,col)數據中的col表示特征, 本示例中0表示 ‘age’, 1表示‘city=北京’,……
data_new:(0, 0) 30.0(0, 2) 1.0(0, 4) 200.0(1, 0) 33.0(1, 3) 1.0(1, 4) 60.0(2, 0) 42.0(2, 1) 1.0(2, 4) 80.0 特征名字:['age' 'city=北京' 'city=成都' 'city=重慶' 'temperature']
(4)稀疏矩陣轉為數組
稀疏矩陣對象調用toarray()函數, 得到類型為ndarray的二維稀疏矩陣
4 CountVectorizer 文本特征提取
(1)API
sklearn.feature_extraction.text.CountVectorizer
構造函數關鍵字參數stop_words,值為list,表示詞的黑名單(不提取的詞)
fit_transform函數的返回值為稀疏矩陣
(2) 英文文本提取
from sklearn.feature_extraction.text import CountVectorizer import pandas as pd data=["stu is well, stu is great", "You like stu"] #創建轉換器對象, you和is不提取 transfer = CountVectorizer(stop_words=["you","is"]) #進行提取,得到稀疏矩陣 data_new = transfer.fit_transform(data) print(data_new) ? import pandas pandas.DataFrame(data_new.toarray(), index=["第一個句子","第二個句子"],columns=transfer.get_feature_names_out())
(3) 中文文本提取
a.中文文本不像英文文本,中文文本文字之間沒有空格,所以要先分詞,一般使用jieba分詞.
b.下載jieba組件, (不要使用conda)
c.jieba的基礎
import jieba data = "在如今的互聯網世界,正能量正成為澎湃時代的大流量" data = jieba.cut(data) data = list(data) print(data) #['在', '如今', '的', '互聯網', '世界', ',', '正', '能量', '正', '成為', '澎湃', '時代', '的', '大', '流量'] data = " ".join(data) print(data) #"在 如今 的 互聯網 世界 , 正 能量 正 成為 澎湃 時代 的 大 流量"
使用jieba封裝一個函數,功能是把漢語字符串中進行分詞(會忽略長度小于等于1的詞語,因為它們往往缺乏語義信息,不能很好地表達文本的特征)
import jieba
from sklearn.feature_extraction.text import CountVectorizer
data = ['陶吉吉唱了二十二', '周杰倫唱了園游會', '王力宏唱了愛錯']
def fenci(str):return " ".join(list(jieba.cut(str)))
data = [fenci(str) for str in data]
print(data)
cv = CountVectorizer(stop_words=["唱了"])
data = cv.fit_transform(data)
print(data.toarray())
print(cv.get_feature_names_out())5 TfidfVectorizer TF-IDF文本特征詞的重要程度特征提取
(1) 算法
詞頻(Term Frequency, TF), 表示一個詞在當前篇文章中的重要性
逆文檔頻率(Inverse Document Frequency, IDF), 反映了詞在整個文檔集合中的稀有程度

(2) API
sklearn.feature_extraction.text.TfidfVectorizer()
構造函數關鍵字參數stop_words,表示詞特征黑名單
fit_transform函數的返回值為稀疏矩陣
(3) 示例
代碼與CountVectorizer的示例基本相同,僅僅把CountVectorizer改為TfidfVectorizer即可
示例中data是一個字符串list, list中的第一個元素就代表一篇文章.
補充:在sklearn庫中 TF-IDF算法做了一些細節的優化
詞頻 (TF)
詞頻是指一個詞在文檔中出現的頻率。通常有兩種計算方法:
-
原始詞頻:一個詞在文檔中出現的次數除以文檔中總的詞數。
-
平滑后的詞頻:為了防止高頻詞主導向量空間,有時會對詞頻進行平滑處理,例如使用
1 + log(TF)。 -
在 TfidfVectorizer 中,TF 默認是:直接使用一個詞在文檔中出現的次數也就是CountVectorizer的結果
逆文檔頻率 (IDF)
逆文檔頻率衡量一個詞的普遍重要性。如果一個詞在許多文檔中都出現,那么它的重要性就會降低。
IDF 的計算公式是:
IDF(t)=\log?(\dfrac{總文檔數}{包含詞t的文檔數+1})
在 TfidfVectorizer 中,IDF 的默認計算公式是:
IDF(t)=\log?(\dfrac{總文檔數+1}{包含詞t的文檔數+1})+1
在 TfidfVectorizer 中還會進行歸一化處理(采用的L2歸一化)
L2歸一化
x_1歸一化后的數據=\dfrac{x_1}{\sqrt{x_1^2+x_2^2+...x_n^2}}
x可以選擇是行或者列的數據
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.preprocessing import normalize
from sklearn.preprocessing import StandardScaler
import jieba
import pandas as pd
import numpy as np
def my_cut(text):return " ".join(jieba.cut(text))
data=["教育學會會長期間,堅定支持民辦教育事業!", ?"扶持民辦,學校發展事業","事業做出重大貢獻!"]
