機器學習(Machine Learning)
簡要聲明
基于吳恩達教授(Andrew Ng)課程視頻
BiliBili課程資源
文章目錄
- 機器學習(Machine Learning)
- 簡要聲明
- 摘要
- 過擬合與欠擬合問題
- 一、回歸問題中的過擬合
- 1. 欠擬合(Underfit)
- 2. 剛好擬合(Just right)
- 3. 過擬合(Overfit)
- 二、分類問題中的過擬合
- 1. 欠擬合(Underfit)
- 2. 剛好擬合(Just right)
- 3. 過擬合(Overfit)
- 三、過擬合的原因及解決方法
- 過擬合原因
- 解決方法
- 解決過擬合問題
- 一、收集更多訓練數據
- 二、選擇特征
- 三、正則化
- 四、過擬合解決方法總結
- 正則化的應用
- 一、帶正則化的代價函數
- 二、正則化線性回歸
- 三、正則化邏輯回歸
- 四、正則化參數的選擇
- 五、正則化方法對比
摘要
本文介紹了機器學習中的過擬合和欠擬合問題,通過回歸和分類問題展示了不同擬合程度的表現。針對過擬合問題,提出了增加訓練數據、特征選擇、正則化等解決方法,并討論了正則化在線性回歸和邏輯回歸中的應用,包括帶正則化的代價函數和梯度下降更新規則。最后,對比了正則化方法的優缺點,強調合理應用正則化技術對提高模型泛化能力的重要性。
過擬合與欠擬合問題
