
1.馮諾依曼體系結構
我們常見的計算機,如筆記本。我們不常見的計算機,如服務器,大部分都遵守馮諾依曼體系。
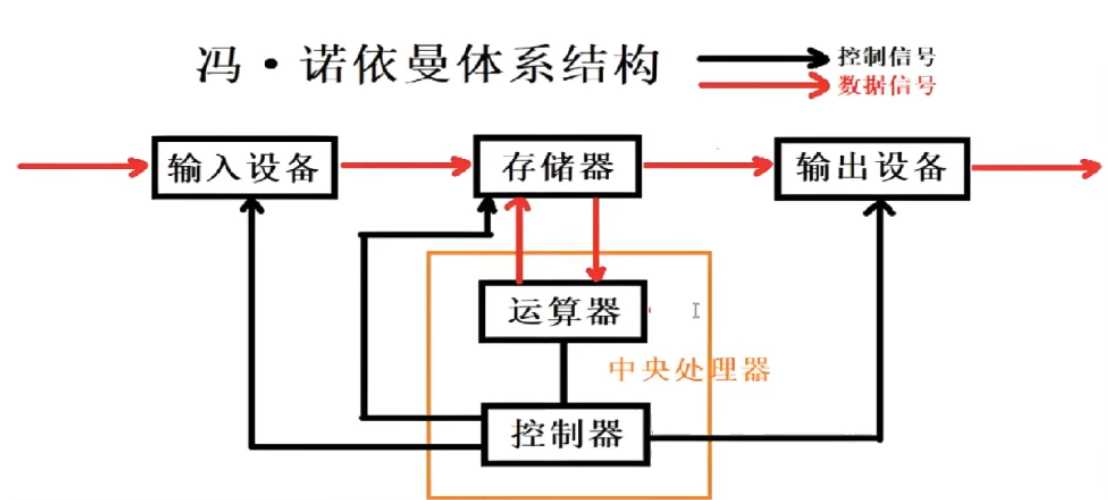
截至目前,我們所認識的計算機,都是由?個個的硬件組件組成。
- 輸入設備:鍵盤,鼠標,話筒,攝像頭,…,網卡,磁盤
- 輸出設備:顯示器,磁盤,網卡,打印機,…
- 中央處理器(CPU):含有運算器和控制器等
我們把輸入輸出設備稱為外設。
磁盤(硬盤):外存
關于馮諾依曼,必須強調幾點 :
- 這里的存儲器指的是內存;
- 不考慮緩存情況,這里的CPU能且只能對內存進行讀寫,不能訪問外設(輸入或輸出設備);
- 外設(輸入或輸出設備)要輸入或者輸出數據,也只能寫入內存或者從內存中讀取。
- 一句話,所有設備都只能直接和內存打交道。
在學習C++進行文件操作時,讀文件操作本質是把磁盤中的數據讀取到內存中,寫文件則是將內存里的數據寫入對應的磁盤上,這類數據的讀寫動作被稱為Input/Output(IO)。
從硬件層面來說,站在內存的角度理解IO,當外部設備將數據傳輸給內存時,這一過程稱為Input(輸入),而當內存把數據傳輸給輸出設備時,這一過程就叫做Output(輸出)。
1.我們編譯好的軟件,它要運行必須先加載到內存?那程序運行之前在哪里?
- 在磁盤,因為我們今天知道,程序就是個文件,它就是我們編譯好的,在我們磁盤特定路徑下的一個二進制文件。
2.為什么我們對應的程序,運行的時候必須得從我們對應的磁盤加載到我們內存呢?
- 程序運行與內存加載:編譯好的軟件以二進制文件形式存于磁盤特定路徑下,要運行必須先加載到內存。因為在計算機體系結構里,軟件運行由CPU執行代碼、訪問數據,但CPU只能讀寫內存數據,無法直接讀取外設數據,所以程序需從磁盤(外設)加載到內存,該加載過程本質是Input,即把外設數據輸入到存儲器。
- printf 執行原理:當程序在內存中運行并執行printf代碼時,數據不會直接打印到輸出設備,而是先存放在緩沖區,待需要時再刷新到外設。這同樣是馮·諾依曼體系結構的規定,printf在CPU中執行代碼,不能直接輸出到外設。
- 數據流動與體系結構效率:數據流動本質是從一個設備“拷貝”到另一個設備。馮·諾依曼體系結構的效率由設備的“拷貝”效率決定。并且在數據層面,CPU只與內存打交道,外設也只與內存打交道。
3.馮諾依曼為什么是這種結構呢?計算機能否不使用內存,僅通過輸入設備、CPU和輸出設備運行?
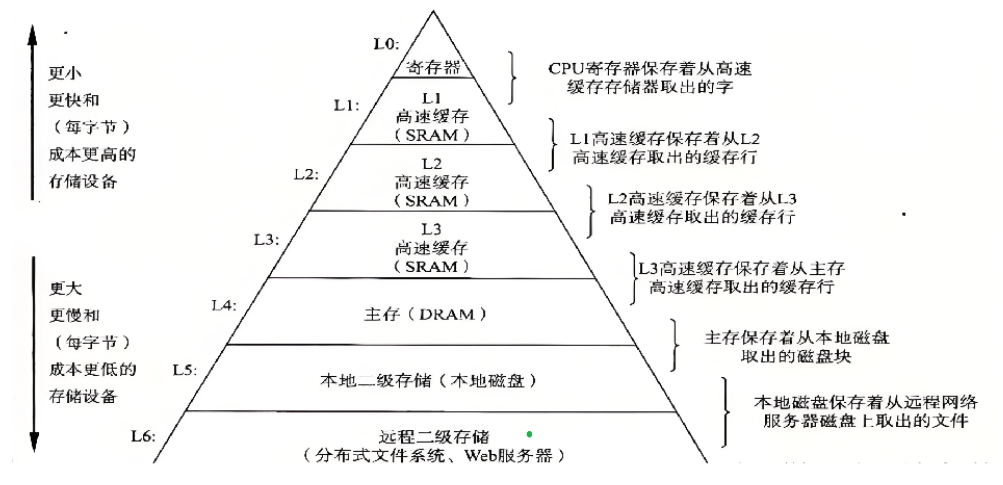
- 存儲分級與特點:計算機中有多種存儲設備,如離CPU近的寄存器有存儲能力,內存離CPU較近,磁盤離CPU較遠。離CPU越遠存儲容量越大、效率越低但價格便宜,如4GB內存幾百塊,而同等價格可買約800T磁盤。
- 效率差異問題:輸入輸出設備作為外設運算效率低(如磁盤為毫秒級),CPU運算速度快(納米級),兩者效率相差10?倍。若沒有內存,外設與CPU、輸出設備交互時,會因速度不匹配導致整個體系結構效率由外設決定(木桶原理)。
設想將所有存儲設備都換成寄存器可行,但會使計算機造價昂貴。
內存的作用及意義:為平衡效率和價格,計算機體系結構引入內存。內存可適配CPU和外設間的速度不匹配,使計算機既能以較低成本制造,又能有不錯的運行效率,當代計算機是性價比的產物。
4.為什么馮諾依曼體系結構從上個世紀五六十年代到現在,基本上是我們當代計算機的主流結構?
- 主流結構原因:馮·諾依曼體系結構的歷史意義在于讓用戶能用較低價格買到效率不錯的計算機。隨著芯片技術、摩爾定律推動存儲技術發展,計算機變得更便宜且效率更高。如今以內存決定計算機效率,使普通人能買得起計算機,進而造就眾多網民和互聯網,該體系是構建互聯網的必要條件。
5.那為什么我們有了內存之后效率就高了呢?木桶定律里里面最短的依然是輸入輸出設備呀?
- 內存提升效率原理:雖按木桶定律輸入輸出設備仍是短板,但后來出現的操作系統加載于內存中,它能用算法提前將外設數據搬到內存,配合局部性原理,讓CPU可直接讀取內存數據,從而使內存發揮最大效果提升效率。
后續內容預告:后續將討論操作系統在該體系結構中扮演的角色和意義。
6.理解數據流動
舉個場景,你在北京,你的朋友在南京,今天你兩在QQ進行聊天,當你們兩個聊天的時候,請幫我解釋一下,今天你通過鍵盤輸入了一個“你好”,那么“你好”這個字符串信息是如何展現在你朋友的顯示器上的?如果是在qq上發送?件呢?
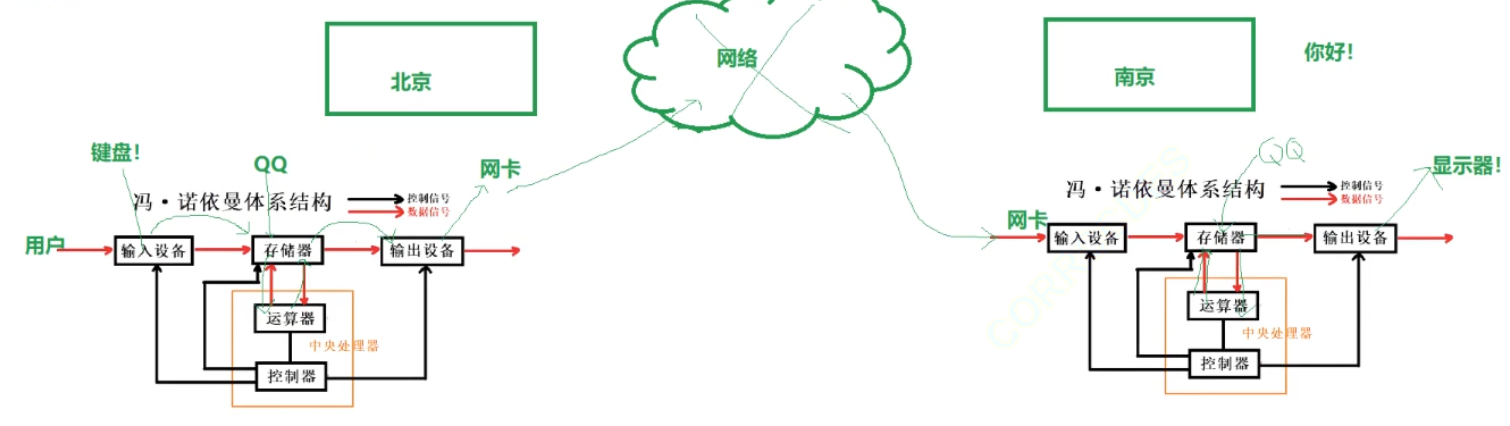
- QQ聊天數據流動:雙方用電腦QQ聊天,本質是兩臺馮·諾依曼體系設備交互。輸入方打開并登錄QQ,將QQ可執行程序加載到內存,通過鍵盤輸入信息,數據從鍵盤(輸入設備)流入內存(存儲器)。QQ對信息加密,經運算器運算、CPU處理后寫回內存,再通過網卡(輸出設備)發送到網絡。接收方網卡(輸入設備)獲取數據存入內存,啟動的QQ讀取數據交CPU解密,再寫回內存并刷新到顯示器(外設)顯示。
- QQ發送文件數據流動:文件本質是數據,拖拽文件到QQ程序時,文件從磁盤拷貝到內存,QQ執行代碼加密、封包后寫回內存,再刷新到網卡發送。對方網卡接收文件數據存入內存,解包、解密后寫回內存,甚至打開目標文件,將數據寫入磁盤(輸出設備)。
總結:聊天是數據從用戶鍵盤經體系結構轉發到對方顯示器的過程;發送文件是文件從本地磁盤經體系結構拷貝至對方磁盤的過程,軟件的作用在于處理存儲器和內存之間的關系,數據流動本質是在馮·諾依曼體系中進行。
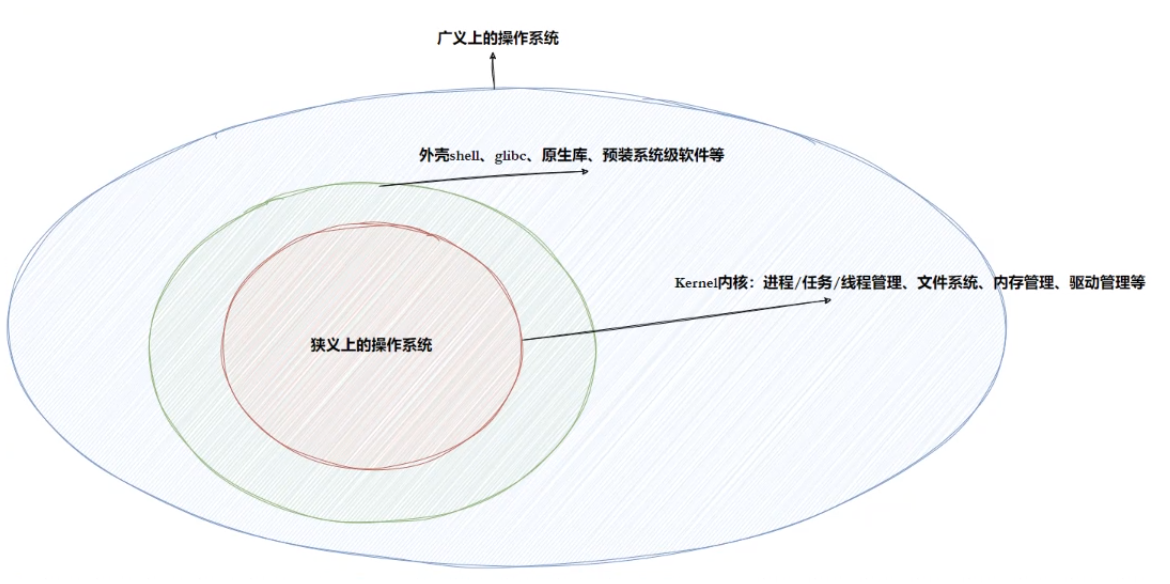
2.操作系統統(Operator System)
2-1概念
任何計算機系統都包含一個基本的程序集合,稱為操作系統(OS)。操作系統包括:
- 內核(進程管理,內存管理,文件管理,驅動管理)
- 其他程序(例如函數庫,shell程序等等)
安卓系統基于Linux內核構建,負責管理手機硬件資源(CPU、內存、存儲等),其本質仍遵循馮·諾依曼架構。與傳統PC不同,手機通過觸摸屏實現輸入輸出的高度集成,交互界面需專門設計。為此,安卓在Linux內核之上新增了應用框架層(如圖形界面、API庫等),開發者可基于此開發移動應用。
對比Windows:
- 安卓采用分層架構,圖形界面運行于用戶空間,與內核解耦;
- Windows部分圖形驅動與內核深度耦合(如DirectX),但因系統閉源,具體細節未知。
2-2設計OS的目的:
- 向下,與硬件交互,管理所有的軟硬件資源(不是目的,是手段)
- 對上,為用戶程序(應用程序)提供一個良好的執行環境(用戶是目的)
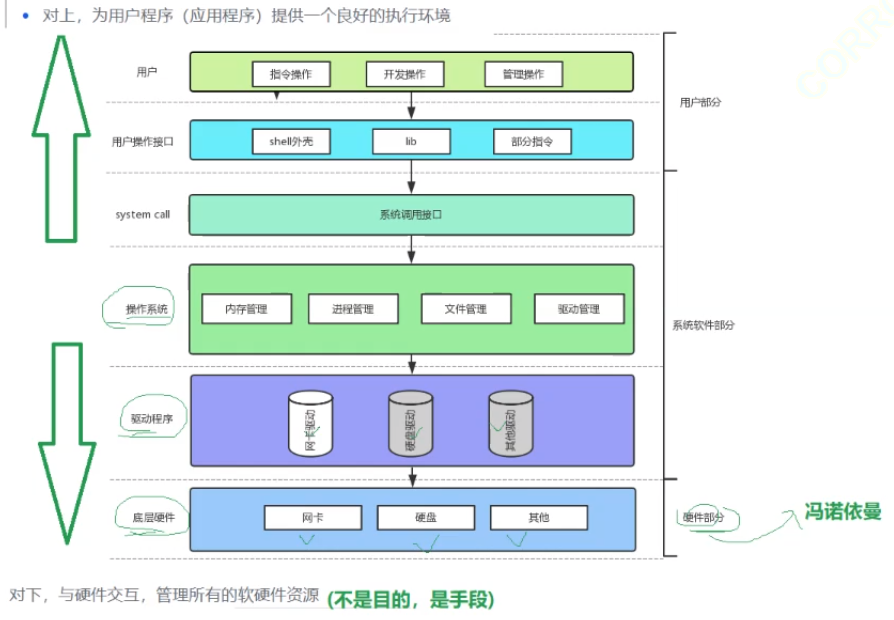
1.軟硬件體系結構層狀結構;
2.訪問操作系統,必須使用系統調用——其實就是函數,只不過是系統提供的;
printf的本質:是你把你的數據寫到了硬件(顯示器)!
3.我們的程序,只要你判斷出它訪問了硬件,那么它就必須貫穿整個軟硬件體系結構;
4.庫可能在底層封裝了系統調用。
2-3核心功能
- 在整個計算機軟硬件架構中,操作系統的定位是:?款純正的“搞管理”的軟件。
2-4理解操作系統的“管理”
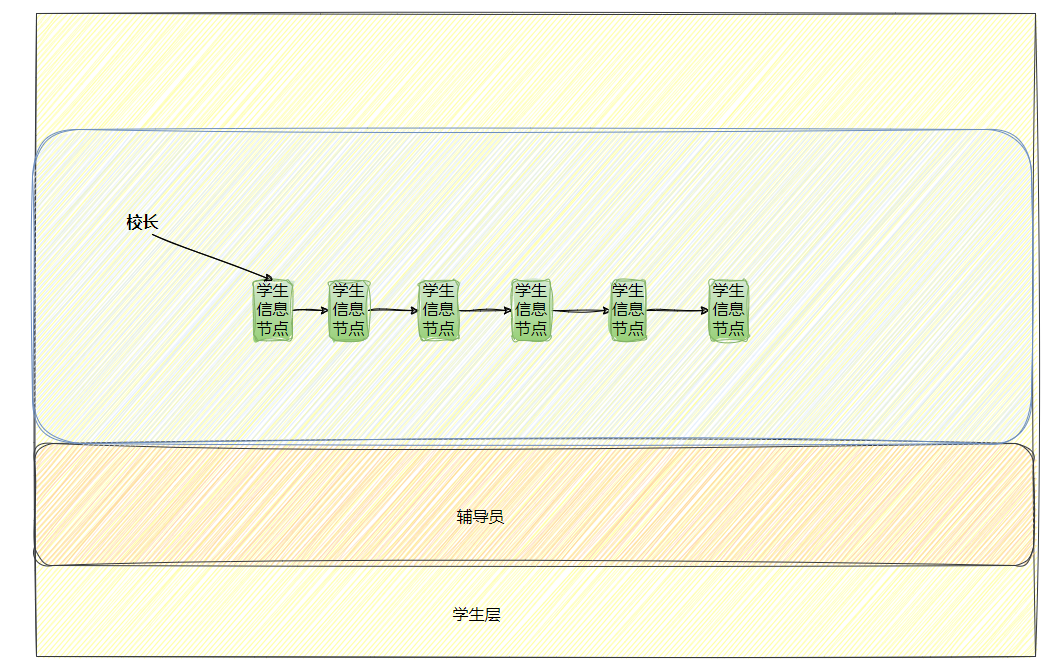
如何理解“管理”,我們下面舉個例子。
? 管理的例子——學生,輔導員,校長
? 要管理的對象:學生
? 進行管理的對象:校長
做這件事情,管理者校長有決策權,輔導員進行執行,去管理學生。
在這里,操作系統= 校長,底層硬件=學生,驅動程序=輔導員
1.要管理,管理者和被管理者,可以不需要見面
2.管理者和被管理者,怎么管理呢?根據“數據”進行管理!
3.不需要見面,如何得到數據?由中間層獲取!

