最近研究了一下GraphRAG,寫了一個文檔轉換工具還有圖可視化工具,結合langchain構建RAG經驗,還有以前的數據平臺,做了一個知識庫概要設計,具體應用歡迎留言探討。
一、GraphRAG整體概述
GraphRAG圖基檢索增強生成,從原始文本中提取知識圖譜、構建社區層次結構、為這些社區生成摘要,然后在執行基于RAG的任務時利用這些結構。旨在利用知識圖譜和大語言模型(LLMs)來提升信息處理能力和問答能力。而標準RAG是一種基礎版本的檢索增強生成架構,采用前置處理流程,通過chunk方式來切割文檔,使用純文本片段的樸素語義進行搜索。
當面臨以下情況時,GraphRAG比標準RAG有更好的表現:當一些實體(名詞)占比比較小,通過標準RAG無法正確召回時;當希望通過實體關系正向和反向查詢內容,通過實體關系實現很正確召回時;通過GlobalSearch對整體進行總結和洞見時。
二、圖基檢索增強生成平臺架構

基本思路:
[用戶端]
│
▼
[文檔預處理層] → 統一文本化
│
▼
[GraphRAG索引管道] → 知識圖譜構建
│
▼
[檢索與問答引擎] → 用戶交互接口
1、文檔預處理模塊
輸入: 支持PDF(含掃描件)/DOCX/IMG/HTML/TXT等文件類型
處理流程:
主要利用Marker處理掃描版PDF(OCR識別),MarkitDown處理結構化文檔,使用LLM增強可以對于文檔中出現的圖片進行描述以及提高pdf掃描件的識別準確性和處理速度,最后統一輸出UTF-8編碼的TXT文件。
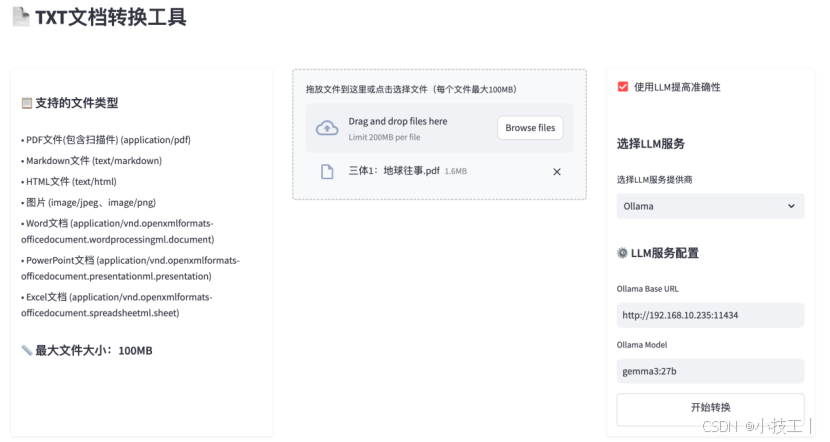
這個工程是利用streamlit構建的一個簡單的app,通過上傳一個或多個文件,轉換txt后批量下載一個zip文件。如果涉及掃描件或者圖譜建議勾選“使用LLM提高準確性”。
實踐挑戰:上述流程主要是對各類文檔進行文本提取,實際還需要對提取的文本進行清洗,提高文本質量,作為graphrag索引管道的輸入,文本質量關系著構建的知識圖譜的質量。
2、GraphRAG索引管道
**輸入:**經過預處理的txt文檔。
處理流程:
通過運行GraphRAG索引管道,會將輸入語料庫切成一系列TextUnits,這些TextUnits充當流程其余部分的可分析單元,并在我們的輸出中提供細粒度的引用。關于知識圖譜提取是使用配置的LLM(支持lm-studio本地大模型)來抽取這些實體、關系、社區等信息,使用Leiden 技術對圖形執行分層聚類,這有助于全面了解數據集。
下圖是基本的工作流:
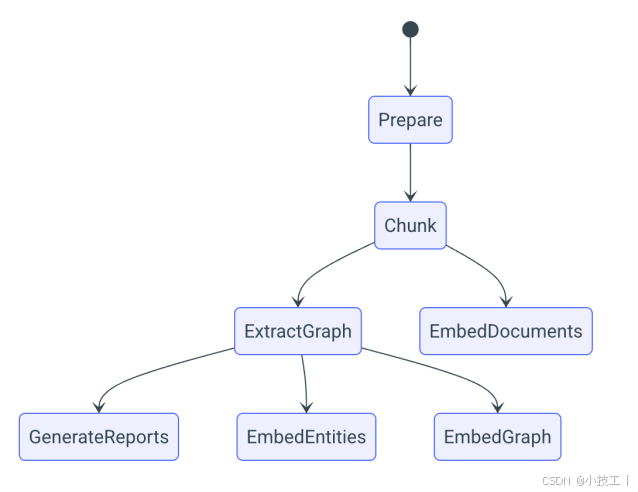
默認情況下,管道的輸出存儲為本地Parquet文件,嵌入將寫入默認配置的lancedb矢量存儲。
實踐挑戰:
- 知識圖譜提取需用到LLM,會消耗大量的token,估算token數量級是個挑戰。
- 實踐中使用的大模型不同,需要相應的優化提示詞,graphrag提供的prompt auto tune效果不太理想。實際測試下來,在社區報告提取過程中經常報錯,需要手動優化提示詞。
