目錄
簡介
安裝
LLama Factory界面介紹
數據格式要求
微調訓練
????????
????????今天在這里介紹一種常用的大模型微調框架——LLama Factory。
簡介
????????LLama Factory?是一個高效的界面化大語言模型微調工具庫,支持多種參數高效微調技術,提供簡潔接口和豐富示例,助力用戶快速定制和優化模型性能。
安裝
????????a.獲取并安裝 git 上的 LLama Factory?
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git????????b.創建一個 LLama Factory 的虛擬環境
conda create -n llamafactory python==3.10 -y????????c.換至 llamafactory 環境
source activate llamafactory????????d.找到從 git 上獲取的 LLama-Factory.zip,并解壓、安裝
unzip LLama-Factory.zip
cd LLama-Factory
pip install -e .????????至此,LLama Factory 安裝完畢。
LLama Factory界面介紹
????????將環境切換至 llamafactory,并切換到 LLama Factory 的目錄后,啟動 LLama Factory。
source activate llamafactory
cd /root/autodl-tmp/LLaMA-Factory
llamafactory-cli webui????????如果你使用的是 vscode 中的 remote 插件鏈接的服務器,由于 vscode 中自帶端口轉發,因此,你可以在你的電腦本地直接使用瀏覽器訪問 LLama Factory 的 web 界面。

? ? ? ? 打開之后的界面大致是這樣的:
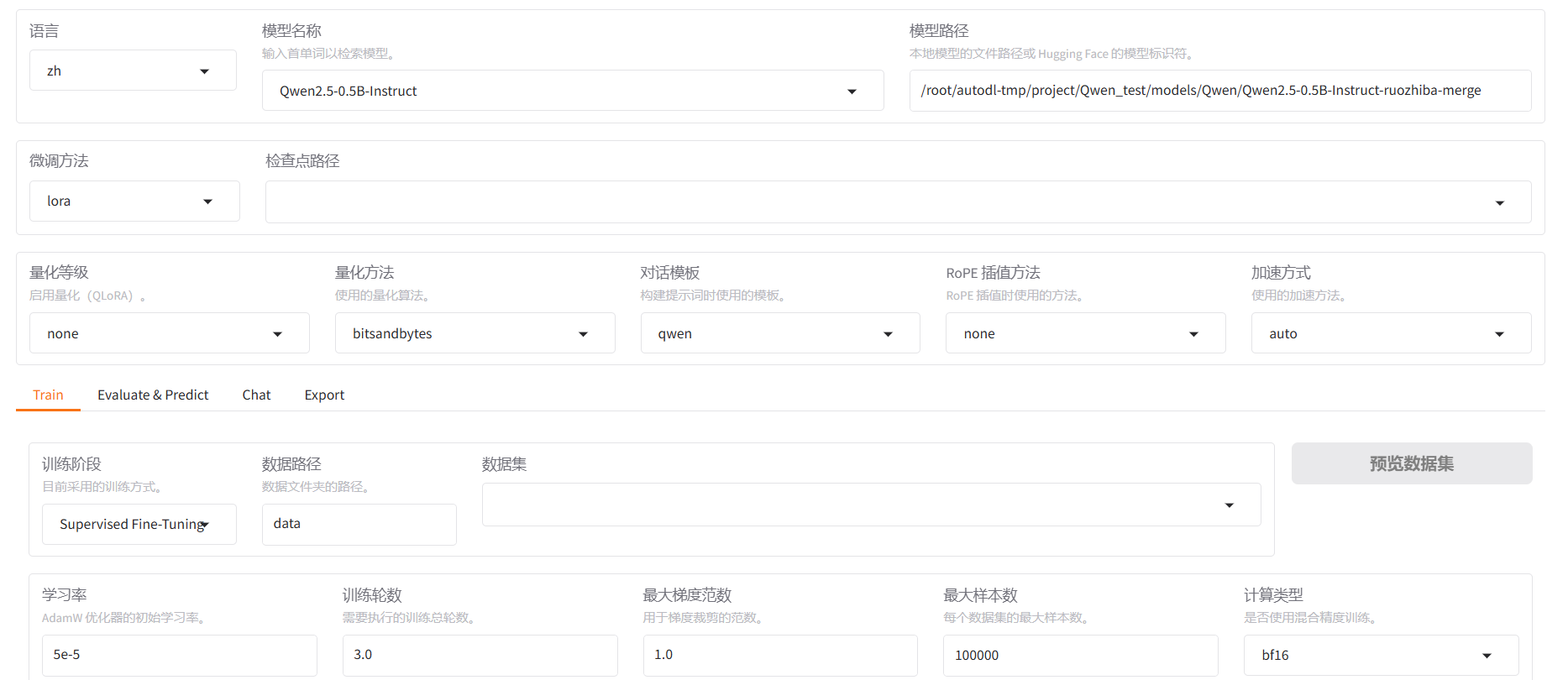
? ? ? ? 接下來,將對界面中的每一個參數進行介紹
? ? ? ? a.模型名稱:你所需要微調的模型的名稱(本參數是為了對應后面的對話模板)

? ? ? ? b.模型路徑:你所需要微調的模型的絕對路徑

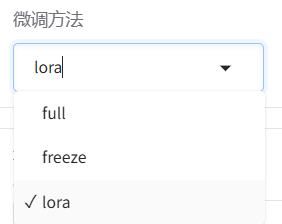
? ? ? ? c.微調方法
? ? ? ? ? ? ? ? full:全量微調——對整個預訓練模型的所有參數進行微調,適用于計算資源較為充足的情況
? ? ? ? ? ? ? ? freeze:凍結部分參數微調——凍結預訓練模型的大部分參數,僅微調部分頂層參數或新增的任務相關層
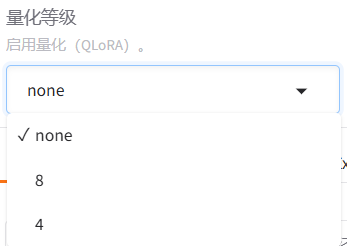
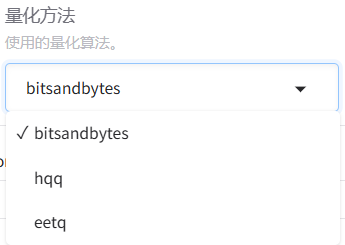