在機器學習中,過擬合是一個常見的問題,它導致模型在訓練數據上表現很好,但在新的、未見過的數據上表現不佳。以下是對過擬合問題的詳細探討。
一、回歸問題中的過擬合
考慮一個簡單的回歸問題,嘗試用不同復雜度的模型來擬合數據。
1. 欠擬合(Underfit)
- 模型表達式: y = w 1 x + b y = w_1x + b y=w1?x+b
- 特征:僅使用輸入變量的一次項。
- 表現:模型無法很好地擬合訓練數據,存在高偏差(high bias)。
2. 剛好擬合(Just right)
- 模型表達式: y = w 1 x + w 2 x 2 + b y = w_1x + w_2x^2 + b y=w1?x+w2?x2+b
- 特征:使用輸入變量的一次項和二次項。
- 表現:模型很好地擬合了訓練數據,具有良好的泛化能力(generalization)。
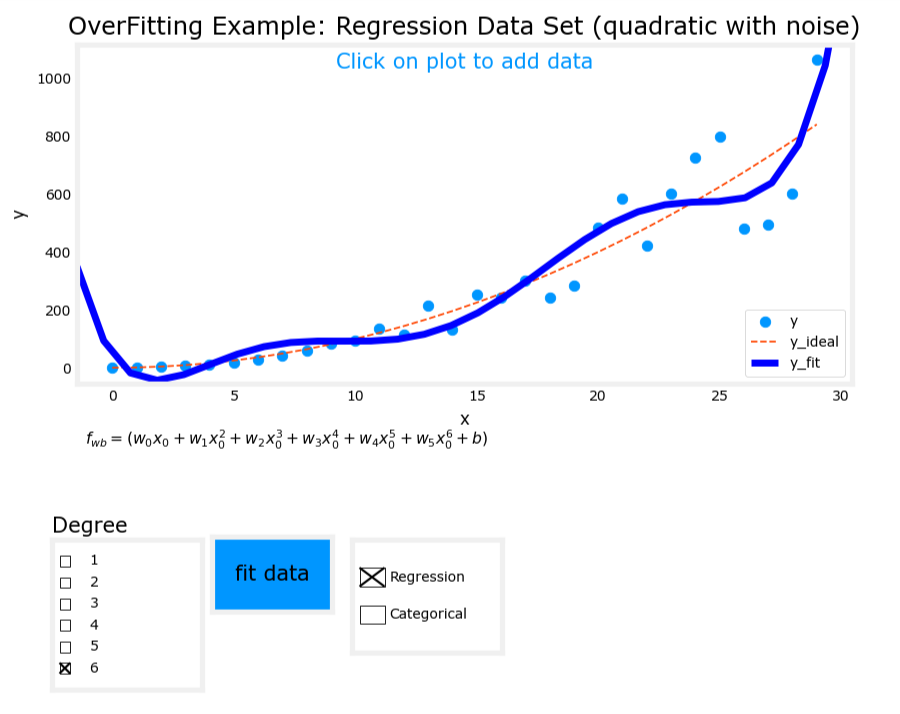
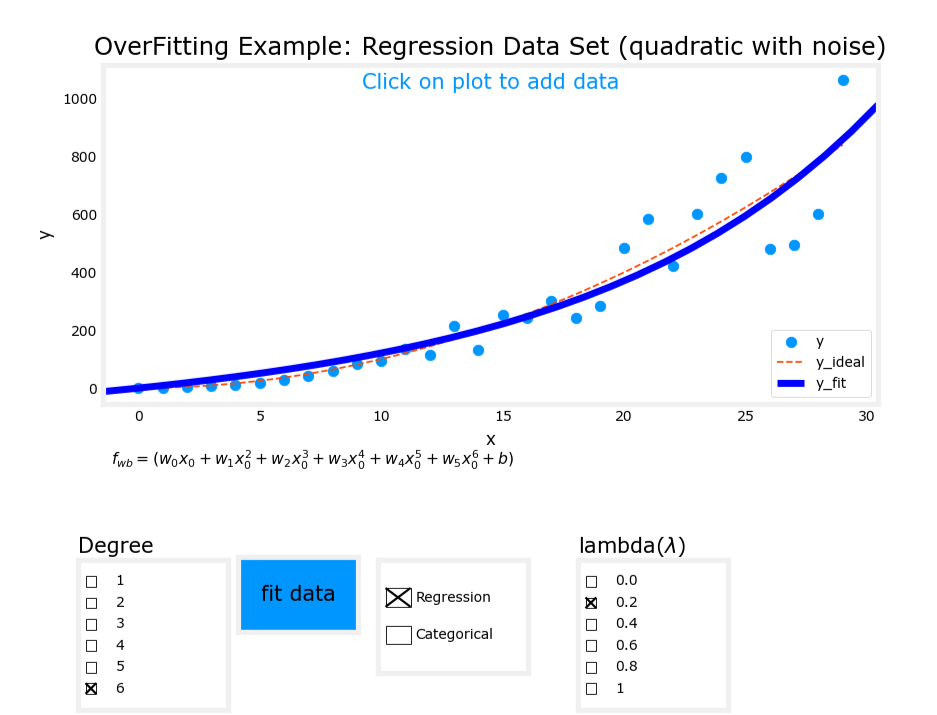
3. 過擬合(Overfit)
- 模型表達式: y = w 1 x + w 2 x 2 + w 3 x 3 + w 4 x 4 + b y = w_1x + w_2x^2 + w_3x^3 + w_4x^4 + b y=w1?x+w2?x2+w3?x3+w4?x4+b
- 特征:使用了過多的高次項。
