音頻處理領域的天花板被撕開了。
剛剛,kimi 發布全新通用音頻基礎模型 Kimi-Audio,這款由月之暗面(Moonshot AI)推出的開源模型,在 24 小時內收獲 3.2 萬星標,不僅以 1.28% 詞錯率刷新語音識別紀錄,更在情感分析、聲音事件分類等十項任務中碾壓其他競品,堪稱“六邊形戰士”——沒有短板,只有王炸。
“全能戰神”Kimi-Audio
傳統音頻模型往往專精單一任務:語音識別、情感分析、降噪……開發者需像拼樂高般組合多個工具。而 Kimi-Audio 的顛覆性在于,它用三層架構統一了音頻處理各項任務:
-
音頻分詞器: 將聲音轉化為離散語義token,保留聲學細節;
-
音頻大模型:基于Transformer處理多模態輸入,生成文本與音頻token;
-
音頻去分詞器:通過流匹配技術,將token轉化為自然聲波。
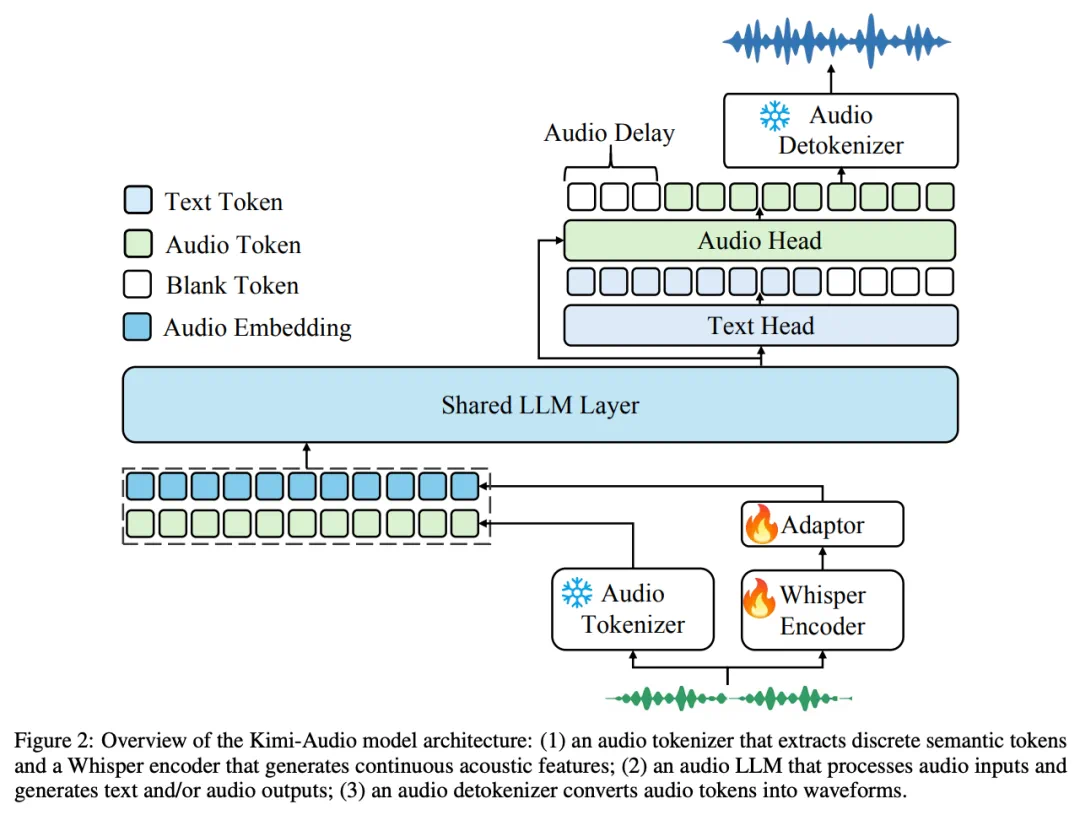
這種設計讓模型能同時處理語音識別、情感分析、環境聲分類等任務,完成了從音頻輸入到文本輸出的全過程,這已經超越了工具范疇,更像是擁有聽覺思維的智能體。
除了新穎的模型架構外,Kimi-Audio 在數據建構和訓練方法上也下足了功夫。
在預訓練階段,Kimi-Audio 使用了約?1300 萬小時覆蓋多語言、音樂、環境聲等多種場景的音頻數據,并搭建了一條自動處理流水線來生成高質量的長音頻-文本對。
這一龐大的數據集為模型的訓練提供了豐富的素材和多樣的場景模擬,使得模型能夠更好地適應各種復雜環境下的音頻處理任務。
在實際應用中的表現方面,研究者們基于評估工具包對 Kimi-Audio 在一系列音頻處理任務中的表現進行了詳細評估,包括自動語音識別(ASR)、音頻理解、音頻轉文本聊天和語音對話等。
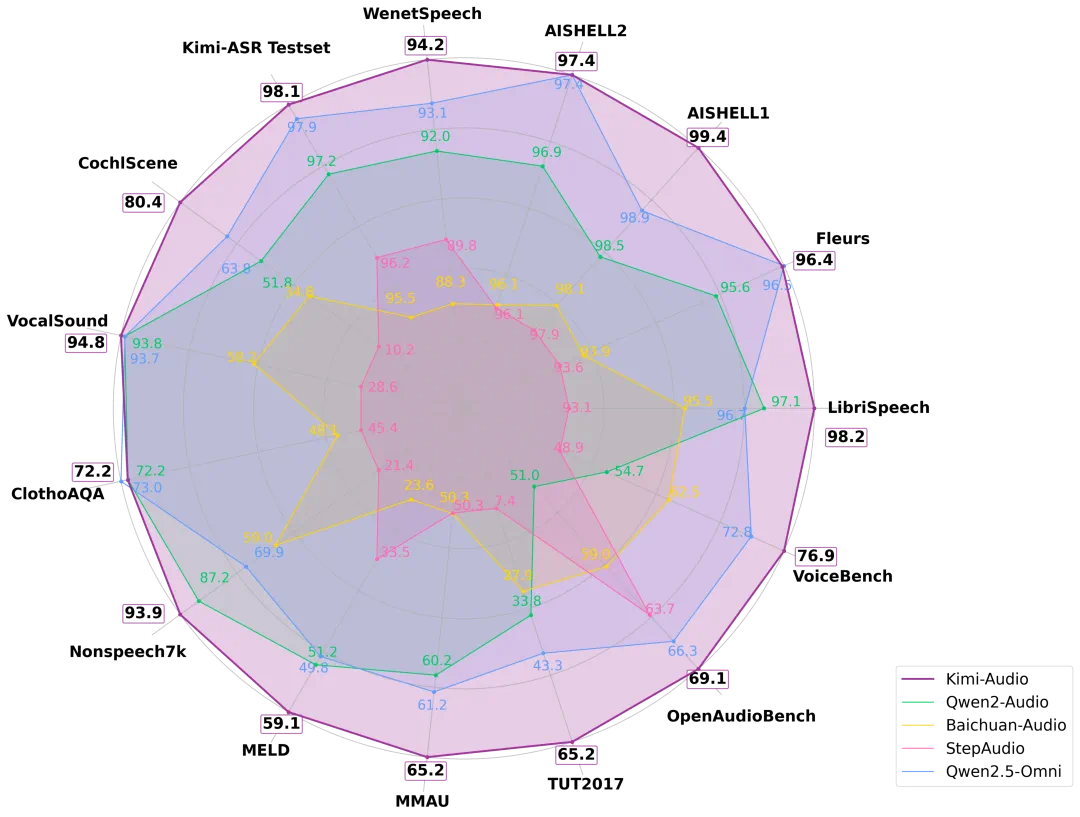
在自動語音識別方面,Kimi-Audio 在多種語言和聲學條件的多樣化數據集上均展現出了比以往模型更優越的性能。特別是在廣泛使用的LibriSpeech基準測試中,Kimi-Audio取得了最佳結果,在test-clean上達到了?1.28%?的錯誤率,在 test-other 上達到了?2.42%,顯著超越了其他同類模型。