? ? ? ? ? ? ? ? LoRA:量化微調——將原模型分解為兩個低秩矩陣,通過微調低秩矩陣來間接微調原模型的參數。可以進一步選擇下方的量化等級,進行QLoRA微調。關于LoRA微調涉及的具體原理,后續單開一篇文章來進行介紹。
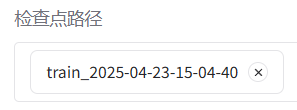
? ? ? ? d.檢查點路徑:如果你想繼承之前的訓練進度的話,可以選擇之前保存的某一輪參數,從該參數繼續進行訓練

? ? ? ? e.對話模板:用于控制模型的輸出規范。對話模板本身并不影響模型的性能,但是,如果模型在微調和推理時的對話模板不一致的話,可能會影響到模型最終的輸出效果。
? ? ? ? f.RoPE 插值方法:通過一種平滑的位置編碼方式,將模型的上下文窗口擴展到更遠的區域。LLama Factory 中可選的方式有:線性縮放位置索引(Linear)、動態調整縮放因子(Dynamic)、非均勻頻率調整(YaRN)和專門用于LLaMA3的優化插值(Llama3)。如果沒有特殊要求的話,通常選擇none就行。這里不再做過多贅述,如果有機會的話,以后單開一章進行詳細說明。
? ? ? ? g.加速方式:通過優化計算內核或引入高效算法,減少模型訓練和推理的時間開銷,同時節省顯存占用。
? ? ? ? auto:框架自動選擇當前環境支持的最優加速方案。
? ? ? ? flashattn2:一種高效計算 Transformer 模型中注意力機制的算法庫,通過優化 GPU 內存訪問模式和計算步驟,顯著加速注意力計算并減少顯存占用。
? ? ? ? unsloth:一個針對大模型微調(尤其是 LoRA)的輕量級優化庫,通過簡化計算圖和混合精度策略加速訓練。
? ? ? ? liger_kernel:LLaMA Factory 自研的輕量級加速內核,針對常見操作(如矩陣乘法、LayerNorm)進行底層優化。
? ? ? ? h.訓練階段:針對大語言模型(LLM)不同訓練目標和任務設計的特定流程。
? ? ? ? Supervised Fine-Tuning:在標注數據上微調預訓練模型,使其適配特定任務。
? ? ? ? Reward Modeling:訓練一個獎勵模型,用于評估生成內容的質量。
? ? ? ? PPO(Proximal Policy Optimization,近端策略優化):一種強化學習算法,通過最大化獎勵模型的反饋優化生成策略。
? ? ? ? DPO(Direct Preference Optimization,直接偏好優化):通過直接優化偏好數據調整模型策略。
? ? ? ? KTO (Kahneman-Tversky Optimization):基于行為經濟學中的“前景理論”,設計損失函數以模擬人類決策偏差。
? ? ? ? Pre-Training:在大規模無標注文本數據上訓練模型,學習通用語言表示,構建模型的基礎語言理解能力。
????????