- 表現:模型在訓練數據上擬合得非常好,但存在高方差(high variance),泛化能力差。
圖像對比
欠擬合
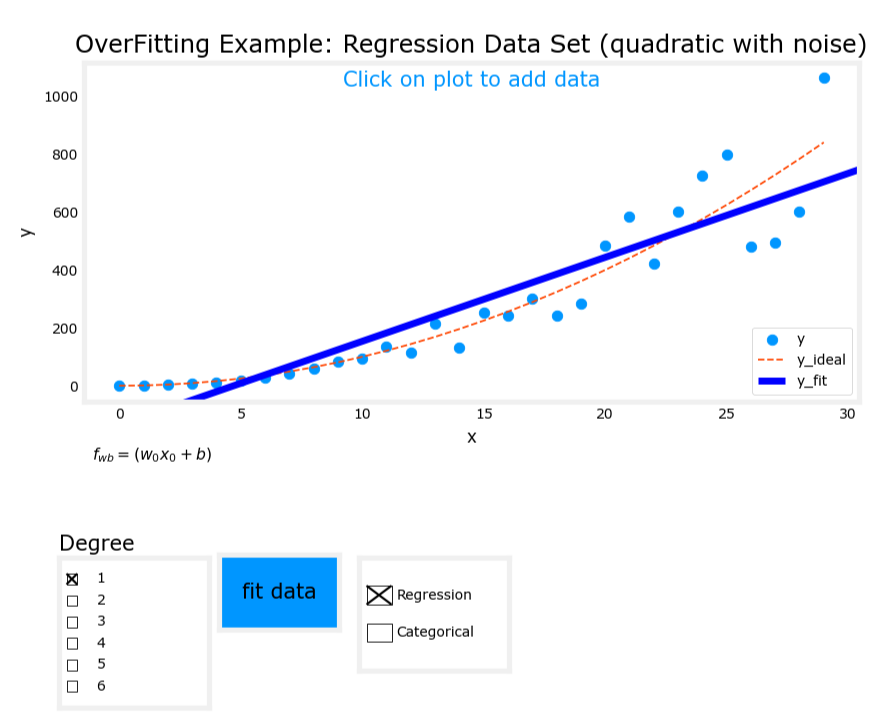
剛好擬合
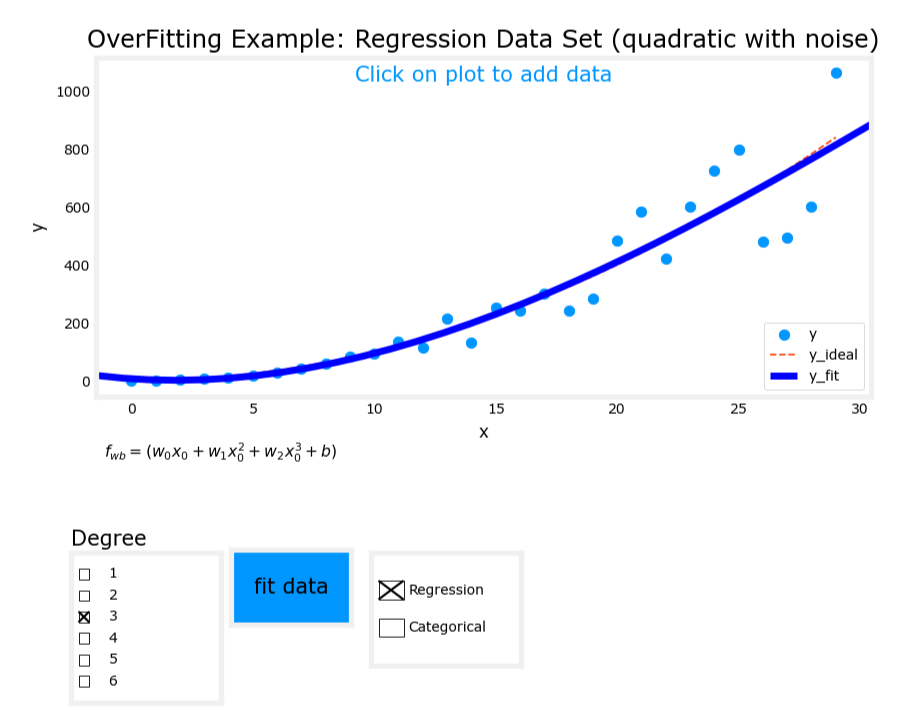
過擬合
二、分類問題中的過擬合
在分類問題中,過擬合問題同樣存在。
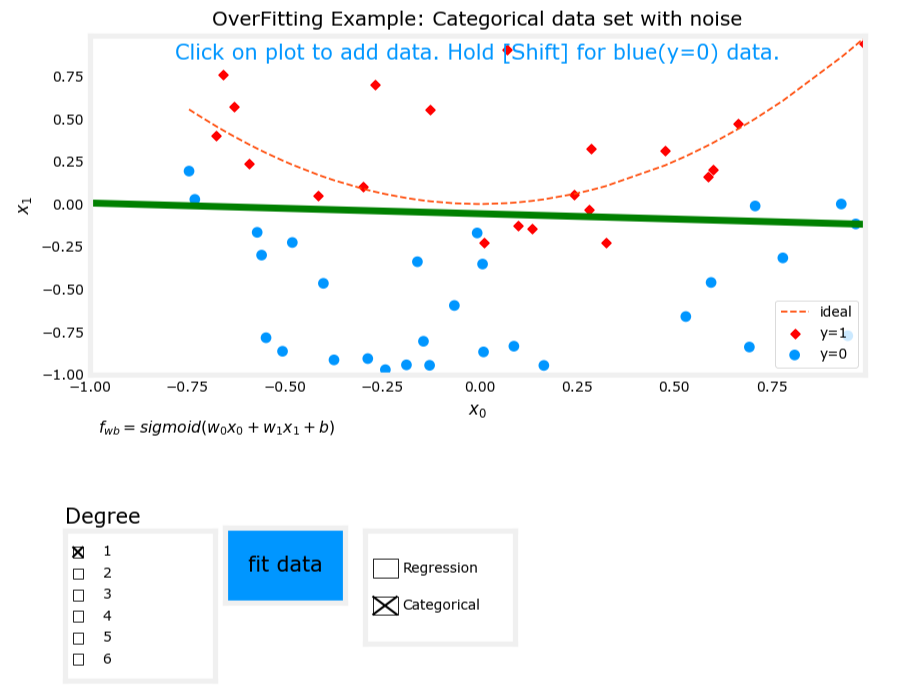
1. 欠擬合(Underfit)
- 模型表達式: z = w 1 x 1 + w 2 x 2 + b z = w_1x_1 + w_2x_2 + b z=w1?x1?+w2?x2?+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b?(x)=g(z),其中(g)是Sigmoid函數。
- 特征:僅使用線性特征。
- 表現:模型無法很好地劃分數據,存在高偏差(high bias)。
2. 剛好擬合(Just right)
- 模型表達式: z = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2 + b z = w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1x_2 + b z=w1?x1?+w2?x2?+w3?x12?+w4?x22?+w5?x1?x2?+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b?(x)=g(z)。