data=[my_cut(i) for i in data]
print(data)
# print("詞頻",CountVectorizer().fit_transform(data).toarray())
transfer=TfidfVectorizer()
res=transfer.fit_transform(data)
print(pd.DataFrame(res.toarray(),columns=transfer.get_feature_names_out()))
?
?
?
?
# 手動實現tfidf向量(跟上面的api實現出一樣的效果)
def tfidf(data):# 計算詞頻count = CountVectorizer().fit_transform(data).toarray()print("count",count)print(np.sum(count != 0, axis=0))# 計算IDF,并采用平滑處理idf = np.log((len(data) + 1) / (1 + np.sum(count != 0, axis=0))) + 1# 計算TF-IDFtf_idf = count * idf# L2標準化tf_idf_normalized = normalize(tf_idf, norm='l2', axis=1)#axis=0是列 axis=1是行return tf_idf,tf_idf_normalized
tf_idf,tf_idf_normalized=tfidf(data)
print(pd.DataFrame(tf_idf,columns=transfer.get_feature_names_out()))
print(pd.DataFrame(tf_idf_normalized,columns=transfer.get_feature_names_out()))
6 無量綱化-預處理
無量綱,即沒有單位的數據
無量綱化包括"歸一化"和"標準化", 為什么要進行無量綱化呢?
這是一個男士的數據表:
| 編號id | 身高 h | 收入 s | 體重 w |
|---|---|---|---|
| 1 | 1.75(米) | 15000(元) | 120(斤) |
| 2 | 1.5(米) | 16000(元) | 140(斤) |
| 3 | 1.6(米) | 20000(元) | 100(斤) |
假設算法中需要求它們之間的歐式距離, 這里以編號1和編號2為示例:
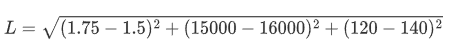
從計算上來看, 發現身高對計算結果沒有什么影響, 基本主要由收入來決定了,但是現實生活中,身高是比較重要的判斷標準. 所以需要無量綱化.
(1) MinMaxScaler 歸一化
通過對原始數據進行變換把數據映射到指定區間(默認為0-1)
<1>歸一化公式:
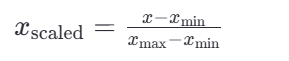
這里的 𝑥min 和 𝑥max 分別是每種特征中的最小值和最大值,而 𝑥是當前特征值,𝑥scaled 是歸一化后的特征值。
若要縮放到其他區間,可以使用公式:x=x*(max-min)+min;
比如 [-1, 1]的公式為:
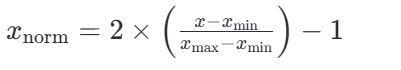
<2>歸一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
參數:feature_range=(0,1) 歸一化后的值域,可以自己設定
fit_transform函數歸一化的原始數據類型可以是list、DataFrame和ndarray, 不可以是稀疏矩陣
fit_transform函數的返回值為ndarray
<3>歸一化示例
示例1:原始數據類型為list
from sklearn.preprocessing import MinMaxScaler
tool = MinMaxScaler(feature_range=(0,1))
x = [[100,2],[800,3],[300,7],[230,4]]
x =tool.fit_transform(x)
print(x)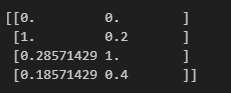
示例2:原始數據類型為DataFrame
from sklearn.preprocessing import MinMaxScaler import pandas as pd; data=[[12,22,4],[22,23,1],[11,23,9]] data = pd.DataFrame(data=data, index=["一","二","三"], columns=["一列","二列","三列"]) transfer = MinMaxScaler(feature_range=(0, 1)) data_new = transfer.fit_transform(data) print(data_new)
示例3:原始數據類型為 ndarray
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import MinMaxScaler
?