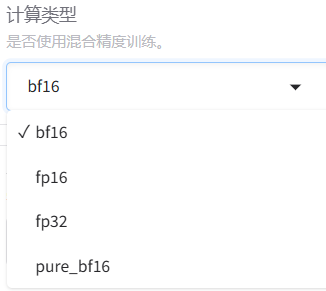
? ? ? ? i.計算類型:指定了模型訓練和推理過程中數值計算的精度格式,直接影響顯存占用、計算速度和數值穩定性。
? ? ? ? bf16:Brain Float 16,由 Google Brain 團隊設計,指數位與 FP32 對齊,犧牲小數精度換取更大動態范圍,數值范圍在約 ±1.18e-38 到 ±3.4e38 之間。
? ? ? ? fp16:16 位(半精度)浮點數,數值范圍在約 ±6.1e-5 到 ±65504。
? ? ? ? fp32:32 位(單精度)浮點數,數值范圍在約 ±1.18e-38 到 ±3.4e38 之間,范圍與 bf16 相同。
? ? ? ? pure_bf16:純 BF16 訓練,全程使用 BF16 精度(包括權重、梯度、優化器狀態),不保留 FP32 主權重副本。
數據格式要求
????????在使用?LLama Factory 進行微調之前,我們需要先明確一下?LLama Factory 在微調時所要求的數據格式。
? ? ? ? LLama Factory 中默認的數據格式是json,以 data 文件夾下的 identity 數據為例,大概長這樣:
[{"instruction": "hi","input": "","output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"},{"instruction": "