- 特征:使用二次項特征。
- 表現:模型能夠很好地劃分不同類別的數據。
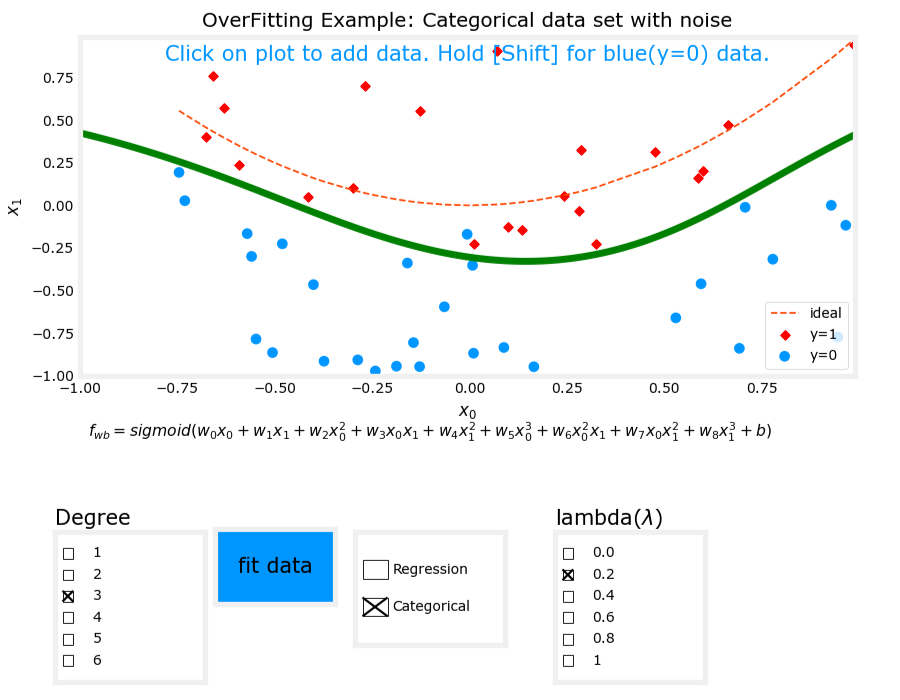
3. 過擬合(Overfit)
- 模型表達式: z = w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 3 x 2 + w 6 x 1 3 x 2 2 + ? + b z = w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1^3x_2 + w_6x_1^3x_2^2 + \cdots + b z=w1?x1?+w2?x2?+w3?x12?+w4?x22?+w5?x13?x2?+w6?x13?x22?+?+b, f w , b ( x ) = g ( z ) f_{\mathbf{w},b}(\mathbf{x}) = g(z) fw,b?(x)=g(z)。
- 特征:使用了過多的高次交叉項。
- 表現:模型在訓練數據上表現完美,但在新數據上表現不佳,存在高方差(high variance)。
圖像對比
欠擬合
剛好擬合
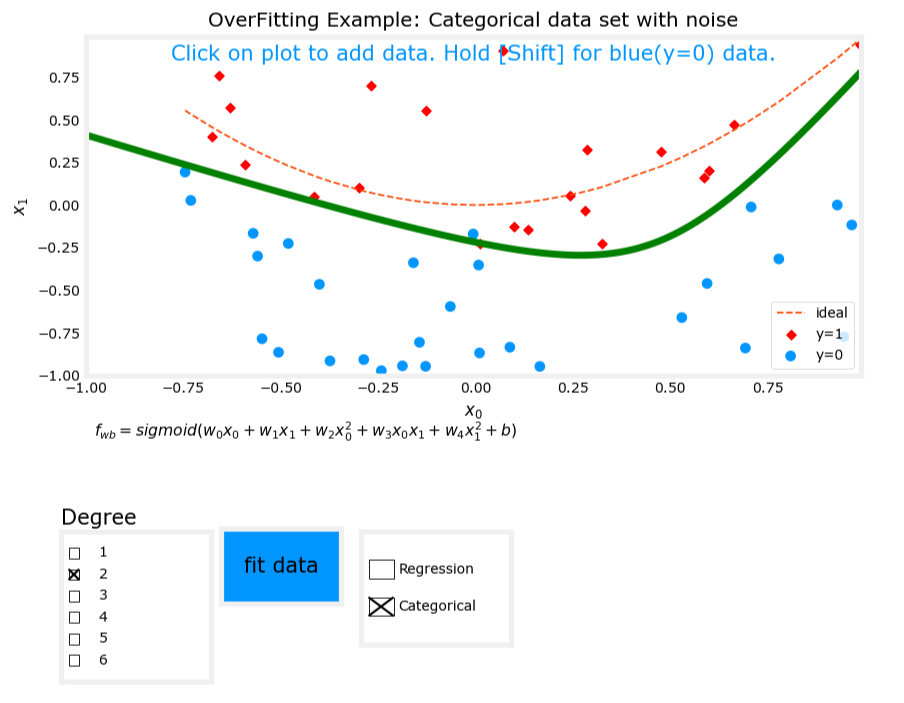
