目錄
一、圖像拼接的原理過程
1. 特征檢測與描述(Feature Detection & Description)
2. 特征匹配(Feature Matching)
3. 圖像配準(Image Registration)
4. 圖像變換與投影(Warping)
5. 圖像融合(Blending)
二、圖像拼接的簡單實現
1、 匹配方法
2、實現上述兩個圖片的拼接
(1)導入opencv的庫以及sys庫
(2)定義cv_show()函數
(3)創建特征檢測函數detectAndDescribe()
(4)讀取待拼接的兩張圖片并顯示在窗口中?
(5)調用detectAndDescribe()函數,獲得兩個圖像的關鍵點信息,關鍵點坐標、描述符信息
(6)創建暴力匹配器,進行關鍵點之間的匹配
(7)繪制匹配成功的關鍵點之間的連線,使用drawMatchesKnn()匹配方法
(8)透視變換
(9)將圖片A填充到指定位置
OpenCV中的圖像拼接(Image Stitching)主要基于計算機視覺和圖像處理技術,將多張具有重疊區域的圖像拼接成一張全景圖。其核心原理可以分為以下幾個步驟:
一、圖像拼接的原理過程
1. 特征檢測與描述(Feature Detection & Description)
-
目標:在不同圖像中檢測關鍵特征點(如角點、邊緣等),并生成特征描述子。
-
常用算法:
-
SIFT(尺度不變特征變換):對旋轉、尺度、光照變化具有魯棒性。
-
SURF(加速版SIFT):計算速度更快。
-
ORB(Oriented FAST and Rotated BRIEF):輕量級,適合實時應用。
-
-
輸出:每張圖像的特征點坐標及其對應的描述子(特征向量)。
-
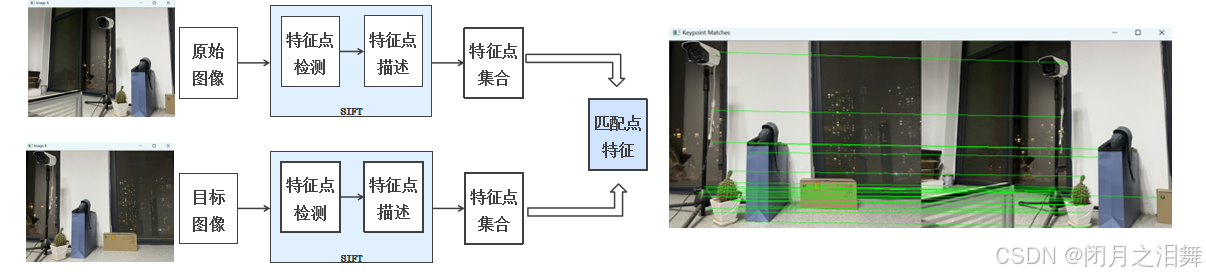
過程:圖像拼接的第一步是檢測并描述圖像中的關鍵特征點。通過使用如SIFT、SURF或ORB等算法,系統能夠提取對尺度、旋轉和光照變化具有魯棒性的特征點(如角點或邊緣)。這些算法不僅定位特征點的位置,還會生成對應的特征描述子(如128維的SIFT向量),用于后續的特征匹配。例如,SIFT通過高斯差分金字塔檢測極值點并賦予方向,ORB則結合FAST關鍵點檢測和BRIEF二進制描述子以提升效率,從而適應不同場景的需求。下圖就是通過sift特征提取找到圖像中特征相同的位置。

2. 特征匹配(Feature Matching)
-
目標:在不同圖像的特征點之間建立對應關系。
-
方法:
-
暴力匹配(Brute-Force Matcher):直接比較所有特征描述子的距離(如歐式距離或漢明距離)。
-
FLANN(快速最近鄰搜索):適合大規模數據集,效率更高。
-
-
篩選策略:
-
比率測試(Ratio Test):保留匹配距離比值(最近鄰/次近鄰)小于閾值的匹配對。
-
RANSAC(隨機采樣一致性):通過迭代剔除誤匹配,估計最優幾何變換模型(如單應性矩陣)。
-
- 過程:在獲取特征點后,需在不同圖像間建立特征點的對應關系。暴力匹配法直接計算所有特征描述子間的距離(如歐氏距離或漢明距離),而FLANN通過構建高效的數據結構加速最近鄰搜索。為排除誤匹配,通常會采用比率測試(保留最近鄰與次近鄰距離比值小于閾值的結果)和RANSAC算法。RANSAC通過隨機采樣一致性迭代估計最優單應性矩陣,同時剔除不符合幾何約束的異常點,確保匹配的準確性。
3. 圖像配準(Image Registration)
-
目標:計算圖像間的幾何變換關系,對齊圖像。
-
單應性矩陣(Homography Matrix):
-
描述兩個平面之間的透視變換關系(3×3矩陣)。
-
通過匹配的特征點對求解(至少需要4對點)。
-
使用?RANSAC?或?LMEDS?算法魯棒地估計單應性矩陣。
-
-
變換模型:
若相機僅旋轉(無平移),單應性矩陣能完美對齊圖像。若存在視差(如平移),可能需要更復雜的模型(如Bundle Adjustment)。 - 過程:配準的目標是計算圖像間的幾何變換關系,通常使用單應性矩陣(3×3矩陣)描述平面間的透視變換。通過至少4對匹配點可求解該矩陣,RANSAC在此過程中進一步優化模型的魯棒性。若相機僅繞光心旋轉(如全景拍攝),單應性矩陣能精確對齊圖像;若存在視差(如平移拍攝),則需引入光束法平差(Bundle Adjustment)等優化方法,聯合調整多圖像的相機參數以減少投影誤差。
4. 圖像變換與投影(Warping)
-
目標:將圖像投影到同一坐標系(全景畫布)。
-
方法:
-
使用?