校長管理學生,可以轉化為對Excel表格的數據的管理!
要是學生越來越多了,那校長的負擔越來越大,而這項工作的本質其實是對數據進行增刪查改。
“校長”了解一點編程語言,它只會c語言——因為它是一個操作系統,操作系統是用C語言寫的。
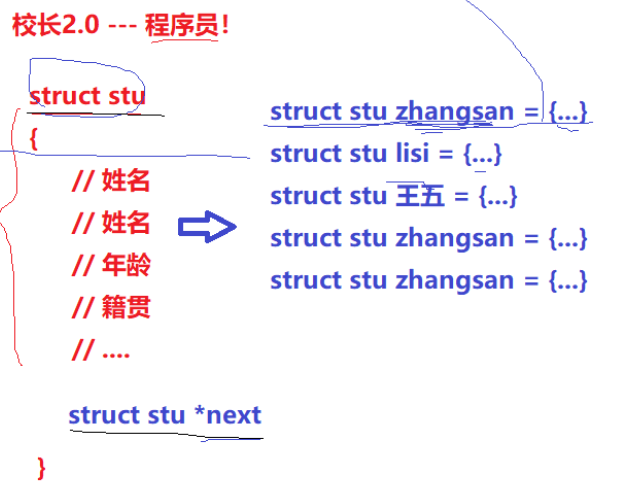
日常的校長管理學生的工作,轉化為對鏈表的增刪查改!(其他數據結構也可)
這個建模的過程稱為**先描述,再組織!**
對任何“管理”場景進行建模都適用!
- 總結計算機管理硬件:
- 描述起來,用struct結構體
- 組織起來,用鏈表或其他高效的數據結構
(類:解決先描述的問題;STL:解決的是再組織的問題。)
2-5理解系統調用
-
系統調用與庫函數的關系:庫函數和系統調用處于上下層關系。從開發層面看,操作系統對外呈現為一個整體,并暴露部分接口,即系統調用。系統調用功能基礎,對用戶要求較高。開發者可對部分系統調用進行適度封裝形成庫,方便上層用戶或開發者進行二次開發。
-
操作系統的服務:操作系統需向上層提供服務。像printf打印是將字符串寫到顯示器硬件,scanf讀入是從鍵盤讀取硬件數據到軟件程序,這些操作都需要操作系統參與,操作系統提供的訪問硬件的能力就是服務。同時,操作系統不信任任何用戶或人。
-
系統調用的本質:系統調用本質上是操作系統提供的函數調用。用戶要訪問操作系統獲取數據、設置信息等都需通過系統調用完成。由于Linux、Windows、macOS等操作系統基本由C語言編寫,所以提供的系統調用一般是C風格的C函數。函數有輸入參數(用戶提供給操作系統)和返回值(操作系統反饋給用戶),系統調用本質是用戶與操作系統之間的數據交互。
承上啟下: 我們啟動的軟件都會被加載到內存,因為馮諾依曼規定它必須得加載進來,在內存當中,當我們還沒有啟動軟件的時候,還有一款軟件在最開始就加載進來了,叫做操作系統(OS)。
OS必然要對多個被加載到內存中的程序進行管理,采取“先描述,再組織”的辦法。
3.進程
3-1基本概念與基本操作