過擬合
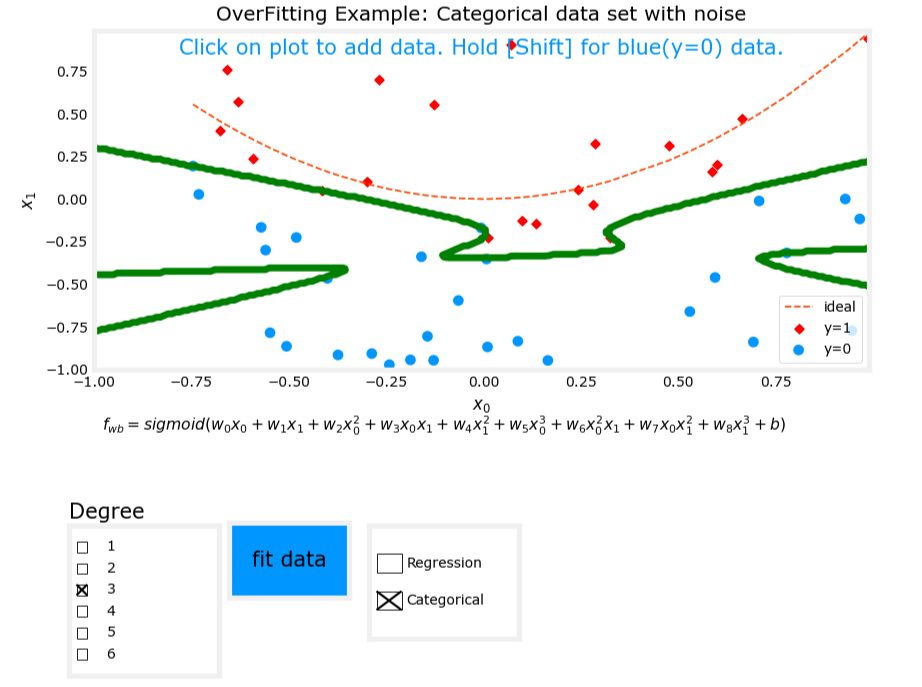
三、過擬合的原因及解決方法
過擬合原因
- 模型復雜度過高
- 訓練數據量不足
- 特征過多或噪聲特征
解決方法
| 方法 | 說明 |
|---|---|
| 增加訓練數據 | 更多樣化的數據有助于模型學習到更通用的模式。 |
| 減少特征數量 | 通過特征選擇或降維技術減少輸入特征的數量。 |
| 正則化 | 通過在損失函數中添加正則化項(如L1或L2正則化)來限制模型復雜度。 |
| 交叉驗證 | 使用交叉驗證技術評估模型在不同數據集上的表現,避免過擬合。 |
| 早停 | 在訓練過程中,當驗證集性能不再提升時提前停止訓練。 |
解決過擬合問題
一、收集更多訓練數據
增加訓練數據量是解決過擬合的一種有效方法。更多的數據可以幫助模型學習到更通用的模式,減少過擬合的風險。
- 原理:更多的訓練樣本可以提供更全面的信息,使模型更好地泛化。
- 示例:如果模型在有限的房屋價格數據上過擬合,增加更多不同大小、價格的房屋數據可以使模型更準確地預測新數據。
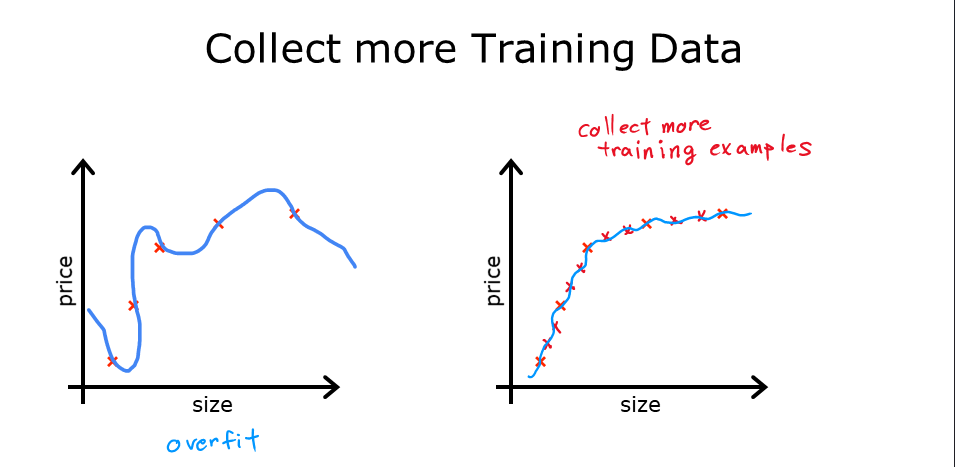
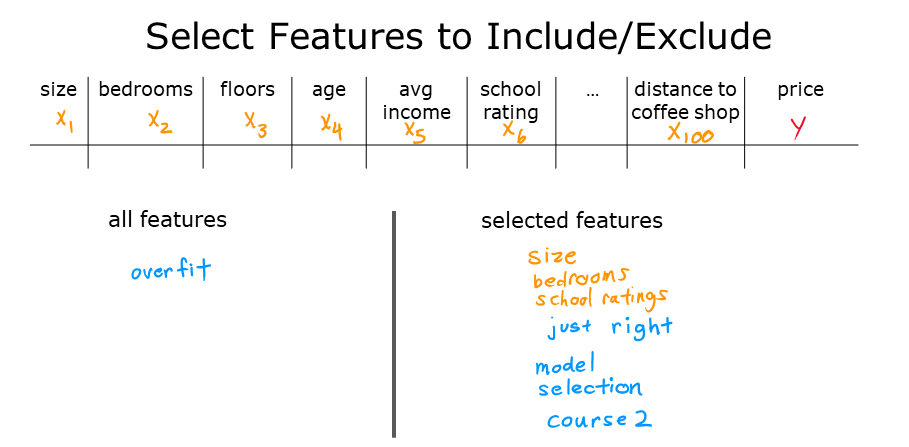
二、選擇特征
選擇合適的特征可以減少模型的復雜度,從而降低過擬合的可能性。
- 特征選擇:從眾多特征中選擇最相關的特征,去除無關或冗余的特征。
