前言:隨著互聯網的發展,前端技術也在不斷變化,數據的加載方式也不再是單純的服務端渲染了。現在你可以看到很多網站的數據可能都是通過接口的形式傳輸的,或者即使不是接口那也是一些 JSON 的數據,然后經過 JavaScript 渲染得出來的。
這時,如果你還用 requests 來爬取內容,那就不管用了。因為requests 爬取下來的只能是服務器端網頁的源碼,這和瀏覽器渲染以后的頁面內容是不一樣的。因為,真正的數據是經過 JavaScript 執行后,渲染出來的,數據來源可能是 Aiax,也可能是頁面里的某些 Data,或者是一些 ifame 頁面等。不過,大多數情況下極有可能是 Aiax 接口獲取的。
所以,很多情況我們需要分析 Aiax請求,分析這些接口的調用方式,通過抓包工具或者瀏覽器的"開發者工具”,找到數據的請求鏈接,然后再用程序來模擬。但是,抓包分析流的方式,也存在一定的缺點。因為有些接口帶著加密參數,比如 token、sign 等等,模擬難度較大;
那有沒有一種簡單粗暴的方法,這時 Puppeteer、Pyppeteer、Selenium、Splash 等自動化框架出現了。使用這些框架獲取HTML源碼,這樣我們爬取到的源代碼就是JavaScript 渲染以后的真正的網頁代碼,數據自然就好提取了。同時,也就繞過分析 Ajax 和-些 JavaScript 邏輯的過程。這種方式就做到了可見即可爬,難度也不大,同時適合大批量的采集。
Selenium,作為一款知名的Web自動化測試框架,支持大部分主流瀏覽器,提供了功能豐富的API接口,常常被我們用作爬蟲工具來使用。然而selenium的缺點也很明顯,比如速度太慢、對版本配置要求嚴苛,最麻煩是經常要更新對應的驅動
1,selenium
1.1 安裝
由于sleenium4.1.0需要python3.7以上方可支持,請注意自己的python版本。
方式1:pip安裝
Python3.x安裝后就默認就會有pip (pip.exe默認在python的Scripts路徑下),打開 cmd,使用pip安裝。
pip install selenium
首次安裝會有進度條,而且裝出來是多個包(依賴于其他第三方庫)。如果安裝慢(默認連接官網),可以指定國內源。
pip install selenium -i Simple Index
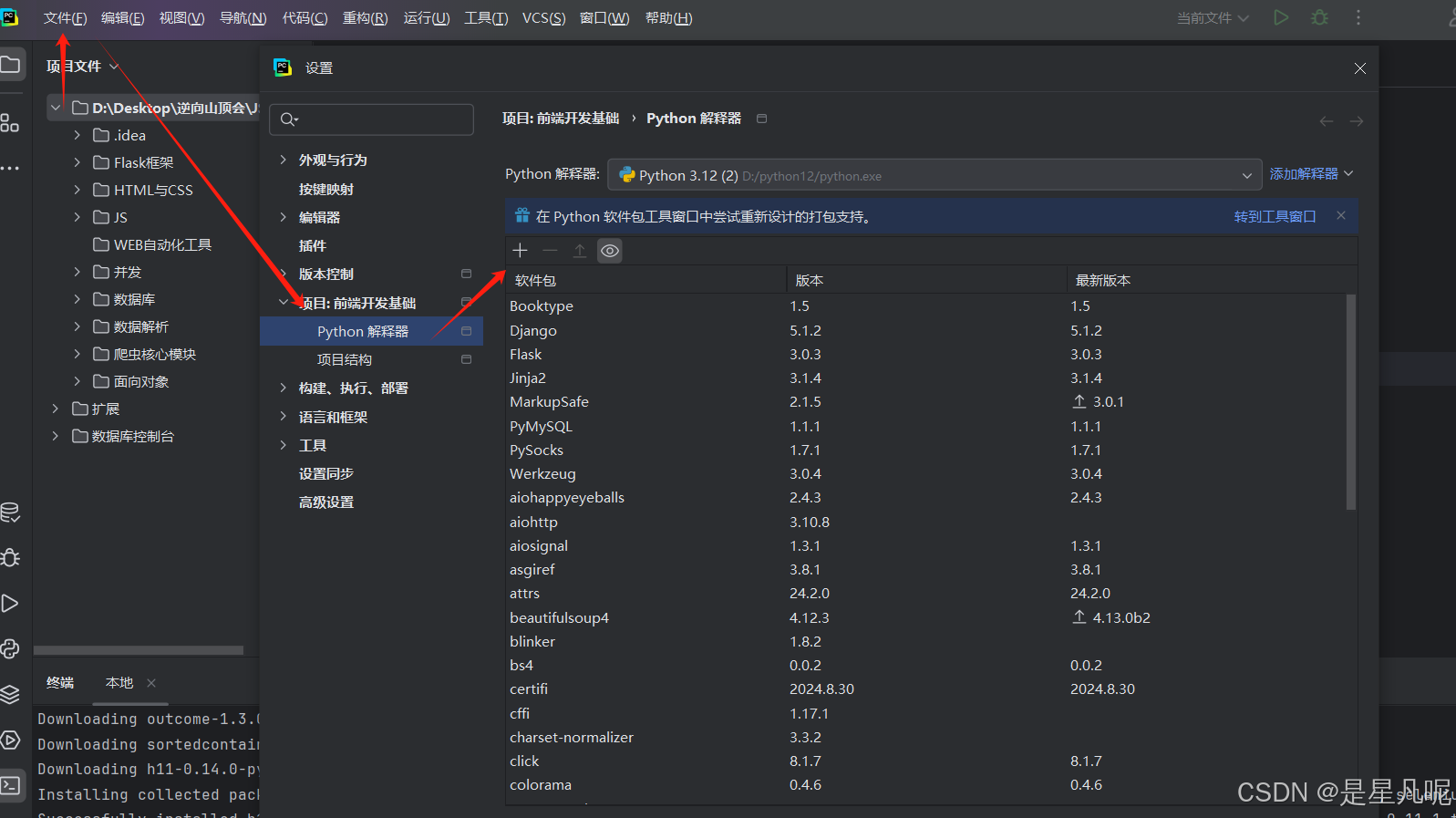
方式2:Pycharm安裝
Pycharm-File-Setting-Project:xxxx-Python Interpreter,點擊+號
下載瀏覽器驅動
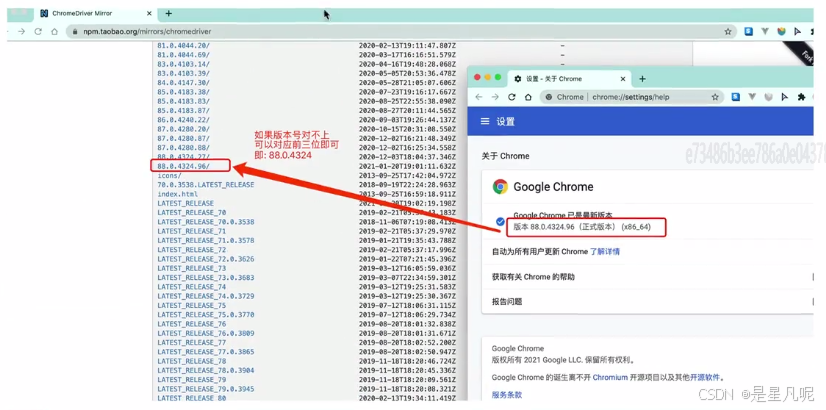
chrome驅動地址:
http://chromedriver.storage.googleapis.com/index.html
==========================
安裝對應驅動
Microsoft Edge WebDriver | Microsoft Edge Developer
檢查瀏覽器版本,下載對應版本驅動
1.2 quick start
selenium最初是一個自動化測試工具,而爬蟲中使用它主要是為了解決rpquests無法直接執行javaScript代碼的問題 selenium本質是通過驅動瀏覽器,完全模擬瀏覽器的操作,比如跳轉、輸入、點擊、下拉等,來拿到網頁渲染之后的結果,可支持多種瀏覽器安裝pip包
import time
from selenium import webdriver # 按照什么方式查找 By.ID
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 鍵盤按鍵操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait ## edge_driver_path = 'D:\python12'
edge_data = webdriver.Edge()
edge_data.get("https://www.baidu.com")
input_tag = edge_data.find_element(By.ID, 'kw') #百度的搜索輸入框ID是kwinput_tag.send_keys('hellokitty')