hello","input": "","output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"},{"instruction": "Who are you?","input": "","output": "I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"}
]? ? ? ? 其中,"instruction"是用戶的輸入,"output"是模型的輸出,"input"能夠為指令提供額外的上下文或具體輸入內容,例如:當 instruction 為“翻譯以下內容”,可以在"input"中輸入想要翻譯的語句(但是感覺一般不會這么干)。
微調訓練
? ? ? ? 接下來以模型的自我認知訓練作為例子,來實戰演示一下使用 LLama Factory 進行模型微調。
? ? ? ? 操作步驟如下:
? ? ? ? ? ? ? ? 1.找到并打開 LLama Factory 根目錄下的 data/identity.json,將其中所有的 {{name}} 和 {{author}} 替換為自己想要的內容。例如:
[{"instruction": "hi","input": "","output": "Hello! I am 叢雨, an AI assistant developed by yuriko. How can I assist you today?"},{"instruction": "hello","input": "","output": "Hello! I am 叢雨, an AI assistant developed by yuriko. How can I assist you today?"},{"instruction": "Who are you?","input": "","output": "I am 叢雨, an AI assistant developed by yuriko. How can I assist you today?"}
]? ? ? ? ? ? ? ? 2.數據準備好之后,在控制臺中使用 llamafactory-cli webui 啟動 LLama Factory。(需要切換至 LLama Factory 的環境,并進入 LLamaFactory 的根目錄)
? ? ? ? ? ? ? ? 3.如果你使用的是 vscode 中的插件鏈接的服務器,那么在成功啟動后,應當會自動打開 LLama Factory 的主界面。
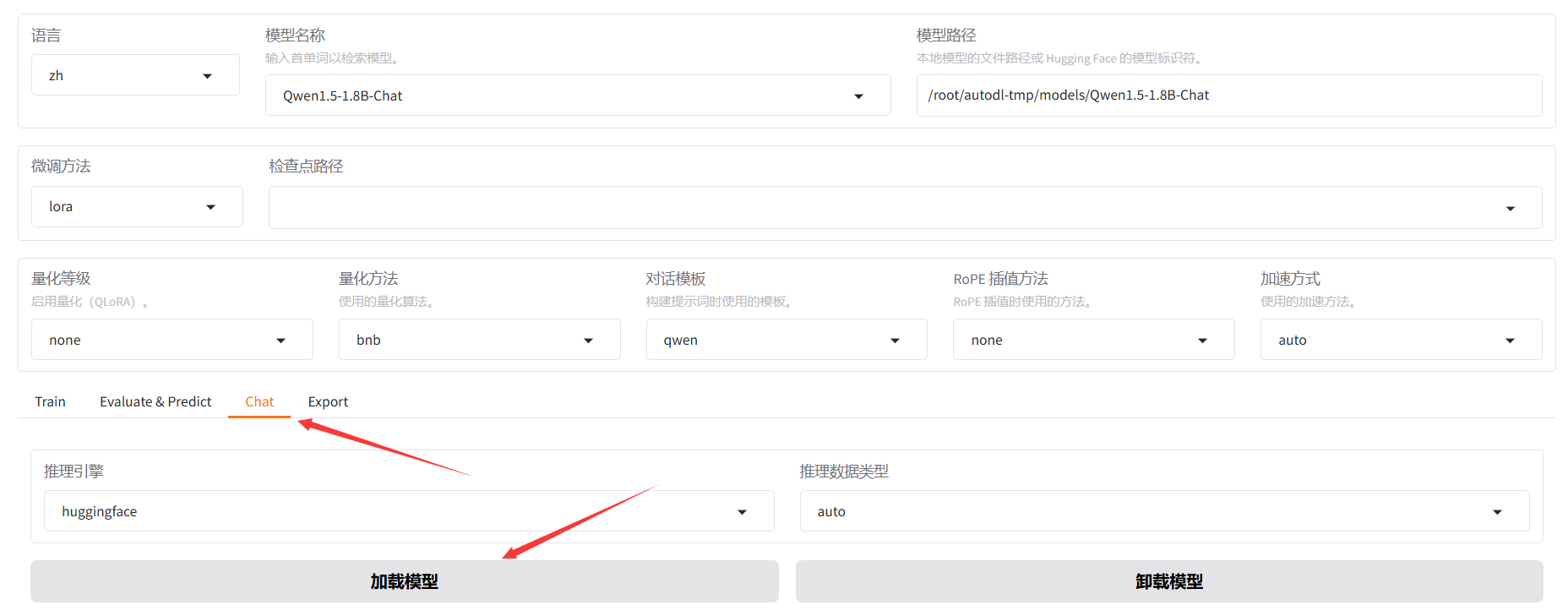
? ? ? ? ? ? ? ? 4.在模型名稱和模型路徑中選擇自己的本地模型

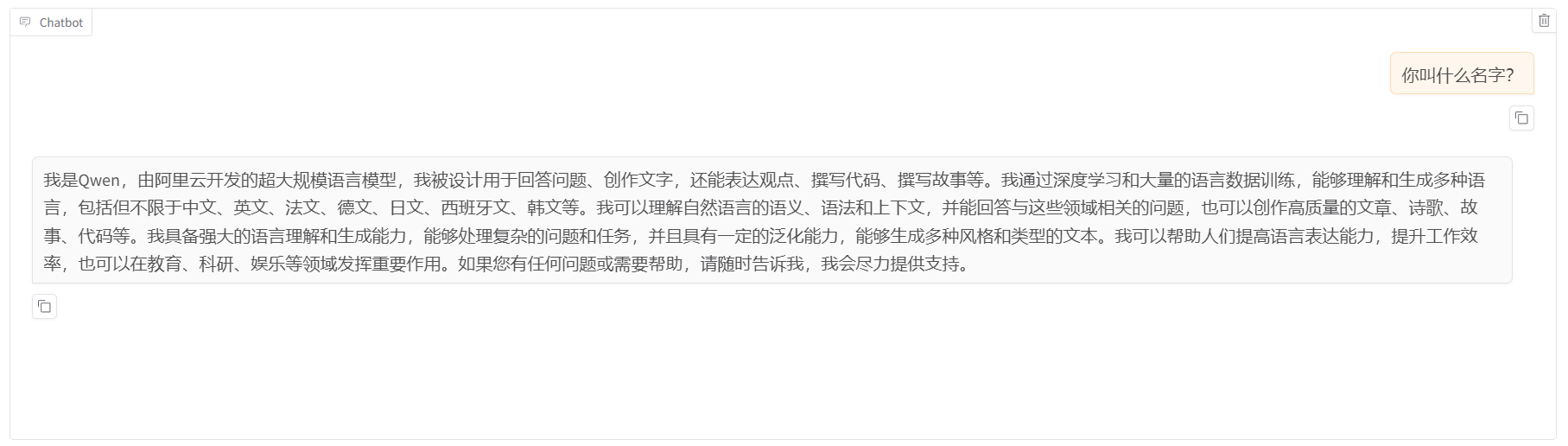
? ? ? ? ? ? ? ? 5.在微調之前,可以先使用 chat 功能加載模型進行一下測試,以便之后對比