- 優點:減少模型復雜度,提高訓練速度。
- 缺點:可能丟失一些有用的信息。
| 特征選擇方法 | 說明 |
|---|---|
| Filter Methods | 通過相關性分析等方法預選特征 |
| Wrapper Methods | 通過模型性能評估選擇特征組合 |
| Embedded Methods | 在模型訓練過程中自動選擇特征 |
三、正則化
正則化是一種通過在損失函數中添加懲罰項來限制模型復雜度的方法。
- L1正則化:添加參數的絕對值之和。公式為: λ ∑ j = 1 n ∣ w j ∣ \lambda \sum_{j=1}^{n} |w_j| λj=1∑n?∣wj?∣
- L2正則化:添加參數的平方和。公式為: λ ∑ j = 1 n w j 2 \lambda \sum_{j=1}^{n} w_j^2 λj=1∑n?wj2?
- 作用:使參數值更小,減少模型對單個特征的依賴。
| 正則化方法 | 優點 | 缺點 |
|---|---|---|
| L1正則化 | 可進行特征選擇,稀疏性好 | 收斂速度較慢 |
| L2正則化 | 收斂速度快,穩定性好 | 無法進行特征選擇 |
四、過擬合解決方法總結
| 方法 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|
| 收集更多數據 | 訓練數據量不足時 | 提高模型泛化能力 | 數據收集成本高 |
| 特征選擇 | 特征數量多且存在冗余特征時 | 減少模型復雜度,提高訓練速度 | 可能丟失有用信息 |
| 正則化 | 模型參數量大,容易過擬合時 | 有效控制模型復雜度,提高泛化能力 | 需要調整正則化參數 |
| 交叉驗證 | 數據集有限,需要充分利用數據進行模型評估時 | 減少數據浪費,提高模型評估準確性 | 計算成本高 |
| 早停 | 模型訓練時間長,容易過擬合時 | 防止模型在訓練集上過優化,保存較好的泛化能力 | 需要確定合適的停止點 |
正則化的應用
一、帶正則化的代價函數
在帶正則化的代價函數中,我們在原始代價函數的基礎上添加了一個正則化項。對于線性回歸模型,其帶正則化的代價函數形式如下:
J ( w , b ) = 1 2 m ∑ i = 1 m ( f w , b ( x ( i ) ) ? y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = \frac{1}{2m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right)^2 + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=2m1?i=1∑m?(fw,b?(x(i))?y(i))2+2mλ?j=1∑n?wj2?