time.sleep(2)# 關閉瀏覽器
edge_data.quit()
?1.2.1 元素定位
方式1
el = driver.find element by xxx(value)方式2:推薦
from selenium.webdriver.common.by import By
driver.find element(By.xxx,value)
driver.find elements(Byxx,value)# 返回列表八種方式:
id
nawe
class
tag
link
partial
xpath
Css1.2.2 元素操作(節點交互)
Selenium可以驅動瀏覽器來執行一些操作,也就是說可以讓瀏覽器模擬執行一些動作。比較常見的用法有:輸入文字時用 send _keys()方法,清空文字時用clear()方法,點擊按鈕時用 click()方法。示例如下:
find_element方法僅僅能夠獲取元素對象,接下來就可以對元素執行以下操作 從定位到的元素中提取數據的方法
-
從定位到的元素中獲取數據
el.get_attribute(key)
el.text獲取key屬性名對應的屬性值
獲取開閉標簽之間的文本內容
-
對定位到的元素的操作
el.click() # 對元素執行點擊操作
el.submit() # 對元素執行提交操作
el.clear() # 清空可輸入元素中的數據
el.send_keys(data) # 向可輸入元素輸入數據1.2.3 動作鏈
在上面的實例中,一些交互動作都是針對某個節點執行的。比如,對于輸入框,我們就調用它的輸入文字和清空文字方法;對于按鈕,就調用它的點擊方法。其實,還有另外一些操作,它們沒有特定的執行對象,比如鼠標拖曳、鍵盤按鍵等,這些動作用另一種方式來執行,那就是動作鏈。
比如,現在實現一個節點的拖曳操作,將某個節點從一處拖曳到另外一處,可以這樣實現
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import Bydriver = webdriver.Edge()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get('http://sahitest.com/demo/dragDropMooTools.htm')dragger = driver.find_element(By.ID,'dragger') # 被拖拽元素item1 = driver.find_element(By.XPATH,'//div[text()="item_1"]') #目標元素1
item2 = driver.find_element(By.XPATH,'//div[text()="item_2"]')# 目標2
item3 = driver.find_element(By.XPATH,'//div[text()="item_3"]')# 目標3
item4 = driver.find_element(By.XPATH,'//div[text()="item_4”]') #目標4
action = ActionChains(driver)
action.drag_and_drop(dragger,item1).perform() #1.移動dragger到目標1
sleep(2)
action.click_and_hold(dragger).release(item2).perform() #2.效果與上句相同,也能起到移動效果
sleep(2)
action.click_and_hold(dragger).move_to_element(item3).release().perform() #3,效果與上兩句相同,也能起到移動的效果
sleep(2)
action.click_and_hold(dragger).move_by_offset(800,0).release().perform()
sleep(2)
driver.quit()1.2.4 執行JS
selenium并不是萬能的,有時候頁面上操作無法實現的,這時候就需要借助JS來完成了