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重慶','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=False)
data = transfer.fit_transform(data) #data類型為ndarray
print(data)
?
transfer = MinMaxScaler(feature_range=(0, 1))
data = transfer.fit_transform(data)
print(data)
<4>缺點
最大值和最小值容易受到異常點影響,所以魯棒性較差。所以常使用標準化的無量鋼化
(2)normalize歸一化
API
from sklearn.preprocessing import normalize normalize(data, norm='l2', axis=1) #data是要歸一化的數據 #norm是使用那種歸一化:"l1" "l2" "max #axis=0是列 axis=1是行
<1> L1歸一化
絕對值相加作為分母,特征值作為分子
<2> L2歸一化
平方相加作為分母,特征值作為分子
<3> max歸一化
max作為分母,特征值作為分子
from sklearn.preprocessing import normalize
x = [[100,2],[800,3],[300,7],[230,4]]
x = normalize(x,norm='max',axis=0)
print(x)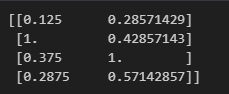
(3)StandardScaler 標準化
在機器學習中,標準化是一種數據預處理技術,也稱為數據歸一化或特征縮放。它的目的是將不同特征的數值范圍縮放到統一的標準范圍,以便更好地適應一些機器學習算法,特別是那些對輸入數據的尺度敏感的算法。
<1>標準化公式
最常見的標準化方法是Z-score標準化,也稱為零均值標準化。它通過對每個特征的值減去其均值,再除以其標準差,將數據轉換為均值為0,標準差為1的分布。這可以通過以下公式計算:
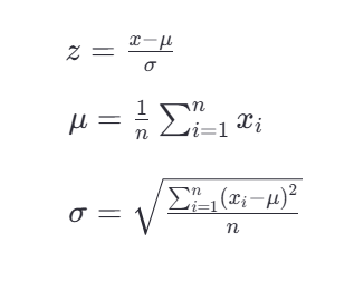
其中,z是轉換后的數值,x是原始數據的值,μ是該特征的均值,σ是該特征的 標準差
<2> 標準化 API
sklearn.preprocessing.StandardScale
與MinMaxScaler一樣,原始數據類型可以是list、DataFrame和ndarray
fit_transform函數的返回值為ndarray, 歸一化后得到的數據類型都是ndarray
from sklearn.preprocessing import StandardScaler #不能加參數feature_range=(0, 1) transfer = StandardScaler() data_new = transfer.fit_transform(data) #data_new的類型為ndarray
<3>標準化示例
from sklearn.preprocessing import StandardScaler
x = [[100,2],[800,3],[300,7],[230,4]]
tool = StandardScaler()
x = tool.fit_transform(x)
print(x)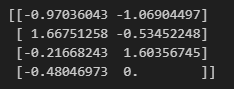
<4> 注意點
在數據預處理中,特別是使用如StandardScaler這樣的數據轉換器時,fit、fit_transform和transform這三個方法的使用是至關重要的,它們各自有不同的作用:
fit:
這個方法用來計算數據的統計信息,比如均值和標準差(在