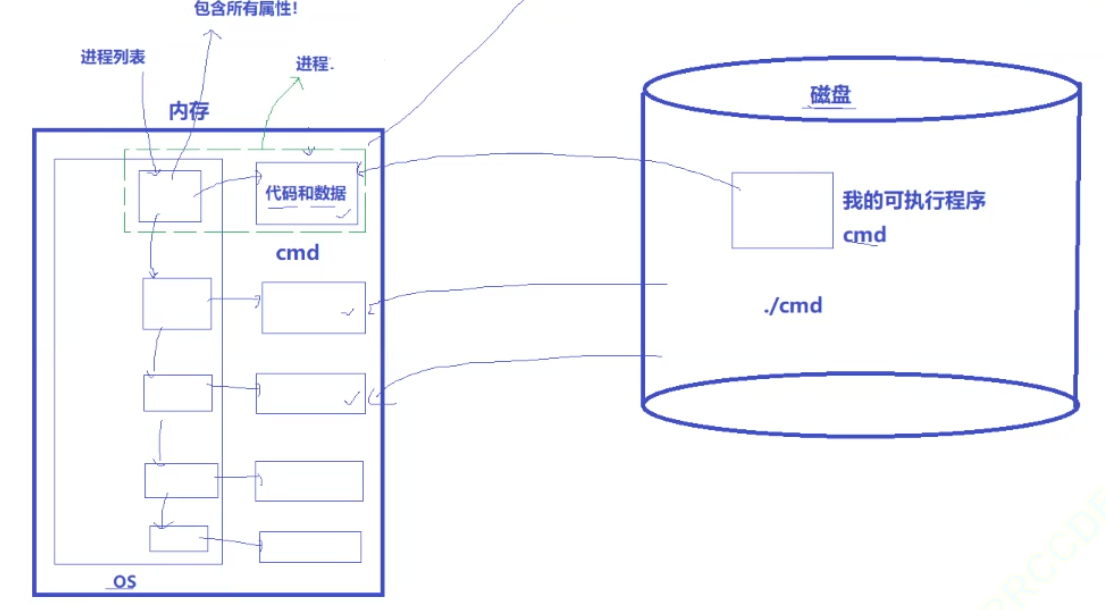
- 進程的組成:進程由內核數據結構對象和自身的代碼與數據構成。
3-2描述進程——PCB
基本概念
- 進程信息被放在?個叫做進程控制塊的數據結構中,可以理解為進程屬性的集合。
- 課本上稱之為PCB(process control block),Linux操作系統下的PCB是: task_struct
task_struct-PCB的?種
- 在Linux中描述進程的結構體叫做task_struct。
- task_struct是Linux內核的?種數據結構,它會被裝載到RAM(內存)?并且包含著進程的信息。
對進程理解的誤區:
- 很多人錯誤地認為將程序和代碼加載到內存中就是進程。實際上,進程加載時,除了將代碼和數據加載到內存,操作系統還會在內部為其創建對應的task_struct結構體,該結構體可找到對應的代碼和數據。并且所有的task_struct在操作系統內常以鏈表形式被管理起來,因此操作系統對進程的管理最終轉化為對進程鏈表的增刪查改。
創建PCB的原因:
- 操作系統為加載的進程創建對應的PCB(task_struct)結構體對象,是因為要管理進程。而管理進程必須先進行描述再組織,所以需要有描述進程的task_struct,之后通過特定數據結構(如鏈表)進行組織管理,這樣操作系統對進程的管理就轉變為對數據結構的增刪查改操作。
3-3task_struct
內容分類:

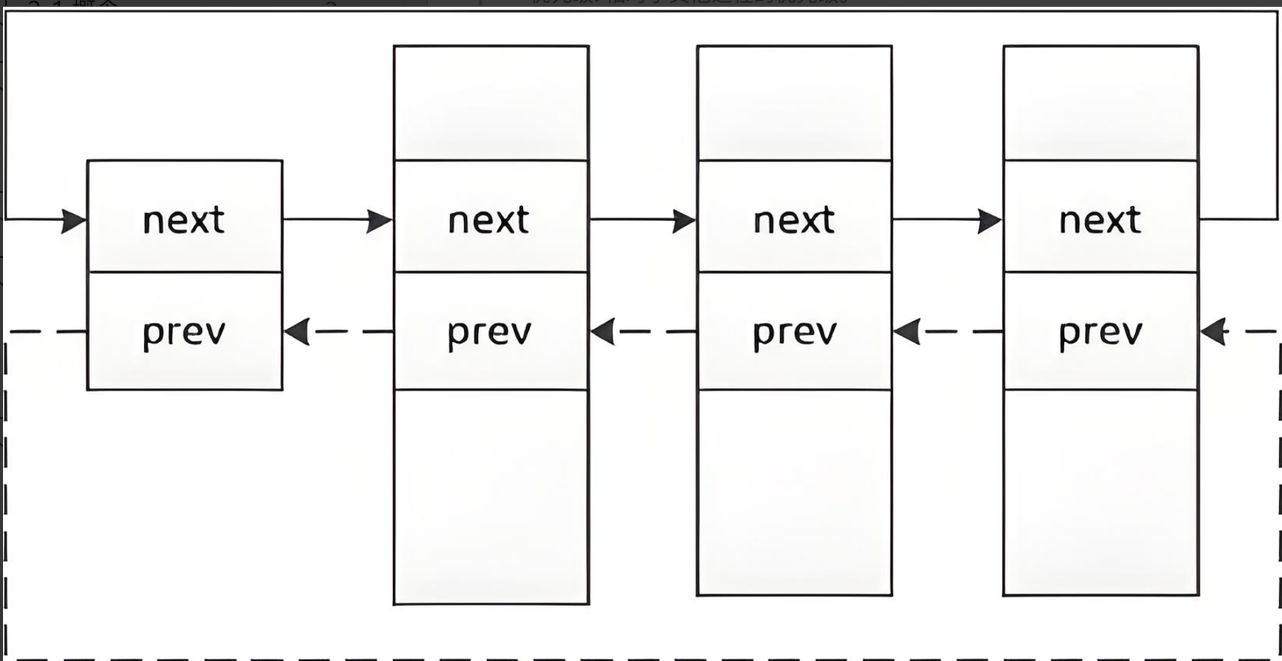
組織進程
可以在內核源代碼里找到它。所有運行在系統里的進程都以task_struct鏈表的形式存在內核里。
3-4查看進程
我們歷史上執行的所有的指令、工具、自己的程序,運行起來,全部都是進程。
- 進程一旦啟動,我們可以使用
ps來查所有進程axj,a表示所有。
top也可以查所有進程。
如果我們只想看到我們自己剛啟動的進程,可以用下面的命令:

在Linux中我們想同時執行兩條命令可以用分號相隔。分號可以用&&代替,效果相同。

當我們去查進程的時候,對應的這個grep選項它總是會被顯示出來,為什么呢?
8993 11868 11867 8993 pts/1 11867 S+ 0 0:00 grep --color=auto myprocess
因為整條命令從左向右查的時候,grep也是個命令,當它最終要把你對應的查顯示出來的結果做過濾的時候,grep命令一旦跑起來自己也是個進程,而它自己的過濾關鍵字里面本來就包括myprocess,所有它也會自己把自己查出來。
要是我們不想要查到grep可以使用下面命令:

這樣就只會查到只是包含./myprocess對應進程ID8807了.
- 我們也可以通過一個Linux當中的目錄結構叫做proc目錄,也就是可以通過文件的形式去查看進程:
ls /proc
在操作系統中,不僅能用 ls 等命令通過目錄結構查看磁盤上的文件,還能以文件形式呈現內存相關數據,讓用戶動態查看。比如 /proc 是內存級文件系統,其數據都來自內存,與磁盤無關。由于 Linux 遵循“一切皆文件”的設計理念,在 Linux 的設計中,甚至每個進程都能轉化為若干個文件。
3-5通過系統調用獲取進程標示符
我們來學習第一個系統調用:getpid
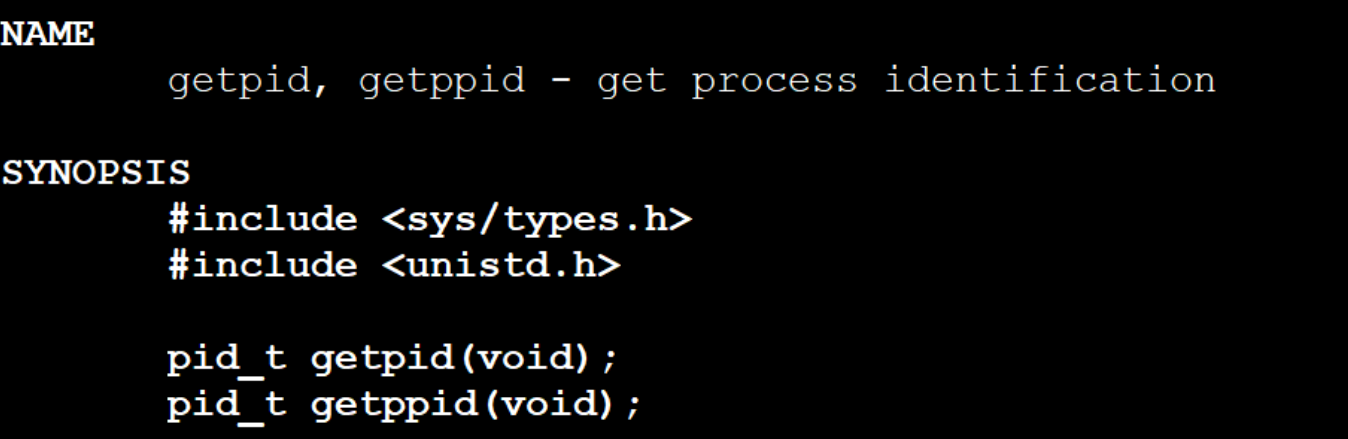
pid_t getpid(void); //獲取進程ID
pid在哪里?在你當前task_struct的標識符中。
所以我們調用getpid,本質是讓操作系統把當前進程的,從PCB把我的pid給拷貝出來,讓用戶看到自己的ID是什么。
- 只要是一個進程,就必然有自己的ID信息,所有只要有ID,我們就能證明這是一個進程。
pid_t是系統提供的,不是C語言的double這些,但Linux也是由C語言寫的,這pid_t雖然是個系統級的類型,但它其實就是個int。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{printf("pid: %d\n", getpid());printf("ppid: %d\n", getppid());return 0;
}
3-6終止進程的方法
1.ctrl+c是殺掉進程的!
2.輸入命令:kill -9 +PID值(-9是一個信號編號)

每一次啟動同一個進程,pid的值不同是很正常的;
我們運行的所有的命令,在系統里都是進程。只不過ls運行特別快,一啟動就退出;只不過top命令一啟動不退出,需要手動q來退出。
在Linux系統里,我們用戶是以進程的方式,來反問操作系統。把用戶看做一名老師,操作系統是一名學生,老師給學生布置任務,讓學生去完成,可以布置很多任務,所以我們一般把進程也叫任務。所以PCB在Linux里,它叫做task.
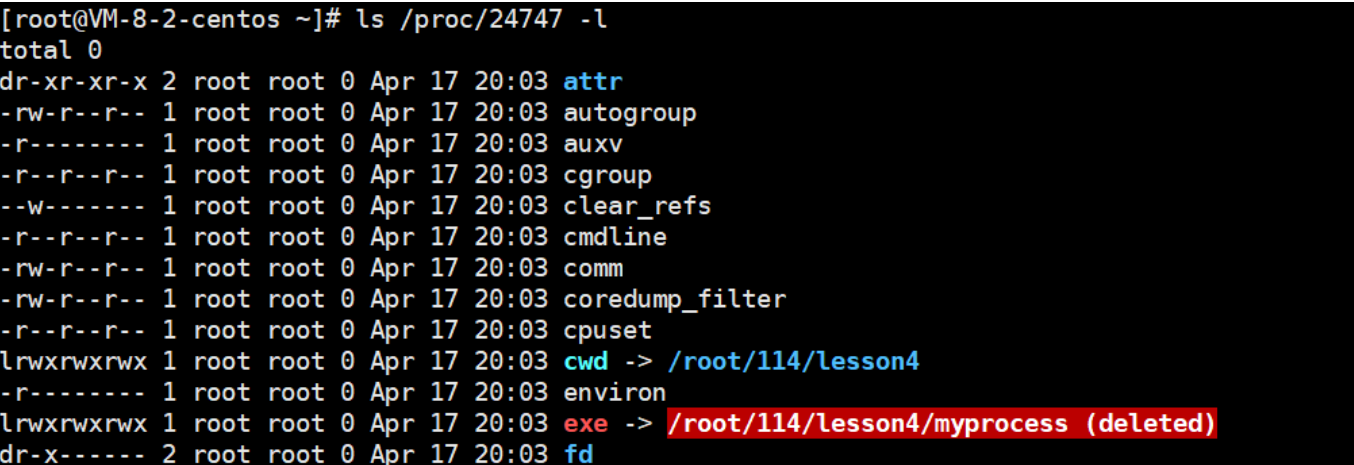
3-7查看一下pid24747當前目錄里的所有屬性
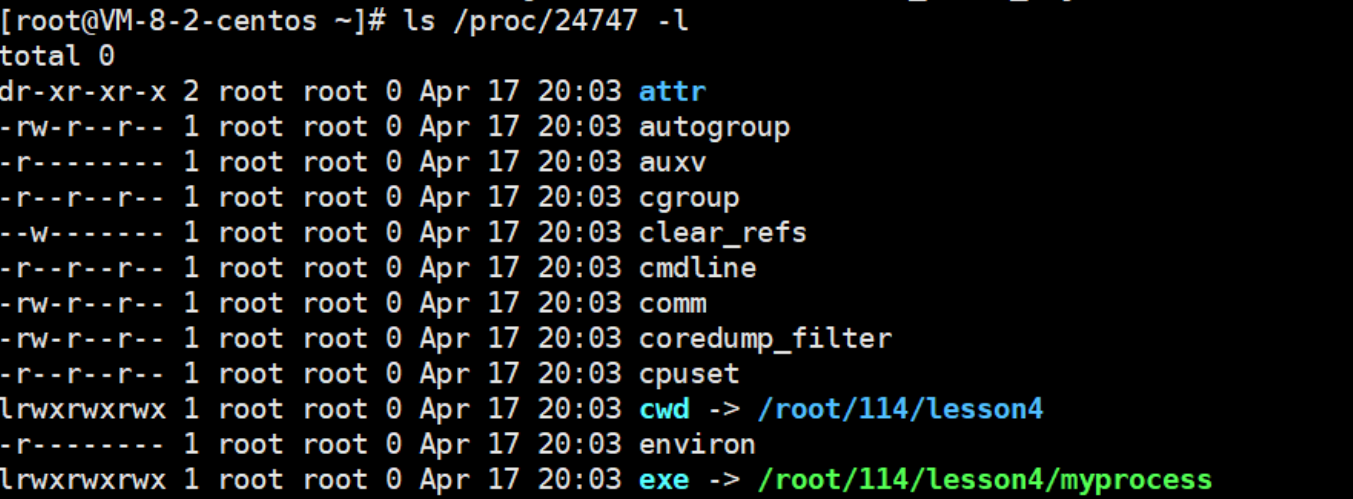
在這里面,我們來重點了解一下exe和cwd:
1.exe:進程對應的可執行文件的絕對路徑+我的數據名
要是刪掉這個路徑,并不影響進程,因為你刪掉的是磁盤上的文件,而進程啟動時,這個程序的拷貝已經在內存了,所以刪掉并不直接影響這個進程,當然后面可能會有影響,后面再說。這充分證明了,我們自己代碼已經從磁盤拷貝到內存了,所以我這個進程還在運行。
但我們再查找一次,這個路徑就開始閃爍變紅:它告訴我們進程雖然還在,但他對應的可執行程序已經deleted。
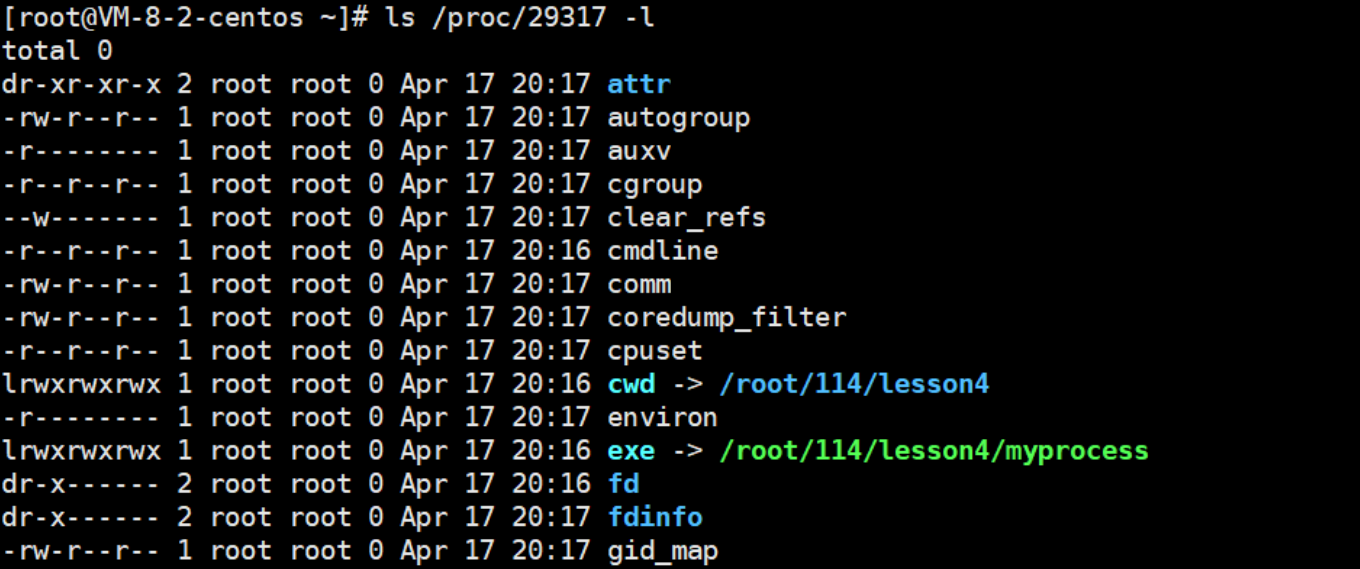
- cwd 即 current work dir (當前工作目錄),會保存一個路徑,該路徑就是當前程序所在路徑。
在 C 語言中使用 fopen 函數創建文件,如
fopen("/a/b/c/d.txt","w");或fopen("d.txt","w");時,若fopen要新建文件,對于像fopen("d.txt","w");這種不帶完整路徑的情況,文件會在當前進程的當前路徑下創建。
什么叫做當前路徑呢?也就是說為什么fopen新建一個不帶路徑的文件,它就在你的那個指定路徑下新建這個文件呢?
所謂當前路徑,是因為進程在啟動時會記錄下自身的當前路徑。 fopen 是進程內部的代碼,執行 fopen 時,傳入文件名后, fopen 內部會獲取當前的工作路徑,并將指定的文件名拼接到該路徑后面,所以新建的文件就在當前路徑下了。
3-8如何更改路徑