其中:
- m m m是訓練樣本的數量
- n n n 是特征的數量
- λ \lambda λ 是正則化參數,用于控制正則化的強度
正則化項 λ 2 m ∑ j = 1 n w j 2 \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 2mλ?∑j=1n?wj2? 會懲罰過大的參數值,使模型更傾向于學習較小的參數,從而降低模型的復雜度。
二、正則化線性回歸
在正則化線性回歸中,我們通過梯度下降算法來最小化帶正則化的代價函數。其梯度下降的更新規則如下:
w j = w j ? α [ 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) ? y ( i ) ) x j ( i ) + λ m w j ] w_j = w_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} + \frac{\lambda}{m} w_j \right] wj?=wj??α[m1?i=1∑m?(fw,b?(x(i))?y(i))xj(i)?+mλ?wj?]
b = b ? α 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) ? y ( i ) ) b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) b=b?αm1?i=1∑m?(fw,b?(x(i))?y(i))
其中:
- α \alpha α是學習率
- w j w_j wj? 是特征 ( j ) 的參數
- b b b是偏置項
在梯度下降過程中,正則化項會使得參數 w j w_j wj?在每次更新時都乘以一個因子 ( 1 ? α λ m ) (1 - \alpha \frac{\lambda}{m}) (1?αmλ?),從而實現參數的“收縮”。
| 正則化線性回歸與普通線性回歸對比 | 正則化線性回歸 | 普通線性回歸 |
|---|---|---|
| 更新規則 | 包含正則化項 | 不包含正則化項 |
| 參數變化 | 參數逐漸收縮 | 參數無收縮 |
| 泛化能力 | 更強 | 較弱 |
三、正則化邏輯回歸
正則化邏輯回歸與正則化線性回歸類似,其代價函數也包含一個正則化項。對于邏輯回歸模型,其帶正則化的代價函數形式如下:
J ( w , b ) = ? 1 m ∑ i = 1 m [ y ( i ) log ? ( f w , b ( x ( i ) ) ) + ( 1 ? y ( i ) ) log ? ( 1 ? f w , b ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\mathbf{w},b}(\mathbf{x}^{(i)})) + (1 - y^{(i)}) \log(1 - f_{\mathbf{w},b}(\mathbf{x}^{(i)})) \right] + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=?m1?i=1∑m?[y(i)log(fw,b?(x(i)))+(1?y(i))log(1?fw,b?(x(i)))]+2mλ?j=1∑n?wj2?
其中:
- ( f w , b ( x ( i ) ) ) ( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) ) (fw,b?(x(i))) 是邏輯回歸模型的預測輸出,使用Sigmoid函數計算得到
正則化邏輯回歸的梯度下降更新規則與正則化線性回歸類似,也是在原始梯度的基礎上添加了正則化項。
四、正則化參數的選擇
正則化參數 λ \lambda λ 的選擇對模型的性能有重要影響:
- λ \lambda λ 過小:正則化效果不明顯,模型可能仍然過擬合
- λ \lambda λ 過大:過度正則化,模型可能欠擬合
可以通過交叉驗證的方法來選擇合適的 λ \lambda λ 值。
五、正則化方法對比
| 正則化方法 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|
| L1正則化 | 特征稀疏 | 可進行特征選擇 | 收斂速度較慢 |
| L2正則化 | 參數平滑 | 收斂速度快 | 無法進行特征選擇 |
通過合理應用正則化技術,可以有效防止模型過擬合,提高模型的泛化能力和實際應用效果。
正則化后圖像
線性回歸
分類
end











:存儲數據的“排排坐”)
)

)
:Balking(猶豫模式))