當頁面上的元素超過一屏后,想操作屏幕下方的元素,是不能直接定位到,會報元素不可見的。這時候需要借助滾動條來拖動屏幕,使被操作的元素顯示在當前的屏幕上。滾動條是無法直接用定位工具來定位的。selenium里面也沒有直接的方法去控制滾動條,這時候只能借助Js代碼了,還好selenium提供了一個操作js的方法:execute_script(),可以直接執行js的腳本。代碼如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(3)1.2.5 頁面等待
為什么需要等待
如果網站采用了動態html技術,那么頁面上的部分元素出現時間便不能確定,這個時候就可以設置一個等待時間,強制等待指定時間,等待結束之后進行元素定位,如果還是無法定位到則報錯
頁面等待的三種方法
-
強制等待
也叫線程等待,通過線程休眠的方式完成的等待,如等待5秒: Thread sleep(5000),一般情況下不太使用強制等待,主要應用的場景在于不同系統交互的地方。
import time time.sleep(n)
阻塞等待設定的秒數之后再繼續往下執行
-
顯式等待
也稱為智能等待,針對指定元素定位指定等待時間,在指定時間范圍內進行元素查找,找到元素則直接返回,如果在超時還沒有找到元素,則拋出異常,顯示等待是 selenium 當中比較靈活的一種等待方式,他的實現原理其實是通過 while 循環不停的嘗試需要進行的操作。
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 每隔 0.5s 檢查一次(默認就是 0.5s),最多等待 10 秒,否則報錯。如果定位到元素則直接結束等待,如果在10秒結束之后仍未定位到元素則報錯
chrome = webdriver.Edge()
# 發起請求
chrome.get('https://www.jd.com')
# 查找響應頁面中的某個標簽元素
img_s = chrome.find_elements(By.CLASS_NAME, "focus-item-img")
wait = WebDriverWait(chrome,10,0.5)
wait.until(EC.presence_of_element_located((By.ID, 'J goodsList')))- 隱式等待
隱式等待設置之后代碼中的所有元素定位都會做隱式等待通過implicity_wait完成的延時等待,注意這種是針對全局設置的等待,如設置超時時間為10秒,使用了implicitly_wait后,如果第一次沒有找到元素,會在10秒之內不斷循環去找元素,如果超過10秒還沒有找到,則拋出異常,隱式等待比較智能它可以通過全局配置,但是只能用于元素定位
driver.implicitly_wait(10) #在指定的n秒內每隔一段時間嘗試定位元素,如果n秒結束還未被定位出來則報錯注意:
Selenium顯示等待和隱式等待的區別
1、selenium的顯示等待原理:顯示等待,就是明確要等到某個元素的出現或者是某個元素的可點擊等條件,等不到,就一直等,除非在規定的時間之內都沒找到,就會跳出異常Exception
(簡而言之,就是直到元素出現才去操作,如果超時則報異常)
2、selenium的隱式等待
原理:隱式等待,就是在創建driver時,為瀏覽器對象創建一個等待時間,這個方法是得不到某個元素就等待一段時間,直到拿到某個元素位置。
注意:
在使用隱式等待的時候,實際上瀏覽器會在你自己設定的時間內部斷的刷新頁面去尋找我們需要的元素
1.2.6 selenium的其他操作
-
無頭瀏覽器
我們已經基本了解了selenium的基本使用了,但是呢,不知各位有沒有發現,每次打開瀏覽器的時間都比較長,這就比較耗時了.我們寫的是爬蟲程序.目的是數據,并不是想看網頁.那能不能讓瀏覽器在后臺跑呢?答案是可以的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") #設置窗口大小
web = Chrome(options=opt)-
selenium處理cookie
# 通過driver.get_cookies()能夠獲取所有的cookie
dictCookies=driver.get_cookies() #添加cookie