#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>int main()
{chdir("/home/LD");fopen("hello.txt","a");while(1){sleep(1);printf("我是一個進程!,我的pid:%d\n",getpid());}
}
在進程啟動時,先把自己的當前路徑改一下,改完之后再創建文件。
getppid
pid_t getppid(void);//獲取父進程ID
在Linux系統中,所有進程皆由其父進程創建,呈現單親繁殖的特點,不存在“母進程”這一概念。每個子進程都由對應的父進程生成,并且一個父進程能夠創建多個子進程。同時,父進程本身也有自己的父進程。基于這種進程間的創建關系,Linux中所有進程構成了類似樹狀的結構,故而也被稱作進程樹。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>int main()
{while(1){sleep(1);printf("我是一個進程!,我的pid:%d,我的父進程id:%d\n",getpid(),getppid());}
}
我是一個進程 !,我的pid: 23421,我的父進程id: 21817
我是一個進程 !,我的pid: 23421,我的父進程id: 21817
我是一個進程 !,我的pid: 23421,我的父進程id: 21817
^C
[root@VM-8-2-centos lesson4]# ./myprocess
我是一個進程 !,我的pid: 23590,我的父進程id: 21817
我是一個進程 !,我的pid: 23590,我的父進程id: 21817
^C
[root@VM-8-2-centos lesson4]# ./myprocess
我是一個進程 !,我的pid: 23611,我的父進程id: 21817
我是一個進程 !,我的pid: 23611,我的父進程id: 21817
^C
我的pid每次啟動都會變化,這是正常的,它是一個遞增的一個值,其實你每次啟動你的進程都是向系統里重新加載。
父進程ID是不變的?那父進程是誰呢?
[root@VM-8-2-centos ~]# ps ajx | head -1 && ps axj | grep 21817 | grep -v grepPPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
21752 21817 21817 21817 pts/0 25397 Ss 0 0:00 -bash我們查到的進程是一個bash,也就是說我自己的程序在啟動時,每一次啟動我的父進程都是bash,bash是什么呢?
bash——命令解釋器!
1.命令行解釋器(老板):bash本質是一個進程!
2.老板和實習生!
知識點:我們每次登陸我們的云服務器時,操作系統會給每一個登錄用戶分配一個bash!
其中bash前的-,表示是遠程登錄的。
那么下面的一串是什么?
[root@VM-8-2-centos lesson4]#
這是bash打出來的一個字符串。
為什么光標就卡在那里不動了?
因為bash也是C語言寫的,我們可以想到之前寫printf,scanf的時候,一printf它就可以把字符串打印出來,一scanf它就卡在那里了,所以我們命令行輸入的所有命令都是喂給了對應的bash,以字符串交給bash,bash拿到命令就可以做分析了。
一個進程比如bash,他是怎么做到可以創建一個子進程呢?
代碼創建子進程的方式!
3-7通過系統調用創建進程——fork初識
man fork認識fork
- fork是一個系統調用,它的作用就是創建一個子進程。
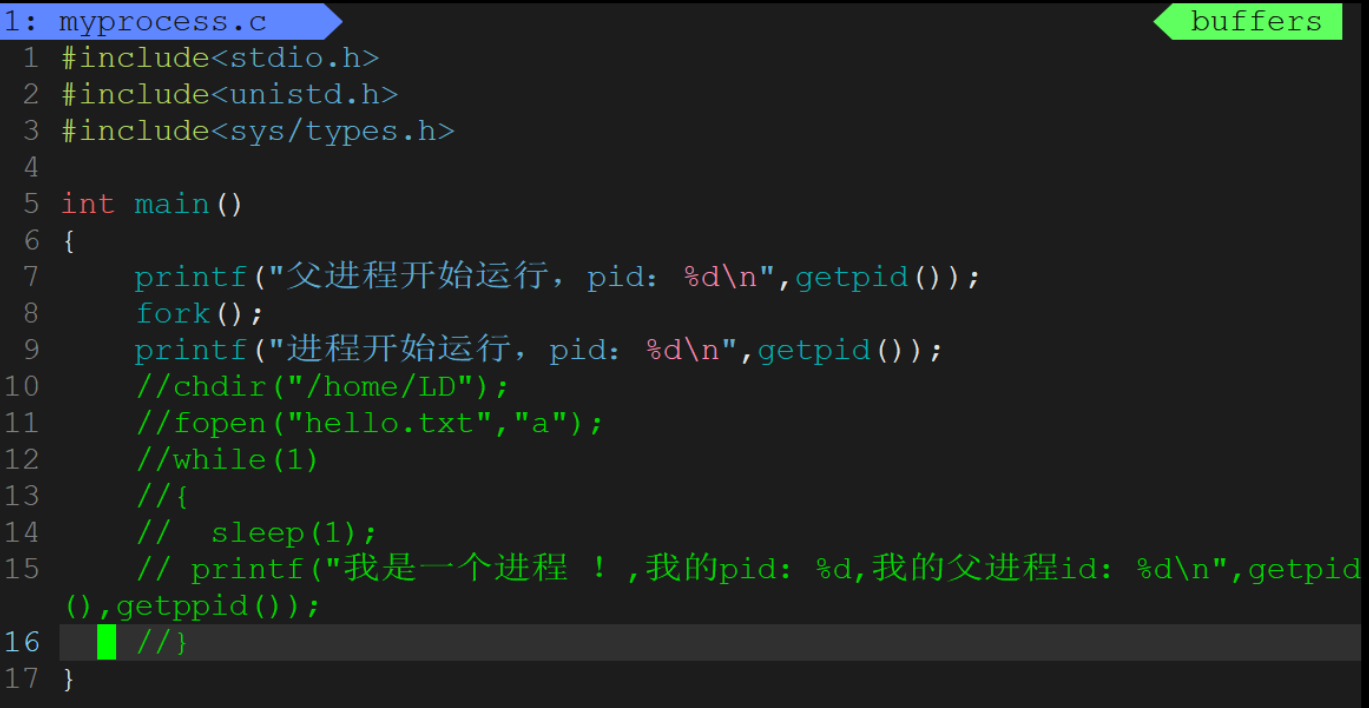
fork有創建了一個進程,那么我們一會將看到,第二個printf將執行兩次,但是打印的getpid()的值應該是不一樣的,因為一個是父進程它自己,一個是新創建的子進程。