- 管道輸出的數據默認存儲在本地文件(parquet和lancedb),如果結合其他數據源通過langchain或llamaindex實現多路召回,則需要實現指定數據庫的接入。可以使用postgresql數據同AEG和pgvector拓展實現圖和向量查詢,或者分別接入單獨的圖數據庫和向量數據庫,例如neo4j和Milvus。
- 知識圖譜質量評估也是一個挑戰。不過可以通過圖形化展示很直觀的看到:點、邊、社區等信息。其次,就是提供給LocalSearch中對應的entitylD,GlobalSearch中的community reqportID引用信息,并根據這些ID獲取進一步信息,進行查詢和可視化展示。
下圖僅為知識圖譜可視化展示:
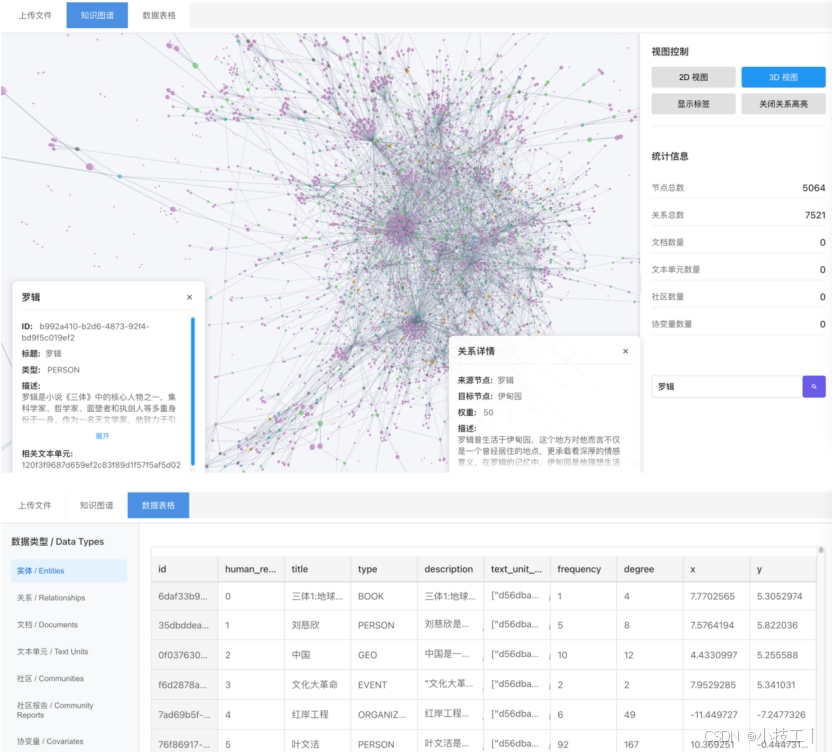
這個工程分成前后端,可以上傳對應的parque文件,存入postgres數據庫,前端查詢出實體和關系信息解析成2d或3d圖形,同時提供parque文件對應的table。其中主要使用 react-force-graph-2d 和 react-force-graph-3d來構建2d或3d圖形。目前可以通過查詢模式,或者點擊交互模式,找到對應節點信息和關系信息。
3、檢索與問答引擎
GraphRAG的查詢接口主要有LocalSearch、GlobalSearch和Driftsearch。
- LocalSearch主要是將知識圖譜中的結構化數據與輸入文檔中的非結構化數據相結合,能夠在查詢時使用相關實體信息來增強LLM上下文。它非常適合回答需要了解輸入文檔中提到的特定實體的問題。
- GlobalSearch主要使用來自圖的社區信息和社區報告作為LLM的上下文,對于需要聚合數據、集中信息來組成答案的全局查詢有很好的支持。
- Driftsearch具有靈活遍歷的動態推理,結合了全局搜索和本地搜索的特征,以平衡計算成本和質量結果的方法生成詳細的響應。
localsearch 和標準rag一樣,只查找相關實體縮關聯的社區信息,構建查詢上下文,對于全局類型的問題不能很好的回答。而GlobalSearch過程需要遍歷某一層的社區,如果對應的知識圖譜巨大的,社區很多的話,需要消耗大量的token,花費很長時間才能得到最終答案。DriftSearch就是在兩種采取一個權衡。
4、graphrag實踐挑戰
- 1)實際使用速度比較慢,主要原因包括:
- 初始化時間:加載知識圖譜
- 查詢復雜度:通過向量查詢實體,構建上下文
- LLM調用:調用LLM,生成token
時間成本、價格成本主要是在llm調用上,可以通過提示詞工程優化。目前能優化的點主要就是:提示詞優化和增加大語言模型的理解次數。
- 2)難以評估graphrag好壞,除了rag評估的主要指標,知識圖譜質量評估也是一個挑戰。
改進RAG的兩個方向:對數據進行處理,提高數據質量和索引。對檢索生成的結果進行評估。
5、檢索增強生成評估
Ragas 框架提供了一系列工具和技術,借助 Ragas可以合成生成一個多樣化的測試數據集客觀的衡量RAG系統性能。后面研究看看。



)
:項目的搭建與啟動)
:必要性、挑戰與實踐指南)
)