StandardScaler的情況下)。這些統計信息隨后會被用于數據的標準化。你應當僅在訓練集上使用
fit方法。fit_transform:
這個方法相當于先調用
fit再調用transform,但是它在內部執行得更高效。它同樣應當僅在訓練集上使用,它會計算訓練集的統計信息并立即應用到該訓練集上。
transform:
這個方法使用已經通過
fit方法計算出的統計信息來轉換數據。它可以應用于任何數據集,包括訓練集、驗證集或測試集,但是應用時使用的統計信息必須來自于訓練集。
當你在預處理數據時,首先需要在訓練集X_train上使用fit_transform,這樣做可以一次性完成統計信息的計算和數據的標準化。這是因為我們需要確保模型是基于訓練數據的統計信息進行學習的,而不是整個數據集的統計信息。
一旦scaler對象在X_train上被fit,它就已經知道了如何將數據標準化。這時,對于測試集X_test,我們只需要使用transform方法,因為我們不希望在測試集上重新計算任何統計信息,也不希望測試集的信息影響到訓練過程。如果我們對X_test也使用fit_transform,測試集的信息就可能會影響到訓練過程。
總結來說:我們常常是先fit_transform(x_train)然后再transform(x_text)
7 特征降維
實際數據中,有時候特征很多,會增加計算量,降維就是去掉一些特征,或者轉化多個特征為少量個特征
特征降維其目的:是減少數據集的維度,同時盡可能保留數據的重要信息。
特征降維的好處:
減少計算成本:在高維空間中處理數據可能非常耗時且計算密集。降維可以簡化模型,降低訓練時間和資源需求。
去除噪聲:高維數據可能包含許多無關或冗余特征,這些特征可能引入噪聲并導致過擬合。降維可以幫助去除這些不必要的特征。
特征降維的方式:
-
特征選擇
-
從原始特征集中挑選出最相關的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通過一系列數學計算,形成新的特征,新的特征數量會小于之前特征數量
-
1 .特征選擇
(a) VarianceThreshold 低方差過濾特征選擇
-
Filter(過濾式): 主要探究特征本身特點, 特征與特征、特征與目標 值之間關聯
-
方差選擇法: 低方差特征過濾
如果一個特征的方差很小,說明這個特征的值在樣本中幾乎相同或變化不大,包含的信息量很少,模型很難通過該特征區分不同的對象,比如區分甜瓜子和咸瓜子還是蒜香瓜子,如果有一個特征是長度,這個特征相差不大可以去掉。
-
計算方差:對于每個特征,計算其在訓練集中的方差(每個樣本值與均值之差的平方,在求平均)。
-
設定閾值:選擇一個方差閾值,任何低于這個閾值的特征都將被視為低方差特征。
-
過濾特征:移除所有方差低于設定閾值的特征
-
-
# 特征降維
from sklearn.feature_selection import VarianceThreshold
tool = VarianceThreshold(threshold=1.5)
x = [[10, 2],[11,6],[10,8],[10,10],[10,19]]
x = tool.fit_transform(x)
print(x)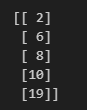
(b) 根據相關系數的特征選擇
<1>理論
正相關性(Positive Correlation)是指兩個變量之間的一種統計關系,其中一個變量的增加通常伴隨著另一個變量的增加,反之亦然。在正相關的關系中,兩個變量的變化趨勢是同向的。當我們說兩個變量正相關時,意味著:
-
如果第一個變量增加,第二個變量也有很大的概率會增加。
-
同樣,如果第一個變量減少,第二個變量也很可能會減少。