driver.add_cookie(dictCookies) #刪除-條cookie
driver.delete_cookie("CookieName") #刪除所有的cookie
driver.delete_all_cookies()-
頁面前進和后退
driver.forward() #前進
driver.back() #后退學
driver.refresh() #刷新
driver.close() #關閉當前窗口1.2.7 滑動驗證案例
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 按照什么方式査找
from selenium.webdriver.support import expected conditions as EC
from selenium.webdriver.support.wait import webDriverWait #等待頁面加載某些元素
import cv2
from urllib import request
from selenium.webdriver.comon.action chains import Actionchains2 ,pyppeteer
由于Selenium流行已久,現在稍微有點反爬的網站都會對selenium和webdriver進行識別,網站只需要在前端js添加一下判斷腳本,很容易就可以判斷出是真人訪問還是webdriver。雖然也可以通過中間代理的方式進行js注入屏蔽webdriver檢測,但是webdriver對瀏覽器的模擬操作(輸入、點擊等等)都會留下webdriver的標記,同樣會被識別出來,要繞過這種檢測,只有重新編譯webdriver,麻煩自不必說,難度不是一般大。由于Selenium具有這些嚴重的缺點。pyppeteer成為了爬蟲界的又一新星。相比于selenium具有異步加載、速度快、具備有界面/無界面模式、偽裝性更強不易被識別為機器人,同時可以偽裝手機平板等終端;雖然支持的瀏覽器比較單一,但在安裝配置的便利性和運行效率方面都要遠勝selenium。
-
pyppeteer的安裝
pyppeteer無疑為防爬墻撕開了一道大口子,針對selenium的淘寶、美團、文書網等網站,目前可通過該庫使用selenium的思路繼續突破,毫不費勁。
介紹Pyppeteer之前先說一下Puppeteer,Puppeteer是谷歌出品的一款基于Node.js開發的一款工具,主要是用來操縱Chrome瀏覽器的 APl,通過Javascript代碼來操縱Chrome瀏覽器,完成數據爬取、Web程序自動測試等任務。
pyppeteer是非官方 Python 版本的 Puppeteer 庫,瀏覽器自動化庫,由日本工程師開發
Puppeteer是 Google 基于 Node.js 開發的工具,調用 Chrome 的 API,通過 JavaScript代碼來操縱 Chrome 完成一些操作,用于網絡爬蟲、Web 程序自動測試等。
pyppeteer 使用了 Python 異步協程庫asyncio,可整合 Scrapy 進行分布式爬蟲。
puppet 木偶,puppeteer 操縱木偶的人。
pip3 install pyppeteer
使用之前需要運行下這個代碼
import pyppeteer.chromium_downloader
print('默認版本是:{}'.format(pyppeteer.__chromium_revision__))
print('可執行文件默認路徑:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64')))
print('win64平臺下載鏈接為:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))
查看電腦中間的可執行文件的默認的路徑,如果沒有需要建立相對應的文件夾,下面為下載路徑
下載完成之后需要將對應的解壓縮之后的文件夾放到上面的文件夾的目錄下面
commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/
-
pyppeteer滑動驗證案例