原理:進程=PCB(task struct)+自己的代碼和數據!
創建子進程時,操作系統會為其創建一個進程控制塊(PCB),本質是拷貝父進程的PCB 。父進程的PCB指向自身的代碼和數據,子進程創建后,默認也指向父進程的代碼和數據。由于此時沒有新程序加載,子進程沒有獨立的代碼和數據,會共享父進程的代碼和數據,在被調度執行時,會執行父進程后續的代碼。
我們執行下面命令來看一下fork的返回值:
man fork
/return val

所以fork會有兩個返回值嗎??是的!!
我們要是想要父子進程未來執行不同得代碼邏輯!要怎么辦呢?
fork 之后通常要用 if 進行分流
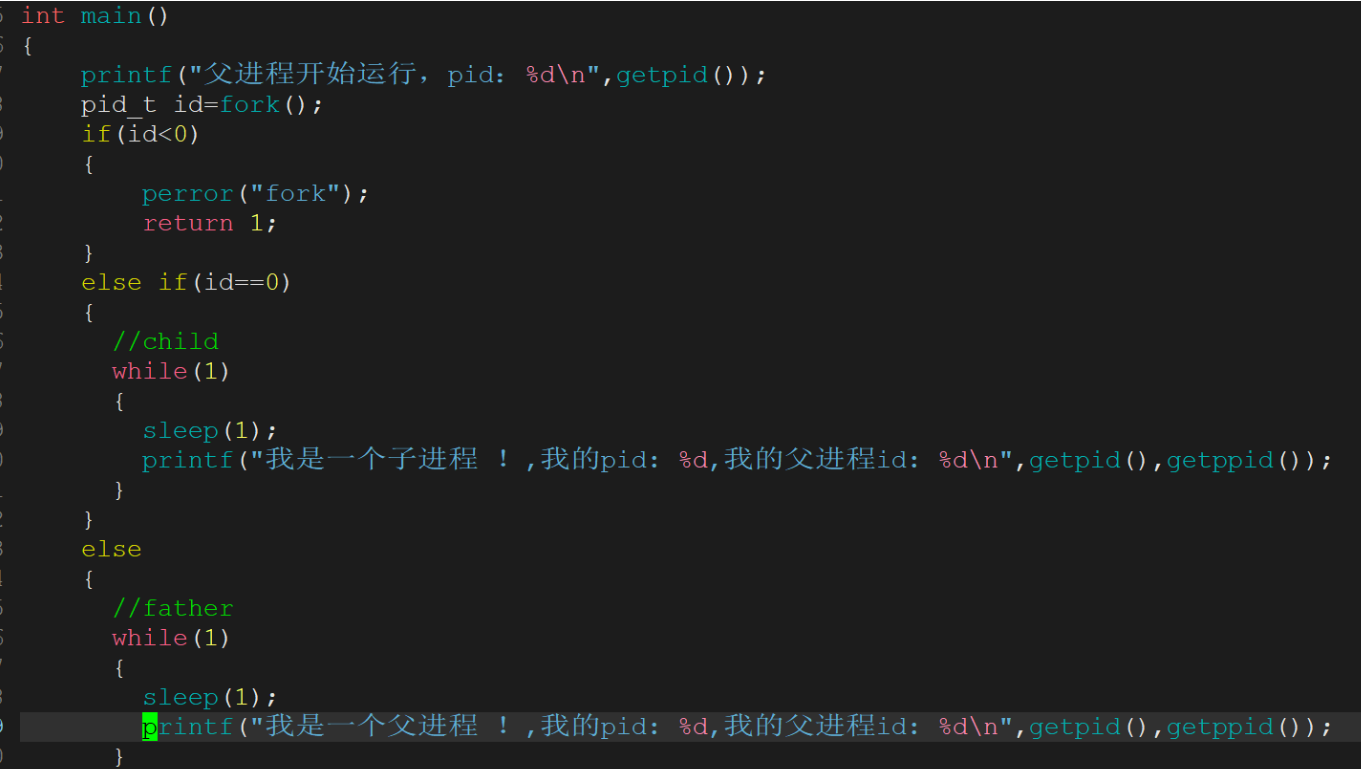