在音頻理解方面,Kimi-Audio 也在 MMAU 基準測試中取得了高分;在 MELD 語音情感理解任務上,它以?59.13?的得分超越了其他模型。
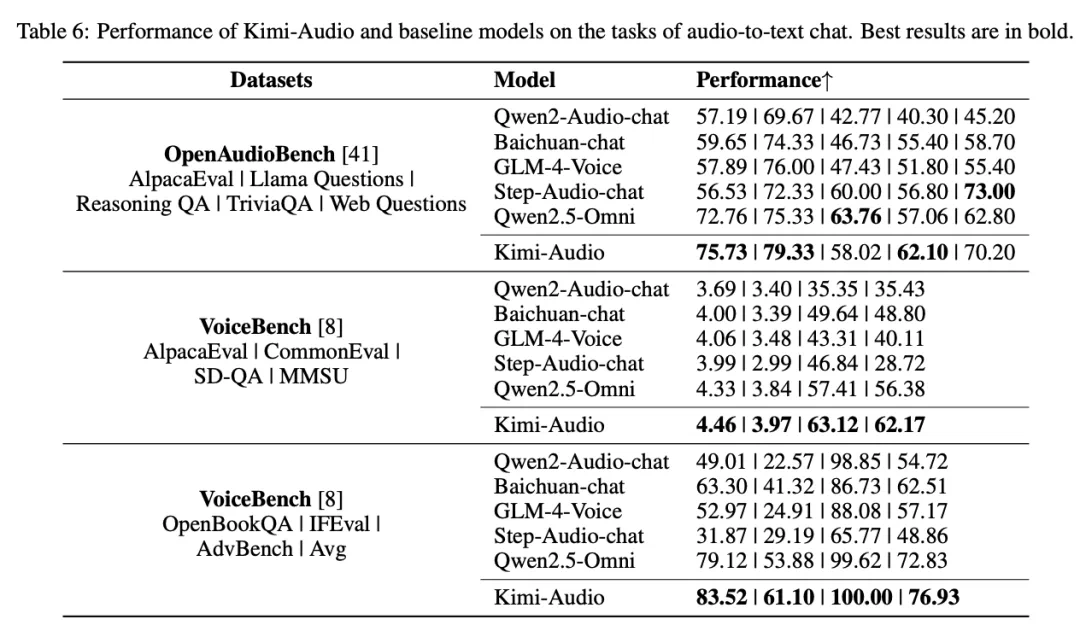
在音頻轉文本聊天和語音對話方面,Kimi-Audio同樣表現出色。在 OpenAudioBench 和 VoiceBench 基準測試中,Kimi-Audio 在多個子任務上實現了最先進的性能。
值得一提的是,Kimi-Audio的模型代碼、模型檢查點以及評估工具包已經在 Github 上開源,這使得更多的研究者和開發者能夠參與到音頻處理領域的研究中來,共同推動這一領域的進步和發展。
Kimi-Audio 的發布,恰逢 AI 多模態革命的臨界點。當 GPT-4o、Gemini 3.0 聚焦“視覺+文本”時,Kimi選擇押注被低估的聽覺賽道,為音頻技術領域帶來了新的突破和創新。
隨著技術的不斷進步和應用場景的不斷拓展,我們有理由相信AI大模型將在未來發揮更加重要的作用,AI應用也將滲透到更多場景中。


)













 + Ollama)