cv2.warpPerspective()?對圖像應用單應性矩陣變換。 -
根據所有圖像的變換結果,計算全景圖的尺寸和偏移量。
-
-
優化:
-
曝光補償:調整不同圖像的亮度差異。
-
相機參數優化:若已知相機參數(如焦距),可提升對齊精度。
-
-
配準后,需將圖像投影到統一坐標系以構建全景畫布。使用
cv2.warpPerspective()對圖像應用單應性變換,并根據所有圖像的變換結果計算全景圖的尺寸和偏移量。例如,若將第二張圖像投影到第一張的坐標系中,需擴展畫布以容納所有像素。此外,需處理因曝光差異導致的亮度不一致問題,可能通過直方圖匹配或全局優化調整顏色平衡。
5. 圖像融合(Blending)
-
目標:消除拼接處的縫隙和光照差異,實現平滑過渡。
-
常用方法:
-
簡單混合(Alpha Blending):在重疊區域對像素進行線性加權平均。
-
多頻段融合(Multi-Band Blending):
-
將圖像分解為不同頻率的子帶(如拉普拉斯金字塔)。
-
對各頻段分別融合,避免高頻細節(如邊緣)錯位。
-
-
光照一致性處理:調整重疊區域的亮度和顏色。
-
-
最后一步是消除拼接縫隙與光照差異。簡單線性混合(Alpha Blending)在重疊區域對像素加權平均,但可能導致模糊。多頻段融合則通過拉普拉斯金字塔分解圖像,對不同頻率的子帶分別融合:低頻(如光照)平滑過渡,高頻(如邊緣)保留細節,從而避免重影和錯位。對于動態物體(如行人),可通過分割掩模或運動檢測排除干擾,進一步提升視覺效果。
二、圖像拼接的簡單實現
1、 匹配方法
 特征匹配的方法: 關鍵點A與找到的兩個關鍵點 X、Y的歐氏距離分別 d1、d2,且d1<d2。 歐氏距離(關鍵點A,關鍵點X)=d1。 歐氏距離(關鍵點A,關鍵點Y)=d2。 ????????(1)d1<d2,比值較大:可能不是匹配點,通常是由噪聲引起的。 ????????(2)d1<d2,比值較小:是匹配點。
特征匹配的方法: 關鍵點A與找到的兩個關鍵點 X、Y的歐氏距離分別 d1、d2,且d1<d2。 歐氏距離(關鍵點A,關鍵點X)=d1。 歐氏距離(關鍵點A,關鍵點Y)=d2。 ????????(1)d1<d2,比值較大:可能不是匹配點,通常是由噪聲引起的。 ????????(2)d1<d2,比值較小:是匹配點。
2、實現上述兩個圖片的拼接
(1)導入opencv的庫以及sys庫
import cv2
import numpy as np
import sys(2)定義cv_show()函數
在做opencv項目時,如果想顯示一張圖片,總會使用到cv2.imshow()和cv2.waitKey()這兩個函數,因此,為了方便將該功能封裝成一個小的函數方便使用。
def cv_show(name,value):cv2.imshow(name,value)cv2.waitKey(0)(3)創建特征檢測函數detectAndDescribe()
def detectAndDescribe(image):#將輸入的圖片轉化為灰度圖gray=cv2.cvtColor(image,cv2.COLOR_BGRA2GRAY)#創建SIFT特征檢測器describe=cv2.SIFT_create()#使用SIFT特征檢測器,調用detectAndCompute()函數,獲得關鍵特征點的坐標kps和描述符des(kps,des)=describe.detectAndCompute(gray,None)#使用列表生成式將獲得到的坐標信息轉化為32位的浮點數kps_float=np.float32([kp.pt for kp in kps])#返回關鍵點、關鍵點浮點數坐標、描述符return (kps,kps_float,des)(4)讀取待拼接的兩張圖片并顯示在窗口中?