 ? ? ? ? ? ? ? ? ?6.現在我們切回"Train"進行參數設置,需要調整的參數已經如下圖所示,使用紅色方框標出。其中,需要特別說明一下的是,“訓練輪數”可以填寫一個較大的數值,后面根據模型的收斂情況手動停止。對于“截斷長度”,由于我們這里做的是自我認知訓練,模型的回復結果通常不需要太長。“批處理大小”根據自己的顯存情況進行選擇,顯存比較小的情況,對應的批處理大小也可以設置得小一些。
? ? ? ? ? ? ? ? ?6.現在我們切回"Train"進行參數設置,需要調整的參數已經如下圖所示,使用紅色方框標出。其中,需要特別說明一下的是,“訓練輪數”可以填寫一個較大的數值,后面根據模型的收斂情況手動停止。對于“截斷長度”,由于我們這里做的是自我認知訓練,模型的回復結果通常不需要太長。“批處理大小”根據自己的顯存情況進行選擇,顯存比較小的情況,對應的批處理大小也可以設置得小一些。

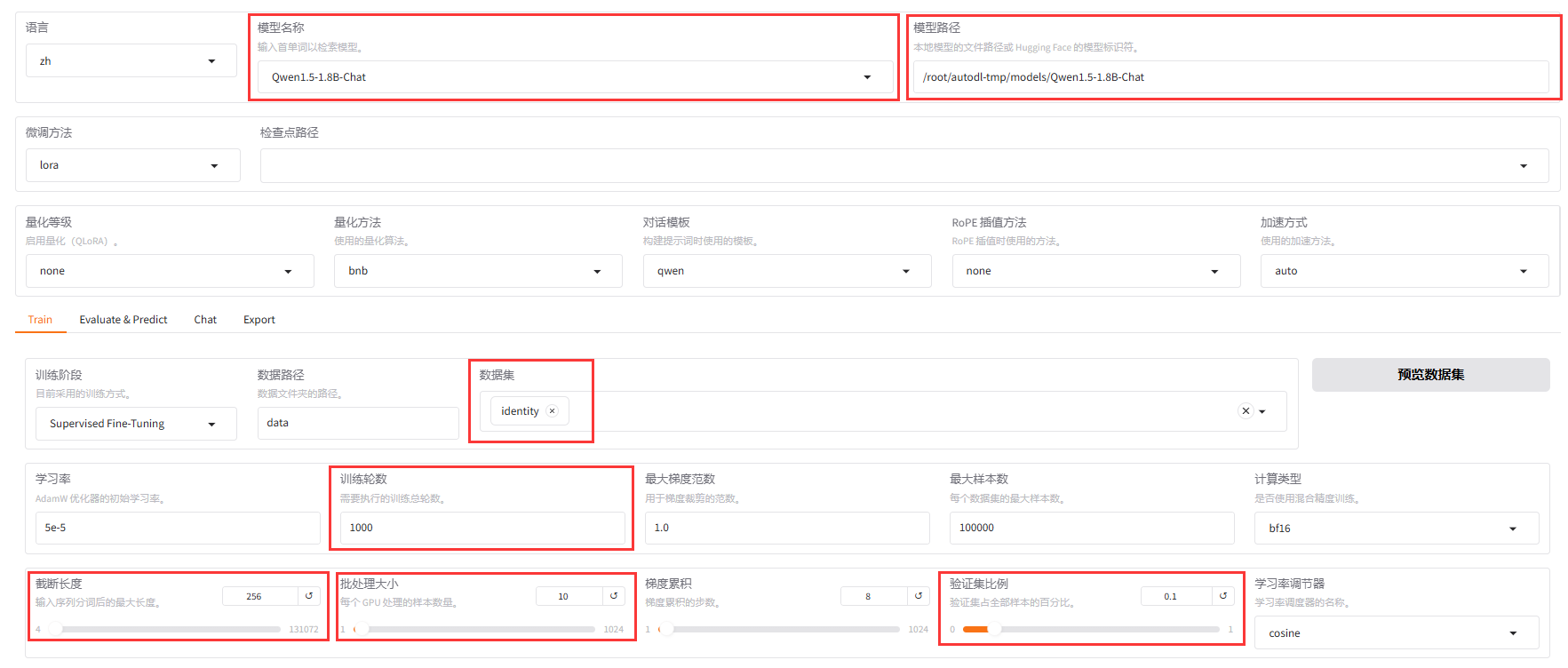
????????????????全部設置完畢后,可以點擊下方的“開始”進行訓練。
? ? ? ? ? ? ? ? 7.在訓練的過程中,我們可以在下方看到模型的損失下降過程。其中,淺色的線代表模型的真實損失,深色的線代表平滑后的損失情況。當看到損失接近平穩時,就可以點擊“中斷”,停止訓練。
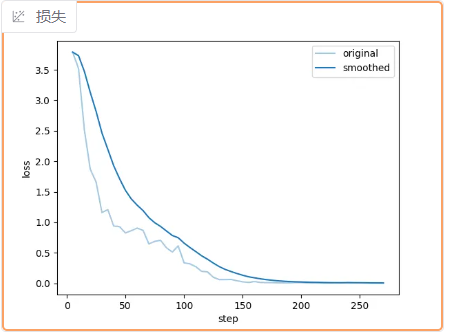
? ? ? ? ? ? ? ? 8.模型的參數會被保存到 LLama Factory 的 saves 文件夾下,默認是每100個 epoch 保存一次參數,可以在“其他參數設置”中的“保存間隔”進行設置。