正相關性并不意味著一個變量的變化直接引起了另一個變量的變化,它僅僅指出了兩個變量之間存在的一種統計上的關聯性。這種關聯性可以是因果關系,也可以是由第三個未觀察到的變量引起的,或者是純屬巧合。
在數學上,正相關性通常用正值的相關系數來表示,這個值介于0和1之間。當相關系數等于1時,表示兩個變量之間存在完美的正相關關系,即一個變量的值可以完全由另一個變量的值預測。
舉個例子,假設我們觀察到在一定范圍內,一個人的身高與其體重呈正相關,這意味著在一般情況下,身高較高的人體重也會較重。但這并不意味著身高直接導致體重增加,而是可能由于營養、遺傳、生活方式等因素共同作用的結果。
負相關性(Negative Correlation)與正相關性剛好相反,但是也說明相關,比如運動頻率和BMI體重指數程負相關
不相關指兩者的相關性很小,一個變量變化不會引起另外的變量變化,只是沒有線性關系. 比如飯量和智商
皮爾遜相關系數(Pearson correlation coefficient)是一種度量兩個變量之間線性相關性的統計量。它提供了兩個變量間關系的方向(正相關或負相關)和強度的信息。皮爾遜相關系數的取值范圍是 [?1,1],其中:
-
\rho=1 表示完全正相關,即隨著一個變量的增加,另一個變量也線性增加。
-
\rho=-1 表示完全負相關,即隨著一個變量的增加,另一個變量線性減少。
-
\rho=0 表示兩個變量之間不存在線性關系。
相關系數\rho的絕對值為0-1之間,絕對值越大,表示越相關,當兩特征完全相關時,兩特征的值表示的向量是
在同一條直線上,當兩特征的相關系數絕對值很小時,兩特征值表示的向量接近在同一條直線上。當相關系值為負數時,表示負相關
<2>皮爾遜相關系數:pearsonr相關系數計算公式, 該公式出自于概率論
對于兩組數據 𝑋={𝑥1,𝑥2,...,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,...,𝑦𝑛},皮爾遜相關系數可以用以下公式計算:
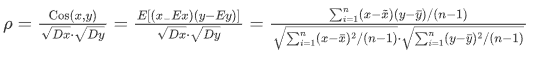
\bar{x}和 \bar{y} 分別是𝑋和𝑌的平均值
|ρ|<0.4為低度相關; 0.4<=|ρ|<0.7為顯著相關; 0.7<=|ρ|<1為高度相關
<3>api:
scipy.stats.personr(x, y) 計算兩特征之間的相關性
返回對象有兩個屬性:
statistic皮爾遜相關系數[-1,1]
pvalue零假設(了解),統計上評估兩個變量之間的相關性,越小越相關
<4>示例:
# 皮爾遜相關系數
from scipy.stats import pearsonr
x = [10,20,30,40,50]
x2 =[10,20,1,40,77]
y = [1,2,3,4,5]
res = pearsonr(x2,y)
print(res.statistic) # 相關系數
print(res.pvalue) # p值 越小越好開發中一般不使用求相關系數的方法,一般使用主成分分析,因為主成分分樣過程中就包括了求相關系數了。
2.主成份分析(PCA)
PCA的核心目標是從原始特征空間中找到一個新的坐標系統,使得數據在新坐標軸上的投影能夠最大程度地保留數據的方差,同時減少數據的維度。
(a) 原理
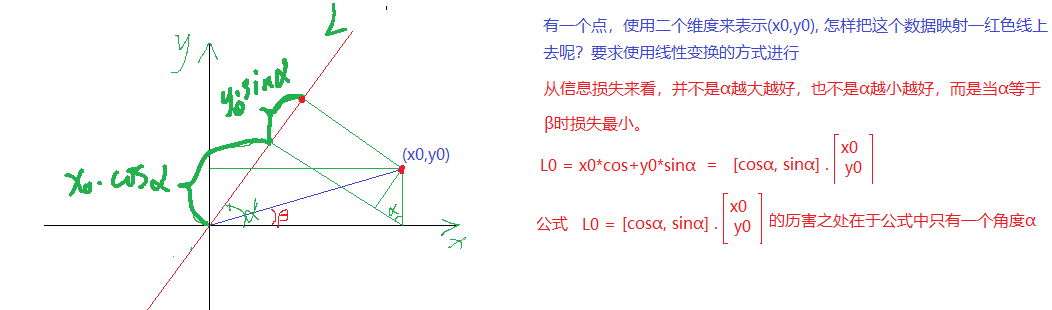
x_0投影到L的大小為x_0*cos \alpha
y_0投影到L的大小為y_0*sin\alpha
使用(x_0,y_0)表示一個點, 表明該點有兩個特征, 而映射到L上有一個特征就可以表示這個點了。這就達到了降維的功能 。
投影到L上的值就是降維后保留的信息,投影到與L垂直的軸上的值就是丟失的信息。保留信息/原始信息=信息保留的比例
下圖中紅線上點與點的距離是最大的,所以在紅色線上點的方差最大,粉紅線上的剛好相反.