imageA=cv2.imread("../data/imageA.jpg")
cv_show("imageA",imageA)
imageB=cv2.imread("../data/imageB.jpg")
cv_show("imageB",imageB)(5)調用detectAndDescribe()函數,獲得兩個圖像的關鍵點信息,關鍵點坐標、描述符信息
#計算圖片特征點及描述符
(kpsA,kps_floatA,desA)=detectAndDescribe(imageA)
(kpsB,kps_floatB,desB)=detectAndDescribe(imageB)(6)創建暴力匹配器,進行關鍵點之間的匹配
這里的匹配器會在指紋識別、指驗證項目中詳細講解,其中有關Knnmatch()為什么要選擇兩個點會詳細講解。
#建立暴力匹配器BFmatcher,在匹配大訓練集和時使用flannbasematcher
matcher=cv2.BFMatcher()#使用KNN匹配器,使用B去匹配圖片A,每次會選取兩個結果,一個最近的點一個次近鄰的點
rawMatches=matcher.knnMatch(desB,desA,2)good=[]
matches=[]
for m in rawMatches:if len(m)==2 and m[0].distance < 0.65* m[1].distance:good.append(m)matches.append((m[0].queryIdx,m[0].trainIdx))print(len(good))
print(matches)
????????這里進行條件判斷,判斷m的長度是否為2,m是對rawMatches的遍歷,所以取到的每個值都會有兩個點的信息,所以長度為2,當某一個圖中匹配的關鍵點缺失時就會出現長度小于2的情況。
? ? ?????并且如果最近點距離當前點的距離小于次近點的距離當前點距離的0.65,則認定這個點是一個比較優秀的點,并將該點保存到good這個列表中,將最近點的兩個索引值放到matches這個列表中,這兩個索引分別代表,因為是使用圖片B去匹配圖片A中的點,所以這里表示的是第一個索引queryIdx表示匹配圖片中關鍵點的索引,第二個索引trainIdx則是待匹配的圖片A中的關鍵點索引。
(7)繪制匹配成功的關鍵點之間的連線,使用drawMatchesKnn()匹配方法
vis=cv2.drawMatchesKnn(imageB,kpsB,imageA,kpsA,good,None,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv_show('Keypoint Matches',vis)
(8)透視變換
因為圖片拍攝角度的不同所以,使用透視變換將圖片扶正,將圖片轉換成同一個彎曲程度的圖像
"""透視變換"""
if len(matches)>4:ptsB=np.float32([kps_floatB[i] for (i,_) in matches])ptsA=np.float32([kps_floatA[i] for (_,i) in matches])(H,mask)=cv2.findHomography(ptsB,ptsA,cv2.RANSAC,10)
else:print("圖片未找到四個以上的匹配點")sys.exit()result=cv2.warpPerspective(imageB,H,(imageB.shape[1]+imageA.shape[1],imageB.shape[0]))
cv_show('resultB',result)
 ?
?
因為透視變換是四個點進行匹配,所以這里使用條件判斷,當圖片A和B之間有四個以上的匹配點時則依次取出圖片A和B中的坐標點信息,matches這個列表中,這兩個索引分別代表,因為是使用圖片B去匹配圖片A中的點,所以這里表示的是第一個索引queryIdx表示匹配圖片B中關鍵點的索引,第二個索引trainIdx則是待匹配的圖片A中的關鍵點索引。因此上面使用列表生成式分別取出圖片A和B中的關鍵點,findHomography函數計算變化矩陣,H是變化矩陣,mask是指外點和內點值,圖片的寬變成兩圖片的寬相加。
(9)將圖片A填充到指定位置
result[0:imageA.shape[0],0:imageA.shape[1]]=imageA
cv_show('result',result)




顏色空間轉換-----將圖像從 RGB 色彩空間轉換到 HSV色彩空間RGB2HSV())






」里最隱形的殺手)







時,對Elasticsearch(ES)數據和算法數據進行測試(如何測試幾百萬條數據))