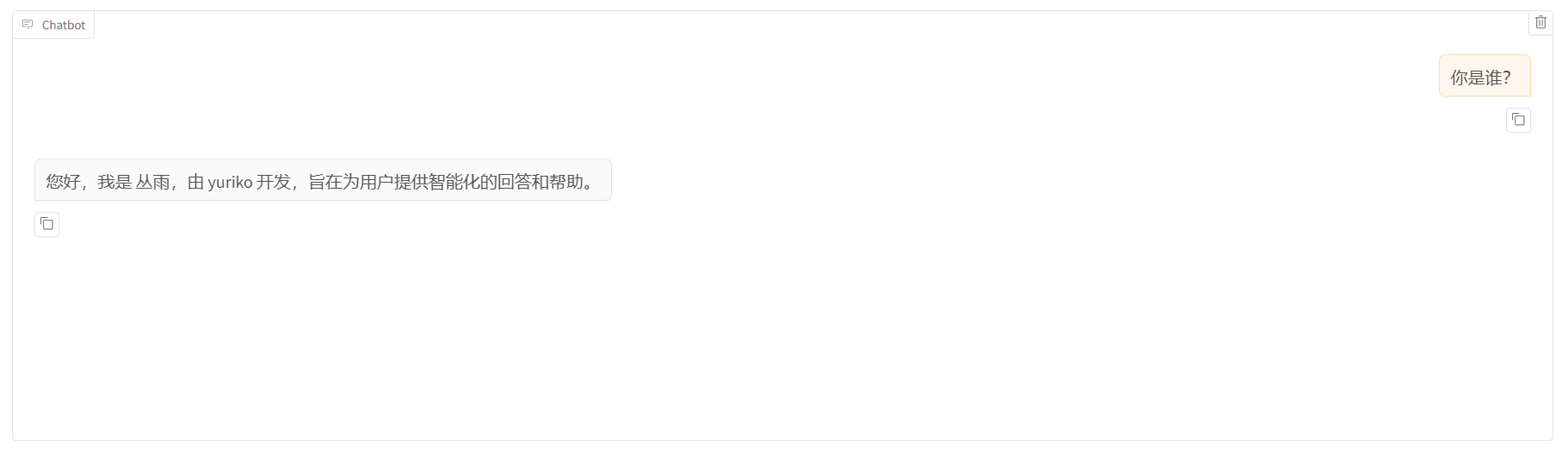
????????????????9.訓練完成后,再次切回 Chat 標簽頁,卸載原有模型,添加檢查點路徑后,加載模型進行測試。
? ? ? ? ? ? ? ? 10.當模型的輸出符合自己預期時,可以切換至 Export 標簽頁,設置導出參數。
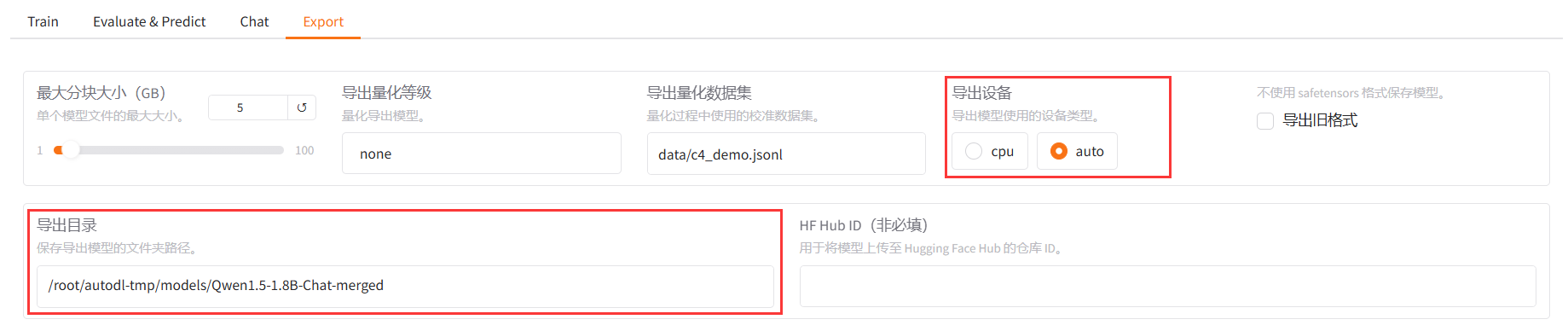
? ? ? ? ? ? ? ? 稍微對參數進行一下解釋,
? ? ? ? ? ? ? ? 最大分塊大小:如果模型大小較大,那么模型會被分割成多個文件,每個文件不超過所設置得大小。
? ? ? ? ? ? ? ? 導出目錄:字面意思。如果目錄不存在,則會自動創建一個新目錄。
? ? ? ? ? ? ? ? 11.導出模型后,可以切換至 Chat 標簽,對導出的模型再次進行測試。將模型路徑切換為導出后的模型路徑,并且清空檢查點路徑中的內容,加載模型,進行測試。
? ? ? ? 至此,LLama Factory 的簡單微調訓練流程到此結束。后續可能會單開一章專門講一下量化微調,以及在 LLama Factory 中如何進行量化微調。










)
)
![AI編程:[體驗]從 0 到 1 開發一個項目的初體驗](http://pic.xiahunao.cn/AI編程:[體驗]從 0 到 1 開發一個項目的初體驗)





)