from pyppeteer import launch
import random
import asyncio
import cv2
from urllib import requestasync def get_track():big = cv2.imread("bigimg.jpg",0)small = cv2.imread("smallimg.jpg",0)# print("cv2:",small)res = cv2.matchTemplate(big, small, cv2.TM_CCOEFF_NORMED)value = cv2.minMaxLoc(res)[2][0]print(value)#需要通過渲染比計算出實際的距離return value * 342 / 360async def main():browser = await launch({"headless": False,"args":["--window-size=1920,1080"],})#打開新的標簽頁page = await browser.newPage()# 設置界面大小一致await page.setViewport({"width":1920, "height":1080})#訪問主頁await page.goto("https://passport.jd.com/new/login.aspx")await page.type("#loginname","18438371807",{"c":random.randint(30,60)})await page.type("#nloginpwd", "abc10000610", {"delay":random.randint(30, 60)})await page.waitFor(2000)await page.click("div.login-btn")await page.waitFor(2000)# page.Jeval(selector,pageFunction) # 定位元素,并調用js函數去執行big_img = await page.Jeval(".JDJRV-bigimg > img","el=>el.src")small_img = await page.Jeval(".JDJRV-smallimg > img", "el=>el.src")# 下載圖片request.urlretrieve(big_img, 'bigimg.jpg')request.urlretrieve(small_img, 'smallimg.jpg')# 得到滑動的距離distance = int(await get_track())print("distance:", distance)# Pyppeteer 三種解析方式# Page.querySelector() # 選擇器# Page.querySelectorAll()# Page.xpath() #xpath 表達式# 簡寫方式為:# Page.J(), Page.j](), and Page.Jx()el = await page.J("div.JDJRV-slide-btn")#獲取元素的邊界框box = await el.boundingBox()await page.hover("div.JDJRV-slide-btn")await page.mouse.down()# steps 是指分成幾步來完威 steps越大,滑動速度越慢await page.mouse.move(box["x"] + distance + random.uniform(30,33), box["y"], {"steps":100})await page.waitFor(2000)await page.mouse.move(box["x"] + distance + 29, box["y"], {"steps": 100})await page.mouse.up()await page.waitFor(2000)if __name__ == "__main__":asyncio.get_event_loop().run_until_complete(main())


