fork 函數被調用后,系統會復制父進程的地址空間等資源來創建子進程,此時父子進程共享代碼段。之所以會出現子進程返回值為0,父進程返回值大于0(子進程ID),進而進入不同執行流。
疑問:
1.為什么fork給父子返回各自的不同返回值?為什么給子進程返回0,給父進程返回子進程對應的pid?
主要原因是父:子=1:n。父進程可能有多個孩子,所以一定要把子進程的pid返回給父進程,因為父進程要通過不同的pid,來區分它不同的子進程,而子進程就不需要獲得父進程的pid,因為它已經能獲得getppid了。
2.為什么一個函數會返回兩次?
一個函數運行到return XX了,它的核心功能已經做完了。
fork函數它本質是一個系統調用,它被調用時就會進入fork函數。在fork函數中,進行申請新的PCB,拷貝父PCB給子進程,子PCB放入進程list,甚至放入調度隊列中!(這時子進程已經被創建,甚至被調度了!)。
之后執行return id; return 是語句嗎?是的!所以實際上,在fork函數內部它在進行執行時,執行到return的時候就已經共享了,所以父進程會執行,子進程也會執行。所以return被返回兩次。
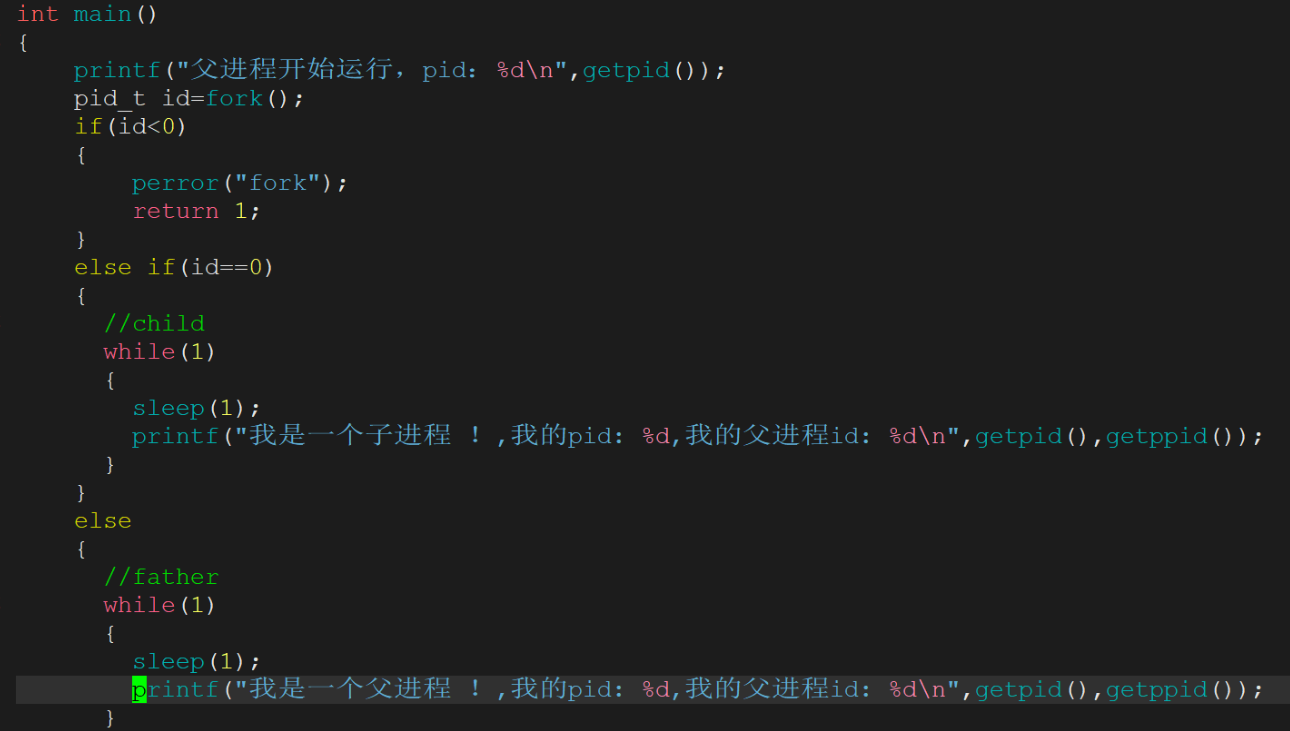
3.為什么一個變量,即等于0,又大于0?導致if else同時成立?
關于變量看似矛盾的情況:不存在一個變量既等于0又大于0。在父子進程中,因進程獨立性,父進程掛了不影響子進程正常運行。
父子進程的數據關系:父子進程間數據初始是共享的,當任何一方要修改數據時,操作系統采用寫時拷貝技術,會在底層拷貝一份數據讓目標進程修改,如子進程寫數據時,父進程訪問舊數據,子進程訪問新拷貝的數據。
父子進程獨立性的實現:
一是數據結構獨立,因為數據與內存結構相關;
二是代碼共享,數據通過寫時拷貝方式各自私有一份,即父子進程代碼共享,數據各自開辟空間私有。
之后的在虛擬地址空間展現講。
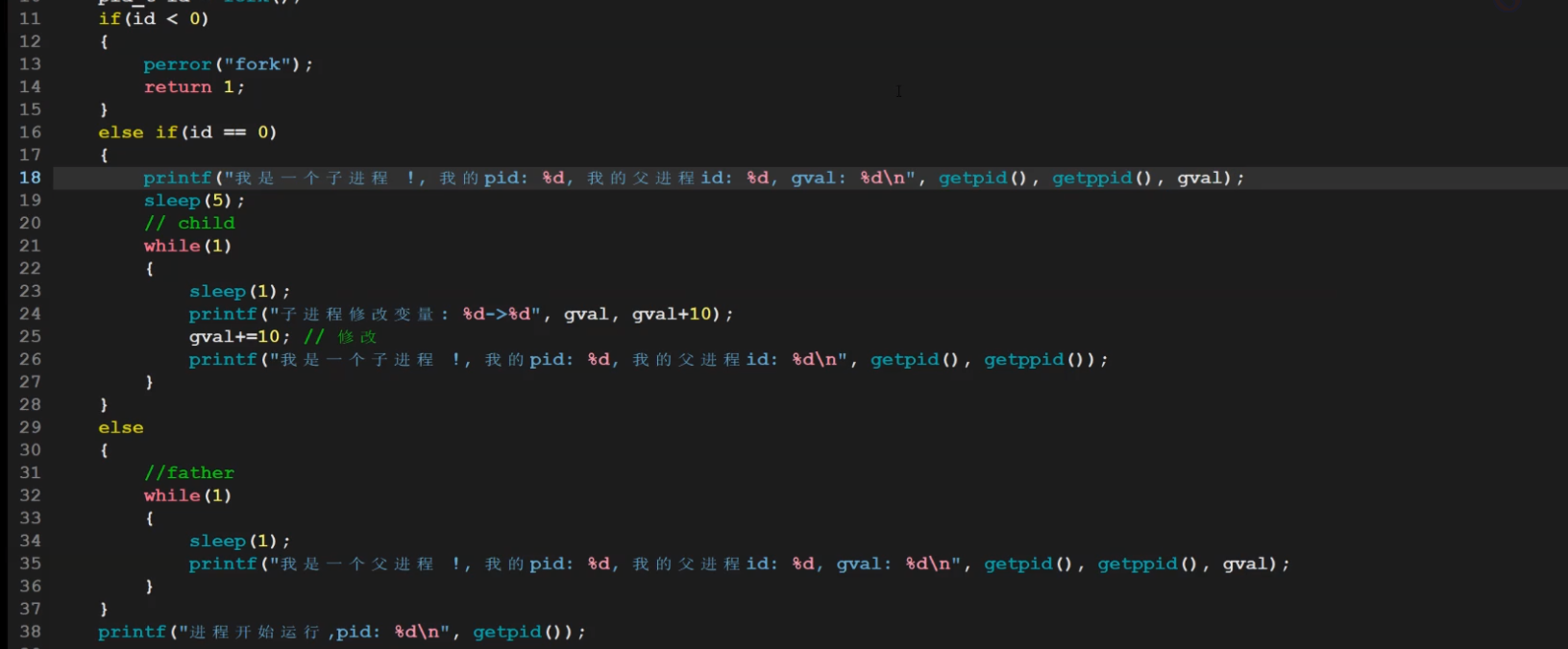
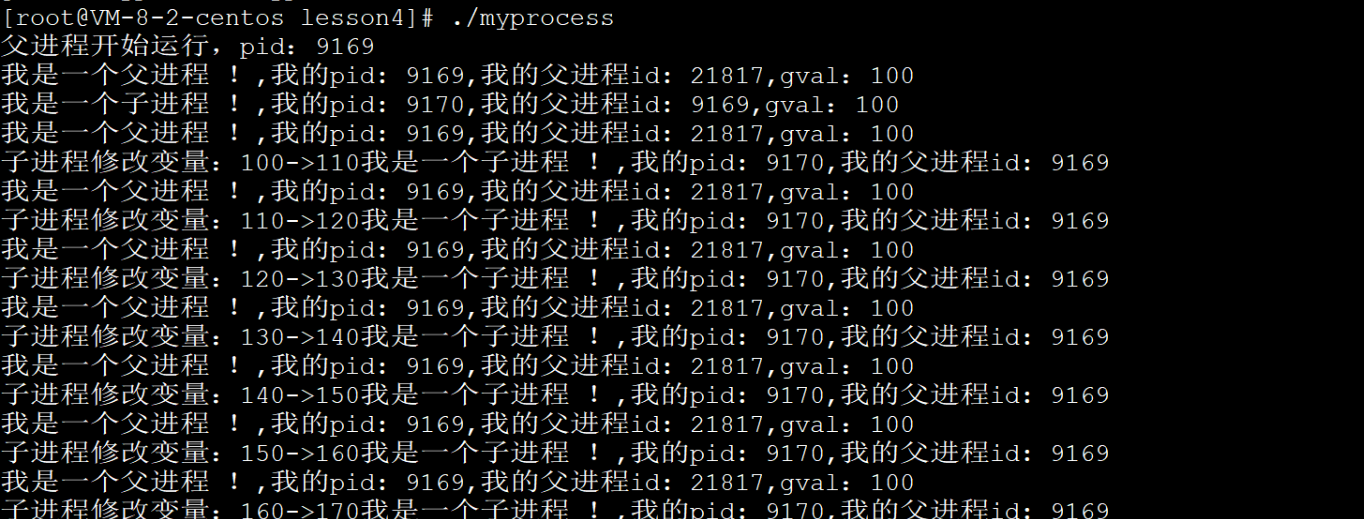
圖片上,子進程不管怎么改,父進程都是100.

)




 函數中使用 TypeScript 處理 null 和 undefined 的最佳實踐)





)




)