所以紅色線上點來表示之前點的信息損失是最小的。
(b) 步驟
-
得到矩陣
-
用矩陣P對原始數據進行線性變換,得到新的數據矩陣Z,每一列就是一個主成分, 如下圖就是把10維降成了2維,得到了兩個主成分
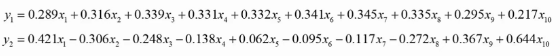
-
根據主成分的方差等,確定最終保留的主成分個數, 方差大的要留下。一個特征的多個樣本的值如果都相同,則方差為0, 則說明該特征值不能區別樣本,所以該特征沒有用。
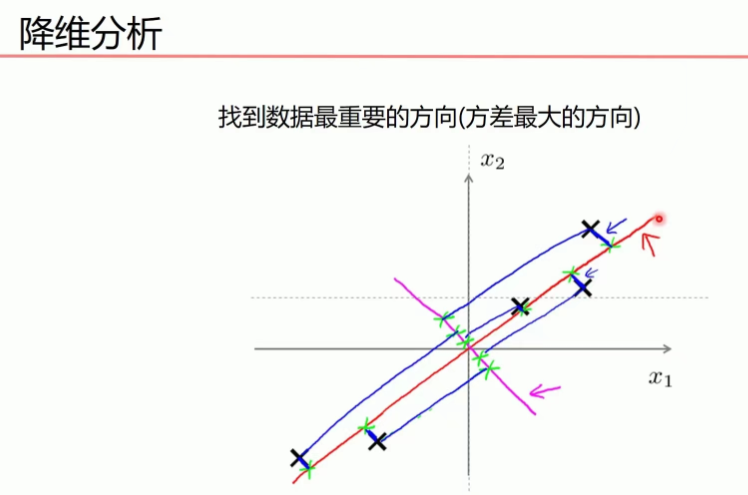
比如下圖的二維數據要降為一維數據,圖形法是把所在數據在二維坐標中以點的形式標出,然后給出一條直線,讓所有點垂直映射到直線上,該直線有很多,只有點到線的距離之和最小的線才能讓之前信息損失最小。
這樣之前所有的二維表示的點就全部變成一條直線上的點,從二維降成了一維。
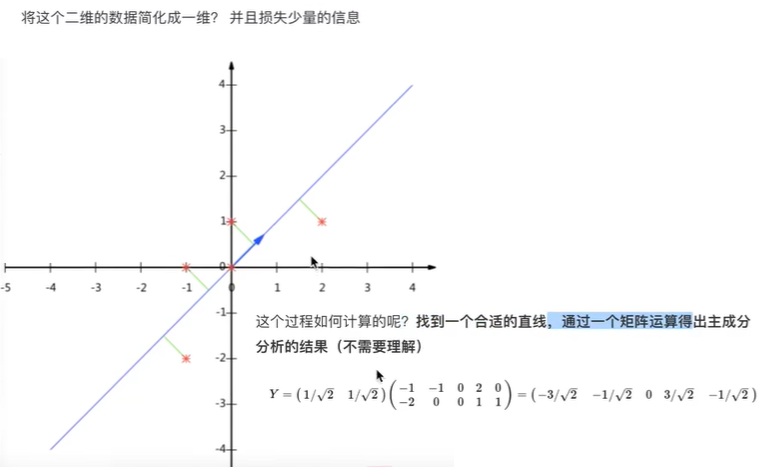
上圖是一個從二維降到一維的示例:的原始數據為
| 特征1-X1 | 特征2-X2 |
|---|---|
| -1 | -2 |
| -1 | 0 |
| 0 | 0 |
| 2 | 1 |
| 0 | 1 |
降維后新的數據為
| 特征3-X0 |
|---|
| -3/√2 |
| -1/√2 |
| 0 |
| 3/√2 |
| -1/√2 |
3.api
-
from sklearn.decomposition import PCA
-
PCA(n_components=None)
-
主成分分析
-
n_components:
-
實參為小數時:表示降維后保留百分之多少的信息
-
實參為整數時:表示減少到多少特征
-
-
from sklearn.decomposition import PCA
data = [[2,18,4,5],[6,32,10,8],[5,43,93,1]]
# 信息保留50% 但是不確定會保留幾個
pca = PCA(n_components=0.5)
data = pca.fit_transform(data)
print(data)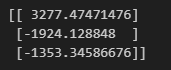
#鳶尾花 特征降維
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
x,y = load_iris(return_X_y=True)
pca = PCA(n_components=2)
# pca.fit(x)
# x_pca = pca.transform(x)
x = pca.fit_transform(x)
print(x.shape)
print(x)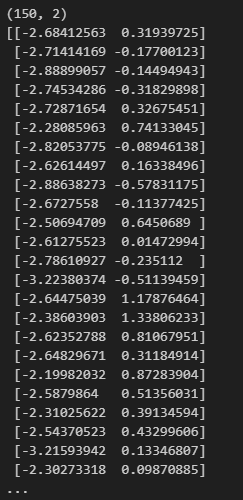
![[數據庫之十一] 數據庫索引之聯合索引](http://pic.xiahunao.cn/[數據庫之十一] 數據庫索引之聯合索引)
簡介)














四個基本公式推導)


